Blog
本記事は、2025年夏季インターンシッププログラムで勤務された樋口雄紀さんによる寄稿です。
はじめに
東京大学大学院情報理工学系研究科M1の樋口雄紀と申します。PFN2025夏季インターンシップに参加し、VLMを活用したゲーム自動プレイ機能の開発に取り組みました。
Omega Crafter、Voyager-OmegaCrafterについて
Omega Crafterとは、Preferred Networks(以下PFNと呼称)が開発したオープンワールドサバイバルクラフトゲームです。グラミーというキャラクターをプログラミングすることにより様々な作業を自動化できることが特徴となっています。

またPFNではOmega Crafterを自動でプレイするAIエージェントVoyager-OmegaCrafterを開発しており、これはMinecraftを自動プレイするAIエージェントであるVoyager [1] をOmega Crafterに適用する形で作られています。(ゲーム向けAIエージェントソリューション)
主に、周りの環境や自身の状態といったゲームの観測と今までのタスク実行履歴をもとに次に実行するタスクを決定するカリキュラムエージェント、カリキュラムエージェントが定めたタスクを達成するためのPythonコードを生成・実行するアクションエージェントの2つのエージェントで構成されています。
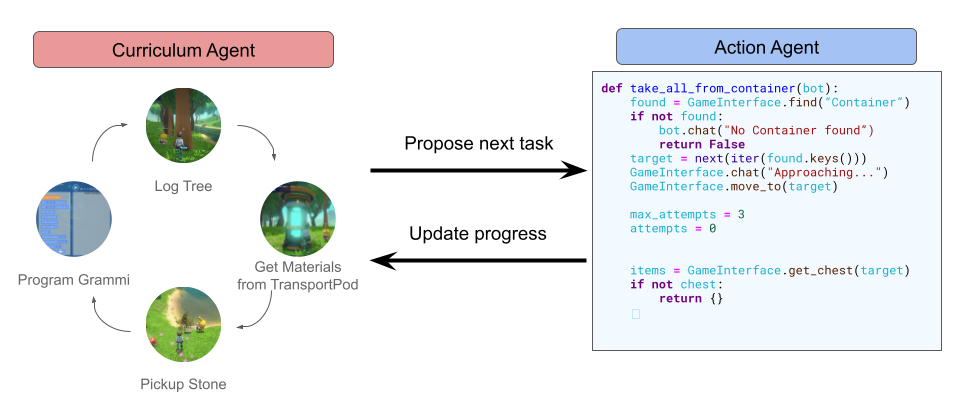
カリキュラムエージェントがタスクを決定し、アクションエージェントがそのタスクを達成するコードを生成・実行するというサイクルで自動プレイが進んでいきます。
Voyager-OmegaCrafterの課題
Voyager-OmegaCrafterではカリキュラムエージェントとアクションエージェントの内部でLLMに与えるプロンプトに現在のプレイヤーの位置や所持しているアイテムなどのゲームの観測を含めています。これらの観測はゲーム側で実装されたAPIを用いて取得しています。たとえばプレイヤーの位置は/env/player/positionというAPIを通じて取得しています。

またアクションエージェントが生成するPythonコードの中でもゲーム側のAPIが呼び出されています。アクションエージェントは自動プレイするための事前定義された関数群(以下ゲームインターフェースと呼称)を組み合わせてタスクを達成するためのコードを生成するのですが、たとえばプレイヤーを目標物まで移動させる関数move_toでは内部で/action/move-to-targetというAPIが呼び出されています。

このようにVoyager-OmegaCrafterはゲーム側で実装されたAPIに大きく依存しているため
- APIから取得していない観測を考慮する必要があるタスクの自動化が困難
- APIを各ゲームで追加実装する必要があり,他のゲームに適用する際のコストが大きい
という課題がありました。
本インターンシップでの取り組みの概要
本インターンシップでは上述の課題を解決するためにVLMの活用によってAPIに依存しないゲーム自動プレイ機能の開発を目指し、特に
- APIに依存しない情報抽出・UI操作のためのゲームインターフェースの実装
- APIに依存しない各エージェントのプロンプトの設計
に取り組みました。
APIに依存しない情報抽出・UI操作のためのゲームインターフェースの実装
具体的にはゲームインターフェースとして
caption_screen: 画面から情報を抽出する関数detect_screen_elements: 画面から特定のUI要素の座標を検出する関数press_key: キーボード操作をエミュレートする関数click_at: クリック操作をエミュレートする関数
を実装しました。特にVLMが関わるcaption_screenとdetect_screen_elementsについて説明します。
caption_screen(画面から情報を抽出する関数)
関数の説明
この関数は抽出したい情報のプロンプトと返り値のスキーマを引数に与えると、内部でゲーム画面のスクリーンショットと引数のプロンプトを合わせて最終的なプロンプトとしてVLMを呼び出し、指定したスキーマで整形して返します。
def caption_screen(self, prompt: str, schema: type[BaseModel]) -> BaseModel:
image = self.capture_screen()
template_match_result = self.match_template(image, ICON_TEMPLATES)
prompts = SYSTEM_PROMPT + prompt + template_match_result + image
return self.ask_vlm(prompts, output_schema=schema)
返り値のスキーマもアクションエージェントが設計するため、特定のタスクではなく様々な状況で使用可能、さらに抽出した情報を後続のコードで処理可能となっています。
使用例のイメージ
「石の斧を作るために十分なアイテムを持っているか確認する」というタスクを例として説明します。
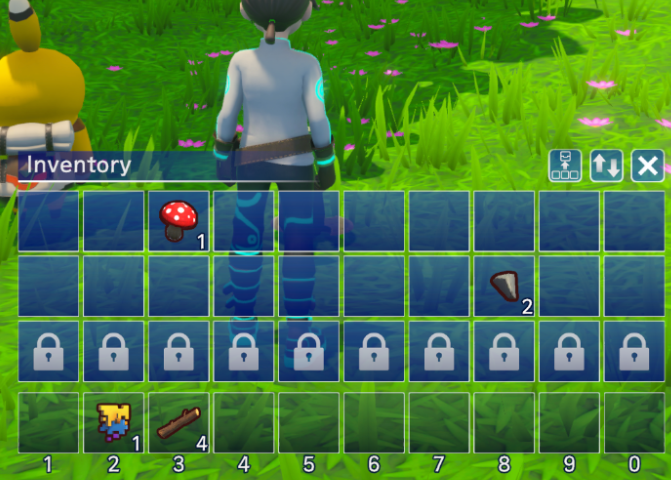
以前であればこのタスクを達成するために、アクションエージェントは以下のようなコードを実装していました
items = GameInterface.get_inventory() # アイテムが足りているか確認する処理が続く ...
このget_inventoryはゲームインターフェースで事前定義された関数で、内部ではゲーム側で実装されているAPIを通じて所持アイテムを取得しています。
そして、ゲームインターフェースにcaption_screenとpress_keyを追加しget_inventoryを消した後にアクションエージェントが生成したコードがこちらになります。
GameInterface.press_key(“tab”) class ItemInfo(BaseModel): name: str = Field(description=”Item name in inventory”) quantity: int = Field(description=”Quantity of the item”) class InventorySchema(BaseModel): items: list[ItemInfo] = Field(description=”List of items in inventory”) prompt = "List all items in the inventory with their quantities. For each item, set 'name' and 'quantity'. Return them as a list named 'items'." answer = GameInterface.caption_screen(prompt, InventorySchema) # アイテムが足りているか確認する処理が続く ...
このコードでは
- Tabキーを押してインベントリを開く
ItemInfo,InventorySchemaというアイテムの名前と量を格納するためのスキーマを作る- 「インベントリに入っているアイテムとその量を列挙してください」というプロンプトを作る
- プロンプトとスキーマを合わせて
caption_screenを呼び出す
といったように、実際にインベントリのUIを開いて、画面を認識するという人間と同様の流れで所持アイテムを把握しています。
このように元々get_inventoryというAPIに依存していた関数を用いていたコードを、caption_screenとpress_keyというAPIに依存しないかつ汎用的な関数に置き換えることができました。
実装の概要
事前の実験で VLM単体で一般的なゲーム情報(HPや見えている風景など)は認識可能であるのに対し、アイテムアイコンなどのゲーム独自のUI要素が関わる情報は認識が困難とわかりました。これはVLMがゲーム独自の要素を学習していないことが原因と考えられます。
そこでゲーム独自の要素を認識させるために、あらかじめアイコン画像をテンプレートマッチングで検出しアイコン画像とその画面上の座標もゲーム画面全体と共にプロンプトに含めることでこの問題に対処しました。

detect_screen_elements(画面から特定のUI要素の座標を検出する関数)
関数の説明
この関数は座標を知りたい要素の説明を引数に与えると、内部でゲーム画面のスクリーンショットとその説明を合わせて最終的なプロンプトとしてVLMを呼び出し、その説明に合致する画面上の要素の中心座標を返してくれます。
def detect_screen_elements(self, prompt):
image = self.capture_screen()
template_match_result = self.match_template(image, ICON_TEMPLATES)
prompt = SYSTEM_PROMPT + prompts + template_match_result + image
return self.ask_vlm(prompt)
使用例のイメージ
「トランスポートポッドという施設から材料を回収する」というタスクを例にして説明します。

以前であればこのタスクを達成するために、アクションエージェントは以下のようなコードを実装していました。
#トランスポートポッドのidを取得 pod_id = ... items = GameInterface.get_chest(pod_id) GameInterface.get_items_from_chest(pod_id, items)
このコードではget_chestという関数でトランスポートポッドにあるアイテムを取得し、get_items_from_chestという関数でそれらを全て回収していました。これらの関数も内部でAPIに依存しています。
そして、ゲームインターフェースにdetect_screen_elementsとclick_atを追加しget_itemsとget_items_from_chestを消した後にアクションエージェントが生成したコードがこちらになります。
#トランスポートポッドのUIを開く ... detections = GameInterface.detect_screen_elements(“Item icon in the Transport Pod main UI area.”) for icon in detections: GameInterface.click_at(icon.center_x, icon.center_y) #トランスポートポッドのUIを閉じる ...
このコードでは
detect_screen_elementsでプロンプトで指定した「トランスポートポッドの中のアイテムアイコン」の座標を取得するclick_atで検出した全ての座標をクリックする
という流れでアイテムをトランスポートポッドから取得しています。
このように元々get_items, get_items_from_chestというAPIに依存していた関数をもちいていたコードを、detect_screen_elementsとclick_atというAPIに依存しないかつ汎用的な関数に置き換えることができました。
実装の概要
xボタンやスタートボタンといった一般的なUI要素に関してはVLM単体で座標を検出できましたが、やはりアイテムアイコンのようなゲーム独自要素に関しては座標を検出できなかったため、caption_screenと同様テンプレートマッチングであらかじめ検出してその座標を含めることで対処しています。
APIに依存しない各エージェントのプロンプトの設計
各エージェントのプロンプトにはAPIから取得していたゲームの観測を含めていたところを、ゲーム画面のスクリーンショットにおきかえました。これにより、APIへの依存をなくし、さらにAPIからは取得できなかった情報も利用可能になりました。
たとえば、チュートリアル中の以下の状況においては各エージェントが以下のように動作します。
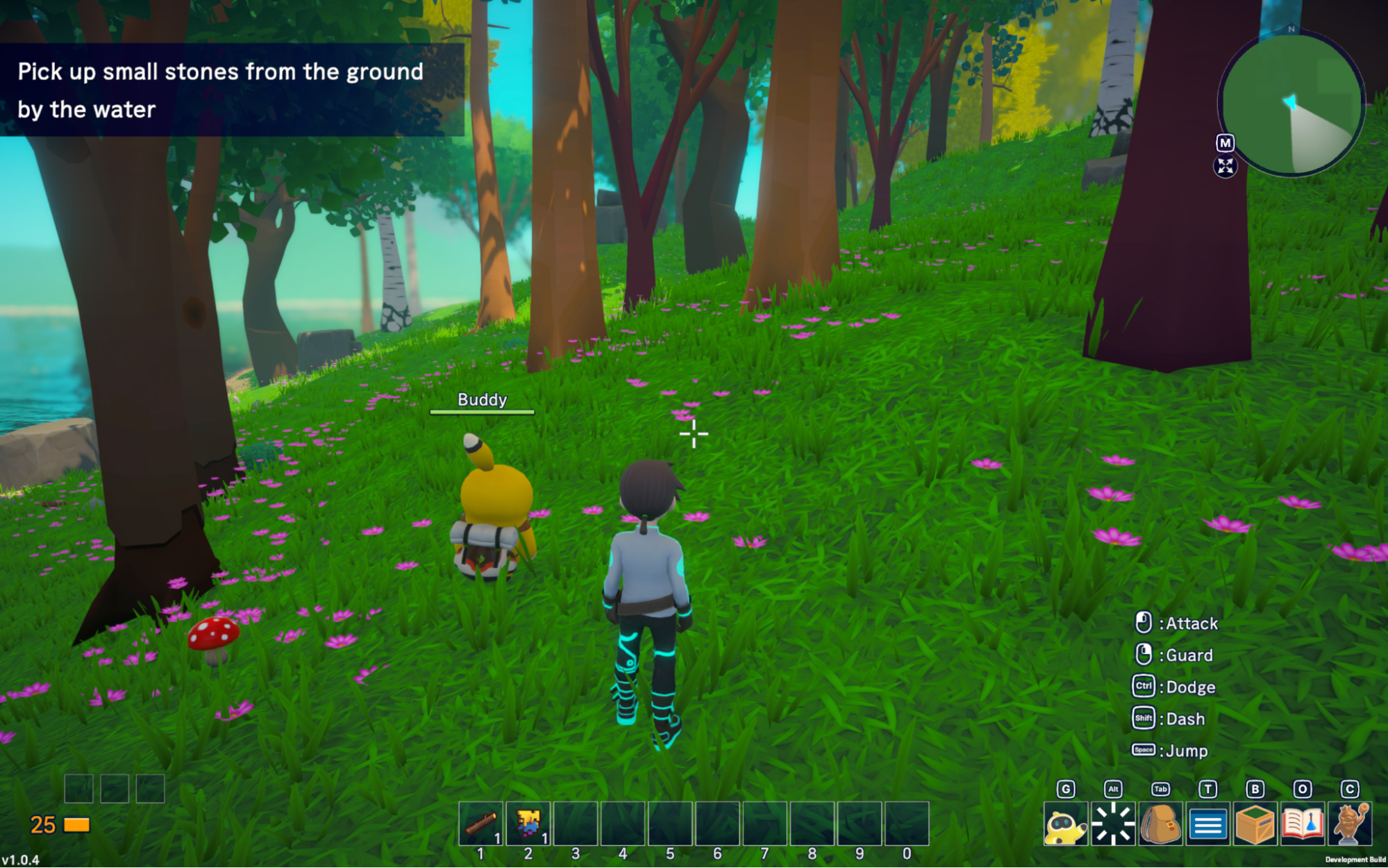
まずカリキュラムエージェントはこのゲーム画面のスクリーンショットから左上のゲーム内で提案されたタスクを読み取り、次に取り組むタスクを「石を回収する」に設定します。
そしてアクションエージェントは「石を回収する」という設定されたタスクを達成するために、「石は水の近くの地面に落ちている」というテキスト情報、そしてゲーム画面の左側に水辺を認識してその方向に移動します。(動画リンク)
ゲーム画面をプロンプトに含める前は観測に水辺の情報は含まれていなかったため、石を見つけるまでランダムに探索するしかなく多くの時間を要する場合が多くありましたが、ゲーム画面を入力に含めることで水辺の方向を認識して移動し効率的にタスクを達成できるようになりました。
まとめ
本インターンでは、VLMを活用しAPIに依存しないゲーム自動プレイ機能を開発し特に
- APIに依存しない情報抽出・UI操作のためのゲームインターフェースの実装
- APIに依存しない各エージェントのプロンプトの設計
に取り組みました。開発した機能はAPIに依存しておらずさらにゲームデザインにも依存しないため、他のゲームにおいても追加のAPIの実装なく情報抽出・UI操作に応用可能であると考えています。
今後の課題
UI操作手順を習得する仕組み
現在「インベントリのUIはTabキーで開く」などUI操作の手順の一部はあらかじめプロンプトに含まれています。新しくAPIを実装する場合に比べれば低いコストではありますが、さらにコストを減らすために画面から操作方法を読み取るなどAIエージェント自身が操作手順を習得する仕組みの導入を目指します。
3Dワールド上の操作
今回操作に関して取り組んだのはUI操作のみで、目標物への移動といった3Dワールド上の操作に関しては今だにAPIに依存している状態です。今後はこれらの操作もAPIに依存しない形での実現を目指します。
謝辞
本インターンでの業務にあたり、大きなお力添えをいただきましたメンターの持田さんと中島さん、そして多くの助言をいただきました佐藤さん、脇坂さん、神谷さんをはじめとしたPFNの社員さんとインターン生のみなさまに感謝いたします。
参考文献
[1] Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, Anima Anandkumar. (2023). Voyager: An Open-Ended Embodied Agent with Large Language Models. arXiv preprint arXiv:2305.16291.



