Blog
乱雑に積まれた物体を取り出す産業用ロボットの動作を、ディープラーニングで学習しました。
こんにちは、松元です。今回は、国際ロボット展2015にてFANUCブースで出展した「バラ積みロボットの0から学習」について解説したいと思います。
まずは次の動画をご覧ください。
背景
「物を取る」というのはロボットの最も基本的なタスクの一つで、あらゆる場面で必要となります(たとえば産業用では、カゴから部品を取り出してベルトコンベアに乗せるといった用途で頻繁に使われます)。このときに、取るべき部品が決まった位置に整然と並んでいたり、平らな面に一つだけ置かれているなら簡単なのですが、箱にぐちゃっと積まれたところから一つ取り出したいというケースもあります。このようなタスクをバラ積み取出しといいます。
いま、3Dカメラによってバラ積みされた領域の深度付き画像が得られているとして、取り出したい対象(ワークという)の座標を返すことを目標とします。通常は次のような手法が用いられます。
- 取りたいワークの写真やCADデータとパターンマッチして、目標位置を探す
ワークの形状が予め完全に分かっている場合に有効です。
- ある程度以上の面積の平らな場所を探して、そこを目標とする(吸着やマグネット式のハンドの場合)
こちらはワーク形状が未知の場合にも使えます。

既存手法(FANUCの製品)によるワーク位置の検出
しっかりチューニングを行えば高い精度が出る
しかし、いずれの手法でも、判別の閾値などのパラメタチューニングには熟練を要します。また、特定のハマりパターンがあったときに、それを回避するのが難しいという問題もあります(今回取り組んだ円柱ワークの場合、ワークが複雑に重なっている時や、円柱が2つピッタリくっついて並んでいるときなどに、誤検出することがありました)。
今回私たちはディープラーニングを用いることで、このような問題を解決し、既存手法の熟練者によるチューニングに匹敵する精度を自動で達成することができました。
手法
セットアップ
・ワーク
鉄製の円柱(高さ5.0cm, 直径2.5cm)が200個程度箱にバラ積みされています。

ワークを吸着して持ち上げている様子
・ロボット
取り出しには、FANUC製の「LR Mate 200iD」というロボットアームを用いました。ロボット展の会場を見渡すと、あちらこちらで使われているのを目撃できるくらい、産業用では広く使われている優秀な機体です。
このアームは同じくFANUCの「R-30iB」というコントローラーから制御します。
PCからコントローラーに目標座標(x, y, z, yaw, pitch, roll)を指示すれば、そこに移動するまでの経路を自動で計算して正確に動いてくれます。
動作も高速で、3秒に1つくらいのペースでワークを取っていくことができます。

・ハンド
ロボットの先端に取り付け、ワークとコンタクトする部分をハンドといいますが、
今回は空気による吸着式のハンドを用いました。
先端はジャバラ状になっていて、多少ワークが傾いていても取ることができます。
吸着動作後に気圧を測ることで、ワークの取得に成功したか失敗したかを自動で判別します。
・ビジョンセンサ
箱の上方に3Dカメラがついていて、箱内部の深度付き画像を取得します。
3Dカメラとロボットの座標系の対応をキャリブレーションして、
深度付き画像から、ロボットの移動目標座標を求められるようにしてあります。
学習
学習は次のような流れで行います。
(1) 深度付き画像を撮影する
(2) 現在の予測モデルのもとで最善の(x, y)を選ぶ(学習初期では領域内の点をランダムに選ぶ)。深度付き画像からzが求まるので、この(x, y, z)を目標座標とする
(3) (x, y, z)にロボットを動かし、ワークの吸着を試み、成否を取得する
(4) (x, y)周辺の深度付き画像を切り出して、成否のラベルと組にして保存する
(5) 現在得られているデータから、画像から取得成否を予測するモデルを学習してアップデートする(この処理は数百回おきに行う)
(6) 以上を繰り返す

集めたデータの一例。こういったラベル付きデータから、CNNを教師あり学習する
予測モデルにはChainerで実装したCNN(convolutional neural network)を用いました。目標座標周辺を切り出した深度付き画像を入力とし、取得成功確率が出力となります。
(5)での学習処理は教師あり学習ですが、学習に用いるデータセットの構築に現在のモデル自身を用いるため、能動学習の一つと捉えることができます。
ロボットを動かすのはPCから自動で指示が送れるので、ときどき空になった箱をリフィルする以外は自動でサイクルを回すことができます。ディープラーニングではデータの数を揃える必要があるので、ほっとけばどんどんデータが集まってくるという設定にすることはとても大事です。
結果
学習当初のランダムモデルでは50%ほどの取得成功率だったものが、
学習データが集まるにつれて、2000データ(約4時間)で70%、5000データ(約10時間)で90%の取得率を達成できました。
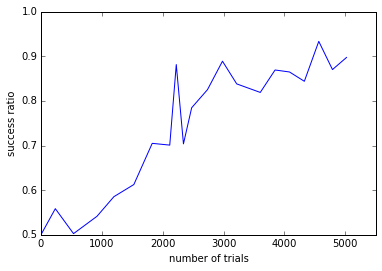
学習に伴う取得成功率の向上
学習の進捗は、実際の撮影された画像に対して、CNNがどのような評価値を出力しているかを可視化することでも評価できます。
下の図は、1000データ学習後と5000データ学習後のCNNで、同じ盤面に対して評価値を出力させた図になります。明るい色で塗られている部分が、「取れる」と判断した座標になります。

学習による予測精度の向上
基本的には他のワークが上に重なっていないワークの、側面あるいは端面の中心付近を狙えば取得に成功しますが、
1000データ学習の時点でも大まかにはその性質が学習できていることが分かります。
しかし、青い丸が付けてあるところのように、ワークとワークの境界部分や、上に他のワークが重なっているワークにも高い評価値が割り振られているところがあります。このようなエラーが、5000データ学習後にはぐっと減っていることが分かります。
このような精度の改善は、取りやすいワークを全て取ってしまった後のような難しい局面にて威力を発揮します。
学習前は何回も連続で失敗してしまうようなところで、数少ない取れるワークを正確に狙うことが出来るようになり、90%の取得率を達成できるのです。
本手法の意義
- 熟練を要するチューニングのプロセスを、自動で行うことができるようになりました
ある程度までは手動チューニングで精度を高め、それでどうしても誤検出するケースを学習で改善するという使い方もできます
- 取得するワークの形状が不定の場合にも適用できます
食材を扱うロボットや、ゴミを分別するロボットといった応用が考えられます
- 転移学習が可能
Deep Learningの優れている点として、汎用的なモデルをひとつ作ってしまえば、様々なタスクに転移できることが挙げられます(imagenetの画像分類タスクで学習したモデルが、画像からのキャプション生成に使えるなど)。
バラ積み取出しにおいても、複数種類のワークで学習を行ったり、シミュレータ上で大量に学習したものを、転移学習することも可能でしょう
- 分散学習が可能
複数台で同時にデータを集めれば、それだけ高速に学習できます
関連する研究
Supersizing Self-supervision: Learning to Grasp from 50K Tries and 700 Robot Hours
一般物体をハンドで掴むロボット。本研究と同じように、ランダムに掴むところからデータを貯めて学習を行う。取得したい物体が任意の一般物体であり、ハンドも挟むタイプのものであるため難しい問題設定。700時間という時間をかけても取得成功率は70%くらいでちょっと悲しい。
Dex-Net 1.0: A Cloud-Based Network of 3D Objects for Robust Grasp Planning Using a Multi-Armed Bandit Model with Correlated Rewards. Ken Goldberg, et al. ICRA 2016
UC BerkeleyとGoogleの共同研究で、Bay area robotics symposium 2015で発表があった。
10000種類の物体の3Dモデルを用意して、シミュレータ上でどこが掴みやすいかを1000台のマシンで並列に学習するという。
産業用ロボットは指示されたとおりに非常に正確に動き、また、学習初期の頃から実機でいきなり実験すると物を壊してしまう可能性もあるため、シミュレータを使うことは理にかなっている。
一方で、バラ積み取り出しのよくある失敗例として、取得動作の際にワークが崩れて動いてしまったり、ワーク間の光の反射によって位置推定がずれたりといった、シミュレーションしにくい要素が絡んでいることも事実である。
シミュレータで得た学習結果を、いかに実機に適用するのかというのは今後の大きな課題であろう。
Area



