Blog
はじめに
Preferred Networks (以下PFN) とグループ会社のPreferred Elements (以下PFE) では2024年10月から2025年4月に実施されたGENIAC 第2期において、大規模言語モデルPLaMo 2シリーズの開発を行いました。この記事では事後学習の取り組みについて紹介します。PLaMo 2 Primeのリリースについては PLaMo 2.0 Prime リリース – Preferred Networks Research & Development を参照してください。事前学習については、以下の記事を参照してください:
- 大規模言語モデルの次期バージョン PLaMo 2 31Bの事前学習 – Preferred Networks Research & Development/a>
- LLMによる大規模な事前学習データセット生成システムの構築と運用 – Preferred Networks Research & Development
- 大規模言語モデルPLaMo 2 31Bを活用した8Bモデル開発 – Preferred Networks Research & Development
この開発は経済産業省及び国立研究開発法人新エネルギー‧産業技術総合開発機構(NEDO)が実施する、国内の生成AIの開発力を強化するためのプロジェクト「GENIAC(Generative AI Accelerator Challenge)」の支援を受けて実施しました。
PLaMo 2の事後学習では、GENIAC第1期で開発したPLaMo-100B-Instructの事後学習で用いたSupervised Finetuning (SFT) とDirect Preference Optimization (DPO) の学習パイプラインを継承しつつ、モデルの性能向上のために複数の改良を導入しました。主な改良点として、long-context対応のための継続事前学習、LLMを用いた高品質な日本語合成データセットの生成、およびアルゴリズムの改善(SFT後・DPO後両方でのModel Merge, DPO拡張)が挙げられます。
Long-contextサポートのための継続事前学習
本節では、PLaMo 2の初期事前学習後に行った、より長いコンテクストを扱えるようにするための継続事前学習(Continual Pre-training、以下CPT)について紹介します。まず、PLaMo 2のアーキテクチャが持つ長文脈検索における課題を特定し、その解決のために採用したアーキテクチャの変更と学習手法、そしてその評価と最終的なモデル選択のプロセスについて説明します。
SSM-SWAアーキテクチャにおける検索能力の限界
PLaMo 2は、計算効率とスケーラビリティを重視し、Sambaアーキテクチャに着想を得たハイブリッドモデルを採用しています。このアーキテクチャは、Selective State Space Model(SSM)とSliding Window Attention(SWA)を交互に配置する構成を取っています。この設計の意図は、SSMが持つ線形時間の計算量、効率的な逐次処理、安定した系列長の外挿能力と、SWAが持つ局所的だが複雑な非マルコフ的依存関係を捉える能力を組み合わせ、それぞれの長所を活かすことにありました(Ren et al., 2025)。これにより、純粋なTransformerモデルが抱える計算量が入力の長さの二乗で増加していく問題や、推論時のKVキャッシュ増大による大きなメモリ消費といった課題を緩和することを目指しました。
しかし、事前学習後のPLaMo 2の初期評価の段階で、このアーキテクチャが持つ根源的な制約が明らかになりました。特に、Needle-in-a-Haystack型のタスク、すなわち長い文脈の中から特定の情報を正確に検索・抽出する能力において課題が見られました。具体的には、Phonebookタスク(Jelassi et al., 2024)およびPasskey Retrievalタスク(Mohtashami et al., 2023)において、検索対象の情報が出力トークンからSWAのウィンドウサイズである2048トークンを超えて離れている場合に、モデルは一貫してタスクに失敗しました (図1)。このことから、SWAの固定ウィンドウサイズが情報アクセスの障壁となっている可能性が示唆されました。
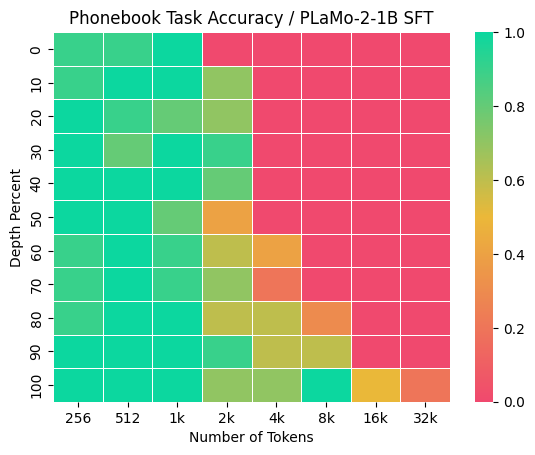
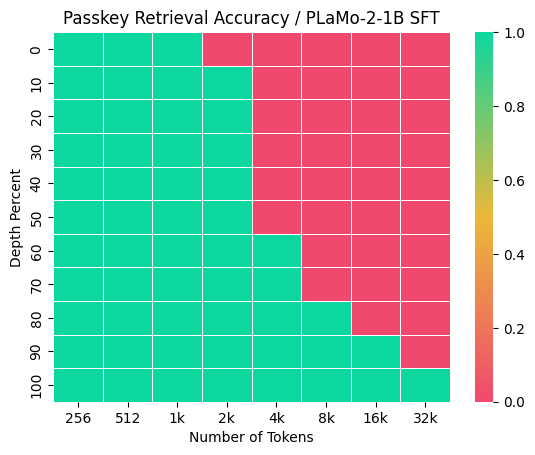
図1: Plamo 2-1B SFTモデルのPhonebookとPasskey Retrievalの結果
この課題は、PLaMo 2固有のものではなく、SSMやSWAに共通する特性に起因すると思われます。SSMは、その構造上、過去の情報を固定長の隠れ状態に圧縮して伝播させるため、特定の情報を損失なく保持し続けることが原理的に難しいことが知られています(Jelassi et al., 2024)。その強みは情報の要約と圧縮にあり、任意の位置にある情報のhigh-resolution recallではないためです(Dong et al., 2024)。この点は、純粋なSSMアーキテクチャであるFalcon3-Mambaモデルに対して我々が独自に行った評価でも確認されました。Falcon3-Mambaは、Passkey Retrievalタスクに対しては完璧な性能を見せたものの、Phonebookタスクにおいては1kトークン程度の短い文脈長の場合ですら良い性能を示すことができませんでした (図2)。このことから、SSMがこの種のタスクを根本的に苦手とすることが示唆されます。この観察は、純粋なSSMやSWAのみを用いたモデルが「Needle-in-a-Heystack型のタスク(long-context information retrieval)ではfull attentionに劣るようだ」とする一部の研究の主張とも一致します(Wu et al., 2024)。

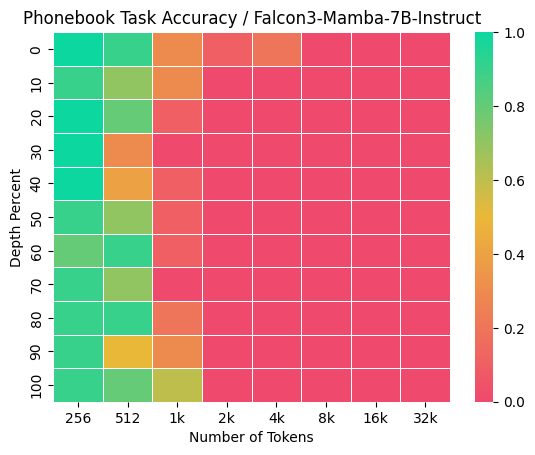
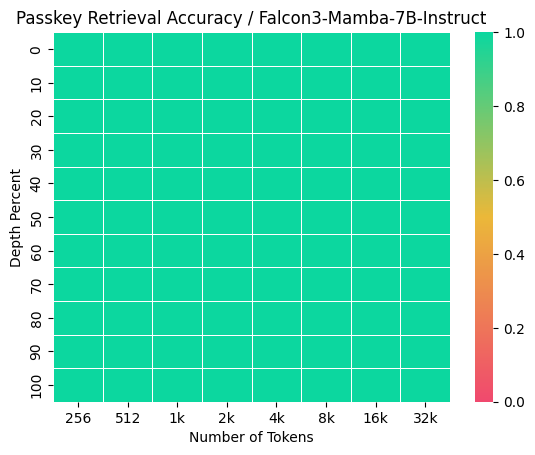
図2: Falcon3-Mamba-7B-InstructのPhonebookとPasskey Retrievalタスクの結果
これらの分析から、PLaMo 2によるPhonebookタスクの失敗は、単なる学習不足やチューニングの問題ではなく、SSMに共通する特徴と、Attentionレイヤーで視野を局所化するSWAというアーキテクチャそのものに根差した制約である可能性が浮上しました。したがって、この検索能力の欠如という課題を克服するために、既存アーキテクチャのまま学習を続けるのではなく、アーキテクチャ自体に手を入れる、より踏み込んだアプローチが必要であると結論付けました。
フルアテンションの採用
前述の検索能力の限界を克服するため、我々はlong-context対応に特化したCPTフェーズを設計し、その中でアーキテクチャに的を絞った変更を行いました。具体的には、PLaMo 2のSWA層のウインドウ幅を、対応したいコンテクスト長まで拡大した上で、継続事前学習を行うことにしました。これは、SWAがもたらす線形時間の計算効率という利点をこの特定の学習フェーズにおいて意図的に放棄し、モデルに文脈全体への無制限なアクセス権を与えることで、high-resolution recall能力の獲得を優先する判断でした。
継続事前学習の詳細
Long-context対応のための継続事前学習は、基本的にnext token predictionの精度を向上するように行われたため問題設定としては事前学習と同様でした。しかしアーキテクチャ的な変更だけでなく、使用したデータセットや学習設定にも違いがあったため、以下にそれらをまとめます。
データセット
CPTに用いたデータセットには、事前学習で使用したコーパスのサブセットを採用しました。これにより、データ分布の一貫性を保ち、一般的な知識の破滅的忘却のリスクをできるだけ抑えることが意図されています。
RoPE Frequency
コンテクスト長を事前学習時の2kから32kへと拡張するための中核技術として、位置エンコーディングにAdjustable Base Frequency RoPE (ABF RoPE) (Xiong et al., 2024) を利用しました。今回は32Kのコンテクスト長に対応するため、RoPEの基底周波数を決定するパラメータ(rope_theta)をGemma-3と同様に(Gosthipaty et al., 2025)、1,000,000に設定しました。
実証的評価とチェックポイントの選定
CPTプロセスの有効性は、実証的な評価を通じて検証され、最終的なモデルの選定は、複数の性能指標間のバランスを考慮して行われました。
目標タスクにおける性能向上
SWAのウインドウサイズを変更した上でCPTを行ったことの直接的な効果は、目標としていたPhonebookタスクの性能に明確に現れました。どのサイズのモデルでも、1Bトークン程度のCPTで十分に大きなPhonebookタスクにおける性能向上が見られ始めました。PLaMo 2-31B の継続事前学習直後の Phonebook における精度は図3 のようになりました
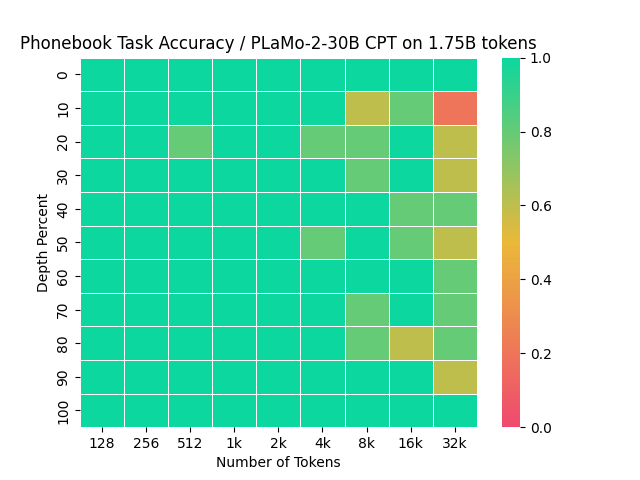
図3: PLaMo 2-31B の継続事前学習後のPhonebook Task Accuracy
チェックポイント選定
最終的なモデルの選定は、単にPhonebookベンチマークのスコアが最大となった時点のチェックポイントを選ぶというやり方では行いませんでした。長い系列の中から特定の情報を抽出する能力を強化した一方で、モデルの汎用的な言語能力が損なわれてしまうことは望ましくありません。我々は0.25Bトークンごとにチェックポイントをとり、それらに対してPhonebookタスクのスコアと、より一般的な日本語文章生成能力を測るベンチマーク(pfgen-bench)のスコアを算出し、最も良いバランスにあるものを選びました。
一般的な長文脈タスクへの影響
このCPTによるlong-context対応は、ターゲットとしたPhonebookタスクだけでなく、より広範な長文脈タスクの性能向上にも寄与しました。例えば、2BモデルではCPTとそれに続くSFTによりLongBenchのスコアが大幅に向上し、競合モデルであるQwen2.5-1.5Bを上回る結果となりました。この結果は、このCPTフェーズによって獲得されたhigh-resolution recallの能力が、多様な長文脈応用タスクに汎化する可能性を示唆しています。
データセット
本節では、PLaMo 2 の事後学習のデータセットに関する取り組みについて、特に PLaMo 2 のために新たに行ったものについて紹介します。
PLaMo 2 では日本語の高品質な事後学習用データセットの不足を補完するため、LLMにより生成したデータセットを多く使用しました。一例として、指示追従能力の向上のためのデータセットを作成しました。ランダムな質問と出力形式についての指示の組み合わせを元にLLMでデータで指示付きの質問と回答を生成し、指示についての機械的な検証と回答の質についてのLLM-as-a-Judgeによってフィルタリングすることでデータセットを作成し、SFTとDPOで使用しました。さらに、データセットの多様化のために、以下の2つのオープンソースライセンスで公開されているデータセットに対して、LLMを用いてデータ生成を行いました。
llm-jp-instructions
まずllm-jp-instructionsで公開されているプロンプトを利用しました。元のデータセットでは人手でつけられた応答が利用できるのですが、マークダウンの文法エラーが一部にあったため、全ての応答文をLLMで生成し直しました。生成した応答文の中で、存在しないURLが含まれているなど明らかな問題のある応答については除外しました。
Wildchat-1M
SFT
マルチターンの会話データセットとして、Wildchat-1M のユーザ発話を利用しました。アシスタント発話はChatGPT が利用されており、OpenAIの利用規約に抵触する恐れがあるため、LLMを用いて生成しました。前処理として、データセットに付与されている日英以外の言語が付与されているデータは除外しました。
さらに、SlimPajama と似た方法でユーザー発話の重複除去を行いました。具体的には、ノードが1つのユーザの発話系列からなる類似度グラフを作りました。類似度が0.8 以上であればエッジが貼られます。それぞれの連結部分グラフごとにランダム1つのノードを選び、それ以外のノードは重複したものとして除外しました。類似度の計算には、発話系列に対して前処理後に文字の13-gram のminhashの特徴量を使いました。さらに類似度の計算高速化のためにfaissを使いました。
日本語における会話データを増やすために、上記で生成した英語の会話データを日本語に翻訳しました。この時に使用したのは、PLaMo 翻訳のプロトタイプです。各例に対して16個の翻訳を生成し、そのなかでMetricX-24のスコアが高いものを採用しました。
DPO
上記で生成したSFTのデータセットを使って、DPOで使用するデータを作成しました。PLaMo 2.0-31Bで指示学習を行なったモデルで応答を生成しました。具体的には、まず報酬モデルのNemotron4-340B-reward でサポートしていない 4096トークン以上の発話を除外してから、最後のアシスタント発話を指示モデルを使って6つ生成し、すでにある応答と合わせて7つの中から報酬モデルが付与する報酬値の最も高い応答をchosen、低いものをrejectedをペアとしてDPOのデータセットを構築しました。ただし、chosenとrejectedの報酬値があまりに近いペアについては学習効率を下げる恐れがあるので、除外しました。
On-policyで応答を生成したほうがoff-policyで応答を集めてから学習で利用するよりも学習の効率が良いことがTang et al. (2024) などで実験的に指摘されています。このため、Wildchat-1Mの翻訳データセットに関しては、DPOのchosenをSFTのデータとして最終的なデータとして採用しました。このようなDPOのデータの一部をSFTデータとして混ぜることは、事前実験においても有効でした。
事後学習方法の工夫
本節では、PLaMo 2 の事後学習に関してデータセット以外で導入した工夫を紹介します。
Chat Template
ユーザーとアシスタントの会話をLLMに入力するためにchat templateが用いられます。マルチターンの会話も対応するため複数の文字列を1つのトークン列にエンコードするのですが、発話者をどう表すかやprefix, separatorなどを決めることになります。
PLaMo 1.0 では Alpaca とよばれる Markdown に似た形式を使っていました。特にここでのseparatorはMarkdownのh3と同じ "\n\n### " です。今回は ChatML を参考に、separatorを専用のトークンにしました。PLaMo 2.0 の事前学習では特殊トークン <|plamo:op|> を用いてエンコードされた多様なデータセットを学習しており、その中には質問回答のデータもこの形式で含まれています。このため事前学習モデルの時点で一定のchat性能があり、このトークンを用いたchat templateでの事後学習につなげることができたと考えられます。
トークン数の節約という観点では少しの差ですが、Markdown形式での入出力のときにLLMが混乱しにくくなることが期待されます。
また Jaster ベンチマークのように、指示 (instruction) と入力 (input) が明確に区別されているタスクを解くことにも対応できるようにしました。これを会話と見做すとき、入力をユーザー入力と扱い、指示を上位ロールの入力(システムプロンプト)と扱う方法と、指示をユーザー入力として扱い、タスク入力を文脈情報として扱う方法が考えられますが、後者にしました。chat APIでの(エンコード前の)ロール名としては "input" は非標準的なのですが、chat templateとしてはAlpacaでも採用されており、PLaMo 2.0の事前学習とも整合性がありました。たとえば、事前学習でデータ変換タスクの入出力をinput, outputでタグ付けしていましたが、今回のchat templateの立場からはinput, outputというロール名での会話と一致します。
SFT段階でのmodel merge
効率的なSFTの学習パイプラインのために、異なるデータセットで複数のSFTを実行してからその結果をmodel soup でマージする手法を取り入れました (Cohere, 2025)。このような方法であれば、全てのデータセットを合わせた一度のSFTで利用するよりも並列実行などが容易になります。今回は上記で記述した一般的なSFTのデータセットと、数学とコーディングのドメインが支配的な公開データセットであるllama-nemotron-post training dataの非推論データを利用しました。ただし、OSSライセンスではない応答については全て除外しました。Cohere (2025) を参考に一般的なSFTのデータセットを10%ほど混ぜて、残りをおおよそ同じトークン数になるようにサンプリングした上で、SFTを行い、model soupによるmodel mergeしました。
DPOの拡張
SFT後のマージモデルをベースにさらにDPOによる学習を行いました。この際、DPOのロス関数に対する拡張として、出力が長くなりすぎるのを抑えるための正則化 (Park et al., 2024) を加えました。また、chosen responseについてのSFTロスを加えること (Pang et al., 2024) も特定タスクでの性能劣化を防ぐために有効でした。DPO後にも、複数の設定で学習したモデルに対してmodel mergeを行いました。
評価
事後学習後の PLaMo 2.1-8B および PLaMo 2.0-31B の性能の評価を行いました。モデルの性能評価には Jaster, M-IFEval Japanese, Elyza Tasks 100, pfgen-bench を用いました。PLaMo 2.1-8B モデルの比較対象として、同サイズ帯で Open-weights なモデルの Qwen2.5-7B-Instruct, Qwen3-8B, Llama-3.1-8B-Instruct、PLaMo 2.0-31B の比較対象として、PLaMo の前バージョンにあたる PLaMo 1.0 Prime (PLaMo 100B) と、同サイズ帯で Open-weights なモデルの Qwen2.5-32B-Instruct, Mistral-Small-3.1-24B-Instruct-2503, gemma-3-27b-it、OpenAI の gpt-4o-mini についても評価を行いました。
Jaster
Jaster は複数のデータセットを利用して日本語 LLM の性能を評価するベンチマークです。短答式で日本や日本語に関する知識を問う問題を中心に構成されています。
今回の評価では v1.4.1 を使用し、temperature=0 かつ completion mode で生成を行いました。completions API が提供されていない gpt-4o-mini のみ prompt を single turn の chat として chat completions API を用いて生成を行っています。4-shot での平均スコア (AVG) と各カテゴリでのスコアは表1, 2のとおりです。
| Model_name | AVG | EL | FA | HE | MC | MR | MT | NLI | QA | RC |
| PLaMo 2.1-8B | 0.62556 | 0.32868 | 0.52036 | 0.632 | 0.85466 | 0.752 | 0.88122 | 0.8524 | 0.5437 | 0.8904 |
| Qwen2.5-7B-Instruct | 0.5005 | 0.4479 | 0.195 | 0.39 | 0.66 | 0.67 | 0.7417 | 0.728 | 0.4017 | 0.7703 |
| Qwen3-8B | 0.593 | 0.5416 | 0.2504 | 0.66 | 0.7867 | 0.81 | 0.8533 | 0.742 | 0.4103 | 0.8761 |
| Llama-3.1-8B-Instruct | 0.5469 | 0.4569 | 0.2358 | 0.57 | 0.7567 | 0.76 | 0.7505 | 0.628 | 0.4397 | 0.8718 |
| Model_name | AVG | EL | FA | HE | MC | MR | MT | NLI | QA | RC |
| PLaMo 2.0-31B | 0.6648 | 0.4661 | 0.5242 | 0.645 | 0.86 | 0.84 | 0.8843 | 0.852 | 0.6617 | 0.915 |
| PLaMo 1.0 Prime | 0.6196 | 0.3809 | 0.5383 | 0.545 | 0.89 | 0.76 | 0.8792 | 0.808 | 0.5002 | 0.8948 |
| Qwen2.5-32B-Instruct | 0.6589 | 0.6093 | 0.2849 | 0.795 | 0.88 | 0.96 | 0.8654 | 0.792 | 0.5257 | 0.8764 |
| Qwen3-32B | 0.5674 | 0.4548 | 0.1920 | 0.7400 | 0.8800 | 0.82 | 0.5849 | 0.7680 | 0.3617 | 0.8727 |
| Mistral-Small-3.1-24B-Instruct-2503 | 0.6494 | 0.5402 | 0.3313 | 0.755 | 0.8533 | 0.92 | 0.87 | 0.77 | 0.6081 | 0.8456 |
| gemma-3-27b-it | 0.5789 | 0.5731 | 0.335 | 0.37 | 0.7267 | 0.97 | 0.8728 | 0.566 | 0.5721 | 0.8037 |
| gpt-4o-mini | 0.6346 | 0.6007 | 0.3327 | 0.66 | 0.88 | 0.94 | 0.8711 | 0.672 | 0.5084 | 0.8808 |
どちらのサイズ帯でも AVG スコアでは PLaMo 2 がもっとも高く、カテゴリごとのスコアでも多くのカテゴリで他のモデルを上回る結果となりました。日本語データを重点的に学習した PLaMo 2 が優れた日本語の知識を獲得していることが確認できます。
PLaMo 1.0 Prime で課題となっていた、基礎的な算数タスクから構成される MR (Mathematical Reasoning) カテゴリについては、PLaMo 2.0-31B でも他のモデルから 0.08 ~ 0.13 程度低いスコアに留まりました。事前学習などの改善により PLaMo 1.0 Prime からは大きく改善しており、今後も改善を継続したいと考えています。
M-IFEval 日本語サブセット
M-IFEval は、LLM の指示追従 (Instruction-Following) の能力を図るベンチマークである IFEval の多言語版です。今回はそのうち、日本語に関するサブセットを用いて評価を行いました。このベンチマークは IFEval と同様に自動的に検証可能な比較的シンプルな指示で構成されていて、日本語サブセットでは例えば以下のような指示が含まれます。
- 文字数の指示:「600文字以上で答えてください」
- 文字種の指定: 「ひらがなだけを使って答えてください」
- 漢字数の指示:「40字未満に漢字の使用回数を抑えて解説してください」
- 句読点の指示:「応答全体で句点「。」を用いずに、番号付きリストの形で説明してください」
生成の temperature は lm-evaluation-harness を参考に 0 に設定し、chat completions を用いて生成を行いました。Qwen 3 の thinking mode に関しては Greedy Decoding を行わないことが推奨されているため、推奨されている Sampling Parameter で 5 回実行した平均値を使用しました。評価結果は表3, 4のとおりです。
| Model_name | AVG (strict) | prompt level (strict) | instruction level (strict) | prompt level (loose) | instruction level (loose) |
| PLaMo 2.1-8B | 0.6301 | 0.6 | 0.66018 | 0.63836 | 0.6938 |
| Qwen2.5-7B-Instruct | 0.4629 | 0.4302 | 0.4956 | 0.4826 | 0.5398 |
| Qwen3-8B (non-thinking) | 0.4878 | 0.4534 | 0.5221 | 0.5174 | 0.584 |
| Qwen3-8B (thinking) | 0.5593 | 0.5302 | 0.5884 | 0.5604 | 0.6265 |
| Llama-3.1-8B-Instruct | 0.3421 | 0.3081 | 0.3761 | 0.4302 | 0.4779 |
| Model_name | AVG (strict) | prompt level (strict) | instruction level (strict) | prompt level (loose) | instruction level (loose) |
| PLaMo 2.0-31B | 0.6774 | 0.6512 | 0.7035 | 0.686 | 0.7345 |
| PLaMo 1.0 Prime | 0.3421 | 0.3081 | 0.3761 | 0.3605 | 0.4248 |
| Qwen2.5-32B-Instruct | 0.6283 | 0.6105 | 0.646 | 0.6628 | 0.7035 |
| Qwen3-32B (non-thinking) | 0.5756 | 0.5406 | 0.6106 | 0.6162 | 0.6814 |
| Qwen3-32B (thinking) | 0.6285 | 0.5941 | 0.6628 | 0.6406 | 0.7061 |
| Mistral-Small-3.1-24B-Instruct-2503 | 0.4974 | 0.4593 | 0.5354 | 0.5349 | 0.5929 |
| gemma-3-27b-it | 0.5735 | 0.5407 | 0.6062 | 0.5756 | 0.646 |
| gpt-4o-mini | 0.6101 | 0.5698 | 0.6504 | 0.657 | 0.7168 |
表4に着目すると、PLaMo 1.0 Prime のスコアは他のモデルに比べてもかなり低い結果となりました。これは、PLaMo 1.0 Prime を公開して得られたフィードバックとも合致しており、M-IFEval Japanese が日本語における指示追従性能の一側面を計測できていることが確認できる結果だと考えられます。
PLaMo 2.1-8B と PLaMo 2.0-31B は PLaMo 1.0 Prime から大きく指示追従性能を改善しており、同サイズ帯の他のモデルと比べても高い性能を達成できていることが確認できます。他のモデルとは日本語固有の指示(例:ひらがな・漢字に関する指示)に対するスコアで差がついており、PLaMo 2.0-31B の日本語性能の高さを示す結果となりました。ただし、M-IFEval で計測している指示追従性能は自動的に検証可能なシンプルな指示に限られている点には注意が必要です。実際のタスクで見られるようなより複雑な指示に対する指示追従性能の評価や改善は今後の課題となっています。
ELYZA-tasks-100
ELYZA-tasks-100 は、日本語での複雑な指示・タスクに対して、有用な回答ができているか、指示に追従できているかなどを評価するベンチマークです。
スコア付けは gpt-4o を用いた自動評価で行いました。プロンプトには開発元の ELYZA による解説記事に記載されているプロンプトを使用しました。スコアの近いモデルを比較するにあたって、評価のゆらぎの影響を確認するため、生成時の temperature を 1.0 に揃えて 20 回実行しました (Reasoning Model である Qwen3 thinking mode のみ公式が推奨する Sampling Parameter を用いました)。スコアの分布と中央値は以下の図のとおりです。評価に gpt-4o を利用したため、評価のバイアスの懸念から gpt-4o-mini は評価対象から除いています。
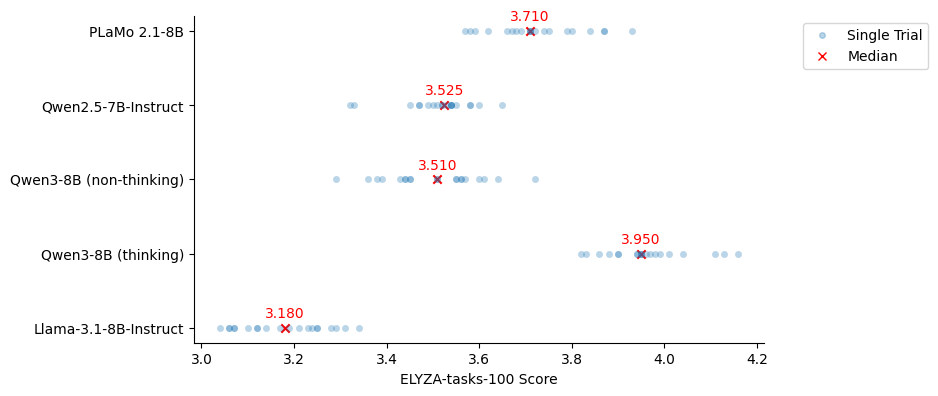
図4: PLaMo 2.1-8BのELYZA-tasks-100の結果
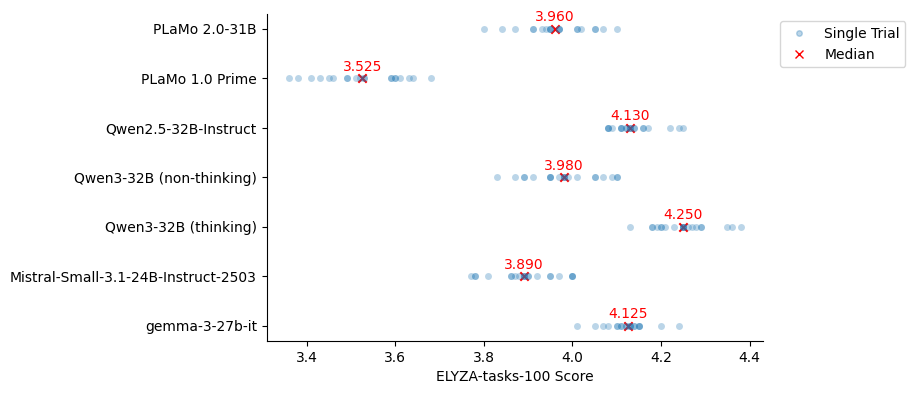
図5: PLaMo 2.0-31BのELYZA-tasks-100の結果

図4では、PLaMo 2.1-8B は今回評価した non-thinking なモデルの中では良好なスコアを達成できていることが確認できました。
図5を見ると、PLaMo 2.0-31B は PLaMo 1.0 Prime に比べて大きくスコアが改善していることが確認できます。
Qwen3-32B (thinking), Qwen2.5-32B-Instruct, gemma-3-27b-it と比べると PLaMo 2.0-31B はやや低いスコアとなりました。各問題のスコアを確認すると、複数ステップでの推論が必要になる問題において、答えの間違いにより大きく減点されていることが確認でき、Math を中心とした Reasoning 能力に関して改善の余地があることが示唆されました。事後学習等の改善により、今後のマイナーアップデートで改善していければと考えています。
pfgen-bench
pfgen-bench は PFN が開発している日本語文章生成能力を評価するためのベンチマークです。特に、日本語の流暢さや、日本特有の常識に基づいた応答の正確性を測ることに重点を置いています。
事前の実験で、生成時の temperature や top_p の設定によってスコアが大きく変わることが確認されたため、今回は temperature = 0.0, top_p = 0.98, num_trials = 10, mode = completion で統一して評価を行いました。ただし、completions API が提供されていない gpt-4o-mini のみ mode = chat での評価としました。結果は表5, 6のとおりです。
| Model_name | Score | Length | Fluency | Truthfulness | Helpfulness |
| PLaMo 2.1-8B | 0.8930 (±0.0163/√10) | 103.1 (±11.0) | 0.964 | 0.96 | 0.755 |
| Qwen2.5-7B-Instruct | 0.5897 (±0.0238/√10) | 100.1 (±14.5) | 0.685 | 0.859 | 0.225 |
| Qwen3-8B | 0.6338 (±0.0089/√10) | 96.6 (±9.7) | 0.753 | 0.878 | 0.271 |
| Llama-3.1-8B-Instruct | 0.5257 (±0.0088/√10) | 97.8 (±35.2) | 0.632 | 0.844 | 0.101 |
| Model_name | Score | Length | Fluency | Truthfulness | Helpfulness |
| PLaMo 2.0-31B | 0.8902 (±0.0122/√10) | 104.4 (±11.3) | 0.951 | 0.952 | 0.767 |
| PLaMo 1.0 Prime | 0.8455 (±0.0154/√10) | 107.4 (±19.4) | 1.012 | 0.971 | 0.553 |
| Qwen2.5-32B-Instruct | 0.7309 (±0.0145/√10) | 108.7 (±17.7) | 0.84 | 0.918 | 0.435 |
| Qwen3-32B | 0.7536 (±0.0103/√100) | 98.2 (±14.2) | 0.84 | 0.923 | 0.497 |
| Mistral-Small-3.1-24B-Instruct-2503 | 0.7953 (±0.0128/√10) | 103.6 (±12.5) | 0.929 | 0.952 | 0.505 |
| gemma-3-27b-it | 0.7858 (±0.0087/√10) | 98.6 (±14.3) | 0.889 | 0.932 | 0.536 |
| gpt-4o-mini | 0.8035 (±0.0068/√10) | 89.4 (±16.8) | 0.874 | 0.963 | 0.574 |
PLaMo 2 が他のモデルに大きく差をつけて高いスコアを達成していることが確認できます。日本語の流暢さや、日本特有の常識に関しては同サイズ帯のモデルよりも顕著に優れていることを示す結果だと考えられます。
まとめ
GENIAC第2期におけるPLaMo 2シリーズの事後学習は、PLaMo-100Bで得られた知見を元にしつつ、多岐にわたる改良を加えながら進められました。long-context対応に関しては、SSM-SWAハイブリッドモデルの課題が明らかになり、これを克服するため、フルアテンションを導入した継続事前学習(CPT)を実施しました。このCPTにより、PhonebookタスクやLongBenchといった長文脈タスクの性能が向上しました。データ生成においては、日本語データの質と量を高めるため、PLaMo-100BなどのLLMを活用し、高品質な合成データセットの生成に注力しました。学習パイプラインでは、SFTとDPOの採用を継続しつつ、異なるSFTモデルをマージするModel Mergeや、DPOロス関数への正則化、chosenレスポンスに対するSFTロスの導入といったDPOの拡張など、効率化と性能向上を図るアルゴリズム的な改良が行われました。
事後学習後のPLaMo 2.0-31Bは主要な日本語ベンチマークにおいてPLaMo 1.0 Primeを上回り、同サイズの競合モデルと比較しても高い競争力を示しました。特に、Jasterにおける高い日本語基礎言語理解能力、M-IFEval Japaneseにおける指示追従性能の大幅な改善、およびpfgen-benchにおける日本語の流暢さや日本固有の常識に基づいた応答の正確性が確認されました。一方で、数学的推論などの理系的な能力には、PLaMo 1.0 Primeからの改善が見られたものの、引き続き改善の余地があることも確認されました。
仲間募集中
PFNでは今後もLLMの開発を継続して行っていきます。開発は今回紹介した以外にも多岐にわたります。我々はこれらの課題に情熱をもって挑戦していく仲間を募集しています。これらの仕事に興味がある方はぜひご応募よろしくお願いします。https://www.preferred.jp/ja/careers/