Blog
この記事は、パートタイムエンジニアの小林悟郎さんによる寄稿です。
はじめに
こんにちは!2023年末からPreferred Elements(PFE)でアルバイトをしています、東北大学 博士課程3年の小林悟郎です。大学では言語モデル内部の挙動や性質について研究しています。PFEのアルバイトでは日本語大規模言語モデル(LLM)の指示学習(Instruction Tuning)について取り組んでいます。
LLMの構築では一般的に、大規模な事前学習(Pre-training)の後に比較的小規模な事後学習(Post-training)を行います。事後学習として典型的に採用されているものの1つが指示学習です。指示学習の訓練データがLLMのベンチマーク性能に大きく影響を及ぼすため、近年では「指示学習で望ましいデータとはどんなものか」について盛んに議論されています。本稿では、Zhao et al. (2024)の「回答が長いサンプルだけを少量抽出して指示学習すると良い」という主張を日本語LLMかつ日本語データで検証します。実験から、使うデータセットによって結果が異なる可能性を示しました。また、回答の長さがベンチマーク性能に与える影響についても分析しました。
事前知識
事前学習と事後学習
LLMの訓練は事前学習(Pre-training)と事後学習(Post-training)の2つに分けられます。
まず事前学習として、主にWebから収集した大量のテキストデータを用いて「テキストを途中まで与えられ、続きを生成する」という訓練を大規模に行います。続いて事後学習として、「指示・質問・発話などが与えられ、望ましい回答を生成する」という訓練を小規模に行います。
ChatGPTをはじめ、LLMはユーザーとのチャット形式での応用・サービスが最も盛んに行われています。事後学習ではLLMをこの形式に慣れさせると共に、幅広い入力に対して有益かつ公正で無害な、ユーザーにとって好ましい回答を生成するように訓練します。
指示学習
事後学習は通常、指示学習(Instruction Tuning)と嗜好学習(Preference Tuning)によって行われます。ここでは、本稿で扱う指示学習についてのみ説明します。
指示学習では、「指示」と「回答」のペアからなるデータセットを用いて、LLMが与えられた指示に対して望ましい回答を生成するように教師あり学習(Supervised Fine-Tuning; SFT)を行います。例えば、以下のようなデータが含まれます(https://huggingface.co/datasets/fujiki/japanese_alpaca_data から抜粋):
- 例1
- 指示:三原色とは何ですか?
- 回答:三原色は赤、青、黄色です。
- 例2
- 指示:与えられた数字を昇順に並べてください。 2、4、0、8、3
- 回答:0、2、3、4、8
こういったデータは当初、人手で作成されることが主流でしたが、最近ではプログラムやLLMを利用した自動生成も盛んに行われています。
指示学習に用いるデータはベンチマーク性能に大きな影響を及ぼします。単に大量のデータセットを採用する戦略は訓練コストが増大するにも関わらず、必ずしも良い性能には繋がりません。むしろ「高品質なごく少量のデータセットでよい」と主張する研究もあります(Zhou et al., 2023)。そこで、効率的に指示学習を行うために、データセットから高品質と考えられる少量サンプルを選択して指示学習する研究が行われており、「指示学習で望ましいデータとはどんなものか」について盛んに議論されています。本稿では、Zhao et al. (2024)の「回答が長いデータが良い」という主張を日本語LLMかつ日本語データで検証します。
先行研究 (Zhao et al., 2024)
今年2月にarXivに公開され、7月のICML 2024に採択された論文(Zhao et al., 2024)では、「回答部分が特に長いサンプルだけをごく少数選択して指示学習する」というシンプルな方法が提案されました。
これまで高品質な少量サンプルを集めるためには、人手で慎重にデータを作成したり(Zhou et al., 2023)、ChatGPTに既存データを品質評価させて高品質なサンプルを抽出する(Chen et al., 2024)といった方法が採用されていました。一方で、この研究では「人間またはLLMが判断する品質の高さ」ではなく「回答の長さ」に基づいてデータを選択する戦略を提案しています。具体的には、データセットから回答が長い順にサンプルを選択するというシンプルなものです。この戦略の直感は、「回答が長いサンプルは学習可能な情報が多く含まれており、過適合(Overfit)しにくいだろう」というものです。
主要な実験結果を紹介します。ChatGPTを用いて自動生成した約52,000件のデータセット(Alpaca)を対象に、以下3つの設定で指示学習を比較しています。
- データセット全体約52,000件(Alpaca-52K)
- ChatGPTによる品質評価が最も高い1,000件(AlpaGasus-1k)
- 回答部分が最も長い1,000件(Alpaca-1k-longest)
- 人手で慎重に作成したデータセット1,000件(LIMA)
図1は、GPT-4およびPaLM2に、2つのモデルの回答の優劣を評価させた結果です。
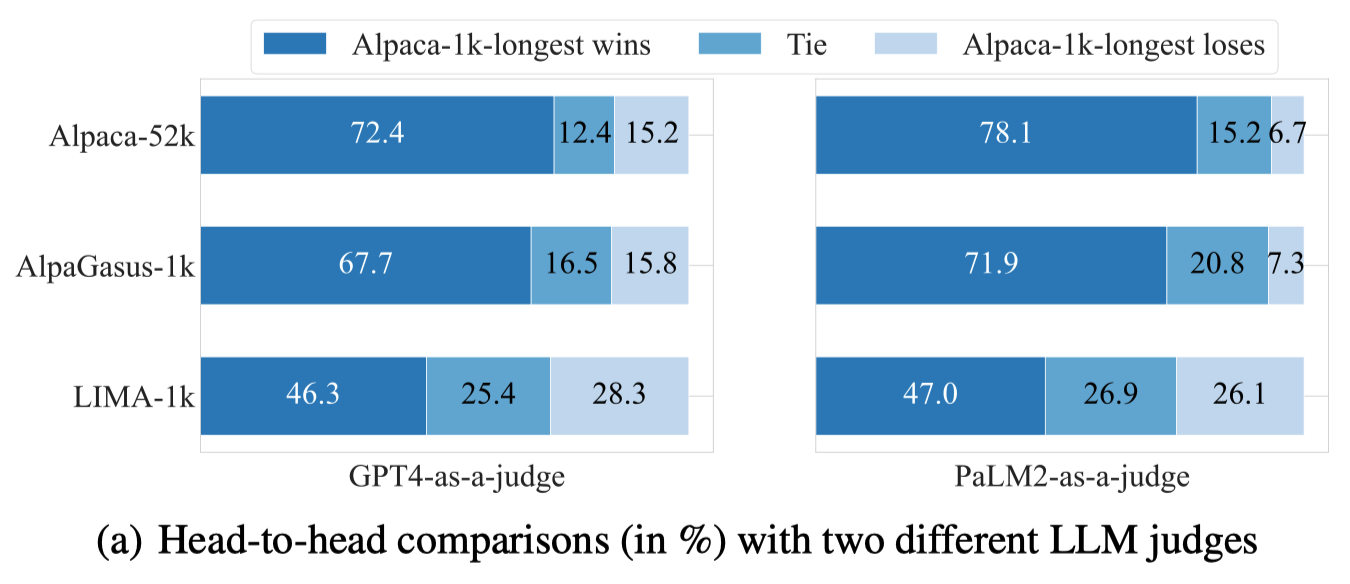
図1: モデル回答の優劣評価(Zhao et al. (2024)より)
提案手法(Alpaca-1k-longest)で指示学習を行ったLLaMA-2-7Bは、その他の設定(Alpaca-52K、AlpaGasus-1k、LIMA)に比べて、優れた回答を出力していると評価されました。
図2は、訓練時と評価時の回答の長さを示したものです。
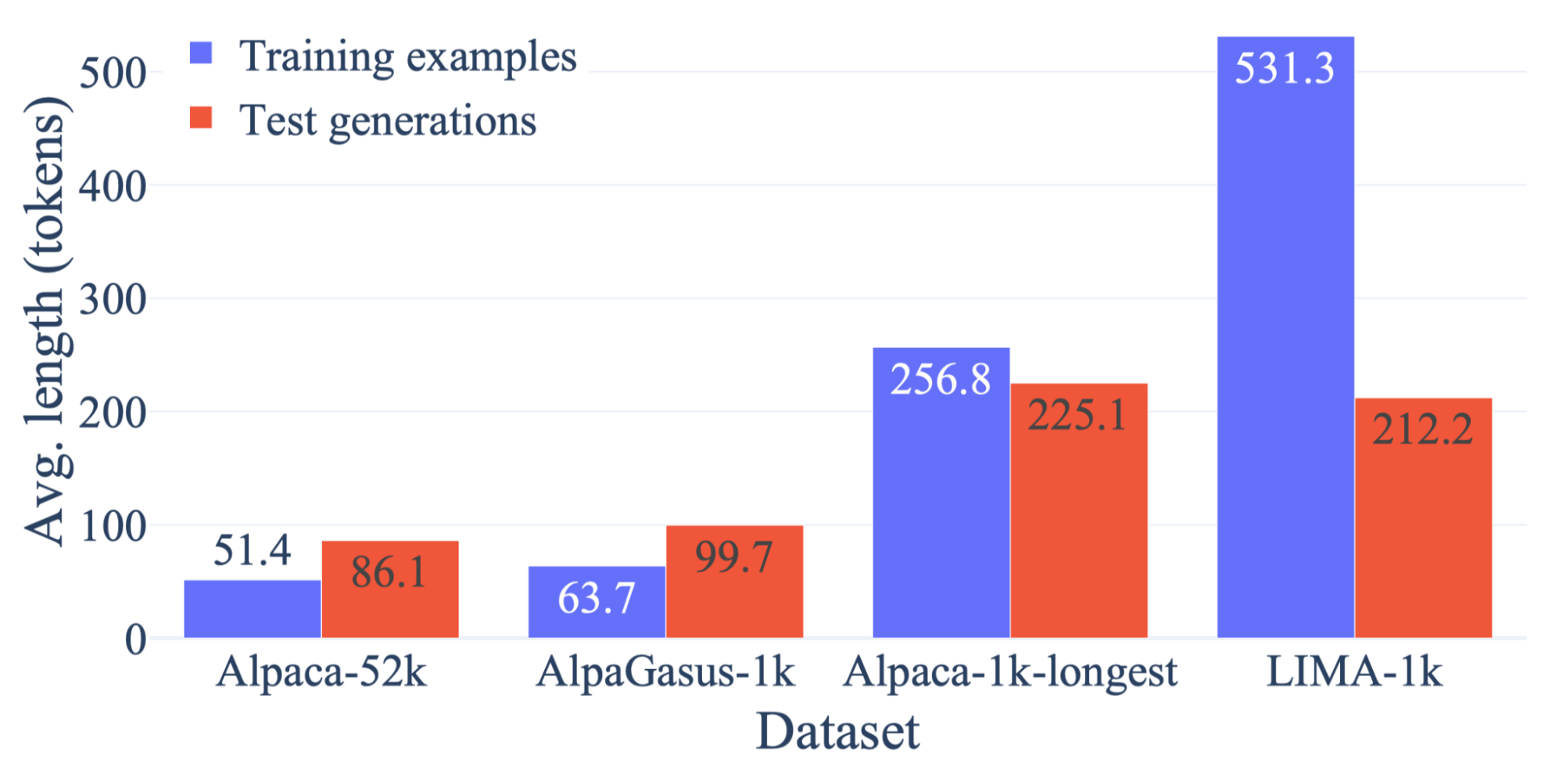
図2: 訓練データと評価時モデル出力の回答の長さ(Zhao et al. (2024)より)
回答が長いデータで訓練したモデルは、推論時に長い回答を出力する傾向にあります。GPT-4やPaLM2は、モデルの回答を評価する際に長い回答を好む傾向にあることが分かっていますが(Li et al., 2023; Zheng et al., 2023)、提案手法(Alpaca-1k-longest)はLIMAとほぼ同じ長さの回答を出力しつつも勝率で上回っており(図1)、回答の長さで過剰評価されているだけではないと主張しています。
以上の結果は「指示学習において回答部分が長いデータが良い」ことを示唆しています。本稿ではこの論文の結果について、日本語LLMかつ日本語データで検証を行います。
日本語LLMかつ日本語データでの検証
モチベーション
上で説明した通り、Zhao et al. (2024)は「指示学習において回答部分が長いデータが良い」ことを示唆しています。この知見は「指示学習ではデータの多様性や品質が重要である」というこれまでの考えとは異なるものであり、効率的なデータ選択や新たなデータ生成の良い指針となる可能性があります。しかし、この知見はどこまで一般化できるのでしょうか?例えば、日本語LLMで、複数の日本語データセットで、複数のベンチマークで、同様の結果は得られるのでしょうか?本稿ではこれらの観点について検証します。
実験設定
事前学習済み日本語LLMをいくつかの設定で指示学習し、ベンチマーク性能を比較します。
モデル
PFEでスクラッチから構築した10億パラメータの日本語LLMであるPLaMo-1B(※ 今回の実験で使用したPLaMo-1Bは、PLaMo-Liteとは異なる社内開発用のモデルです。)を用いました。これはPLaMo-100Bを構築するために整備したコーパスを用いて事前学習した比較的小規模なLLMであり、小規模ながらも高いベンチマーク性能を達成しています。事前学習段階では驚くべきことに昨年にPFNが公開したPLaMo-13Bよりも高いベンチマーク性能を達成しています。
データセット
指示学習に使うデータセットとして、日本語に機械翻訳されたAlpaca(fujiki/japanese_alpaca_data)と、ichikara-instruction(ver 004 Single)を用いました。AlpacaはChatGPTを用いて自動生成された英語の指示学習用データセットであり、今回はこれをChatGPTを用いて日本語に翻訳したものを用いました(以降では日本語翻訳版を指してAlpacaと呼びます)。ichikara-instructionは人手で作成された指示学習用データセットです(以降はIchikaraと呼びます)。データソースの違いが結果にどう影響を及ぼすのかを検証するためにこの2つのデータセットを採用しました。
それぞれのデータセットに対して、以下4種類の設定で指示学習を行います。
- All: データセット全体(Alpacaは52,002件、Ichikaraは11,008件)
- Longest: データセットから回答部分が最も長い1,000件を抽出
- Shortest: データセットから回答部分が最も短い1,000件を抽出
- Random: データセットからランダムに1,000件を抽出
それぞれのデータセットにおける、4種類の設定での回答部分の長さ分布を図3および図4に示します。設定同士を比較しやすくするために縦軸をlogスケールで表示していることにご注意ください。
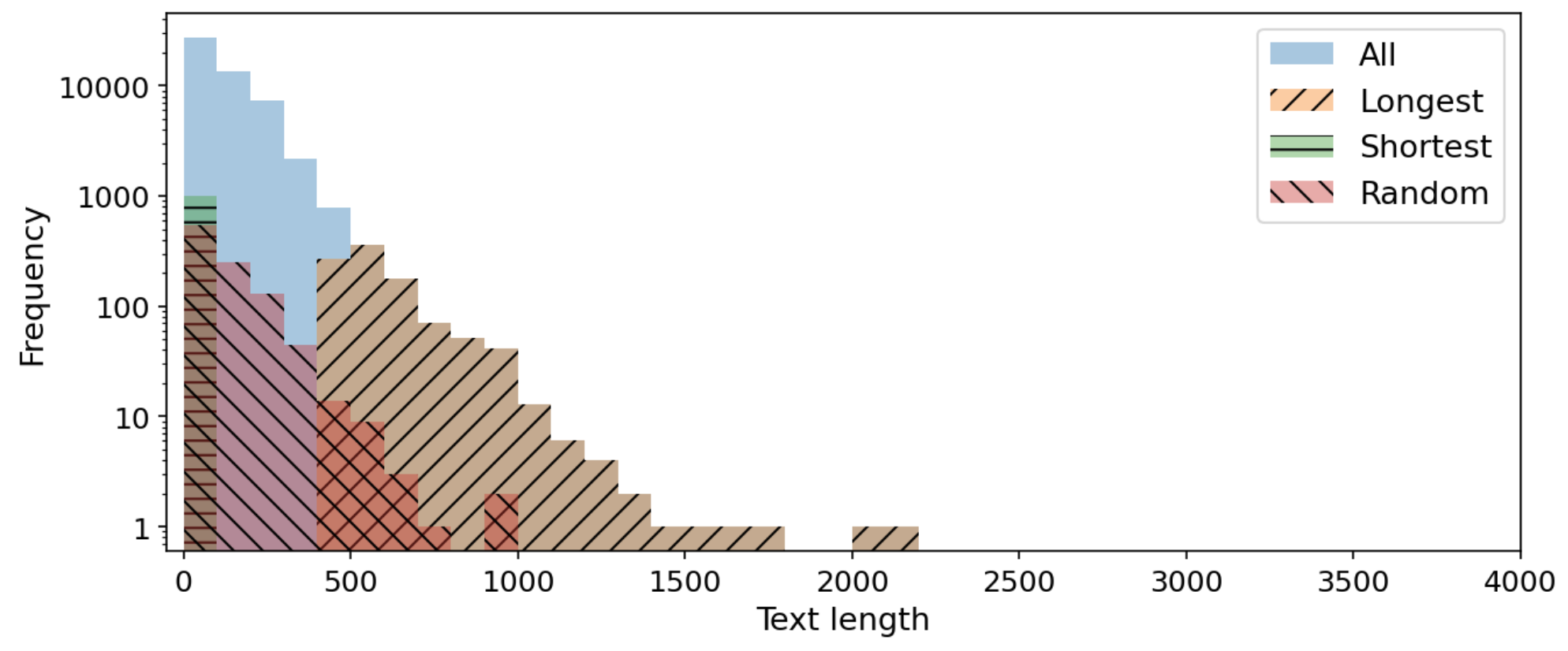
図3: Alpacaにおける回答部分の長さ分布
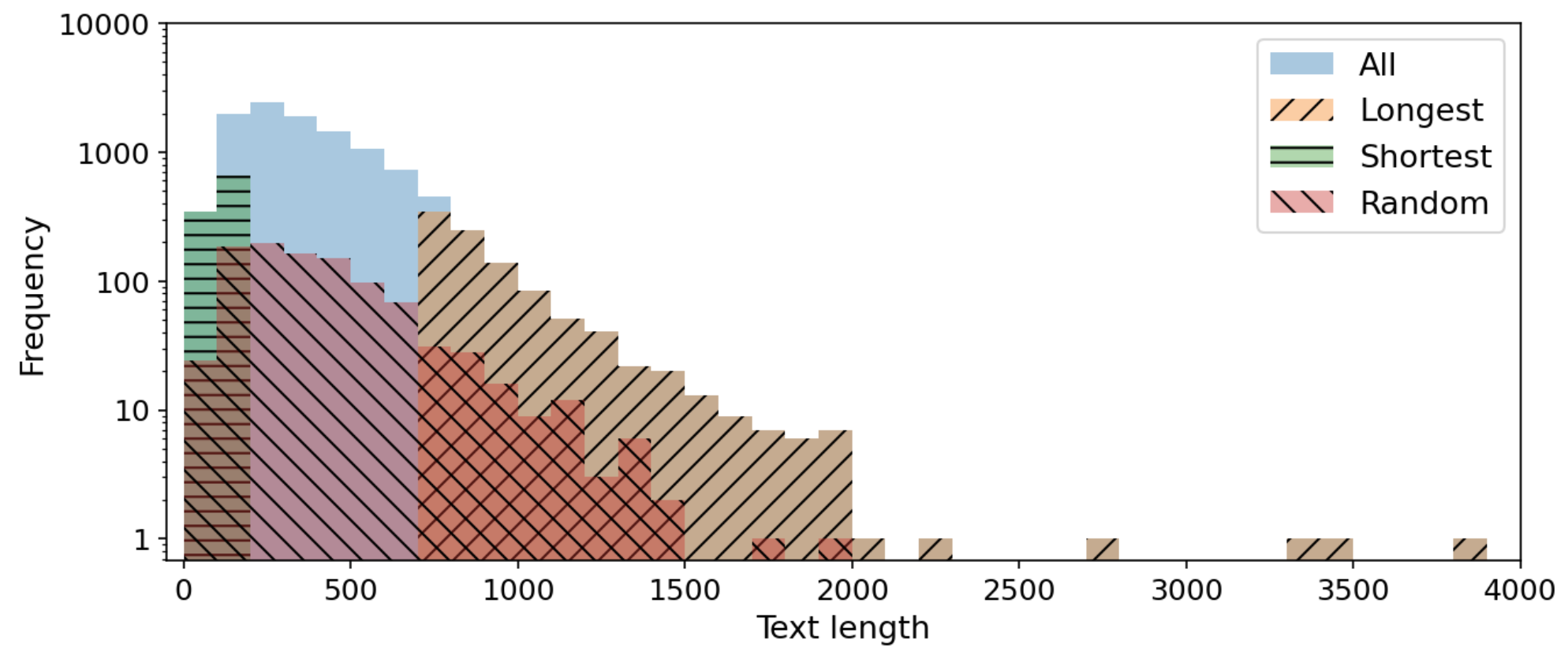
図4: Ichikaraにおける回答部分の長さ分布
どちらのデータセットも、回答の長さとサンプル数の間である程度の冪乗則が成り立っており、回答が短いサンプルが多く、回答が長いサンプルが少ないことが分かります。ただし、データセット間の違いとして、IchikaraはAlpacaに比べてやや回答が長めの傾向にあります。平均的な回答の長さは、Alpacaが123文字で、Icihikaraは393文字です。また、Ichikaraには回答が極端に短い(100文字未満)データがAlpacaに比べてあまり含まれていない特徴があることが分かります。
評価ベンチマーク
評価ベンチマークとして、Rakuda BenchmarkとJapanese MT-Benchを用いました。Rakuda Benchmarkは、日本の地理・政治・歴史・社会に関する質問に対してモデルに自由記述式で回答させ、GPT-4などに評価させます。Japanese MT-Benchは、8カテゴリ(Coding・Extraction・Humanities・Math・Reasoning・Roleplay・STEM・Writing)に渡る質問に対してモデルに自由記述式で回答させ、GPT-4などに評価させます。Rakuda Benchmarkは各質問1ターン、Japanese MT-Benchは各質問2ターンで構成されます。異なる評価観点と性質を持つベンチマーク間で比較するためにこの2種類を採用しました。今回は両ベンチマークとも、MT-Bench (Zheng et al., 2023) の評価フローに従い、GPT-4に1〜10点で評価させました。
結果
4種類の設定(All・Longest・Shortest・Random)での指示学習をベンチマーク性能で比較し、「回答部分が長いデータ(Longest)が日本語においても良いのか」を検証していきます。
Rakuda Benchmark 結果
2つのデータセット(AlpacaとIchikara)それぞれを使って、4種類の設定(All・Longest・Shortest・Random)で指示学習したPLaMo-1BのRakuda Benchmark性能を図5に示します。
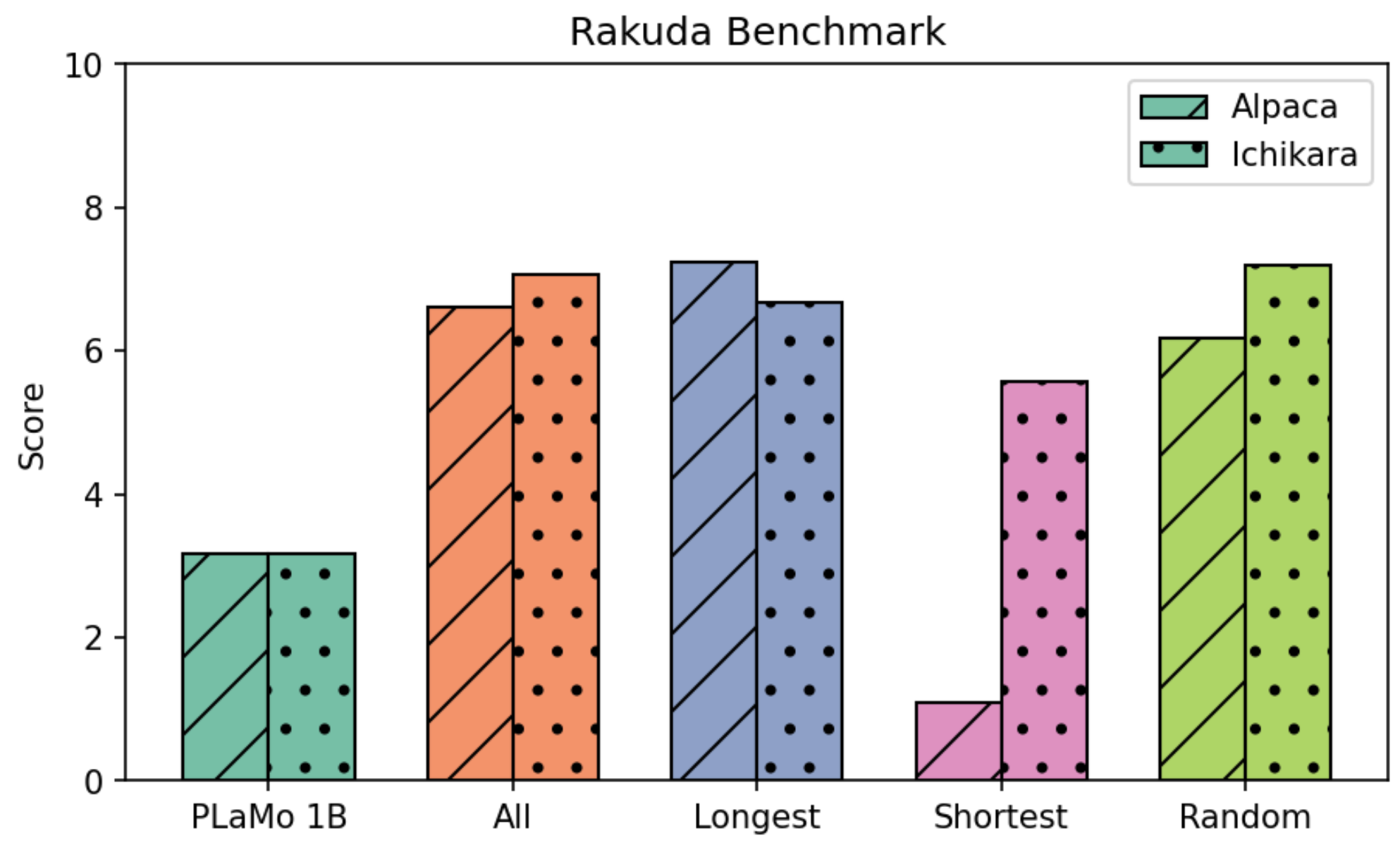
図5: PLaMo-1Bの指示学習前後におけるRakuda Benchmark性能
Alpacaにおいては、1,000件のみで指示学習したLongestが、52,002件で指示学習したAllよりも高い性能を達成しました。また、1,000件で指示学習をする設定の中でも、LongestはShortestおよびRandomよりも高い性能を達成しました。以上の結果から、AlpacaではZhao et al. (2024)が提案した「回答部分が長いサンプルを少量抽出して指示学習する戦略」の有効性が確認できました。
Ichikaraにおいては、1,000件のみで指示学習したLongestは、11,008件で指示学習したAllよりも少し低い性能となりました。また、1,000件で指示学習をする設定の中では、LongestはShortestよりも高い性能となった一方で、Randomよりは低い性能となりました。以上の結果から、IchikaraではZhao et al. (2024)が提案した「回答部分が長いサンプルを少量抽出して指示学習する戦略」の有効性は確認できませんでした。
Japanese MT-Bench 結果
Japanese MT-Bench性能を図6および図7に示します。8つのカテゴリごとに性能を算出しています。設定同士を比較しやすくするため、10点ではなく8点を最大として可視化していることにご注意ください。
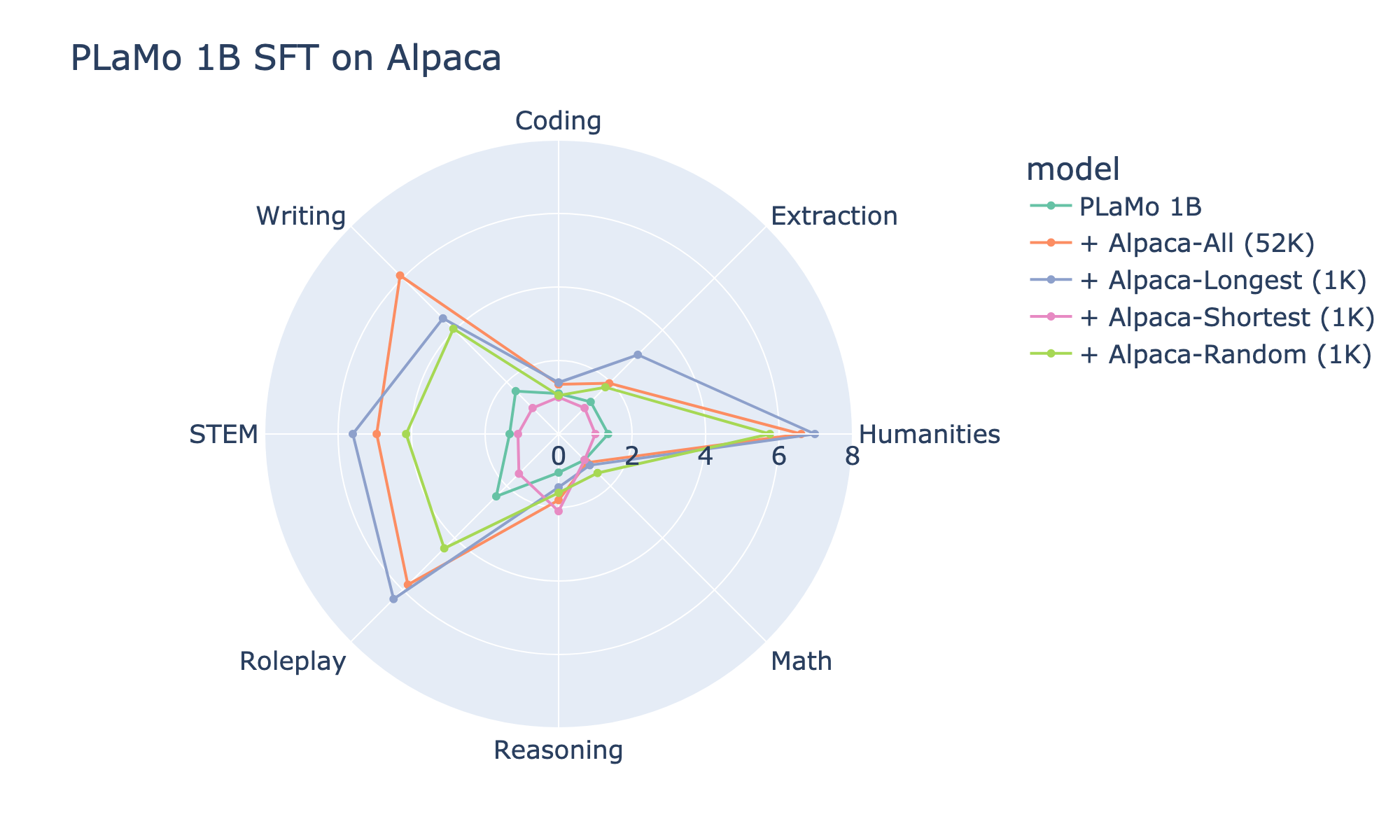
図6: PLaMo-1BをAlpacaで指示学習したモデルのJapanese MT-Bench性能
Alpacaにおいては、8つ中6つのカテゴリ(Coding、Extraction、Humanities、Math、Roleplay、STEM)で、1,000件のみで指示学習したLongestが、52,002件で指示学習したAllよりも高い性能を達成しました。また、1,000件で指示学習をする設定の中でも、Longestは8つ中6つのカテゴリ(Coding、Extraction、Humanities、Roleplay、STEM, Writing)で、ShortestおよびRandomよりも高い性能を達成しました。以上の結果から、Rakuda Benchmarkに引き続きJapanese MT-Benchでも、AlpacaではZhao et al. (2024)が提案した「回答部分が長いサンプルを少量抽出して指示学習する戦略」の有効性が確認できました。
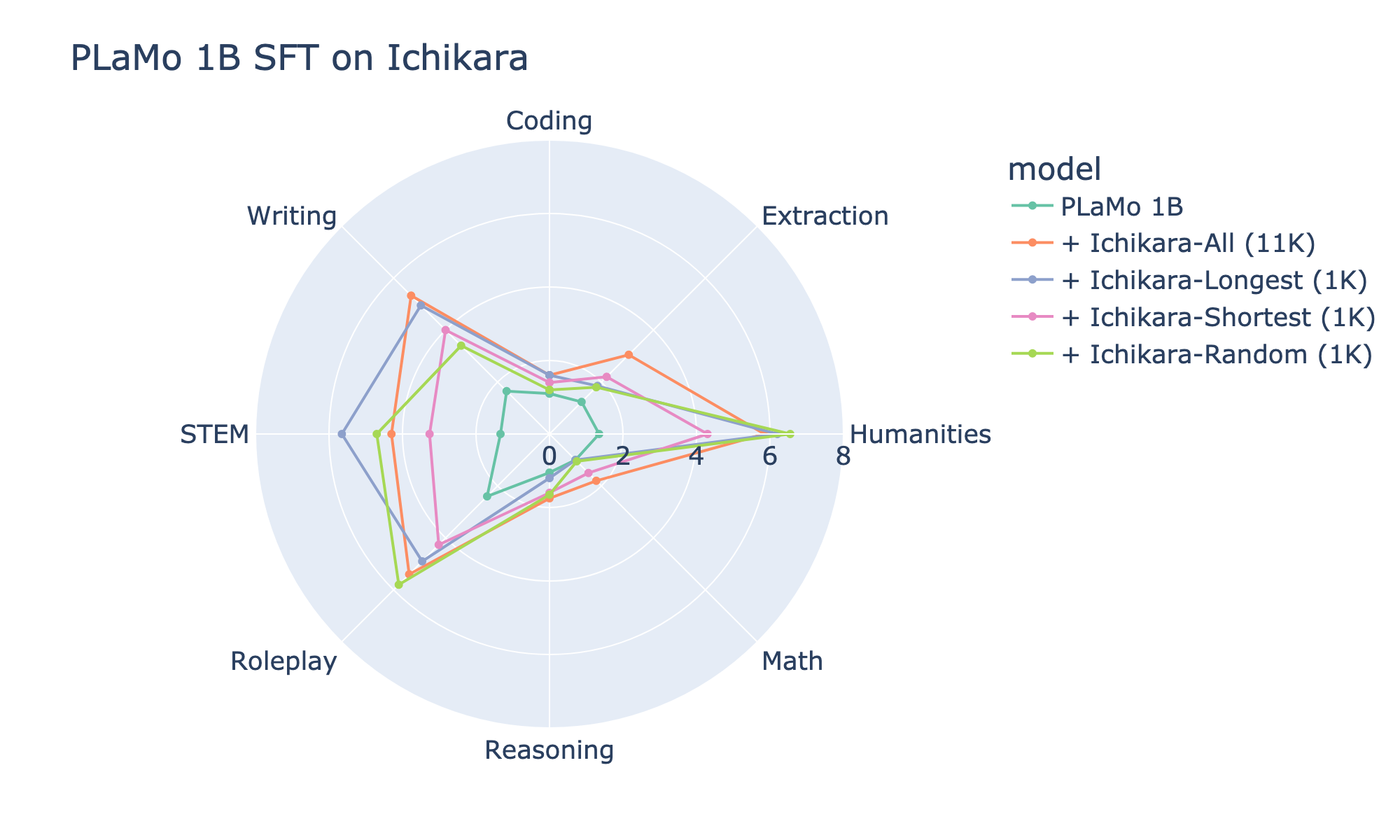
図7: PLaMo-1Bをichikara-instructionで指示学習したモデルのJapanese MT-Bench性能
Ichikaraにおいては、1,000件のみで指示学習したLongestが、52,002件で指示学習したAllよりも高い性能を達成したのは8つ中2つのカテゴリ(Humanities、STEM)だけでした。ほか1つのカテゴリ(Coding)ではAllと同じ性能で、残った5つのカテゴリ(Extraction、Math、Reasoning、Roleplay、Writing)ではAllよりも低い性能でした。また、1,000件で指示学習をする設定の中では、Longestが最も高い性能を達成したのは8つ中3つのカテゴリ(Coding、STEM、Writing)だけでした。ほか2つのカテゴリ(ExtractionとMath)ではShortestが最も高い性能となり、残った3つのカテゴリ(Humanities、Reasoning、Roleplay)ではRandomが最も高い性能となりました。以上の結果から、Rakuda Benchmarkに引き続きJapanese MT-Benchでも、IchikaraではZhao et al. (2024)が提案した「回答部分が長いサンプルを少量抽出して指示学習する戦略」の有効性が確認できませんでした。
結果まとめ
以上のように我々の検証の範囲では、Zhao et al. (2024)の「データセットから特に回答が長いサンプルを少量抽出して指示学習すると良い」という主張は、2つのベンチマークで一貫してAlpacaでは成り立ち、Ichikaraでは成り立ちませんでした。
分析・考察
回答の長さが指示学習とベンチマーク性能にどう影響しているのかを、より詳細に理解するためにいくつかの分析を行いました。
指示学習データと指示学習後モデルの回答の長さ
まずは2つのベンチマークに対する、指示学習前後の各モデルの平均的な回答の長さを図8および図9に示します。
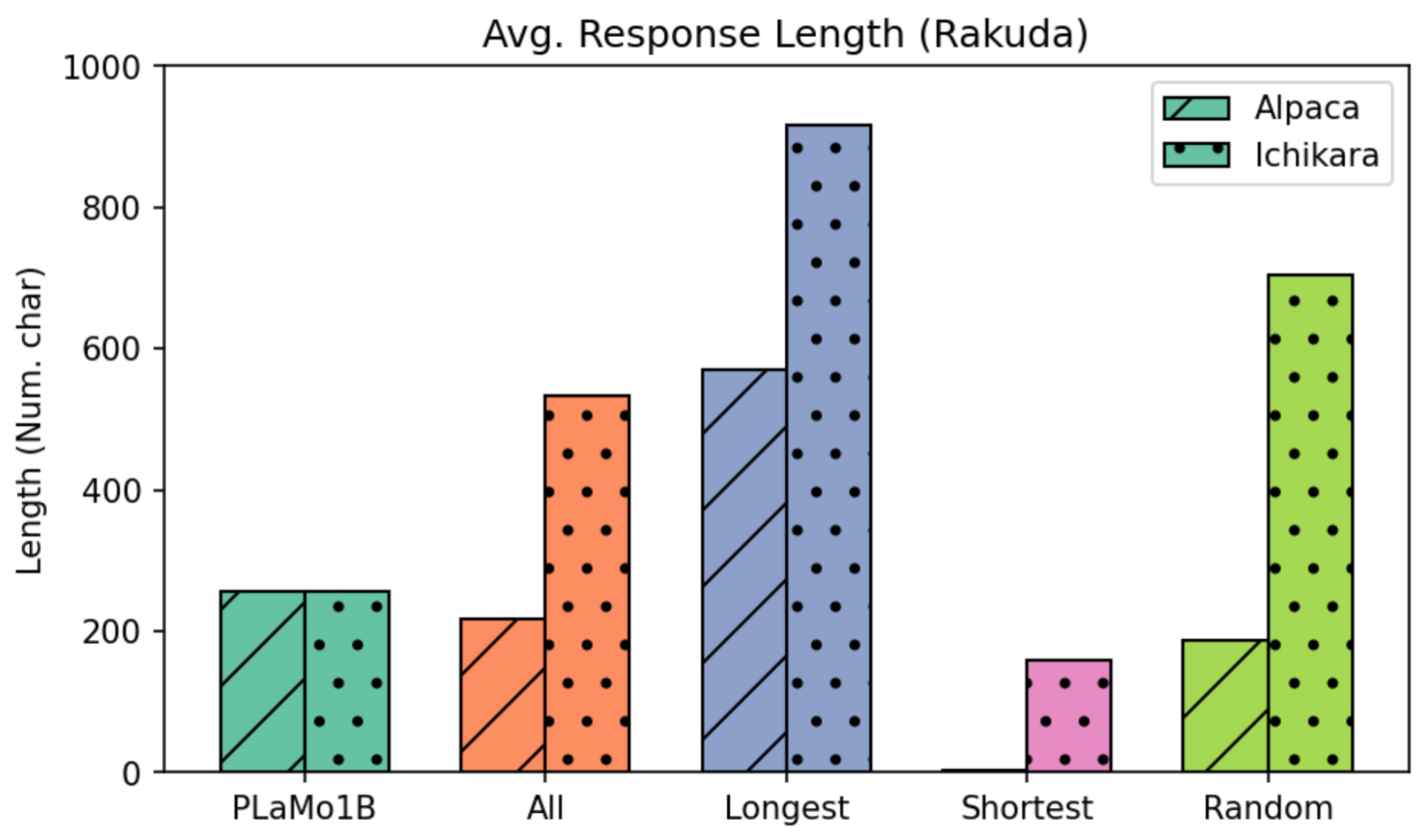
図8: Rakuda Benchmarkに対する平均的な回答の長さ
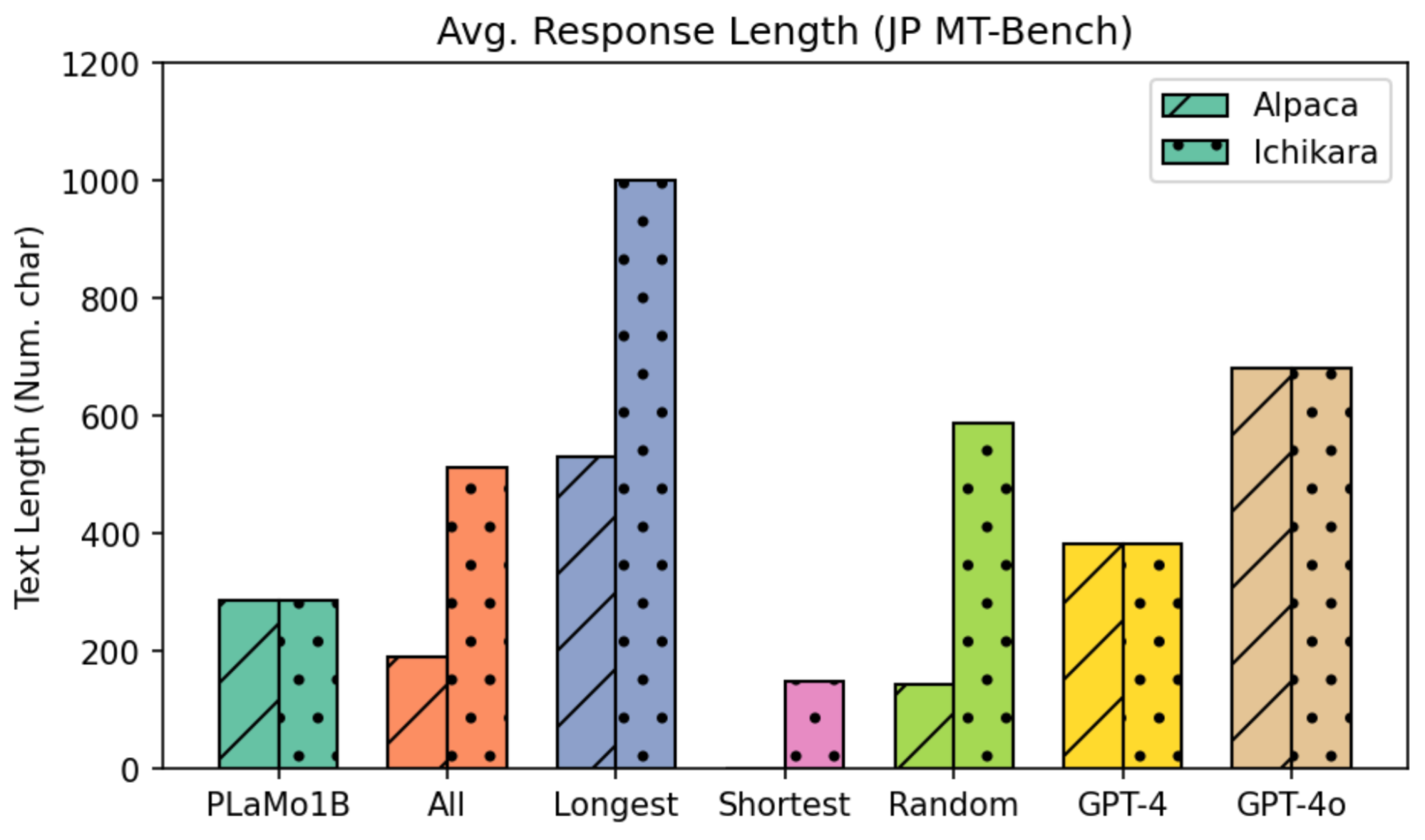
図9: Japanese MT-Benchに対する平均的な回答の長さ
モデルが出力する回答の長さは、当然、指示学習に用いたデータの回答の長さに依存しています。前述した通り、AlpacaとIchikaraでは回答の長さが大きく異なる(123文字 vs. 393文字)ため、指示学習後モデルの回答の長さもデータセットによる差が大きくなっています。例えば、Ichikara-ShortestはAlpaca-Randomと同等の長さの回答を出力し、Icikara-RandomはAlpaca-Longestと同等以上の長さの回答を出力します。つまり、IchikaraではRandomでの指示学習でも十分に長い回答が出力されるようになっています。
回答の長さとベンチマーク性能の関係
続いて、回答の長さとGPT-4の評価スコアに相関があったのかを調査します。前述した通り、GPT-4はモデルの回答を評価する際に長い回答を好む傾向にあることが報告されています(Li et al., 2023; Zheng et al., 2023)。ここでの調査は、Rakuda BenchmarkおよびJapanese MT-Benchの質問に対する日本語の回答を評価するケースでも、同様の傾向があるのかを確認することに相当します。本稿で実験対象とした全てのモデルの回答とその評価スコアから算出した、回答の長さとGPT-4による評価スコアの相関を表1に示します。

表1: 回答の長さとGPT-4による評価スコアの相関
まず、ベンチマーク全体での相関に着目すると、Rakuda BenchmarkとJapanese MT-Benchの両方において、回答の長さとGPT-4の評価スコアの間に相関が見られました(スピアマン相関で0.502と0.260)。つまり、今回の実験において両ベンチマークでは長い回答ほど高い評価スコアがつけられる傾向にありました。これは、我々の実験結果をうまく説明できるかもしれません。回答が短いサンプルを多く含み、平均的にも回答が短めのAlpacaでは「特に長い回答だけを抽出する戦略」が有効だったと考えられます。一方で、回答が短いサンプルが比較的少なく、平均的にも回答が長めのIchikaraでは「特に長い回答だけを抽出する」という戦略はそこまで有効ではなかったと考えられます。
続いて、Japanese MT-Benchのカテゴリ別に見ていくと、カテゴリ間で大きな差があることがわかりました。Humanities、Roleplay、STEM、Writing では相関が見られる(回答が長いほど評価が高い)一方で、Coding、Extraction、Math、Reasoningではほぼ相関がありませんでした(回答の長さと評価スコアに関係がない)。ベンチマーク結果では、確かにLongestがHumanitiesとSTEMで高い性能を発揮する傾向にあり、Extraction、Math、ReasoningではShortesetやRandomに劣るケースがありました。
ここまでの結果から、現状の自動評価においては、指示学習データの回答が長ければ長いほど良いというわけでもなく、一定以上の長さのサンプルを多めに含んでいることが重要であると考えられます。そのため「既存データセットから特に回答が長いサンプルを抽出して指示学習する戦略」が有効かどうかは、元となるデータセットの長さ分布次第で大きく変化すると思われます。人手評価などを通して回答の長さを評価から切り離すことは今後の重要な課題と言えます。
回答の長さとデータセット品質の関係
実験結果をよく見てみると、実はAlpaca-Shortestでの指示学習はほとんど性能劣化をもたらしています。この原因として、回答が短いサンプルには低品質なものが多く含まれている可能性が考えられます。例えばAlpacaの回答が短いサンプルを観察してみると、以下のように回答が存在しないサンプルが28件も存在しています。これは日本語への機械翻訳前のAlpacaでも指摘されています。
- 例1
- 指示: “過去5年間における人工知能の発展を示すタイムラインを作成してください。”
- 入力: “”
- 出力: “”
- 例2
- 指示: “2000年8月9日に生まれた人の年齢を計算してください。”
- 入力: “入力なし”
- 出力: “”
- 例3
- 指示: “以下の形状の面積を平方センチメートルで計算してください。”
- 入力: “4cm x 5cmの長方形”
- 出力: “”
また、LLMに自動生成させたデータセットであるAlpacaと人手で作成したデータセットであるichikara-instructionを比べると、AlpacaではShortest設定およびRandom設定の低さが目立ちました。LLMで自動生成させたデータには「回答の長さ(LLMが生成した回答の長さ)」と「回答としての品質の良さ」に相関があるのかもしれません。この観点での詳細な調査は今後の展望の一つです。
今後の展望
今回の実験では、Longest・Shortest・Randomの3つの設定の間で訓練サンプル数(1,000件)を統一して比較を行いました。訓練トークン数に換算すると設定間でかなり大きな差が生まれてしまいます。訓練トークン数でデータ量を統一して比較を行うことは今後の展望の1つです。
また、今回はデータセット内のサンプルの多様性について分析・考察していません。例えば、回答が長いサブセットの方がトピックが多様なのか、といった調査も重要です。
参考文献
- [Zhao et al., 2024] Hao Zhao, Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion. “Long Is More for Alignment: A Simple but Tough-to-Beat Baseline for Instruction Fine-Tuning.” ICML, 2024. https://proceedings.mlr.press/v235/zhao24b.html
- [Zhou et al., 2023] Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, LILI YU, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, Omer Levy. “LIMA: Less Is More for Alignment.” NeurIPS, 2023. https://openreview.net/forum?id=KBMOKmX2he
- [Chen et al., 2024] Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, Hongxia Jin. “AlpaGasus: Training a Better Alpaca with Fewer Data.” ICLR, 2024. https://openreview.net/forum?id=FdVXgSJhvz
- [Li et al., 2023] Xuechen Li and Tianyi Zhang and Yann Dubois and Rohan Taori and Ishaan Gulrajani and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto. “AlpacaEval: An Automatic Evaluator of Instruction-following Models.” GitHub repository, 2023. https://github.com/tatsu-lab/alpaca_eval
- [Zheng et al., 2023] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, Ion Stoica. “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.” NeurIPS Datasets and Benchmarks Track, 2023. https://proceedings.neurips.cc/paper_files/paper/2023/hash/91f18a1287b398d378ef22505bf41832-Abstract-Datasets_and_Benchmarks.html
Appendix
指示学習の詳細設定
指示学習では、データセット全体(All)と1,000件(Longest・Shortest・Random)の設定で同じ学習パラメータを採用しています。ただしZhao et al. (2024)に倣い、エポック数のみデータセット全体では“5”、1,000件では“15”に設定しました。
謝辞
テーマ決定から本ブログの執筆まであらゆる試行錯誤において親身に相談に乗ってくださり、常に的確なフィードバックとアドバイスをくださった山口さん、林さん、片岡さんに心よりお礼申し上げます。また、計算機環境を整備してくださった皆様、助言をくださったLLMチームの方々に感謝申し上げます。
Tag



