Blog
本記事は、2025年夏季インターンシッププログラムに参加された堀口維里優さんによる寄稿です。今回はWebエージェントの性能改善に取り組んでいただきました。PFNでは自社開発のLLMであるPLaMo以外にも、このようなLLM周辺の技術スタックの研究開発にも取り組んでいます。本取り組みで得られた知見・成果は今後PFNのソリューション開発やプロダクトに取り入れていく予定です。
概要
- WorkArenaというベンチマークにてWebエージェントの改善に取り組みました。
- 対象のWebページの操作知見を蓄積し、操作ミスを減らす方法を検証しました。
- 頻出の失敗パターンを事前に検出し、リトライを試みる方法を検証しました。
- 上記工夫によりベースラインを11.5%ほど改善し、リーダーボードでSOTAを達成しました (2025年9月時点)。
自己紹介
こんにちは、2025年度のPFN夏季インターンシップに参加していた東京大学大学院博士1年の堀口維里優と申します。今回のインターンシップでは「Webエージェントの改善」というテーマに取り組みました。
背景
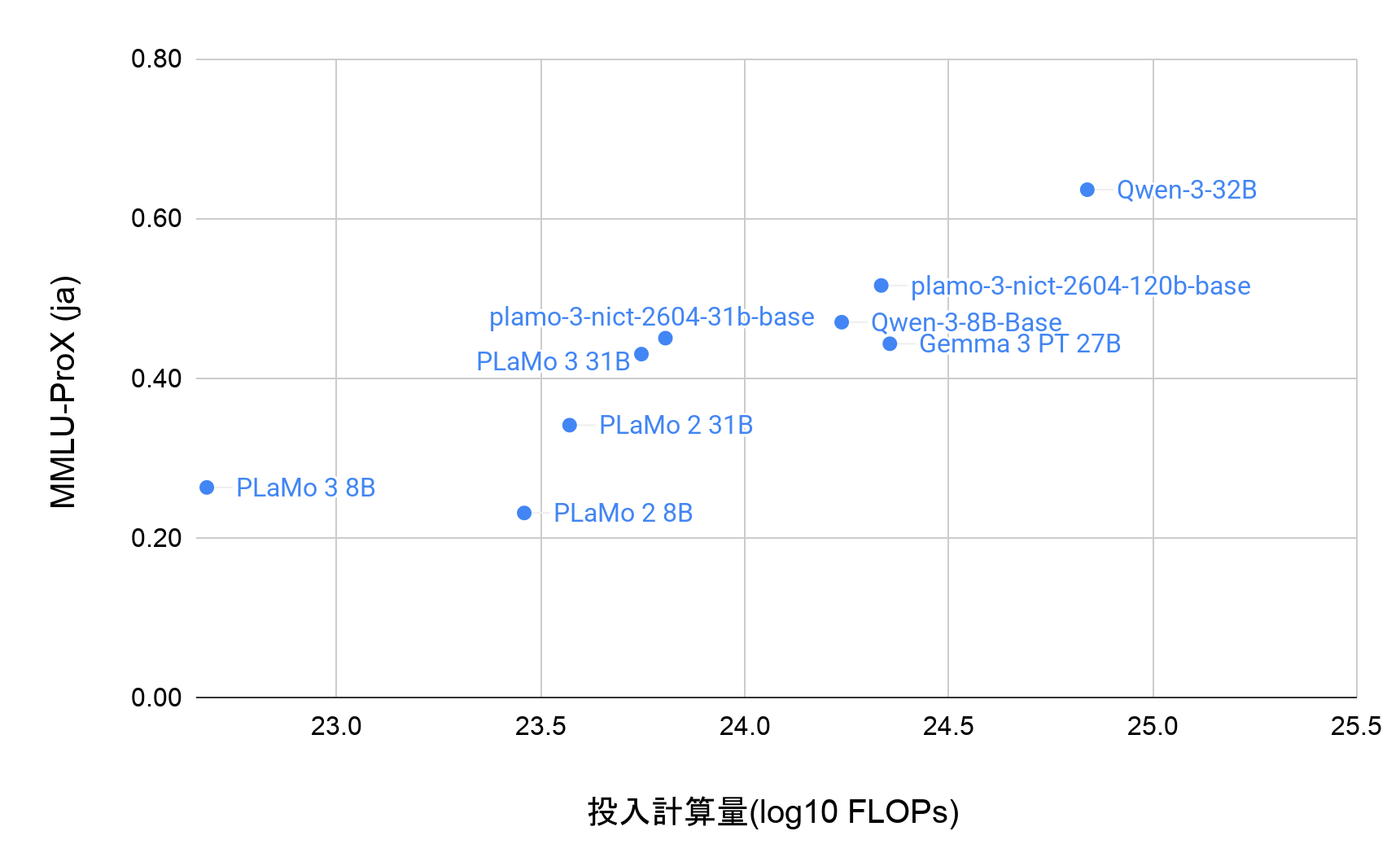
LLMエージェントとは、大規模言語モデル(LLM)の推論能力に、計画立案、外部ツールとの連携、記憶機能を統合した仕組みです(図1)。環境に応じて動的に行動を選択し、複数ステップにわたる現実世界のタスクを自律的に遂行できることが特徴です。LLMの推論能力が向上したことで、こうした複雑なタスク実行システムが実際の課題に対して作れるようになりました。
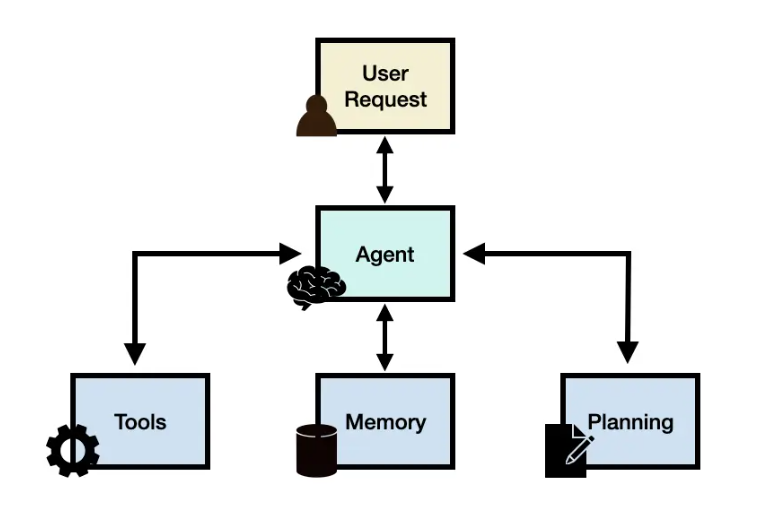
図1. LLMエージェントフレームワーク。図は[1]より引用。
Webエージェントは、LLMエージェントの一種で、外部環境であるWebブラウザ上で人間が行うような操作(クリック、文字入力、ページ移動など)をこなしながら、情報の取得や分析を行えます。この仕組みを使うと、さまざまな業務アプリやオンライン作業をブラウザから利用できるようになり、調査・データ入力・業務サポートなど、多くのタスクを自動でこなせるようになります。
取り組みの概要
近年、Webエージェントの性能向上を目指す提案が数多く行われており [2,3]、精度・信頼性の改善によって、より安定したオンライン業務の自動化が実現しつつあります。こうした技術的進歩は、Webエージェントを単なる実験的な自動化から、実運用レベルへと進化させる重要なステップとなります。
今回の取り組み対象として、ブラウザベースの業務タスクを評価できるベンチマーク WorkArena を選びました [4,5]。WorkArenaは、現実的な条件を想定したブラウザ操作タスクを難易度別(Level 1〜3)に提供し、リーダーボードで性能比較が可能です。タスクは業務アプリケーションで見られる、大規模かつ動的なDOM構造を含むため、Webエージェントの能力を包括的に検証できます。
Level 1はフォーム入力や検索、ボタンクリックなどの単一操作タスク、Level 2は複数のLevel 1タスクを組み合わせた連続操作や条件分岐を含む複合タスク、Level 3は動的コンテンツや高度な判断を要するより複雑な業務ワークフローを再現したタスクで構成されています(図2参照)。
表1. 各レベルの概要
| Level 1 | ブラウザ上の単一タスク:フォーム入力、検索、読み取り、リストの並べ替えなど |
| Level 2 | 複数のLevel 1タスクを組み合わせた複合問題で、連続的な操作や条件分岐を含む |
| Level 3 | 複雑な実務ワークフローを再現し、動的コンテンツや高度な判断と操作を要する |
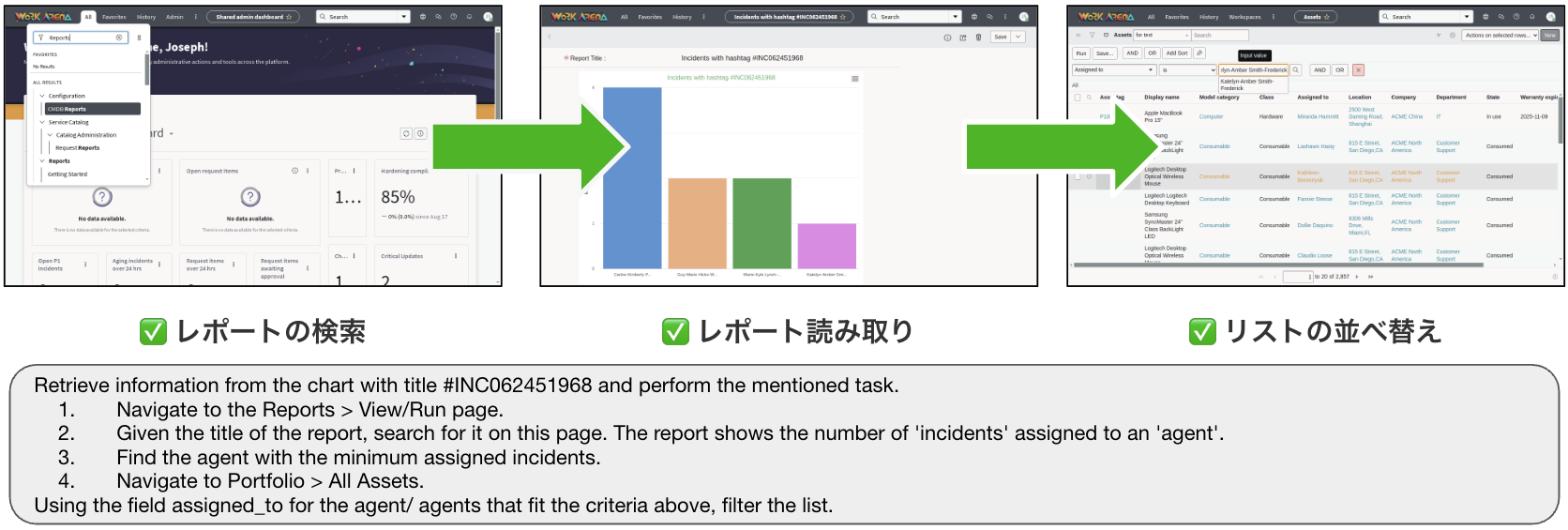
図2. WorkArena Level2の具体例。複数のLevel 1タスクを組み合わせた複合問題。
ベースラインとしてGenericAgentを選びました。GenericAgentは、Webブラウザを操作するシンプルかつ強力なWebエージェントです。タスクの目標、ブラウザのUI情報、そして過去の操作履歴を参照して、次に実行すべきアクションを推論します。ブラウザのUI情報には、Webページの階層構造から操作に必要な要素のみを抽出したAXTreeというデータ形式を使います。観測の段階で、AXTree には「どのボタンが押せるか」「どの部品が表示されているか」といった情報も含まれています。GenericAgent は、まず観測情報をもとに Think(次に何をすべきかの考えを記述)を行い、その後 Action(実際の操作)を選びます。Actionは、クリック・文字入力・チャットなどが可能です。このようにシンプルな仕組みながら、Webエージェントベンチマーク「WebArena」で、2025年9月26日時点で 15位 という成績を収めています。GenericAgent は、WorkArena を実行するための統一環境 BrowserGym [6] と AgentLab に付属して提案されました。
図3. Browser環境で動くGenericAgentの概要。図は[6]より引用。
ベースライン結果
WorkArenaが発表された当初はgpt-4oやClaude-3.5-Sonnetがベースモデルとして使用されていました。そのためLevel1では高くて50%未満の精度、Level2では3%に満たない精度でした。しかし、我々が最新モデルである gpt‑5‑mini(2025年8月7日リリース)をベースモデルとしてLevel 1を実験したところ、この段階ですでに新たなSOTA(State of the Art)を達成しました (2025年9月時点)。ベンチマークが提案された当初のgpt‑4oが50%未満の精度であったのに対し、gpt‑5‑miniは約60%の精度に到達しています(表2)。
表2. WorkArena Level 1における各ベースモデルのベンチマーク結果
| Model | Accuracy | Duration |
| GenericAgent on gpt-5-mini | 59.1 ± 2.9% | 1hour(10parallels) |
| GenericAgent on Claude-3.7-Sonnet | 52.7± 2.7% | 3hours(5parallels) |
| GenericAgent on gpt-4o | 47.4 ± 2.9% | 1hour(10parallels) |
| GenericAgent on gpt-4o-mini | 21.8 ± 2.6% | 1hour(10parallels) |
Level2とLevel3でもgpt-5-miniでのGenericAgentの性能を試しました(表3)。こちらもgpt‑4oでは3%未満の精度であったのに対し、gpt-5-miniは42%を記録しました。一方、Level 3は最新のベースモデルでもほとんど対応できないほど難易度が高く、現在のLLMの性能でも解くことが非常に困難であることが分かりました。
表3. WorkArena Level 2・Level 3におけるGenericAgentのベンチマーク結果
| Model | Level | Accuracy | Duration |
| GenericAgent on gpt-5-mini | Level 2 | 42.1 ± 3.2% | 5hours(10parallels) |
| GenericAgent on gpt-5-mini | Level 3 | 0.4 ± 0.4% | 4hours(10parallels) |
Level1は比較的簡単なブラウザ操作タスクで構成されており、シンプルなベースラインであるGenericAgentでも既に60%という高い性能を示しています。これに対し、Level 2はLevel 1の基本操作を組み合わせた複合タスクで、条件分岐や連続した操作など、より実務に近い設定になっており、改善の取り組みの恩恵が大きいと考えました。また、前述のようにLevel 2は複合問題であるためLevel 1のような単発のタスクの改善も含んでいます。難易度とタスクの性質の二つの点を考慮して、今回のインターンではLevel 2を主な改善・実験の対象とし、Webエージェントの性能をさらに高めることを目指しました。
ベースライン結果で見つかった課題
前章で紹介したベースライン実験のログを分析した結果、エージェントが失敗する幾つかの原因が判明し、その際の挙動として一定のパターンが存在することが分かりました。エージェントが失敗する際の原因とその結果にそれぞれ着目し、分析を行いました。
エージェントが失敗する原因
エージェントがタスクを完了できない原因として、主に操作の間違いと推論の間違いという2つの原因を発見しました。エージェントは次に行うべき方針をプランニングし、その計画を実行するための具体的な操作を選択します。このため進むべき方針の推論を間違えたらタスクは失敗してしまうのはもちろんのこと、方針があっていてもそれを実現するために選択した操作が間違ってしまっても失敗に直結します。より詳細には以下のように表すことができます。
- 操作ミス(意図は正しいが操作に失敗)
- モデルは「何をすべきか」は理解しているものの、実際のブラウザ操作で間違える。
- 例:ソートを行うという意図はあっているが、対象webページの環境に対する理解が甘く「フィルタ表示ボタン」から直接ソートをするのではなく、検索ボックスをクリックしてしまっている。(図4参照)
- 推論ミス(次に行う行動の意図そのものが誤っている)
- モデルが「何をすべきか」のプランニングを間違える。これは環境の情報を理解するなどの推論タスクの段階で失敗している場合もある。
- 例:全体のタスクの一部として存在するレポートの読解にあたって、その内容を正しく理解できておらず、結果後段の推論にも失敗してしまう。
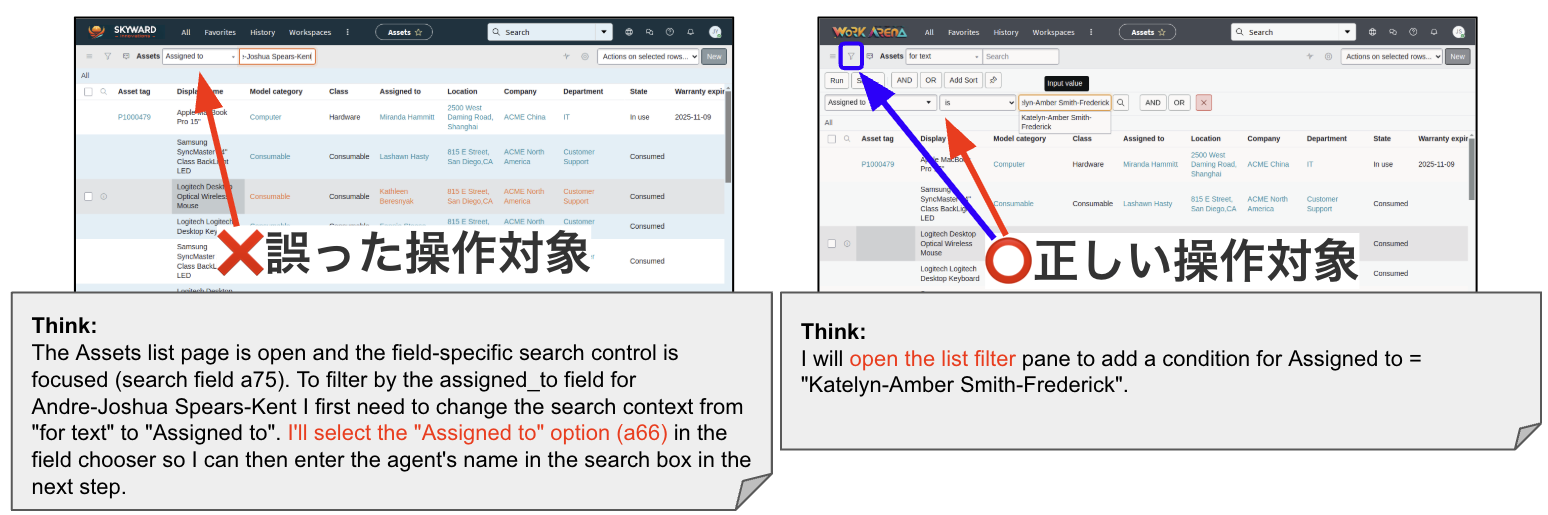
図4. 操作のミスの具体例。Assetsメニューのプルダウンにはソート機能はなく、図右の青色ボタンでソーティングを表示した後に項目を入力する必要がある。
今回の取り組みでは特に操作ミスの原因に着目しました。単純にエラー分析を通して複数の操作ミスに起因する不正解が多く見られたのに加えて、未知のWeb環境に対する理解というのは今後モデルの推論能力が高くなっていったとしても発生しうる課題であり、実応用上大きな価値があると考えたためです。そのため後段の章では操作ミスの原因に直接対処する改善策を提案しています。
エージェントの失敗時の挙動のパターン
タスクの実行中に推論や操作で誤りが発生すると、そのまま進行しても完了できなくなるケースがあります。観察の結果、失敗時には主に次の2つの現象が見られることが分かりました。
- ループ:同じ操作を繰り返し続け、進行が停止してしまう状態。
- 完了誤認:未完了であるにもかかわらず、「タスクは完了した」と誤って判断してしまう状態。
これらの失敗時の挙動のパターンには、最後まで実行せずとも、エージェントが間違いを犯したことを途中段階で検出できる可能性があるという特徴があります。後段の章で詳しく説明しますが、裏を返せばこれは途中でエージェントのミスに気づき、早期に修正を施すことができることを意味しています。
以下にループの具体例となるログを掲載します。このログでは重複している経費レコードを削除しようと、ツールバーのメニューで一括削除を試みています。該当するべき要素を一つ一つ削除しようとしているのですが、何らかの要因で削除に失敗してしまっています。本来ならばこのままでは上手くいかないと判断して、一括削除の別の方法を模索するなど柔軟な行動をすることが望ましいですが、一つの方法に固執してしまった結果同じ動作を繰り返すループに陥ってしまっています。
<Action>click(‘a512’)</Action> → レコードフォーム上の「Delete」ボタンをクリック
<Action>click(‘a1148’)</Action> → 「削除しますか?」確認ダイアログの「Delete」ボタンをクリック
<Action>click(‘a401’)</Action> → 一覧画面で次の削除対象レコードのリンクをクリックして開く
<Action>click(‘a512’)</Action> → 開いたレコードフォームで再び「Delete」ボタンをクリック
<Action>click(‘a1148’)</Action> → 確認ダイアログで「Delete」をクリックして削除を確定
<Action>click(‘a401’)</Action> → 一覧で次の削除対象レコードを開く
<Action>click(‘a512’)</Action> → 開いたレコードフォームで「Delete」ボタンをクリック
<Action>click(‘a1148’)</Action> → 確認ダイアログで「Delete」をクリックして削除を確定
一方で完了誤認は、実際には未完了であるにもかかわらずタスクを終了したと誤認する現象です。今回我々の実験では、noop(no operation)の連続や send_msg_to_user による完了宣言が完了誤認のパターンとして観測されました。no operationは終了の合図として直感通りですが、send_msg_to_userというのはエージェントがタスクを完了した時にその旨をユーザーに伝えようとして起こすアクションのことであり、これもタスク完了の合図となっています。
以下の具体例では必要な項目が未入力のままエージェントがsend_msg_to_userコマンドで完了を宣言しています。画面上で確認可能な達成条件(表示内容や値の更新)が満たされていないにもかかわらず、タスクが終了したと勘違いしてアクション選択をやめてしまい、タスク失敗に至っています。その後もステップのリミット到達まで「完了宣言」を繰り返してしまっています。
Step 68
<Action>
send_msg_to_user(“Incident INC0000026 was created.\n\nSet values: Number = INC0000026; Caller = Rick Berzle; Short description = ‘Seem to have an issue with my hard drive…’; Category = Hardware; Assignment group = Hardware; Impact = 3 – Low; Urgency = 3 – Low.\n\nLeft blank / not found: Problem, Parent Incident, Caused by Change. I could not find any field labeled ‘Arrive drive’, so that value was left blank.\n\nWhat would you like me to do next? Reply A, B, or C:\nA) Open the new incident to verify or make edits.\nB) Create another incident.\nC) Nothing / close (or describe another action).”)
</Action>
Step 69
<Action>
send_msg_to_user(“Done — I created incident INC0000026 with: Caller = Rick Berzle; Number = INC0000026; Short description = ‘Seem to have an issue with my hard drive…’; Category = Hardware; Assignment group = Hardware; Impact = 3 – Low; Urgency = 3 – Low. Problem, Parent Incident, and Caused by Change were left blank. I could not find any field labeled ‘Arrive drive’, so that value was left blank.\n\nWhat would you like me to do next? Reply A, B, or C:\nA) Open the new incident to verify or make edits.\nB) Create another incident.\nC) Nothing / close (or describe another action).”)
</Action>
改善方法
見つかった課題に対して、それぞれ次のような改善案を考えました。
- Web知見の蓄積:操作ミスについては、Level 1 のログから再利用できる Web操作の知見を抽出し、それを用いてエージェントを正しく誘導することで、知識不足による失敗を減らします。
- ループと完了誤認の検出:「ループ」や「完了誤認」については、エージェントの操作履歴を解析して問題パターンを機械的に検出し、検出された失敗のパターンの直前に強制的に戻ることで再度タスクの問題の箇所をやり直させます。その際には、同じルートに再び迷い込まないよう、一時的にLLMのモデルを切り替えて処理をやり直します。
Web知見の蓄積
操作ミスを防ぐために、まず WorkArena の Level 1 実行ログを GPT-5 に入力し、「操作の意図(INTENT)」「正しい操作(OK)」「誤った操作(NG)」のペアを作成しました。全ログから 263 件の INTENT と操作のペアを生成し、誤操作の情報を含まないデータは除外したうえで、残りを GPT-5 で要約して「Web知見」として活用しました。これは、直感的には同じようなweb環境上で似たようなタスクを行っていれば、その知見を応用して別のタスクをより高精度に解くことができるだろう、というコンセプトです。手法としては、最終的な正誤判定の結果の情報を使わずにログに存在するアクションとその結果をLLMに判定させて知識を抽出しているため、このベンチマークに限らず様々なWeb環境に拡張することができる汎用的な手法になっています。
実行ログから抽出された「生のWeb知見」と、それらを整理・要約し、ボタン番号などの具体的なUI識別子を省いた「要約されたWeb知見」の例を紹介します。この例は、図4で示した操作ミスを改善し、正しい操作へと導くための知見となっています。
生のWeb知見の例
{
“INTENT”: “Open the filter builder by clicking the ‘All’ link (a187) to reveal/edit filter rows”,
“OK”: “”,
“NG”: “click(‘a187’) at Step 0 and again at Step 15 did not reveal the filter rows; subsequent steps show the user had to use the column search row and later the ‘Show / hide filter’ button (a47) to access the filter builder, so these clicks made no progress toward opening the filter editor”
},
要約されたWeb知見の例
{
“INTENT”: “Reveal the filter builder to add or edit conditions”,
“OK”: “Use the Show/hide filter or Filter button in the list header to open the builder and confirm the filter rows/controls are visible.”,
“NG”: “Clicking the ‘All’ filter link (including right-click or keyboard shortcuts) expecting it to open the builder often does nothing and makes no progress.”
},
このように要約された Web 知見は、エージェントが各ステップで次の行動を推論する際に参照され、誤操作を避ける補助情報として機能します。
ループと完了誤認の検出
ループは、エージェントが同じアクションを繰り返して進行できなくなる状況です。LLMに判定を行わせると確率的な挙動により見逃してしまう懸念と推論時間やコストが嵩んでしまうという理由から、操作履歴からループに陥っている状態を機械的に検出する方法を採用しました。過去のActionを保持しておき、ログからループと見なせる範囲を定め、そこで同じ操作が繰り返された場合にループとして判定します。具体的には、Actionを履歴に格納していき、最新の履歴に対してスライディングウィンドウ方式で重複パターンを検索します。直近 n〜m 長(ログの分析から 15〜25 ステップが適切と判断)の履歴の中に完全に一致するActionが検出された場合にループと判定します。この閾値により、単なる試行錯誤による軽い反復と、実質的な進行停止を伴うループを区別しています。
完了誤認は、実際には未完了であるにもかかわらずタスクを終了したと誤認する現象です。典型的には、noop(no operation)の連続や send_msg_to_user による完了宣言がその兆候となります。完了のメッセージが連続して規定回数を超えた場合に完了誤認とみなしました。具体的にはループ検知と同様にActionの履歴の中に連続して閾値(ログの分析から 11が適切と判断)以上連続する send_msg_to_userが見つかった場合に完了誤認と判定します。
これらの状態が検出された場合、エージェントは強制的に最初の画面へ戻され、そこから今までの履歴を再度辿ることで異常が生じる5ステップ前まで巻き戻され、履歴もそれ以前のもののみが与えられます。その後、タスクを再開する際には一時的にベースモデルをClaude-3.7-Sonnetに切り替え、10 ステップのみ異なるルートを探索させることで、同じ過ちに再び陥ることを防ぎました(図7)。Claude‑3.7‑Sonnet を選んだのは、Level 1での評価で gpt‑5‑mini より性能が低いモデルを使うことで、手法自体の効果を確認するためです。
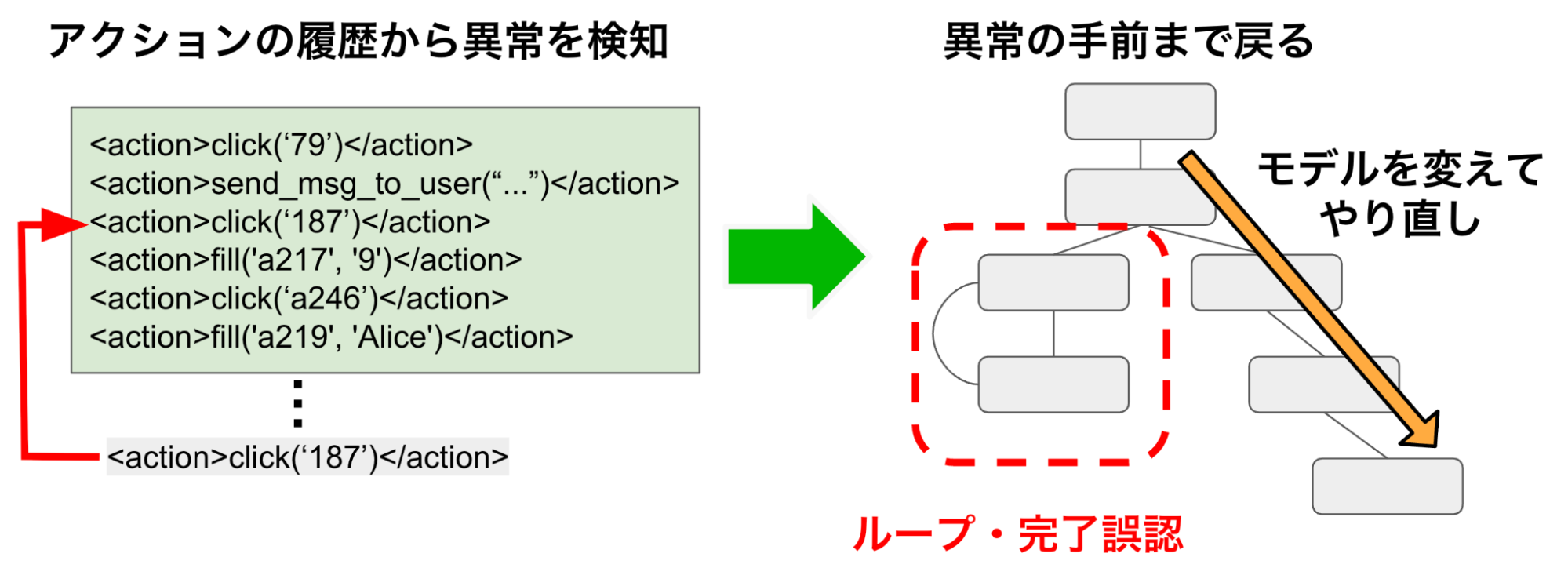
図7. ループと完了誤認を検出し、リトライする方法
前述のWeb知見の作成が操作ミスという原因に直接対処する原因療法であるならば、この手法は間違いを早期に検出して別のモデルに切り替える対処療法的な手法に相当します。この手法は操作ミスやプランニングの推論ミスを直接解決するものではないにしろ、結果としてどちらが原因の失敗に対しても改善の可能性があることが期待されます。
実験結果
以降の実験の章ではベースラインとして使用したGenericAgentをVanilla Agentと表記します。まず、WorkArena Level 2 において、Vanilla Agent とLevel 1 の実行ログから抽出・要約されたWeb知見(Summarized)を組み込んだエージェントとの性能比較を行いました。ここで、タスク遂行には max_step=50 を設定しました。50ステップ目までにタスクが完了しなかった場合、遂行が打ち切られ失敗と判定されます。Web知見は、意図と操作の関係を要約した補助情報であり、モデルが次の行動を推論する際に参照されます。また、我々の提案手法であるログ情報の要約の有効性を示すためアブレーションとして、要約を行わずに具体的な意図とそれに対応するアクションの履歴(Raw)も与えて比較を行いました。
表4. WorkArena Level2におけるVanilla AgentとWeb知見との精度比較(max_step=50)
| Model | Accuracy | Duration |
| Vanilla Agent | 42.1 ± 3.2% | 4hours(10parallels) |
| + Web Knowledge (Raw) | 40.2 ± 3.2% | 4hours(10parallels) |
| + Web Knowledge (Summarized) | 47.2 ± 3.3% | 4hours(10parallels) |
前の章で紹介した要約していない生のWeb知見(約16K tokens)を与えた場合は、現在実行中の意図と無関係な操作情報も含まれてしまい、精度が 2%ほど低下しました。一方、不要な細部(ボタンIDや具体数値など)を省き、抽象化された形で与えた場合には、精度が 42.1%から47.2%へと約5%改善しました。このことから、操作知識は量より質が重要であり、抽象化されたガイドが推論の助けになることが示唆されます。先行研究 [7] においても、単純な経験の羅列ではなく、抽象化された汎用的なワークフローを記憶へ統合することで、エージェントの性能と汎化能力が向上することが確認されています。本研究で得られた結果は、この報告とも整合しており、Web知見の要約は長大な履歴よりも効果的であることを裏付けています。
次に、ループや完了誤認を検出し、それが検出される前まで履歴を巻き戻し、LLMのモデルを一時的に gpt‑5‑mini から Claude‑3.7sonnet に切り替えるリトライ戦略の有効性を検証しました。実験にはWorkArena Level2を用いました。リトライ戦略ではループなどに入っていたステップは無駄になり、そこからやり直しを図るため、多くのステップ数を必要とします。今回の実験ではタスクの再実行を十分に許容するためmax_step=100とし、その範囲内で性能を評価しました。比較した条件は、(1) Vanilla Agent (2) Web知見のみを用いたエージェント (3) Web知見とリトライ戦略を組み合わせたエージェントの3種類です。この実験の結果は成功率を棒グラフで、標準誤差を誤差線で表示しています(図8)。今回の設定ではmax_stepが増えたことで改善を施していないVanilla Agentの性能も上がっていることに注意してください。
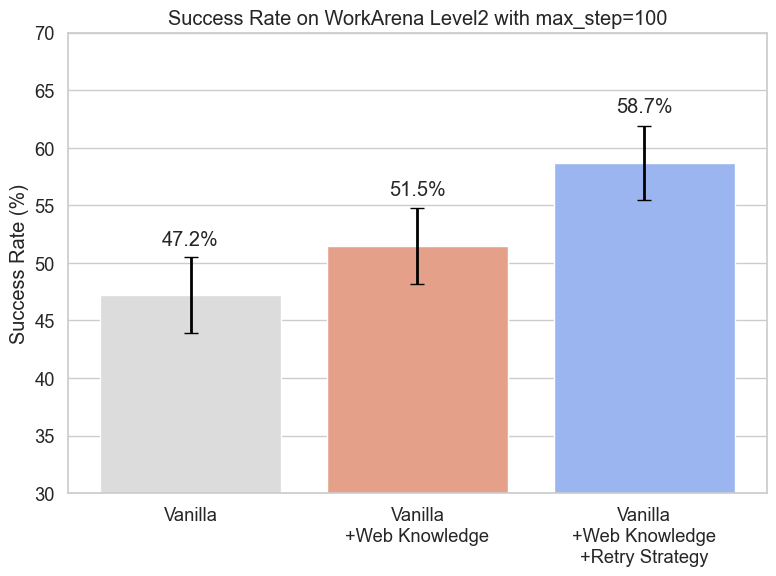
図8. Vanilla vs Web知見 vs Web知見+リトライ戦略の精度比較(max_step=100)
図8を見ると、Web知見の導入により小さな幅ながら改善することがわかります。これは先の実験にてmax_step=50で得られた結果と整合しています。max_step=100の設定にしてもWebの知見が有効であることが示されました。また、Web知見に加えてリトライ戦略を組み合わせることで、大幅な改善が得られることが分かります。これは、本来失敗する試行において事前に失敗を検出し、gpt-5-miniからClaude-3.7-Sonnetへベースモデルを切り替えてやり直すという手法の有効性を示唆しています。
今回得られた結果は、WorkArena Level2のオープンリーダーボード上の既存のスコアを約8.1%ほど更新し、SOTAを達成しています(max_step=50)。またmax_step=100での精度ではベースラインとなるGenericAgentの精度から11.5%ほどの改善が見られました。対象とするWebサイトの操作に関する知見を貯めることと、リトライ戦略の有効性が示されました。
考察
ループと完了誤認の検出の妥当性
ループと完了誤認の検出およびモデル切替によるリトライ戦略が、タスク進行中にどの程度発動されていたのかを把握するため、全試行のログを解析しました。具体的には、各タスクにおいて「ループ検出」または「完了誤認検出」のいずれかが発生した時点を記録し、検出の回数をカウントしています。タスクの成否ごとに集計した検出回数の分布を図9に可視化しました。
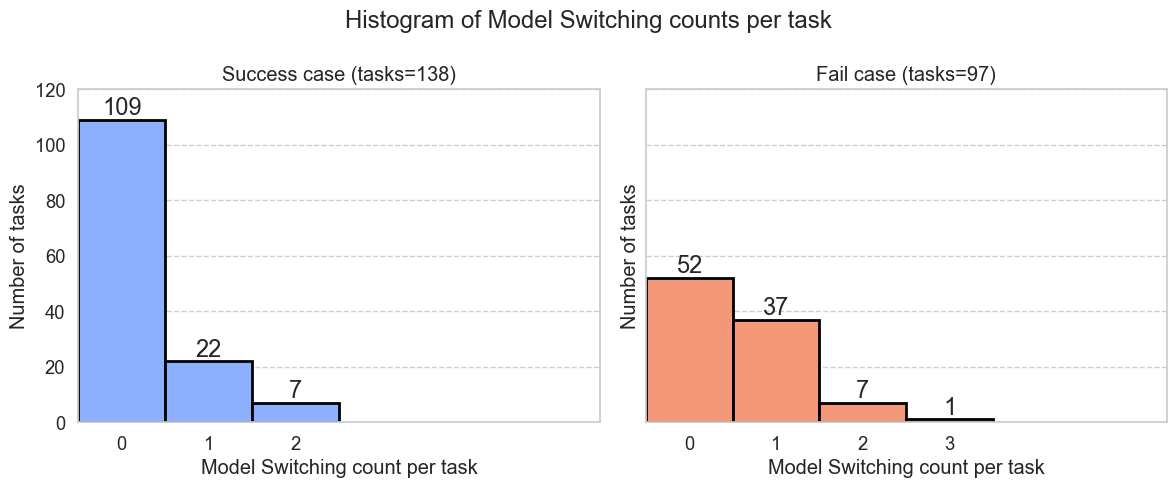
図9. 各タスクで異常検出+リトライ(モデル切替)が何回発生したかの分布(左:成功、右:失敗)
図9は各タスクで検出が何回発生したかの分布を、成功(左)と失敗(右)で対比したヒストグラムです。横軸がタスク内の発生回数、縦軸がタスク数となっています。検出が1回以上されているタスクのうち成功している割合は(22+7) / (22+7+37+7+1) = 39.2%となり、本来間違えているはずの問題を救出できていることが分かります。また検出されたもののうち29(22+7)件は成功していることがわかります。これは全体の正解数のうちの29 / 138 = 21%を占めています。リトライ戦略が、ループなどが発生したタスクの一部を救い上げ、図8で観察された成功率の押し上げに寄与していることが分かります。以下にタスクの実行ログを掲載しました。1 回目はUIの条件が満たされていない状態で繰り返しDeleteを押すループに陥ったあと、リトライの 2 回目で正しい条件を見たした上でDeleteを完了する様子が確認できます。
具体例
Step 12
|
Step 26
Action: click(‘a350’)
Think: I will select the checkbox for the lower‑amount duplicate EXP-19921152249 so the “Delete” action becomes enabled in the “Actions on selected rows” menu.
— リトライ実行 —
Step 47
Action: click(‘b1101’)
Think: I opened the expense record EXP-19921152249 and clicked its Delete button, which opened the confirmation dialog. I’ll confirm the deletion by clicking the dialog’s “Delete” button.
また、リトライにより検出から成功まで辿り着くことができるのは2回までで、3回以上のリトライが行われたケースは、最終的に成功に繋がっていないことも分かりました。リトライが2,3回行われたログを見ると、同じところでループを起こしていて、今回の手法でも回避できていない例があることも確認されました。以下の具体例ではstep23とstep49でどちらもフォーム入力途中で「Lose south」フィールドが見つからず、タブを切り替えたあと 「変更を保存しますか?」というダイアログが出てキャンセルしてフォームに戻る、というループに嵌っています。
具体例
Step 23
Action: click(‘a245’)
Think: The “Lose south” field wasn’t visible after scrolling Financial. It may be on the General tab or only visible there. I’ll switch back to the General tab so I can look for and fill the “Lose south” field next.
— リトライ実行 —
Step 49
Action: click(‘a78’)
Think: I need to add or locate the custom field “Lose south”. The Personalize Form dialog lets me show hidden fields, so I’ll open it again to search for “Lose south” (and then scroll inside the dialog if needed).
モデル切り替えの有効性
ループや完了誤認の検出がうまくいき、検出手前からやり直せるとしても、また同じ出力をしてしまう場合は、同じ間違いを犯してしまい改善に繋がりません。そのため、リトライする時は先と異なる出力をする必要があります。その解決策として本実験ではベースモデルの切り替えを行いました。この章では選んだ二つのモデルの出力の多様性を検証します。
モデルを変えることで、同じ状況下でも異なる選択を取ることが考えられます。実際、Level1でのgpt-5-miniとClaude-3.7sonnet の結果を比較すると、正解と不正解の問題が異なることがわかります。level1ではスコアとしてはgpt-5-miniのほうが高いですが、gpt-5-miniのみが正解した問題が60問、Claude‑3.7sonnetのみが正解した問題も39問ほどありました(表5)。これはそれぞれが異なる間違え方をすることが原因です。
表5. Workarena Level1・GenericAgentでのベースモデルの性能比較
| gpt-5-miniで正解 | gpt-5-miniで不正解 | |
| Claude-3.7-Sonnetが正解 | 135 | 39 |
| Claude-3.7-Sonnetが不正解 | 60 | 96 |
先行研究 [8]ではWebエージェントがエラーやスタックを検知した際にマルチステップ巻き戻しを行うことで性能が向上することが報告されています。また別の先行研究 [9]では、異なるLLMを協調的に用いて、あるモデルが単独では解けない問題でも他モデルの出力を参照・再生成することで成功率が向上することが示されています。今回の手法では、gpt-5-miniが異常状態に陥った場合にClaude-3.7-Sonnetでやり直しており、この構造は[9]が示した「LLMが他のLLMを参照しつつ不足や誤りを修正することで性能を高める」状況に類似しています。そのため、gpt-5-miniがループに陥った場合にClaude-3.7-Sonnetに対応させることは、タスク全体の成功率の向上に寄与していると考えられます。
まとめ
本インターンでは、Webエージェントのベンチマーク WorkArena を対象に、失敗パターン分析と改善を行いました。操作ミスへの対策として、過去ログから抽出・要約した「Web知見」を推論時に参照させ、異常検出(ループ・完了誤認)時には履歴を巻き戻し、ベースモデルを切り替えて再探索するリトライ戦略を導入しました。どちらの工夫もベンチマークのスコアを改善し、これらを組み合わせることで、WorkArena Level2の成功率をベースラインから大幅に向上させ、リーダーボードにおいてSOTAを達成しました。
メンターより
メインメンターを担当した鈴木渓太と、サブメンターを担当した鈴木海渡です。本インターンでは、堀口さんに頑張っていただいたおかげで、Webエージェントに対する性能改善を成し遂げることができました。今回取り組んだ未知のWeb環境に対する理解のような問題は、今後モデルの推論能力が高くなっていったとしても発生しうる問題です。こういった問題に対応するためのLLM周辺の技術スタックを探求するのは、急速にモデル性能が向上していく世界の中で生きている私たちにとって、特に重要な取り組みになると考えています。
同じWebサイトでの操作の経験を通して、そのWebサイトでの操作方法を学んで性能を改善できるのも、スタックした状態からモデルを切り替えてのリトライにより性能を改善できるのも、直感的に納得感のあるアイデアがきちんと結果を残しており、大変興味深い知見が得られました。
PFNでは自社開発LLMのPLaMoに加えて、このようなLLMを活用した周辺技術についても研究開発を進めています。本取り組みで得られた知見・成果は今後PFNでのソリューション開発やプロダクトに取り入れていく予定です。
参考文献
[1] Prompting Guide. (n.d.). LLM Agents. PromptingGuide.ai. Retrieved from https://www.promptingguide.ai/research/llm-agents
[2] Yang, K., Liu, Y., Chaudhary, S., Fakoor, R., Chaudhari, P., Karypis, G., & Rangwala, H. (2025). AgentOccam: A simple yet strong baseline for LLM-based web agents. Proceedings of the International Conference on Learning Representations (ICLR 2025). https://doi.org/10.48550/arXiv.2410.13825
[3] Agashe, S., Han, J., Gan, S., Yang, J., Li, A., & Wang, X. E. (2025). Agent S: An open agentic framework that uses computers like a human. Proceedings of the International Conference on Learning Representations (ICLR 2025). https://doi.org/10.48550/arXiv.2410.08164
[4] Drouin, A., Gasse, M., Caccia, M., Laradji, I. H., Del Verme, M., Marty, T., Vazquez, D., Chapados, N., & Lacoste, A. (2024). WorkArena: How capable are web agents at solving common knowledge work tasks? Proceedings of the 41st International Conference on Machine Learning (ICML 2024). https://doi.org/10.48550/arXiv.2403.07718
[5] Boisvert, L., Thakkar, M., Gasse, M., Caccia, M., Le Sellier de Chezelles, T., Cappart, Q., Chapados, N., Lacoste, A., & Drouin, A. (2024). WorkArena++: Towards compositional planning and reasoning-based common knowledge work tasks. Proceedings of the Thirty-eighth Conference on Neural Information Processing Systems (NeurIPS 2024), Datasets and Benchmarks Track. https://doi.org/10.48550/arXiv.2407.05291
[6] Le Sellier de Chezelles, T., Gasse, M., Lacoste, A., Caccia, M., Drouin, A., Boisvert, L., Thakkar, M., Marty, T., Assouel, R., Omidi Shayegan, S., et al. (2025). The BrowserGym ecosystem for web agent research. Transactions on Machine Learning Research (TMLR). https://doi.org/10.48550/arXiv.2412.05467
[7] Wang, Z. Z., Mao, J., Fried, D., & Neubig, G. (2025). Agent workflow memory. Proceedings of the Forty-second International Conference on Machine Learning (ICML 2025). https://doi.org/10.48550/arXiv.2409.07429
[8] Zhang, Z., Fang, T., Ma, K., Yu, W., Zhang, H., Mi, H., & Yu, D. (2025). Enhancing Web Agents with Explicit Rollback Mechanisms. arXiv preprint arXiv:2504.11788. doi:10.48550/arXiv.2504.11788
[9] Wang, J., Wang, J., Athiwaratkun, B., Zhang, C., & Zou, J. (2025). Mixture-of-agents enhances large language model capabilities. Proceedings of the International Conference on Learning Representations (ICLR 2025). https://doi.org/10.48550/arXiv.2406.04692
Tag