Blog
I am Takeru Miyato, a researcher at Preferred Networks (PFN), and I participated in ICLR 2017 (4/24-4/26), which is the biggest conference on deep learning research.
Let me give you a brief overview of the event. ICLR has been held since 2013 and this was the fifth ICLR. The main features of ICLR are:
- Focus on deep learning and its application. Most of the papers focus on neural networks.
- Adaptation of open review system. Everyone can join the review process. To be precise, everyone can see the all of the reviews and rebuttals and also can comment, ask questions, and post his or her reviews as public reviews. In addition, authors can update their paper anytime from the feedback until the end of the discussion phase.
As far as I know, there is no other conference exposing the all of the reviews and rebuttals to the public, which I think is interesting / helpful to the people who write or review research papers. Also, some people analyzed the submissions and reviews, and they posted articles with interesting results. Here are some links to a pair of interesting ones:
- https://medium.com/@karpathy/iclr-2017-vs-arxiv-sanity-d1488ac5c131
- https://prlz77.github.io/2017 ICLR-stats/
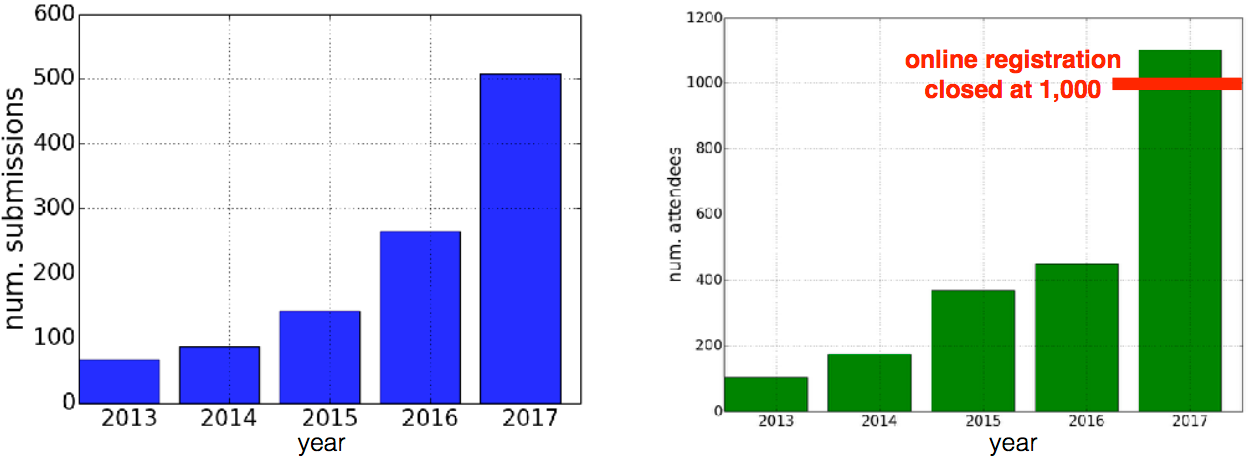
Let’s move on to this year’s ICLR. This was my second time participating in ICLR. First of all, I was surprised at the growing of the scale of ICLR! Last year, the participants were less than 500 and less than 80 papers were accepted, but this year there were over a thousand participants and almost 200 papers were accepted. ICLR 2017 was twice as big as last year.
 http://www.iclr.cc/lib/exe/fetch.php?media=2017 ICLR:ranzato_introduction_2017 ICLR.pdf
http://www.iclr.cc/lib/exe/fetch.php?media=2017 ICLR:ranzato_introduction_2017 ICLR.pdf


(Taken by Dr. Okumura @ DeNA)
In this year’s ICLR, I presented 2 papers (1 conference poster, performed at Google Brain and 1 workshop paper done after joined PFN)
- Adversarial Training Methods for Semi-Supervised Text Classification, T. Miyato, A. M. Dai, and I. Goodfellow
- Synthetic Gradient Methods with Virtual Forward-Backward Networks, T. Miyato, D. Okanohara, S. Maeda, and M. Koyama
The popular topics at this year’s ICLR were deep reinforcement learning, generative adversarial networks, and generalizability of neural networks (NNs).
Among those popular topics, I give brief introduction of ICLR papers focused on the generalizability of NNs.
In Understanding Deep Learning Requires Rethinking Generalization (awarded as one of the best papers at ICLR 2017), the authors show that neural networks easily fit random labels even with some popular regularizations such as weight decay and data augmentation. This result suggests that conventional complexity measures, such as Rademacher complexity, cannot explain the generalizability of NNs, and we need to seek a new measure or tool to analyze/explain the generalizability of NNs.
As for the nature of NNs, there are quite a few local minima, and some of them should have relatively bad generalization performance. The authors claim that the reason why the solutions of NNs don’t converge to such bad local minima may be thanks to SGD optimization. Actually, it is well-known that the SGD solution on the linear system will converge to the minimum L2 norm solution when the number of parameters is larger than the number of samples (p>>n). This is often called implicit regularization by SGD.
Many recent papers concerned with the generalizability of NNs refer to and adopt random label experiments. Consequently, this paper is worth reading for the people who are interested in the generalizability of NNs.
Another interesting topic related (possibly) to the generalizability of NNs is the existence of adversarial examples. We have already seen that the performance by the state of the art CNNs is almost equal to humans in image classification tasks. However, such CNNs are still vulnerable to small perturbations of input examples in a specific direction. Such perturbed examples are called adversarial examples.
In Adversarial Learning at Scale, the authors conducted various experiments on adversarial examples with state of the art CNN architectures trained on ImageNet. It seems that there are many ideas for future study of adversarial examples. Also, in Adversarial Examples in the Physical World, the authors show that adversarial examples actually are able to exist in the real world, not only in simulated situations.
The relationship between the robustness of input (e.g. robustness to adversarial examples) / parameter (like in On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima) space and the generalization performance of NN is a very interesting topic, and there have been already various papers referring to this relationship.
Here are some other interesting papers on the generalizability of NNs that came out after ICLR:
- Sharp minima can generalize for deep nets
- Exploring Generalization in Deep Learning
- A Closer Look at Memorization in Deep Networks
- The Marginal Value of Adaptive Gradient Methods in Machine Learning
- Spectral Norm Regularization for Improving the Generalizability of Deep Learning (Written by PFN)
Thanks for reading this blog post, and let us announce the our next presentations — at this coming ICML (August 6-11, 2017), we will present three papers (two conference papers and one workshop paper). I worked on two of these three papers.
The first one was written by Weihua Hu, as his internship project at PFN. We achieved state of the art performance on both unsupervised clustering and hashing utilizing the VAT regularization that I have been working on and prior knowledge of data augmentation.
The second one (which will appear in the Implicit Models workshop) is work on a new normalization/reparametrization method for improvement on generative adversarial networks (GANs), which is easy to incorporate into any existing GANs methods.
Please stop by our presentations at the ICML 2017 in Sydney!
- Evaluating the Variance of Likelihood-Ratio Gradient Estimators (to appear in the ICML 2017 proceedings). S. Tokui and I. Sato (Univ. of Tokyo).
- Learning Discrete Representations via Information Maximizing Self-Augmented Training. W. Hu (Univ. of Tokyo), T. Miyato, S. Tokui, E. Matsumoto and M. Sugiyama (Univ. of Tokyo)
- Spectral Normalization for Generative Adversarial Networks. (ICML 2017 Workshop on Implicit Models) T. Miyato, T. Kataoka, M. Koyama (Ritsumeikan Univ.) and Y. Yoshida (NII).
Tag