Blog

We are pleased to announce the second major version of Optuna, a hyperparameter optimization (HPO) framework in Python, is now available on PyPI and conda-forge. See the release notes on GitHub for the list of changes.
Starting from January this year when the first major version was released, we have seen tremendous effort from the community in terms of pull requests, issues, use cases beyond the scope of general HPO and much more. The framework has grown to accommodate a multitude of new features, including assessments of hyperparameter importances, sophisticated pruning algorithms for saving compute resources, and tight integrations with LightGBM. This blog will walk you through those updates and explain how the project evolved from version 1.0. We will also share future roadmaps to give a glimpse of what to expect in the coming releases.
If you have used Optuna before, you should feel right at home. If you’d like an introduction to the framework, take a look at the previous blog which explains the concepts behind Optuna.
- New Features
- Hyperparameter Importances
- Performance Improvements
- Hyperband Pruning
- New CMA-ES Sampling
- Integration
- Documentation
- PyTorch Collaborations
- What’s Ahead
- Contributors
New Features
Here are some of the most significant features included in this release.
Hyperparameter Importances
While Optuna is designed to cope with any practical number of hyperparameters, it is generally a good practice to keep the numbers low, reducing the dimensionality of the search space. The truth is, only a few parameters are dominant in determining the overall performance of the model in many cases. Starting from version 2.0, a new module `optuna.importance` is introduced. This module comes with features allowing you to assess the contributions of each hyperparameter to the overall performance, `optuna.importance.get_param_importances`. This function takes a study and returns a dictionary mapping hyperparameters to their respective importances, floats in the range of 0.0 to 1.0. The higher the value, the more important. You can also try different hyperparameter importance assessment algorithms with the `evaluator` argument, including fANOVA, a sophisticated algorithm based on random forests. Because various algorithms evaluate importances differently, we plan to increase the number of available algorithms in coming releases.
study.optimize(...) importances = optuna.importance.get_param_importances(study)
Specify which algorithm to use.
importances.optuna.importance.get_param_importances( study, evaluator=optuna.importance.FanovaImportanceEvaluator() )
Instead of processing the importances yourself, a Plotly figure can be created with `optuna.visualization.plot_param_importances` with the same interface as `optuna.importance.get_param_importances`. This could be useful for visual inspection.
fig = optuna.visualization.plot_param_importances(study) fig.show()
Here is an example of plotted importances from a neural network written using PyTorch. We can see that the learning rate `lr` has the largest impact.
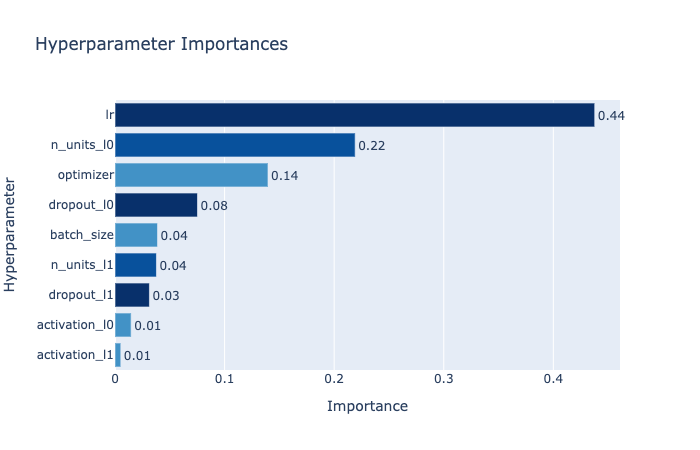
Hyperparameter importances assessed using mean decrease impurity. Different colors are used to distinguish between integers, floats and categorical hyperparameters.
Performance Improvements
You can now sample hyperparameters, prune unpromising trials, or in general work with optimization histories significantly faster with the relational database (RDB) storage. Many improvements were made at the lower storage layer, responsible for persisting trial data (which is especially important in distributed training when workers share data through these tables), using clever caching and smarter database queries. This opens up Optuna for a wider range of black-box optimization problems. The improvements are especially noticeable when running lightweight objective functions or when running larger numbers of trials in the order of hundreds or thousands, where sampling was a bottleneck.
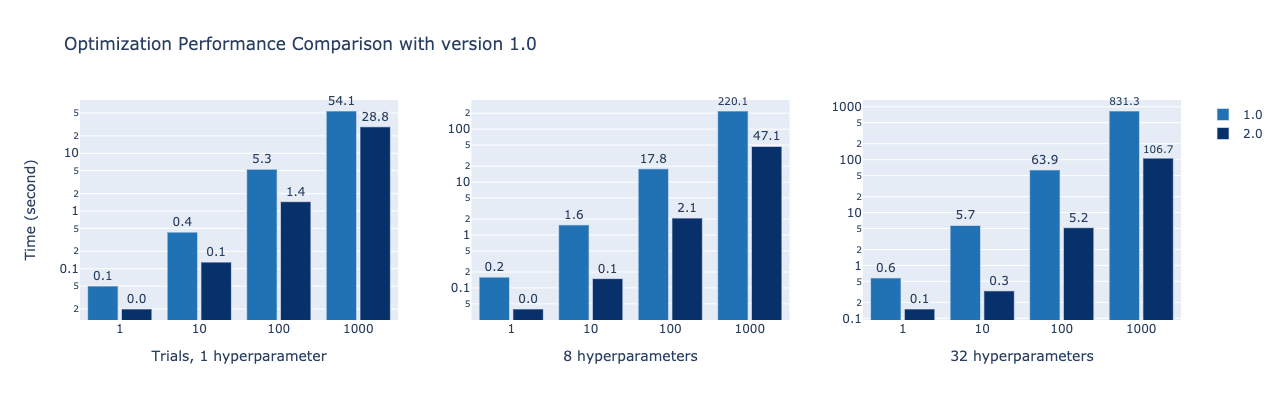
Comparisons of time taken for optimization with version 1.0, with simple objectives function that suggests floats using the Tree-structured Parzen Estimator (`TPESampler`). Version 2.0 is significantly faster when the number of hyperparameters and trials increase. Note that the `TPESampler` must fetch all previous trials in each suggestion, and that the y-axis is logarithmic. MySQL database storages are used in all experiments.
Hyperband Pruning
Pruning can be crucial for optimizing computationally demanding objective functions. It allows you to efficiently stop unpromising trials at early stages to save computational resources, consequently finding good optimums in shorter times. This is often the case in deep learning, a common use case for Optuna. Here, one may have to train neural networks consisting of millions of parameters spanning hours or days of processing. Hyperband is a pruning technique that extends upon the previous Successive Halving algorithm (`SuccessiveHalvingPruner`). Successive Halving can significantly reduce the time required per trial, but is known to be sensitive to how it is configured. Hyperband addresses this problem. While it comes in many flavors, Optuna uses heuristics to reduce user configuration requirements even further, making it easy to adopt without technical backgrounds. It was first introduced in version 1.1 as an experimental feature, and is now stable in terms of interface and performance. Our experiments show strong results on common benchmarks against previous pruners, including the median pruner (`MedianPruner`), the default pruner in Optuna. You can see the results from one of the benchmarks below.
study = optuna.create_study( pruner=optuna.pruners.HyperbandPruner(max_resource=”auto”) ) study.optimize(...)
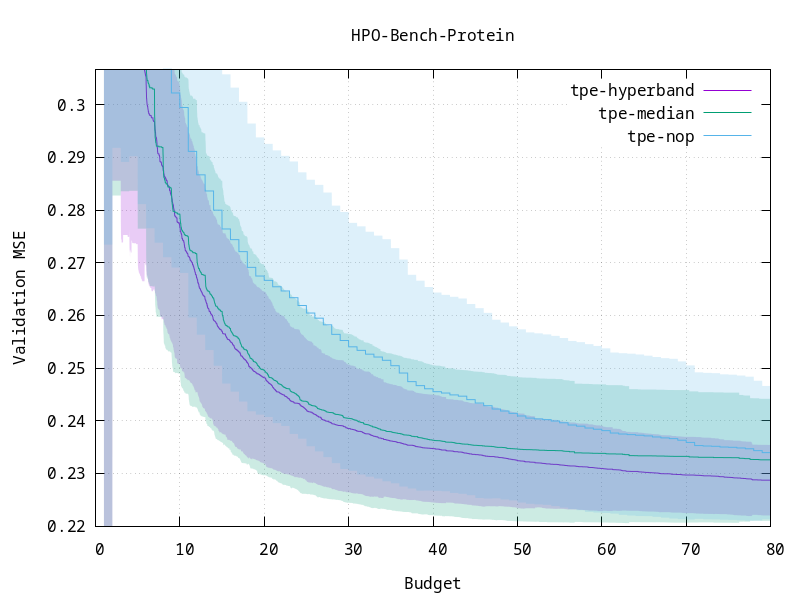
Hyperband (`tpe-hyperband`) converges faster than previous pruners including the median pruner (`tpe-median`) and is more stable when executed multiple times (see the shaded variance). 1 budget corresponds to 100 training epochs. `tpe-nop` means no pruning.
New CMA-ES Sampling
`optuna.samplers.CmaEsSampler` is a new CMA-ES sampler. It is faster than the previous CMA-ES sampler which used to be located under the `optuna.integration` submodule. This new sampler can handle a larger number of trials and should therefore be applicable to a wider range of problems. Additionally, while the previous CMA-ES sampler used to ignore pruned trials for its optimization, this sampler also comes with an experimental feature to more efficiently use the information obtained from pruned trials during optimization. This sampler was developed by @c-bata, one of the main contributors to Optuna, and the author of `cmaes` which is used under the hood.
If you used to write code like the following.
study = optuna.create_study(sampler=optuna.integration.CmaEsSampler())
You can instead use the new sampler by changing the submodule.
study = optuna.create_study(sampler=optuna.samplers.CmaEsSampler())
Or, if you want to keep using the old one which has a new name.
study = optuna.create_study(sampler=optuna.integration.PyCmaSampler())
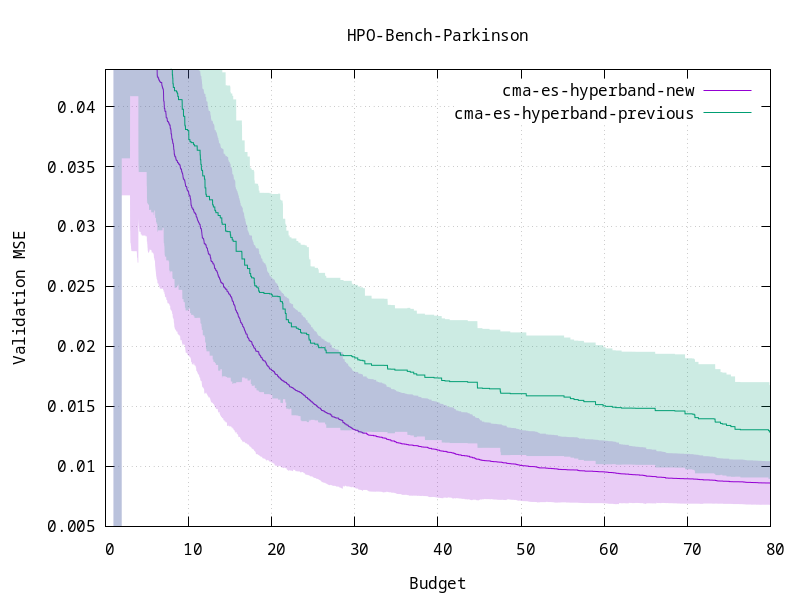
The new CMA-ES converges faster when considering pruned trials during its optimization.
Integrations
Optuna comes with various submodules for integrating with third party frameworks. These range from gradient boosting frameworks such as LightGBM and XGBoost to deep learning frameworks surrounding the PyTorch and TensorFlow ecosystems, to many others. Here, we describe a few of them that are most relevant to this release.
LightGBM
LightGBM is a well established Python framework for gradient boosting. Optuna provides various integration modules that tightly integrate with LightGBM. `optuna.integration.lightgbm.train` provides efficient stepwise tuning of hyperparameters and acts as a drop-in replacement for `lightgbm.train` requiring no other modifications to user code. For cross-validation and integration with other Optuna components, such as studies for recording optimization histories and distributed deployments, there are also `optuna.integration.lightgbm.LightGBMTuner` and `optuna.integration.lightgbm.LightGBMTunerCV`.
MLflow
MLflow is a popular framework for managing machine learning pipelines and lifecycles. MLflow Tracking in particular is a useful tool for monitoring experiments through an interactive GUI. Using MLflow Tracking to track HPO experiments in Optuna is now as simple as registering a callback to Optuna’s optimization thanks to the newly introduced `MLflowCallback`.
Redis
The optimization algorithms and optimization histories are clearly separated in Optuna at an architectural level. A storage abstracts the logic for storing the history of this optimization into various backends such as RDBs or in-memory. RDBs are useful for distributed optimization or for persisting history, and in-memory storages are suited for fast experiments that don’t need either of those. Redis is an in-memory key-value storage commonly used for caching because of its flexibility and performance. In this release, an additional Redis storage is experimentally introduced laying the middle ground between the existing storages. The Redis storage is easy to set up and can serve as an alternative for users who cannot configure RDBs but for instance want to persist optimization histories.
Documentation
The official documentation, has been redesigned with a new look-and-feel. It is now easier to navigate and made more readable with separate and shorter pages for each function or class.
PyTorch Collaborations
PyTorch is a popular framework in the field of deep learning, an important application of Optuna. Optuna recently joined the PyTorch Ecosystem, and we are continuing to add features for easier integration with PyTorch and frameworks surrounding its ecosystem.
AllenNLP
In addition to the existing integration modules for PyTorch Lightning and PyTorch Ignite, an integration has been added for AllenNLP, which is a machine learning framework built on PyTorch specializing in natural language processing (NLP). With AllenNLP, it is common to define the training procedures as well as the model definitions in Jsonnet files. This was inconvenient when combined with Optuna, as parameters had to be read from and written back to files on the system. The `AllenNLPExecutor` allows you to optimize these model definitions with a few lines of code. See the blog article by @himkt for more details.
(Update) Optuna for PyTorch Reinforcement Learning
The organization that created the ChainerRL library of Reinforcement Learning algorithms has migrated their algorithms to PyTorch for a new library called PFRL, and features Optuna integration as well. In fact, the baselines for the Minecraft RL competition for NeurIPS 2020 use Optuna as part of PFRL as well.
What’s Ahead
While many features were initially planned for this release, we ended up with more than what was anticipated. Several integrations described above were not on the roadmap initially but were developed by the growing share of contributors. We continually review what features to include and listen to community input on new areas where Optuna can help.
As for concrete milestones, multi-objective optimization is a major feature on the roadmap. With multi-objective optimization, you will be able to optimize your objective function on multiple criteria. A typical use case would be to maximize the model accuracy while at the same time minimizing the FLOPS. Multi-objective algorithms in Optuna will optimize both criteria at the same time leaving you with a so-called pareto front of optimal trials (since a trial with the optimal parameters on a single dimension is not necessarily best overall if the objective span multiple dimensions). For those who are interested, multi-objective optimization is available experimentally with sophisticated algorithms such as NSGA-II. Its API is much like the existing API in Optuna and should require few changes to existing code to get started. We will polish and fix the API in the coming releases and look forward to users using this feature in production or to develop novel algorithms.
Contributors
As with any other release, this one would not have been possible without the feedback, code, and comments from many contributors.
A03ki, AnesBenmerzoug, Crissman, HideakiImamura, Muragaruhae, PhilipMay, Rishav1, RossyWhite, VladSkripniuk, Y-oHr-N, araffin, arpitkh101, barneyhill, bigbird555, c-bata, cafeal, chris-chris, crcrpar, d1vanloon, daikikatsuragawa, djKooks, dwiel, festeh, g-votte, gorogoroumaru, harupy, hayata-yamamoto, hbredin, henry0312, higumachan, himkt, hross, hugovk, hvy, iwiwi, jinnaiyuu, keisuke-umezawa, kuroko1t, momijiame, mottodora, nmasahiro, nuka137, nzw0301, oda, okapies, okdshin, pablete, r-soga, scouvreur, seungjaeryanlee, sfujiwara, shino-yoshi, sile, smly, suecharo, tadan18, tanapiyo, tohmae, toshihikoyanase, upura, victorhcm, y0z, yasuyuky, ytsmiling, yutayamazaki, zishiwu123 and zzorba.
Thanks to those who have followed the projects from the very early days and those who have joined along the way.
Tag