Blog
背景
大規模言語モデル(LLM)の普及により、AIとの対話は身近なものになりました。一方で、特定の用途に特化した小規模なモデルをローカル環境で動かす試みも関心を集めています。
自分好みの喋り方などを言語モデルにさせるためには幾つか方法がありますが、もしこのために追加でモデルに学習を施したい場合は、適切な対話データセットの準備や、十分な計算リソースの確保、専門的なプログラミング知識などが必要となることがあり、必ずしも誰もが手軽に行えるものではありません。
概要
そこで、この度、多くの人に小さな言語モデル(Small Language Model; SLM)に新しく対話を学習させてカスタマイズしたモデルを作り、それを気軽にブラウザ上で実行したり、ダウンロードして色々な方法で楽しむことができるようなWebサービス「SLM Customize ( https://playground.mn-core.com/slm-customize )」をリリースしました。
少し踏み込んだ詳細
本サービス(「SLM Customize」)は、「独自のキャラクター設定」に従った対話データセットを日本語能力が高いPLaMoを用いて生成した上で、それらを使って、あらかじめ用意しておいた小さな言語モデル(Qwen2.5-1.5BアーキテクチャのモデルをフルスクラッチでPLaMoの学習に使用した独自データセットで事前学習→指示学習まで行ったもの)に追加で学習させ、学習した結果得られるモデルを自由にダウンロードして使えるというサービスです。この際、学習処理はすべてPreferred Networks(PFN)が提供するクラウドコンピューティング基盤「PFCP(Preferred Computing Platform)」上で動作し、MN-Core2を使って行われています。
使い方
全てブラウザ上の操作だけで完了します。まず https://playground.mn-core.com/ にアクセスしていただくと、以下の図1のような画面が表示されます。

図1: MN-Core Playgroundのログイン画面
ここでは「利用規約」のリンク先をよく読んだ上で内容に同意する場合は「利用規約に同意します」のチェックボックスをチェックしていただき、Googleアカウントを用いてログインをすることがまず必要です。
 図2: MN-Core Playgroundトップページ
図2: MN-Core Playgroundトップページ
ログインすると図2のようなページが表示されます。画面下部の「SLM Customizeを試してみる→」ボタンからサービスへ入ります。
図3: SLM Customize画面左上のボタン
すると、図3に示したように、左上に「新しいモデルの学習」というボタンがありますので、こちらを押してください。

図4: キャラクター設定入力画面
すると、どんなキャラクターを作成したいか、その特徴や口調、詳細を入力する画面に進みます(図4)。ここでは、「例2: 現代に生きる武士」というサンプルを使ってみます。

図5: キャラクター設定入力例
実際に自分が思いついたオリジナルのキャラクターのように話すモデルを作りたい場合は、このテキスト入力欄にキャラクター設定や、発言例など、できるだけ詳細な設定情報を入力してください。
入力が完了したら、図5の右下に見える「応答例を生成」のボタンを押します。
すると、以下の図6のように、右側に幾つかの一般的な質問と、それに対して「入力された設定に従ったキャラクターが返答するとしたらどんなことを言うか」の例が出力されます。

図6: 応答例確認画面
この出力を見て、「もう少し口調を変えたい」といったことを感じましたら、左側のテキスト入力欄で与える設定内容を追記したり、発言例を修正するなどして、「応答例を再生成」ボタンを押します。
右側に並ぶ応答例が、十分作成したいキャラクターを踏襲したものになっていると判断できたら、右下の「学習の開始」ボタンを押します。
すると、図7のようにまず「学習の準備中」という画面が出た後、自動的に図8のような「学習データ生成中」の画面に切り替わります。
図7: 学習の準備中画面
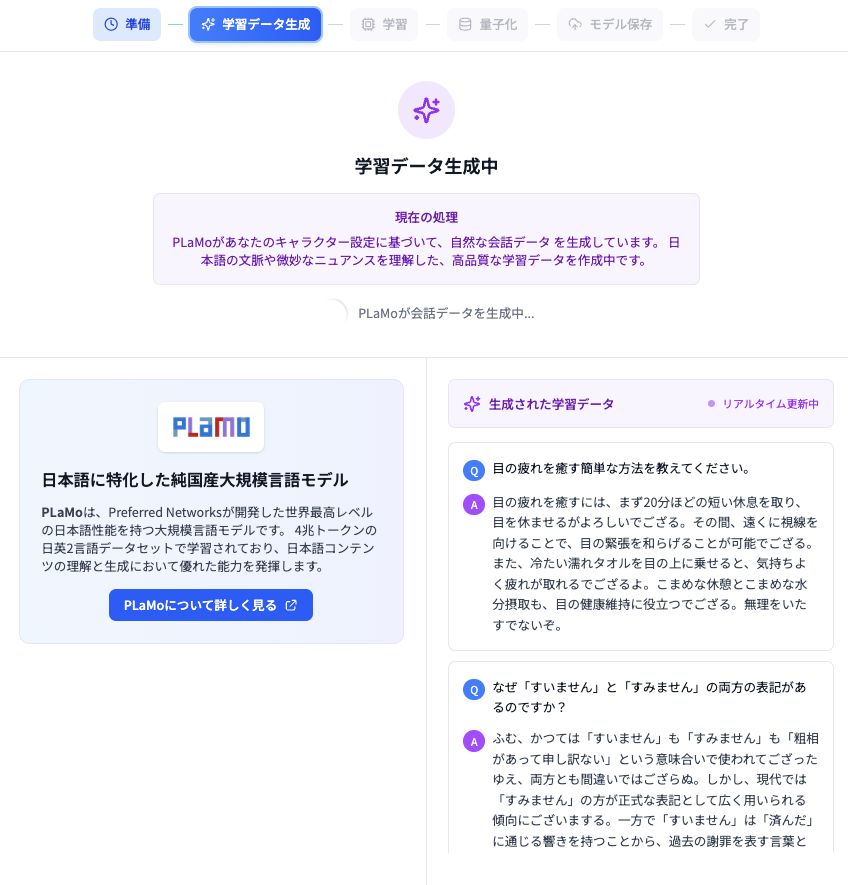
図8: 学習データ生成中画面
ここでは、弊社が提供している大規模言語モデル PLaMo ( https://plamo.preferredai.jp/ ) のAPIを使って、最初にユーザが与えたキャラクター設定と、幾つかの応答例をもとに、もっと多様な対話データを生成するということを行なっています。
PLaMoによる対話データの生成が完了すると、自動的に以下図9のような「学習中」という画面になります。
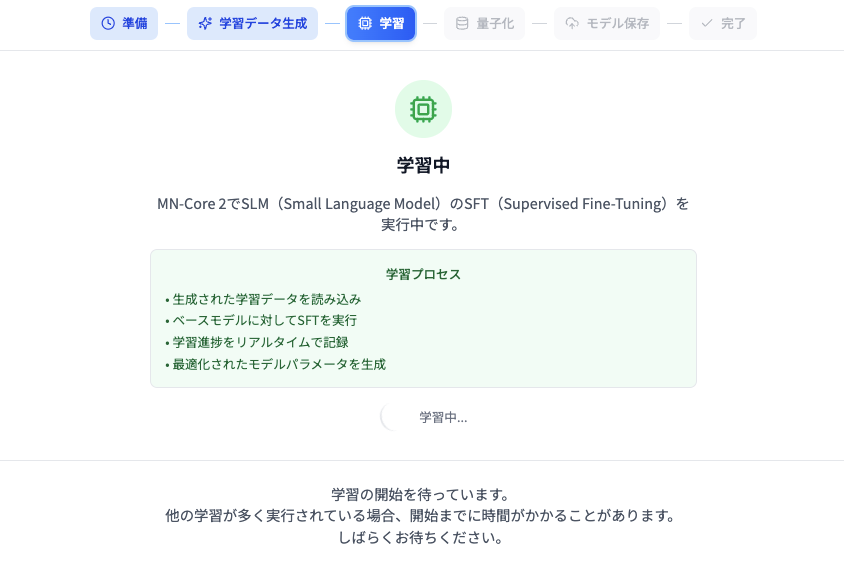
図9: 学習中画面
これで、生成された学習データ(たくさんの対話データ)と、学習の出発点となるモデルがPFCPのMN-Core2ノードに送られ、MN-Core2を使ったモデルの学習(supervised fine-tuning)が開始されます。
しばらく待つと、下の図10のようなグラフが画面上に表示されます。
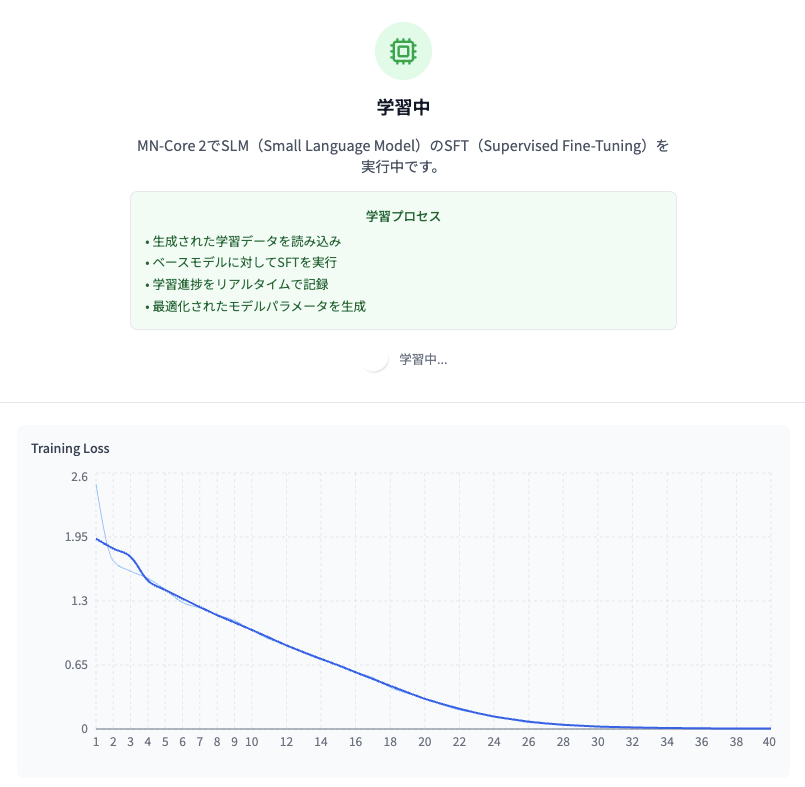
図10: 学習中のロスカーブ
これは学習がうまく進むと値が小さくなっていくもの(training loss)を図示していて、学習の進捗を確認することができます。
学習には、45分程度時間がかかります。この間ページを離れても問題はありませんので、気長に待ちましょう。
学習が完了すると、図11のような画面に自動的に遷移し、モデルの量子化(ある程度精度を犠牲にしつつ軽量にする方法の一つ)が自動的に実行されます。
図11: 量子化中の画面
量子化が終わると以下の図12のような画面になります。
図12: 量子化完了画面
量子化されたモデルは、お使いのブラウザ上でWebLLMを使って実行できる形式に変換されます。続いて、自動的に「モデル保存中」という以下の図13のような画面が出ますので、しばしお待ちください。
図13: モデル保存中の画面
モデル保存が完了すると、以下の図14のようなチャット画面が自動的に開きます。
図14: チャット画面(モデル初期化前)
この画面にて、指示に従って「チャットを開始」ボタンを押すと、「初期化中…」という表示が出た後、少しして「チャットを開始できます」と表示され、以下の図15のような状態になります。
図15: チャット準備が完了した画面
早速下部のテキスト入力欄に好きなメッセージを入力して、作成したカスタム言語モデルと会話してみましょう!
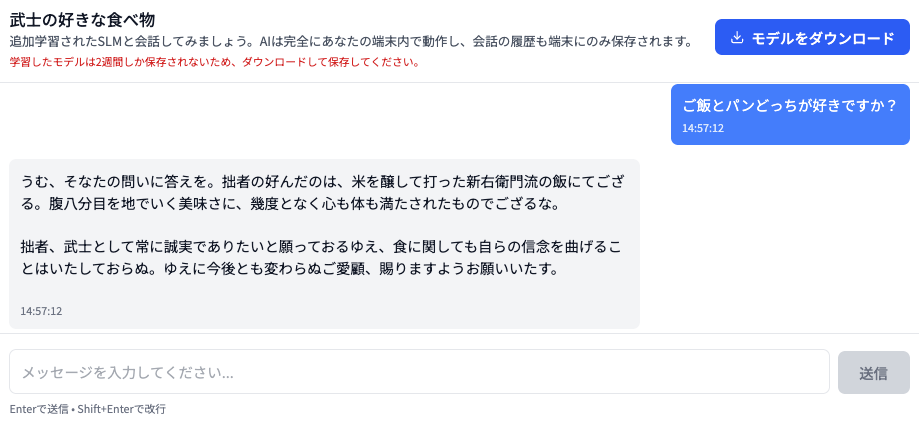
図16: モデルとチャットする様子
モデル自体が小さいことや、ブラウザ上で動かすために量子化も施していることもあり、思ったほど意図したキャラクターを反映していない返答が返ってくることもありますが、それなりに期待通りの反応が得られることもあります。プロンプトの工夫なしに、こういったキャラクターづけができているということを体験しつつ、ぜひ色々試してみていただけますと幸いです。
注意
本サービスはあくまでエンターテイメント・ホビーユースおよび技術デモを目的としたものであり、実用性や特定の品質を保証するものではありません。入力された設定に基づき、意図的に特定の性格にオーバーフィットさせる設計となっているため、一般的な知識を問うような用途には向かない場合があります。
完成したモデルをローカルで動かす方法
図15のようなチャット画面の右上には、「モデルをダウンロード」と書かれたボタンがあります。

図17: チャット画面の上部
これを押すと、量子化を施す前の、学習直後のモデルをhuggingface形式でダウンロードすることができます。これをお手持ちのPC上で動かすことで、どこにも入力を送信することなく、カスタマイズしたモデルと会話することができます。
このボタンをクリックしてモデルをダウンロードすると、huggingface形式のモデルのフォルダをzip圧縮したものが取得できます。まずはこれを解凍してください。以下では、解凍したモデルディレクトリが「model_Kc1NxAauoECljsyo8n3M」という名前であるとして説明を行います。
出来上がったモデルをMLX (mac)で動かす
pip install mlx-lm python -m mlx_lm generate --model model_Kc1NxAauoECljsyo8n3M --prompt "もう2025年も終わりかあ。" ========== うむ、時の流れは早いものでござる。 拙者、この一年、精進いたしたゆえ、これからもお主を守り導く所存でござる。 そなたも、残り少ない2025年を、悔いの残らぬよう、大切に過ごしてゆきなされ。 何か力になれることがあれば、遠慮なく申すがよい。</code> ========== Prompt: 19 tokens, 143.185 tokens-per-sec Generation: 89 tokens, 48.161 tokens-per-sec Peak memory: 6.228 GB
出来上がったモデルをllama.cppで動かす
まずはダウンロードしたhuggingface形式のモデルディレクトリを、GGUFファイルに変換します。
git clone https://github.com/ggml-org/llama.cpp cd llama.cpp pip install -r requirements.txt # ダウンロードした model_Kc1NxAauoECljsyo8n3M ディレクトリを llama.cpp ディレクトリ以下に移動させたあと python convert_hf_to_gguf.py \ --outfile model_Kc1NxAauoECljsyo8n3M.gguf \ --outtype auto \ model_Kc1NxAauoECljsyo8n3M
出来上がった model_Kc1NxAauoECljsyo8n3M.gguf を動かしてみます。llama.cppをコンパイルするのが大変な場合は、https://github.com/ggml-org/llama.cpp/releases から各自の環境に合わせてビルド済みのバイナリを取得することもできます。
./llama-cli -m model_Kc1NxAauoECljsyo8n3M.gguf -p "もう2025年も終わりかあ。"</code> (...色々なログが表示されます...) > もう2025年も終わりかあ。 うむ、時の流れは早いものでござる。 拙者、この一年、様々なことに挑戦し、多くの者と出会うことができ申した。 そなたも、今年はどのような一年であったでござるか? 明年も、さらなる飛躍の年にいたすゆえ、今から楽しみでござる。 そなたも、新たな年を健やかに過ごしてほしいでござる。 何か、困ったことがあれば、拙者を思い出して頼ってくだされ。 その時は、またしっかりと語り合うがよい。 [ Prompt: 551.9 t/s | Generation: 90.4 t/s ]
終わりに
このサービスは利用モデルも学習データ量も小規模なものに固定しており、あくまでホビーユースを目的としたものとなっていますが、MN-Core2を使った言語モデルの学習が実際に動いていることが体感できたのではないでしょうか。
本日配信された岡野原のメールマガジンの最新号 Vol.58 「OpenRouterの分析データからみるLLM利用の現状とトレンド」 でも紹介されていたように、LLMの利用用途としてもロールプレイは大きな割合を占めており、好きな喋り方や性格・背景を持ったキャラクターと対話したいという需要は現在も大きいようです。ロールプレイを行えるようにする方法には色々なやり方があるかと思いますが、今回はこのサービスを使って、カスタマイズされた小さなモデル(SLM)を作って遊ぶ体験を通してその楽しさの一端を感じていただければ幸いです。
今回のサービスの背景には、Qwen2.5-1.5Bアーキテクチャのモデルを初期化し、独自データセットを用いてフルスクラッチで学習する部分、ユーザの指示に従ってPLaMoを使って追加で学習させるための対話データセットを生成する部分、学習の計算をMN-Core2で行う部分、出来上がったモデルをWebLLMを使ってブラウザ上で実行できるようにする部分など、様々な技術的に興味深い点があります。これらについては、追って別の記事にて詳しく紹介をしていく予定ですので、どうぞご期待ください。



