Blog
Writers: Richard Calland, Tommi Kerola
Preferred Networks (PFN) attended the CVPR 2017 conference in Honolulu, U.S., one of the flagship conferences for discussing research and applications in computer vision and pattern recognition. Computer vision is of major importance for our activities at PFN, including applications for autonomous driving, robotics, and of course products such as PaintsChainer. Modern computer vision is largely based on deep learning, which is relevant for our continued research and product development. In this blog post, we will briefly summarize trends from this conference, focusing on a few papers relevant to each topic.

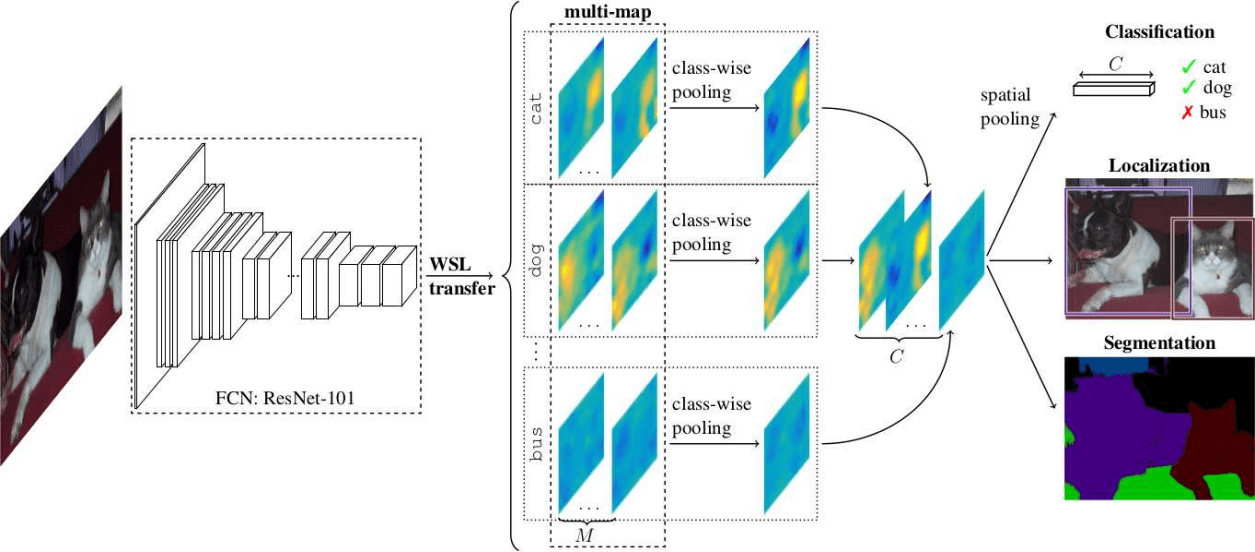
(Durand et al. WILDCAT: Weakly Supervised Learning of Deep ConvNets for Image Classification, Pointwise Localization and Segmentation, CVPR 2017)
Weakly supervised methods were popular, which indicates researchers are thinking about the problem of circumventing the need to do costly dense labelling of datasets, which is the downside of supervised learning. One such approach is WILDCAT, which generalizes global average pooling from CVPR 2016 to have multiple attention maps for each class. In conjunction with a separable class-wise and spatial pooling technique, it achieves competitive performance for jointly learning the tasks of image classification, pointwise object localization, and semantic segmentation. Another method falling into this category uses web-crawled noisy Youtube videos for generating weak labels to be used for the learning task. Yet another paper uses millions of images with noisy annotations together with a small subset of clean annotations to help learn a better classification model.

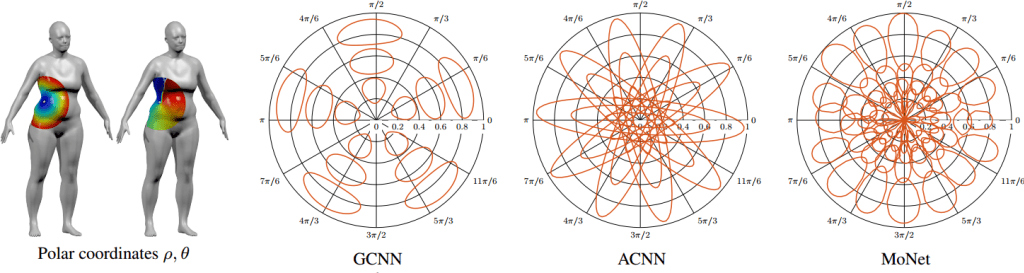
(Monti et al. Geometric deep learning on graphs and manifolds using mixture model CNNs, CVPR 2017)
Graph convolutions were popular at this conference, with several papers on this topic and even two tutorials. This includes approaches such as MoNet, which generalizes previous spatial graph convolution approaches by expressing the patch operator weights as a Gaussian mixture model. This approach is able to show better generalization between graph structures, compared to spectral graph convolution methods. Another paper uses edge-conditioned filters for the graph convolution, which is able to exploit additional data attaches to the edges. This increases performance while avoiding the spectral domain, which also allows their approach to handle graphs of varying size and connectivity.
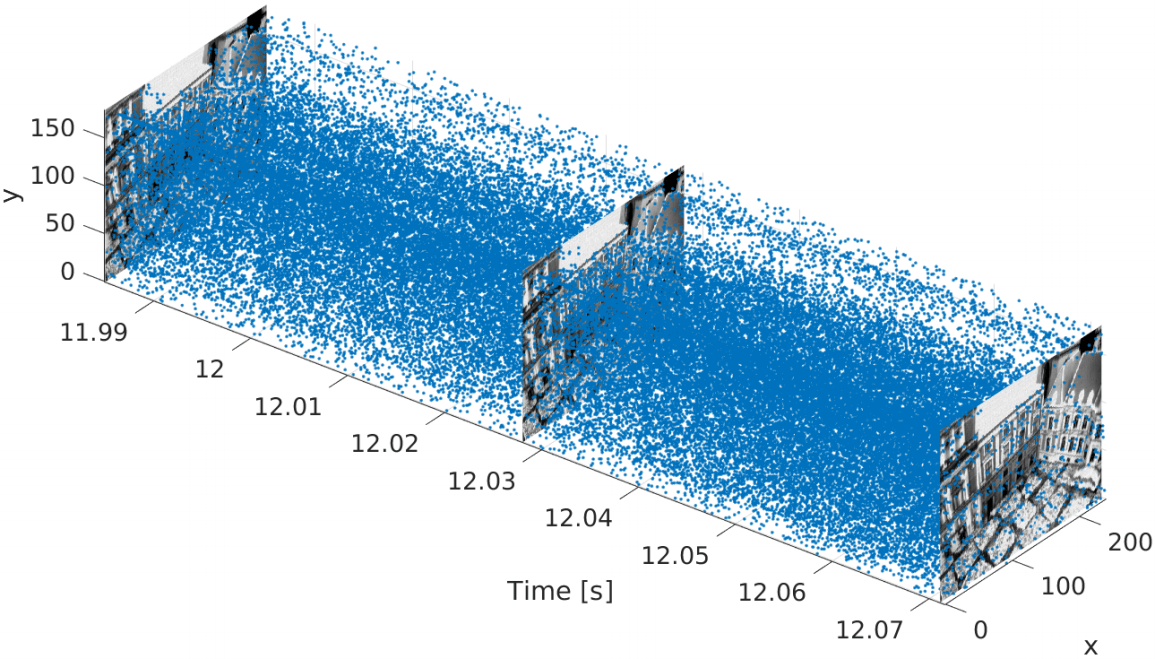

(Mueggler et al., The Event-Camera Dataset and Simulator: Event-based Data for Pose Estimation, Visual Odometry, and SLAM, IJRR 2017)
Event cameras are gaining a lot of attention and uses in computer vision, including applications such as odometry and gesture recognition. Event cameras register relative changes in pixel intensity rather than capturing absolute pixel intensities per frame. This produces an asynchronous output, as events are only created when a change in pixel intensity is detected. The benefits of such a camera are a very high dynamic range, no problems with motion blur, microsecond latency and low power usage. Unfortunately, due to the different structure of data produced by the camera, many computer vision algorithms are not able to be used. Devices called light field cameras also made an appearance, where the direction of incoming light is recorded, allowing the user to change the focus and perspective of the image after capture. At the conference, a dataset for experimenting with this type of data was announced, which should foster further research using these types of sensors.

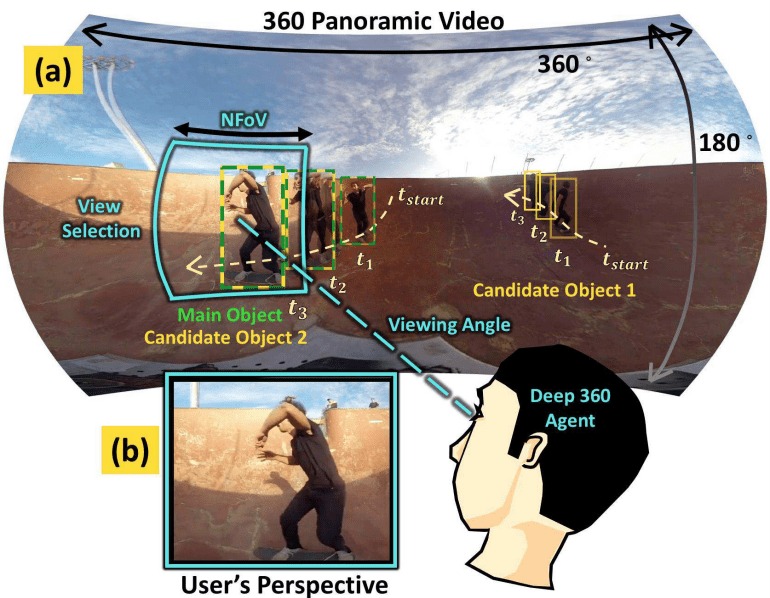
(Hu et al. Deep 360 Pilot: Learning a Deep Agent for Piloting through 360◦ Sports Videos, CVPR 2017)
Attention/saliency was popular, both for weakly supervised training, image captioning, and also for transforming panorama (360 degree) videos into a standard 2D video with a virtual camera that focuses on the interesting content in the video. An interesting paper in this area proposes to spatially adapt the computation time of the forward pass in residual networks, allowing their method to retain accuracy, while achieving twice the computational speed. Finally, approaches for question answering were leveraging attention as well. For instance, one paper proposed an approach for both answering questions about what is occurring in a video, using attention to detect concept words. The resulting framework is also applicable for the tasks of video captioning and retrieval as well.

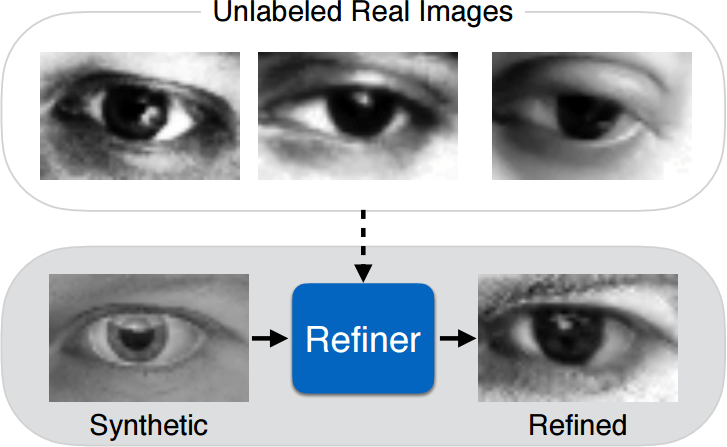
(Shrivastava et al., Learning From Simulated and Unsupervised Images Through Adversarial Training, CVPR 2017)
Many approaches to domain adaptation were shown at CVPR. Domain adaptation tackles the problem of generalizing a method trained on one dataset to another dataset in a different domain. These methods are usually semi-supervised or unsupervised, the latter being the more difficult yet desirable approach. Learning From Simulated and Unsupervised Images Through Adversarial Training and Unsupervised Pixel-Level Domain Adaptation With Generative Adversarial Networks both learn a refiner network from unlabelled data to add realism to simulated images, which can be thought of as moving simulated images into the natural image domain. Adversarial Discriminative Domain Adaptation bypasses the need to learn a generator and instead applies adversarial training directly on the feature vectors inside the classifier itself. Other approaches which avoid adversarial training include Deep Hashing Network for Unsupervised Domain Adaptation and Learning an Invariant Hilbert Space for Domain Adaptation.


(Wang et al. TorontoCity: Seeing the World with a Million Eyes, arxiv 2016)
Along with lots of interesting research, many new and exciting datasets were announced. Specifically for autonomous driving development, the very ambitious and impressive TorontoCity benchmark was shown, which covers the full greater Toronto area. It is said to be released in conjunction with ICCV 2017 later this year. Berkeley DeepDrive also described their upcoming Berkeley DeepDrive video dataset (BDD-V) which promises to contain 100,000 hours of driving video with full IMU and GPS data included. These data contain more drive-time than the average human will experience in their lifetime, and so it is sure to provide a boost to progress in self-driving vehicle development. Along with these huge general datasets, more task-specific benchmarks were announced such as a new depth dataset in the KITTI benchmark, which will contain roughly 93000 images with LIDAR data.
Overall, this year’s CVPR was very interesting and much larger than before. Almost 5000 people attended for six days of workshops, tutorials, poster sessions, and inspiring talks. At PFN, we are certain that the knowledge gained during this conference will prove beneficial to our future research activities, as computer vision is a central topic at our company. Indeed, we recently released the open source library ChainerCV, which is an extension library built on-top of Chainer, to speed up computer vision research by making common reference architectures and functions readily available. At this year’s ACMMM, we will present a paper describing this library. The next conference, CVPR 2018, will be held from June 18-22, 2018, in Salt Lake City, Utah, U.S.
Area



