Blog
Preferred Networksの子会社のPreferred Elementsでは、1,000億(100B)パラメータ規模の国産フルスクラッチLLM「PLaMo-100B」の開発を行い、8月にはPLaMo β版としてトライアル公開をしていました。そして本日、フラッグシップモデルのPLaMo Primeが公開されました。
PLaMoの事後学習を担当するアラインメントチームでは、商用版のリリースにあたり特に需要が高いと判断した以下の項目についての性能向上に取り組みました。
- コンテキスト長の拡大
- RAG用途における性能改善
- 翻訳用途におけるユーザビリティの向上
コンテキスト長の拡大
今回のPLaMo Primeにおける一番わかりやすい改善点は、扱えるコンテキスト長が約4,000から4倍の約16,000まで拡大したことです。このコンテキスト長であれば、PLaMo-100BのarXiv 本文や夏目漱石著の『夢十夜』の全文は、1つのプロンプトに収まります。このように長いテキストを入力に含められるようになったことで、これまでのPLaMoよりも多様な場面で活躍できるようになりました。例えば
- 長文の翻訳:英語で書かれたマニュアル、論文、小説のような長いテキストから日本語の要約や翻訳の生成
- 複数のドキュメントに基づいた質問応答:関連するドキュメントに基づいて質問応答をする際に、より多くのドキュメントを一度に扱えます
- 長い履歴を持つロールプレイ:何十往復にも及んでも、過去の内容を考慮して発話生成できます
といった場面で利用できます。
コンテキスト長に関する性能を実際に以前のPLaMo βと比較してみます。まずNeedle In A Haystackという、入力トークン(Haystack)の中で該当するテキスト(Needle)を探すタスクを解かせた場合、これまでのPLaMo β(図1上段)では、対応するコンテキスト長を超えた場合は、該当するテキストを探し当てることがほぼできませんでした。製品リリース版であるPLaMo Prime(図1下段)では4倍の長さまで高い精度で探し当てることができています。なお、白い箇所は、評価用のLLMであるGPT-3.5-Turboが適切な値を返さなかったことを表しています。
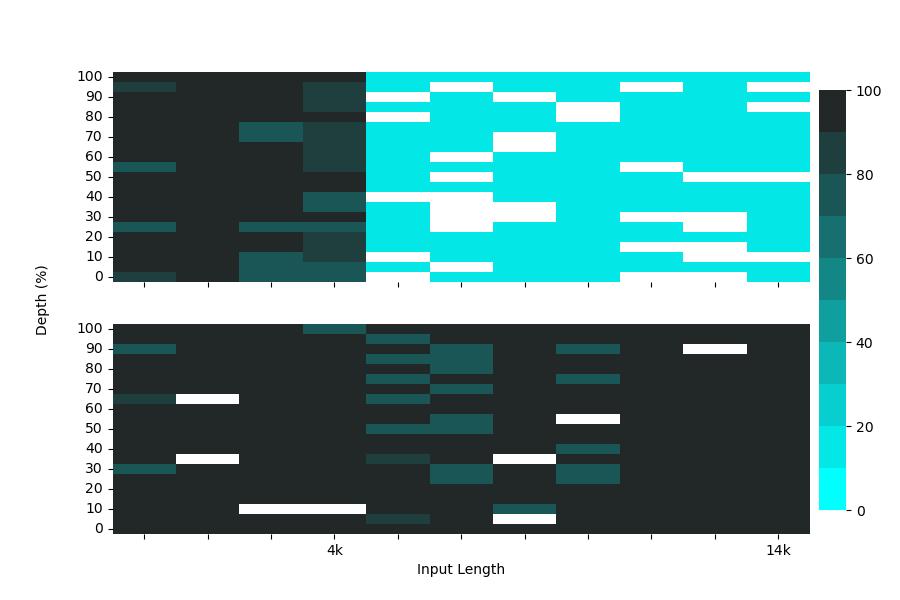
図1: Needle In A Haystackの評価結果: (上) PLaMo β, (下) PLaMo Prime。横軸の入力長に対し、縦軸のDepth位置に存在するNeedle テキストの検出率を示す。色が黒いほど検出率が高い。
より非人工的な実験としてLongBenchという長文テキストに対する質問応答、複数ドキュメントに対する質問応答、長文要約といったタスクを集めたベンチマークの結果を次の表にまとめました:
| Dataset | PLaMo β | PLaMo Prime |
| narrativeqa | 18.96 | 29.48 |
| qasper | 31.35 | 38.65 |
| multifieldqa | 39.19 | 49.47 |
| hotpotqa | 43.07 | 57.98 |
| 2wikimqa | 37.30 | 51.41 |
| musique | 17.20 | 40.04 |
| qmsum | 21.36 | 23.13 |
| triviaqa | 87.27 | 88.43 |
| passage count | 4.50 | 5.00 |
| passage retrieval | 16.50 | 29.50 |
こちらの結果については、全てのタスクについて、PLaMo Primeの方が上回る結果となりました。なお、コンテキスト長の延長のために行った技術的な取り組みは、コンテキスト長拡大のブログで紹介していますので、ぜひご覧ください。
RAG用途における性能改善
大規模言語モデル(LLM)は知識集約型のタスクにおいて目覚ましい能力を発揮しますが、重大な限界があります。それは、知識が訓練時に凍結され、訓練データのみに頼るとハルシネーション(幻覚)を起こしやすいということです。外部ソースから取得した情報を推論時に動的に組み込むことで、静的なモデル知識と最新の信頼できる情報のギャップを埋める「検索拡張生成(RAG: Retrieval Augmented Generation)」が有望な解決策として登場しました。このアプローチにより、最新のデータを使用して根拠のある回答を生成できるようになるほか、公開されているトレーニングデータセットに含めることができない機密情報やセンシティブな情報を使用できるようになります。
RAGパイプラインは、2つの主要なコンポーネントで構成されています。知識ソースから関連情報を特定する「Retriever」と、この情報から応答を合成する「Generator」(LLM)です。従来のQ&Aシステムとは異なり、RAGは、検索されたコンテキストが不完全であったり、断片的であったり、クエリに対して部分的に関連していたり、または重要な詳細が欠けていることが多い環境で動作します。この不完全さは、RAGが文章検索手法(キーワードベース、セマンティック、またはハイブリッド)に依存して、上位k個の一致を取得し、優先順位を付けて再順序化することに起因します。そのため、LLMは、構造化されていないテキストフラグメントを巧みに操作し、回答に必要な情報と関係ない情報を分離して、正確で一貫性のある応答を構築する必要があります。
RAGに関するPLaMoの性能を比較するために、ChatRAG-BenchおよびRAGBenchの中から、様々なQ&Aタスクをカバーするベンチマークを選択し、評価しました。これらのデータセットは、入力および回答の長さやソースが異なります。
| Dataset | PLaMo β | PLaMo Prime | % Improvement |
| DoQA | 20.41 | 25.49 | 24.89 |
| SQA | 40.07 | 58.57 | 46.17 |
| CovidQA-RAG | 27.60 | 33.35 | 20.83 |
| DelucionQA | 40.61 | 46.47 | 14.43 |
| EManual | 39.44 | 44.62 | 13.13 |
| TechQA | 8.97 | 38.22 | 326.09 |
| Mean | 29.52 | 41.12 | 39.30 |
PLaMo Primeは、すべてのテストデータセットにおいてPLaMo βよりも一貫した改善を示しており、特にSQAとTechQAで大きな改善がみられます。TechQAデータセットには、長文の技術マニュアルを使用して回答する質問が含まれており、その長さゆえにPLaMo βでは対応できなかったクエリが75%以上を占めています。「コンテキスト長の拡大」で詳述した長文コンテキスト対応により、新しいモデルはこれらの長いコンテキストを適切に処理し、複雑な技術的クエリに対して包括的な回答を生成できるようになりました。
翻訳用途におけるユーザビリティの向上
PLaMoの特徴は日本語と英語のテキストデータが学習データに豊富に含まれていることで、英語・日本語間の翻訳は得意とするタスクの一つです。
翻訳用途における使用感を向上するために、学習データを追加することで以下のようなユースケースでも意図通りに動くように指示追従性能の向上に取り組みました。(技術詳細は、コンテキスト長拡大のブログのデータセットのセクションで紹介をしています。)
- Long contextを入力するような翻訳もできるようにすること
- Multi turnでの翻訳の際に、毎回指示文を入力しなくても適切に翻訳を続けること
1番目の改善により、例えば以下のような入力を行うことで、たとえば何度か紹介しているコンテキスト長拡大のブログの文章量程度であれば全て一度に英語に翻訳させるといったようなことが可能となっています。
{{ここにブログの文章を全て貼り付ける}}
-----
以上の日本語を英語に直訳してください。返答に余計な語句は含めないでください。
また2番目の改善に間しては、以下のようなやりとりを行い、翻訳を逐次的に続けていくことが可能です。
[User]
以降に書く文章全てを日本語に翻訳してください。日本語は直訳とし、返答に余計な語句は含めないでください。
{{英文1}}
[PLaMo]
{{日本語文1}}
[User]
{{英文2}}
[PLaMo]
{{日本語文2}}
…
実際にPFNのProductsページを翻訳させてみた例が以下となります。Userの2 turn目以降は翻訳指示を入れずに英文を貼り付けするだけでも、適切に翻訳を続けてくれています。

おわりに
本ブログでは、製品版であるPLaMo Primeをリリースするにあたって直近取り組んだモデル開発のうちコンテキスト長の拡大, RAG, 翻訳に関する性能向上について紹介しました。PLaMoの性能改善については今後も継続して続けていく予定です。
もちろんPLaMo Primeはこれ以外にも様々な用途で使用することが可能です。PLaMo LLMのXアカウントやgithubのpfnet-research/plamo-examples リポジトリでも使用例を紹介・日々追加しています。
ぜひ実際に使ってみていただけたら幸いです。
以下のリンクから登録ができます。
関連リンク
- PLaMo-100Bの論文
- PLaMo-100Bの開発ブログ
- PLaMo-100Bベースモデルの公開
Area