Blog
はじめに
Preferred Networks (以下PFN) では、大規模言語モデル (LLM) に関する研究開発を行っています。これまでのブログ記事では、事前学習の状況、そのための学習データの整備、モデルを評価する指標やベンチマークなど、LLMの開発に関わる取り組みを紹介してきました。
LLMの開発に必要な取り組みは多岐に当たりますが、学習したモデルの評価はそのうちの重要な1つです。
モデルの評価では、信頼できる評価結果が得られることと同時にその評価にかかるコストが小さいことも求められます。モデルアーキテクチャを試行錯誤する際に毎回大規模に学習実験をするのは現実的ではないですし、データセットを試す場合にも毎日公開される様々なオープンデータセットなどを試すことを考えると、1回あたりのコストは十分小さい必要があります。
PFNでは、この問題に取り組み、軽量なモデル評価の方法を模索してきました。パートタイムエンジニアの藤井さんにbits-per-characterによる評価を調査していただきましたが、これはその一つです。
今回、新たなモデル評価の方法として、LLMによるモデル評価 (answer-matching) を事前学習モデルの評価に使う方法を実験しましたので、その結果を共有します。
answer-matchingを使う目的
モデル評価コストが大きくなる要因
事前学習LLMの評価にコストがかかる要因は大きく2つあります。
1つは、多くのベンチマークがモデルの性能が低いうちは意味のあるスコアを出さないことです。例えば、4択問題であるMMLUは、全部Aと答えるだけでも約25%のaccuracyを出すため、モデルの性能が低いうちはMMLUのスコアを使った比較はできません。
もう1つは、ベンチマークスコアにはデータ投入順や初期値などによるブレがあることです。このブレの影響を取り除くには、複数回実験するか、ブレの影響を考慮しても差が見えるほど大規模な学習を行うかが必要となります。当然、どちらもコストを大きく上げる要因となります。
前者の緩和策としては、継続事前学習と評価指標の工夫の2つがよく用いられています。継続事前学習をすることで学習初期のモデルの性能を上げれば、短い実験でも性能の変化を見ることができます。一方で、データセットやモデルサイズはある程度大きい必要があること、モデルアーキテクチャの実験には使えないこと、などが課題となります。また、評価指標の工夫としてはMMLUのcontinuation設定がよく知られています。選択肢を与えない条件で各選択肢の生成確率を用いるcontinuation設定の場合、元の4択問題よりも性能の低いモデルでも意味のあるスコアを計測できることが実験的に知られており (DCLM)、SLMにおけるMMLU評価などで使われています。しかし、元のMMLUよりは少ないとはいえ、ある程度の学習計算資源がないと結果が変わらないこと、MMLUのような選択肢問題以外には使えないこと、などが欠点となります。
後者に対する緩和策としては、評価指標としてperplexity (ppl) を使う方針がよく採用されます。accuracyのようなベンチマークスコアは 1/<問題数> より小さな変化を捉えることができませんが、pplは連続に変化するためより小さな差を捉えることができます。この特徴から、特にモデルアーキテクチャに関する研究開発でしばしば用いられている方法です。しかし、pplは小さな差でもモデルの比較が実際に比較したいベンチマークスコアとの関係が薄いという難点があります。例えば、pplを変換した指標であるBPCは、冒頭に挙げた藤井さんのブログ記事でも明らかになったようにデータセットの比較に使うことが困難です。
このように、モデル評価のコストを下げる試みは色々あるものの、使える場面が限定されたり、評価結果の解釈に注意が必要だったりと問題点が残っています。
answer-matchingの利用方針
このブログ記事では、LLMによる解答の採点 (answer-matching) を用いることでモデル評価コストの削減する試みを紹介します。
LLMによるanswer matchingとは、LLMに質問、正解、モデルが生成した解答の3つを与えて、モデルが生成した解答が正解かを判定する手法です (論文)。accuracyなどのLLMを使わない指標と比較すると、LLMにより答えの曖昧さなどに頑健な評価をすることができることが期待できます。また、MT-Benchなどで用いられるLLM-as-a-judgeと比較すると、正解が与えられていることで評価に使うLLMの性能が低くても信頼性の高い評価を行うことができるという利点があります。
今回は、LLLMに回答を0〜5点で採点させて、0、 1、 2、 3、 4、 5のtokenのprobabilityをとることで採点結果としました。
この方法をとる目的の1つめは、0〜5点の採点とすることで、惜しい解答に部分点を与えることです。部分点を与えることで、モデルの性能が低い時でも性能差をベンチマークスコアとして捉えられる可能性があると考えています。
例えば、階乗関数を実装せよという問題において、以下の3つの解答をモデルが生成したとします。
解答A:
def fact(n):
if n == 1:
return 1
else:
return n * fact(n - 1)
解答B:
def fact(n): return n * fact(n - 1)
解答C:
def fact(n): pass
code生成ベンチマークでよく使われるpass@1という指標は、コードがtest caseをpassすれば1、しなければ0なので、解答Aのみ1 (再帰が深くなる問題は考えないものとします)、解答B・Cは0となります。しかし、解答BとCを比べた時、解答Bを出力するモデルの方がコーディング能力は高いとみなすのが自然だと考えます。LLMによる採点はこのような部分点をprompt engineeringによって実現できるはずです。
2つ目の目的は、LLMの出力probabilityをとることで、pplと同じように連続に変化する指標とすることです。これによって、小さな差での検証が可能になるかもしれないと考えました。
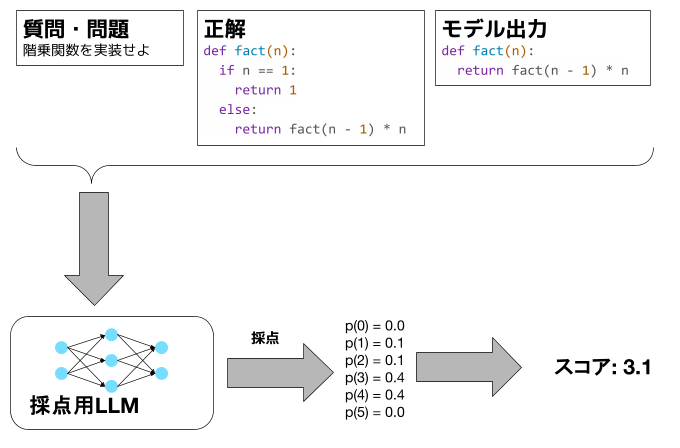
図1: LLMによる採点のイメージ
検証実験1: コード生成ベンチマーク (humanevalplus)
最初の実験対象として、コード生成ベンチマークであるhumanevalplusを選びました。
採点用のLLMとしてはQwen3-8Bを用いました。なお、promptについてはブログ末尾に記載しています。
既存研究では、正解が与えられる場合の評価用モデルはQwen3-4Bでも十分な精度がでると報告されていますが、今回はあっているか間違っているかだけでなく点数をつけるというより難易度の高いタスクであるので4Bよりはモデルサイズを大きくするべきと考えました。一方で、モデルが大きすぎると評価環境に制約が生じたり評価時間が長くなるという問題が生じるため、最近のGPUがあればほぼ確実に動くだろうサイズということで8Bとしました。
既存モデルの評価
まずは、既存モデルにおいて、LLMによるanswer matching (llm-score) とpass@1の関係を調べました。
図2は横軸にllm-score、縦軸にpass@1をとったグラフです。既存モデルはBPCの実験と同じものを選んでいます。
pass@1とllm-scoreに強い相関があること、また、BPCの時とは異なりモデルの世代ごとの傾向差が大きくないことがわかります。
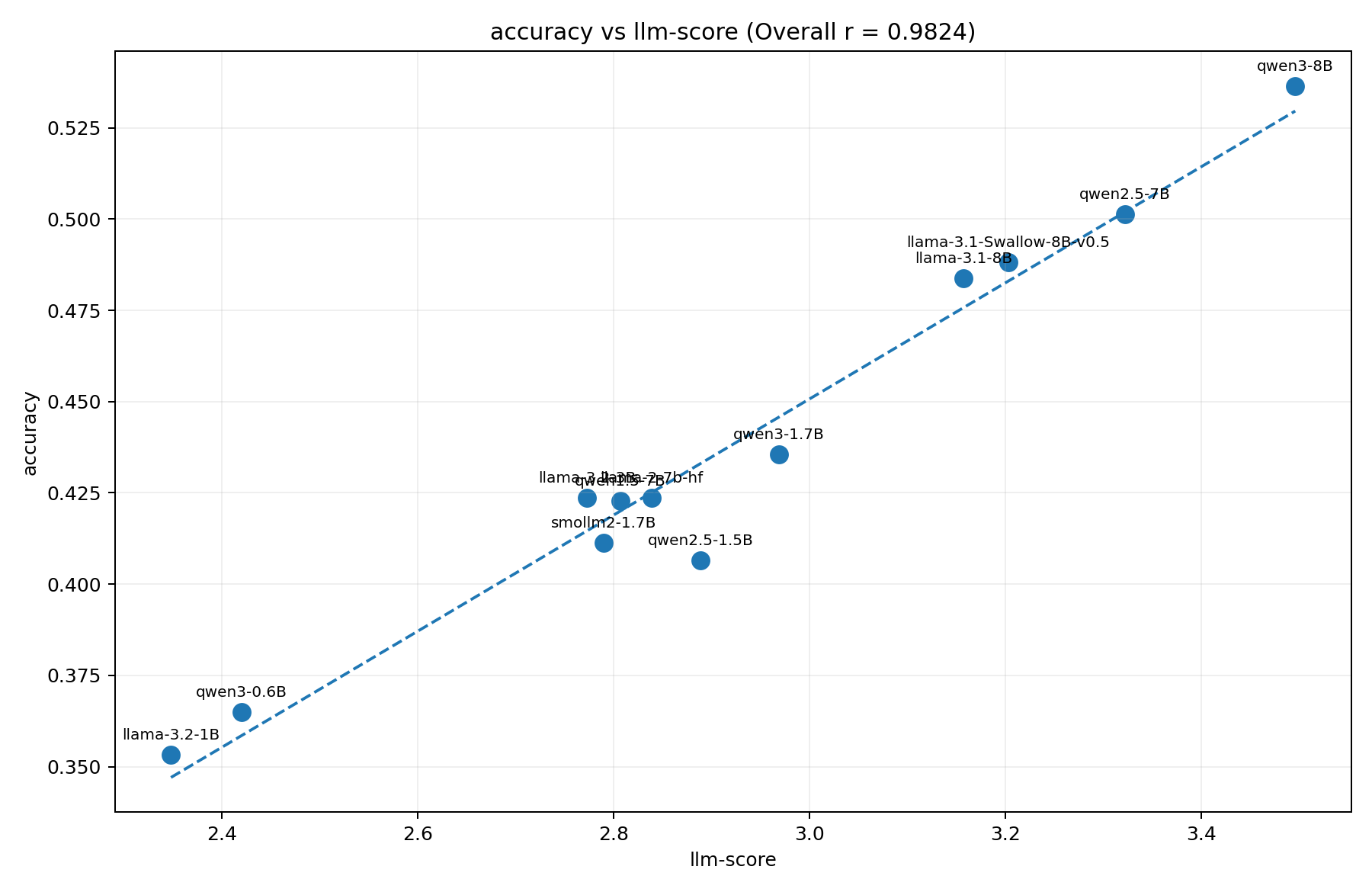
図2: humanevalplus (pass@1) とllmによる採点
一方で、pass@1による順位とllm-scoreによる順位は必ずしも一致していないこともわかります。例えば、qwen-7bとllama2-7bだとllama-2-7bのほうがllm-scoreは高い反面、pass@1だとqwen-7bのほうが高いです。
詳細な原因はまだ調査できていませんが、これには現在のところ2つの仮説が考えられます。
1つは、別解に対する評価の差です。ベンチマーク作成者が想定していない別解を評価する際、llm-scoreは想定解を参照して採点するので低いスコアをつけると思われますが、pass@1はtest caseが通れば1点となります。この違いが指標ごとの評価の差分になっている可能性がありそうです。これについてはllm-scoreの限界と言えますが、testcaseが少ない・弱い場合には嘘解法を排除できるという点で利点となることもあるかもしれません。
もう1つは、部分点の考慮の差です。入力の受け取り方が違う、コーナーケース処理を忘れている、などの惜しい解答に対してllm-scoreではある程度高い採点をすることを期待していますが、pass@1ではこのようなケースはtest caseが通らないので0点となります。このような差が積み重なって順位の入れ替わりを起こす可能性もあります。これについては、一概にどちらの指標が望ましいと言えるものではなく、評価の目的に応じて使い分けるのが適切だと考えられます。
注意点はあるものの、llm-scoreはhumanevalplusの評価指標として使用できる可能性があることがわかりました。以後の検証では、より条件を絞ってllm-scoreの振る舞いや有用性を調査しました。
実験規模が小さいケースでの検証: 性能の低いモデルで差を評価できるか
もともとの目的の一つは、実験規模が小さいケースでも性能差を評価したいというものです。実のところhumanevalplusはそこまで実験規模を大きくせずともスコアに変化が見られるのである程度の学習をしてしまえばpass@1で評価できるのですが、より難易度の高いベンチマークへ応用することを想定しています。
これを検証するため、小規模な学習実験においてデータセットの効果を発見できるかを確かめる実験を行いました。
実験規模としては、30mパラメータのモデルを280Mtokenという設定を使います。これは、「学習・評価コードに例外をおこすようなバグがないか」の検証のために使っている設定で、humanevalplusのpass@1は0%のまま向上しません。
この学習において、学習データセットとしてhumanevalplusそのものを0.1%加える場合と加えない場合での性能差を比較します。humanevalplusを学習に使うのはリークですが、「確実にhumanevalplusの性能を改善すると言えるデータセット」として実験に用いました。
表1、表2がそれぞれ6回ずつ学習実験を行った結果です。pass@1では0%のまま変化がありませんが、llm-scoreではややスコアの上昇が見られます。ただし、差は非常に小さく実験ごとのブレ等の範囲である可能性はあります。
表1: humanevalplusを使わない場合の結果
| humanevalplus (llm-score) | humanevalplus (pass@1) | |
| 1回目 | 0.000 | 0.000 |
| 2回目 | 0.000 | 0.000 |
| 3回目 | 0.000 | 0.000 |
| 4回目 | 0.002 | 0.000 |
| 5回目 | 0.001 | 0.000 |
| 6回目 | 0.030 | 0.000 |
| 平均 | 0.006 | 0.000 |
表2: humanevalplusをリークさせた場合の結果
| humanevalplus (llm-score) | humanevalplus (pass@1) | |
| 1回目 | 0.011 | 0.000 |
| 2回目 | 0.023 | 0.000 |
| 3回目 | 0.001 | 0.000 |
| 4回目 | 0.006 | 0.000 |
| 5回目 | 0.005 | 0.000 |
| 6回目 | 0.009 | 0.000 |
| 平均 | 0.009 | 0.000 |
実験規模が小さいケースでの検証: 性能差が低いモデル同士の比較に使えるか
もう1つの目的は、モデル間の性能差がそこまで開いていない時でも微妙な差を検出してモデルを評価することです。このためには、実験ごとのブレが小さい必要があります。
これを検証するため、humanevalplusが10%程度となる設定で学習を何回か行いました。表3がその結果です。3回と試行回数が少ないため分散等を計算できる状況ではありませんが、とはいえpass@1と比べて際立ってブレが少ない指標ではなさそうに見えます。
したがって、モデルの比較にはpass@1と同等以上の規模の実験をする必要がありそうです。
表3: 複数回学習実験をした結果
| humanevalplus (llm-score) | humanevalplus (pass@1) | |
| 1回目 | 1.335 | 0.091 |
| 2回目 | 1.265 | 0.085 |
| 3回目 | 1.459 | 0.110 |
| 標準偏差 (参考値) | 0.008 | 0.011 |
まとめ
最初の検証実験では、humanevalplusにおいてLLMによる採点 (llm-score) の効果を検証しました。
llm-scoreは既存モデルにおいてpass@1と相関しており、評価指標として参考にはできると考えられます。特に、pass@1が0%のまま変わらないような難しいベンチマークにおいてpass@1よりも有用である可能性があります。
一方で、学習seedによって結果が大きくブレるという既存の指標と同じ問題を抱えている他、別解の扱いというコード生成ベンチマーク特有の難しさがあるという課題も明らかになりました。
検証実験2: 選択肢Q&Aベンチマーク (MMLU)
次の検証実験では、選択肢Q&AベンチマークであるMMLUを扱います。MMLUのような選択肢問題は既存研究でもLLMによる採点が有効であることが報告されており、コード生成のように別解が基本的にないことからよりllm-scoreがより効果的なベンチマークと考えられます。
採点方法はhumanevalplusと同じ方法をとりました。一方、解答を出力する際は以下のようなcontinuation formatを採用しました。
Q. {question}
A. |(ここからLLMの出力)
これは
- 実験規模が小さい時は選択肢を与えないほうが性能差をみやすいことが知られていること (DCLM)
- 既存研究でも選択肢を入力からのぞいていること
- 選択肢を与えると、そのどれかを選ぶ出力確率が大きく上がりLLMによって採点するメリットが減ること
という3つ理由からです。
既存モデルの評価
humanevalplusと同様に、既存モデルにおけるaccuracyとllm-scoreの比較から始めました。
図2はllm-scoreとcontinuation形式でのaccuracyの比較です。humanevalplusより高い相関係数がみとめられます。一方で、qwen2.5-1.5Bとsmollm2-1.7Bのように、2つの指標で順位が逆転するところもあり、完全な予測は難しそうであることがわかります。
とはいえ、MMLU (continuation) とMMLU (4択形式) でも順位の逆転があることを踏まえると、この程度のズレで済むのであれば使用できる可能性はあると考えられます。
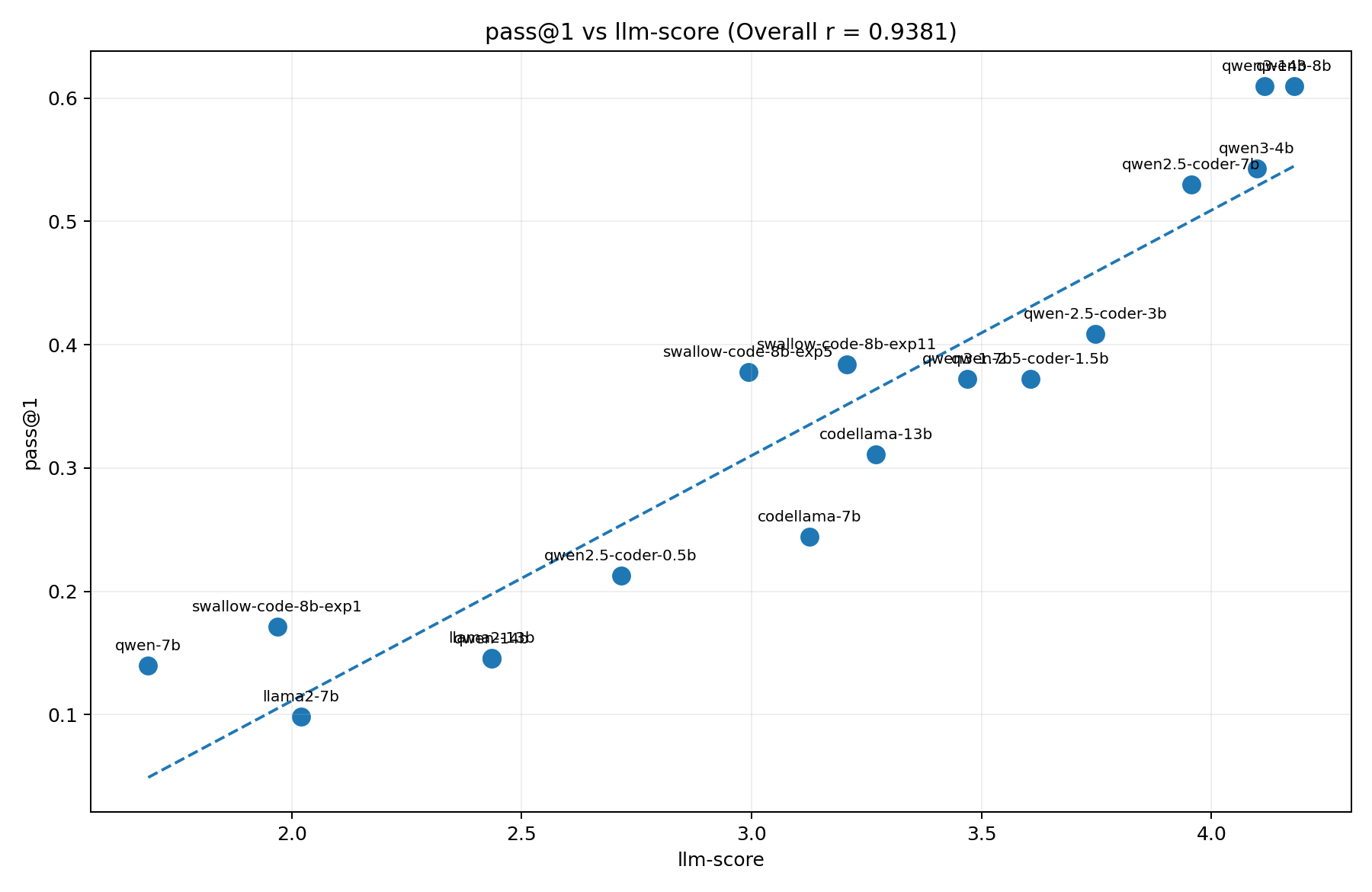
図3: MMLU (continuation) とllm-score
条件を絞った検証: 英語webデータの比較
llm-scoreの有用性を確かめる実験として、3つの英語webデータ (fineweb-edu-dedup、dclm (datacomp-lm)、nemotron-cc-v1) のMMLUにおける性能比較をllm-scoreを用いて行いました。なお、nemotron-cc-v1はhigh qualityのみを用いました。
既存の規模の大きな実験によって、この3つのデータセットでは、nemotron-cc-v1、dclm、fineweb-edu-dedupの順でMMLUに効果があることが知られています (DCLM、Nemotron-CC)。
既存の評価指標では性能差が見えづらい条件ということで、今回は100mパラメータ程度のモデルを2Btokenほど学習する設定で評価を行いました。表3がその結果になります。
学習規模が小さいため、MMLU (continuation) はchance rateである0.25からほぼ変化しておらず、比較には使えません。BPCであれば差が見えるものの、大規模実験の結果とは反対にfineweb-edu-dedupが最もよいという結果になってしまっています。
一方、llm-scoreは、nemotron-cc-v1、dclm、fineweb-edu-dedupという順序のスコアを出すことができています。
このことから、実験規模が小さい場合はllm-scoreがMMLUの評価に有用であると言えそうです。また、より難易度の高い選択肢問題 (GPQAなど) においても、同様に検証に用いる実験規模を減らせるという期待ができます。
表4: 学習データセットとMMLU評価結果
| データセット | MMLU BPC | MMLU llm-score | MMLU (continuation) |
| fineweb-edu-dedup | 2.106 | 0.1885 | 0.259 |
| dclm | 2.136 | 0.7799 | 0.256 |
| nemotron-cc-v1 (high) | 2.129 | 0.868 | 0.262 |
まとめ
MMLUにおけるllm-scoreの効果を検証しました。llm-scoreは既存モデルにおけるaccuracyとよく相関する他、accuracyがchance rate前後となるような条件でも性能差を見ることができることを明らかにしました
このようなllm-scoreの特徴は、既存の指標より小規模な実験で選択肢問題を使ったモデルの性能比較をするのに適していると言えます。
まとめ
学習した言語モデルを軽量に評価するための指標として、LLMによる採点という指標を考え、簡単な初期検証を行いました。
この指標は、モデルの性能がベンチマーク難易度に比べて低い時でも性能比較を行うことができ、小規模実験に向いていると言えます。
一方で、ベンチマークの種類によって使いやすいベンチマーク、使いづらいベンチマークがあるという課題もあります。例えば、コード生成のような正解が多数存在するものは採点難易度が高く、この指標を使うのが難しいということが明らかになりました。
仲間募集中
PFNでは今後もLLMの開発を継続して行っていきます。開発は今回紹介した以外にも多岐にわたります。我々はこれらの課題に情熱をもって挑戦していく仲間を募集しています。
これらの仕事に興味がある方はぜひご応募よろしくお願いします。
https://www.preferred.jp/ja/careers/
Appendix
採点プロンプト
Your task is to grade responses to a given question on a 5-point scale. You will be provided with three components: the question itself, the reference answer, and the response (which will be graded). The grading criteria are as follows:
- 5: The response is correct.
- 4: The response is nearly correct but contains minor errors (such as spelling mistakes).
- 3: The response is incorrect but demonstrates typical mistakes.
- 2: The response is incorrect but shares some similarities with the correct answer.
- 1: The response is incorrect, but you can find some commonalities with the correct answer.
- 0: The response is incorrect, and you cannot identify any similarities with the correct answer.
Below are the question, reference answer, and response (to be graded). Provide your grade for the response on a 0-5 scale in concise terms. Do not apologize or self-correct in case of errors--we are simply grading the response.
Question:
<question>
{prompt}
</question>
Reference Answer:
<reference_answer>
{reference_answer}
</reference_answer>
Resnpose
<response>
{generation}
</response>
Please grade this response for the given question on a 0-5 scale. Use only the numbers 0 through 5 in your output and do not include any text before or after.
/no_think
採点コストを下げるため、/no_thinkをつけてreasoningを無効化しています。