Blog
If the mathematical expressions are not displayed correctly, please reload the page via this link.
Hello, I am Yuichiro Ueno. I participated in a summer internship program at PFN in 2017, and I currently work as a part-time engineer. I am an undergraduate student at Tokyo Institute of Technology, and my research topic is High-Performance, Parallel and Distributed Computing.
In this blog post, I will describe our recent study on algorithms for AllReduce, a communication operation used for distributed deep learning.
What is Distributed Deep Learning?
Currently, one of the significant challenges of deep learning is it is a very time-consuming process. Designing a deep learning model requires design space exploration of a large number of hyper-parameters and processing big data. Thus, accelerating the training process is critical for our research and development. Distributed deep learning is one of the essential technologies in reducing training time.
We have deployed a private supercomputer “MN-1” to accelerate our research and development process. It is equipped with 1024 NVIDIA(R) Tesla(R) P100 GPUs and Mellanox(R) InfiniBand FDR interconnect and is the most powerful supercomputer in the industry segment in Japan. By leveraging MN-1, we completed training a ResNet-50 model on the ImageNet dataset in 15 minutes.
Communication among GPUs is one of the many challenges when training distributed deep learning models in a large-scale environment. The latency of exchanging gradients over all GPUs is a severe bottleneck in data-parallel synchronized distributed deep learning.
How is the communication performed in distributed deep learning? Also, why is the communication so time-consuming?
The Importance of AllReduce in Distributed Deep Learning
In synchronized data-parallel distributed deep learning, the major computation steps are:
- Compute the gradient of the loss function using a minibatch on each GPU.
- Compute the mean of the gradients by inter-GPU communication.
- Update the model.
To compute the mean, we use a collective communication operation called “AllReduce.”
As of now, one of the fastest collective communication libraries for GPU clusters is NVIDIA Collective Communication Library: NCCL[3]. It achieves far better communication performance than MPI, which is the de-facto standard communication library in the HPC community. NCCL is indispensable for achieving high performance in distributed deep learning using ChainerMN. Without it, the ImageNet 15-min feat could not have been achieved[2].
Our researchers and engineers were curious about NCCL’s excellent performance. Since NCCL is not an open source library, we tried to understand the high performance of the library by developing and optimizing an experimental AllReduce library.
Algorithms of AllReduce
First, let’s take a look at the AllReduce algorithms. AllReduce is an operation that reduces the target arrays in all processes to a single array and returns the resultant array to all processes. Now, let P the total number of processes. Each process has an array of length N called \(A_p\). \(i\)-th element of the array of process \(p ~(1 \leq p \leq P)\) is \(A_{p,i}\).
The resulting array B is to be:
$$ B_{i}~~=~~A_{1,i}~~Op~~A_{2,i}~~Op~~…~~Op~~A_{P,i} $$
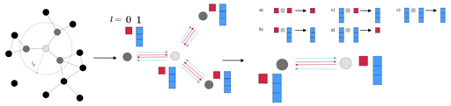
Here, Op is a binary operator. SUM, MAX, and MIN are frequently used. In distributed deep learning, the SUM operation is used to compute the mean of gradients. In the rest of this blog post, we assume that the reduction operation is SUM. Figure 1 illustrates how the AllReduce operation works by using an example of P=4 and N=4.
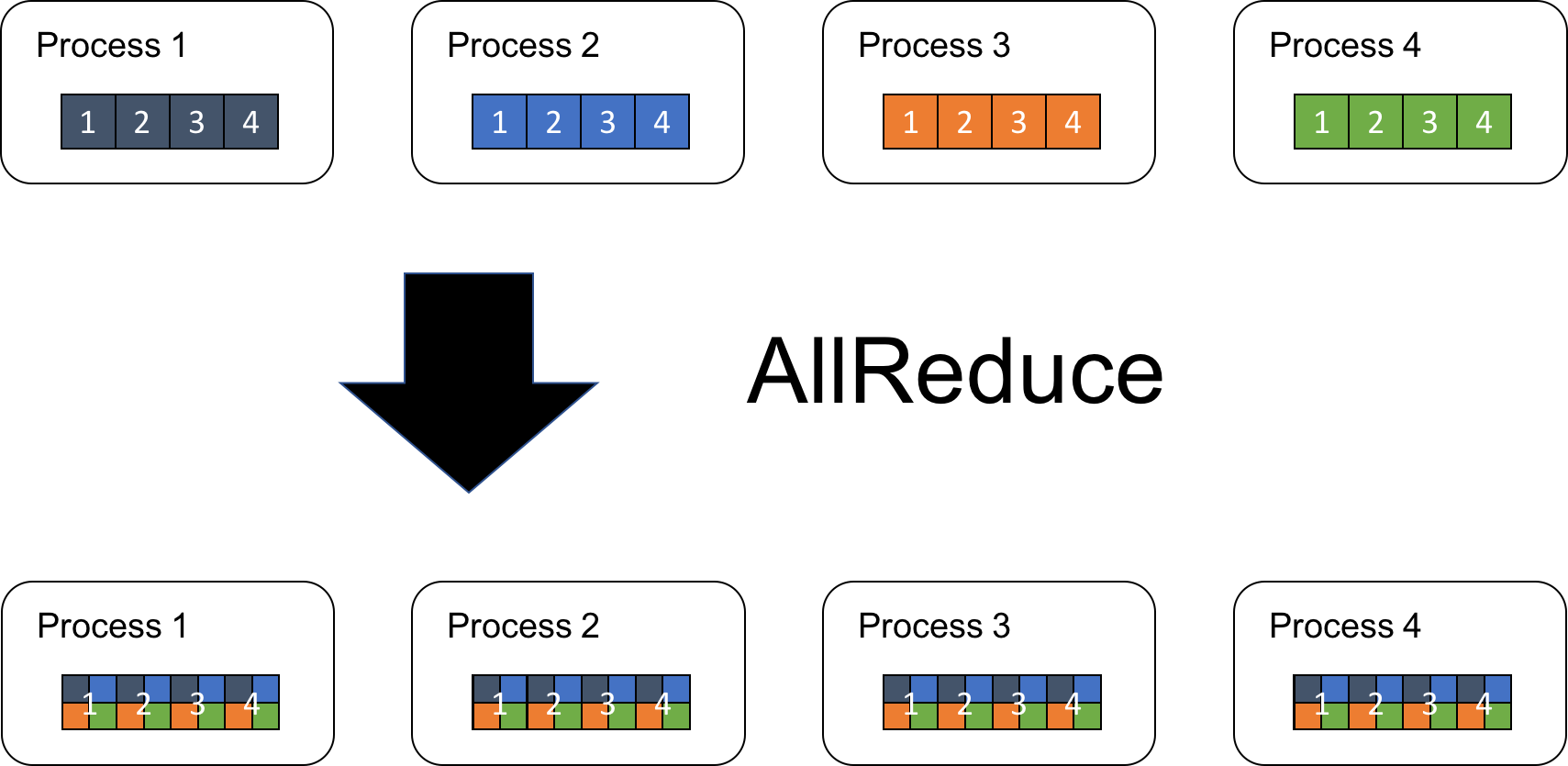
There are several algorithms to implement the operation. For example, a straightforward one is to select one process as a master, gather all arrays into the master, perform reduction operations locally in the master, and then distribute the resulting array to the rest of the processes. Although this algorithm is simple and easy to implement, it is not scalable. The master process is a performance bottleneck because its communication and reduction costs increase in proportion to the number of total processes.
Faster and more scalable algorithms have been proposed. They eliminate the bottleneck by carefully distributing the computation and communication over the participant processes.
Such algorithms include Ring-AllReduce and Rabenseifner’s algorithm[4].
We will focus on the Ring-AllReduce algorithms in this blog post. This algorithm is also employed by NCCL [5] and baidu-allreduce[6].
Ring-AllReduce
Let us assume that P is the total number of the processes, and each process is uniquely identified a number between 1 and P. As shown in the Fig.2, the processes constitute a single ring.
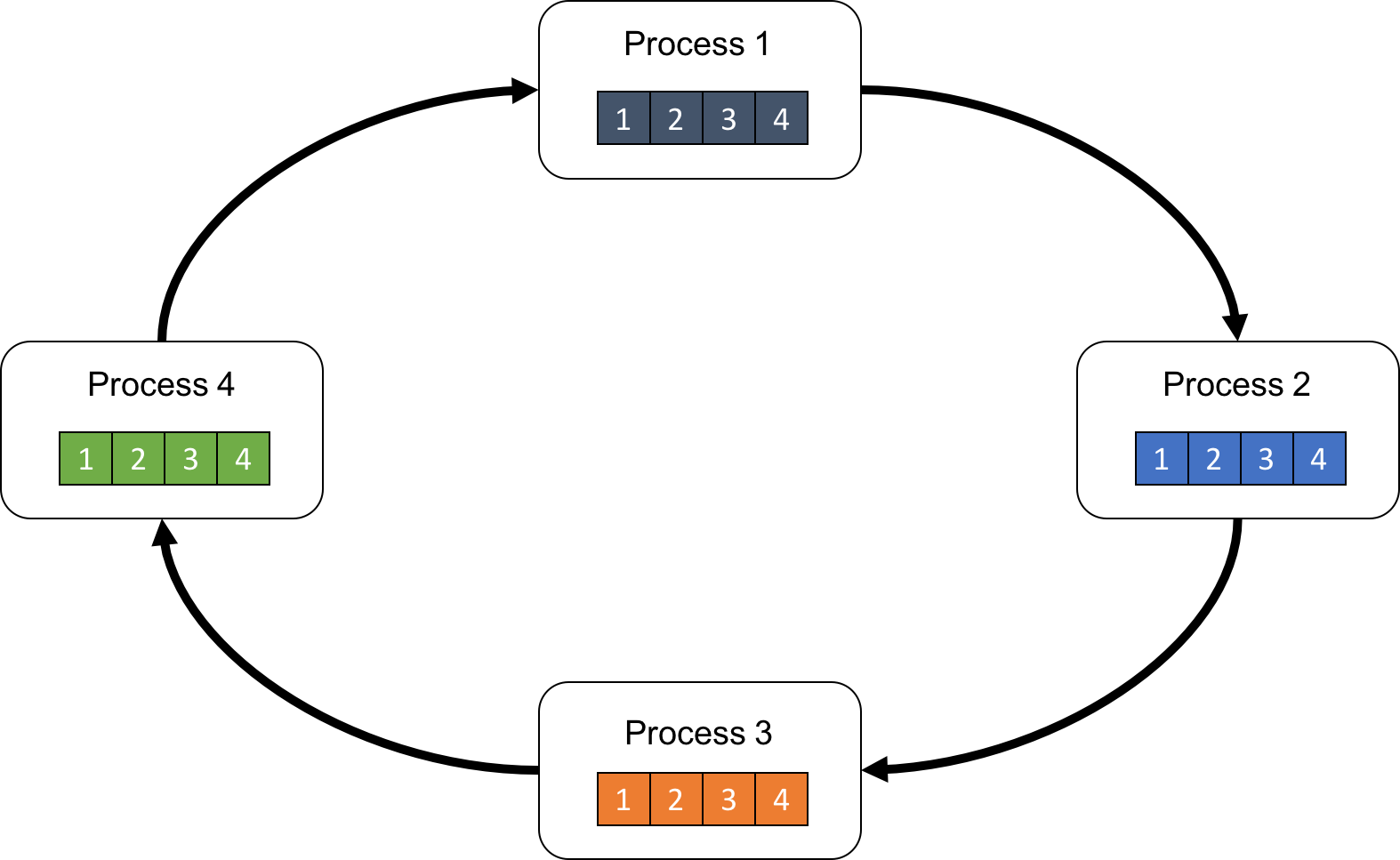
First, each process divides its own array into P subarrays, which we refer to as “chunks”. Let chunk[p] be the p-th chunk.
Next, let us focus on the process [p]. The process sends chunk[p] to the next process, while it receives chunk[p-1] from the previous process simultaneously (Fig.3).
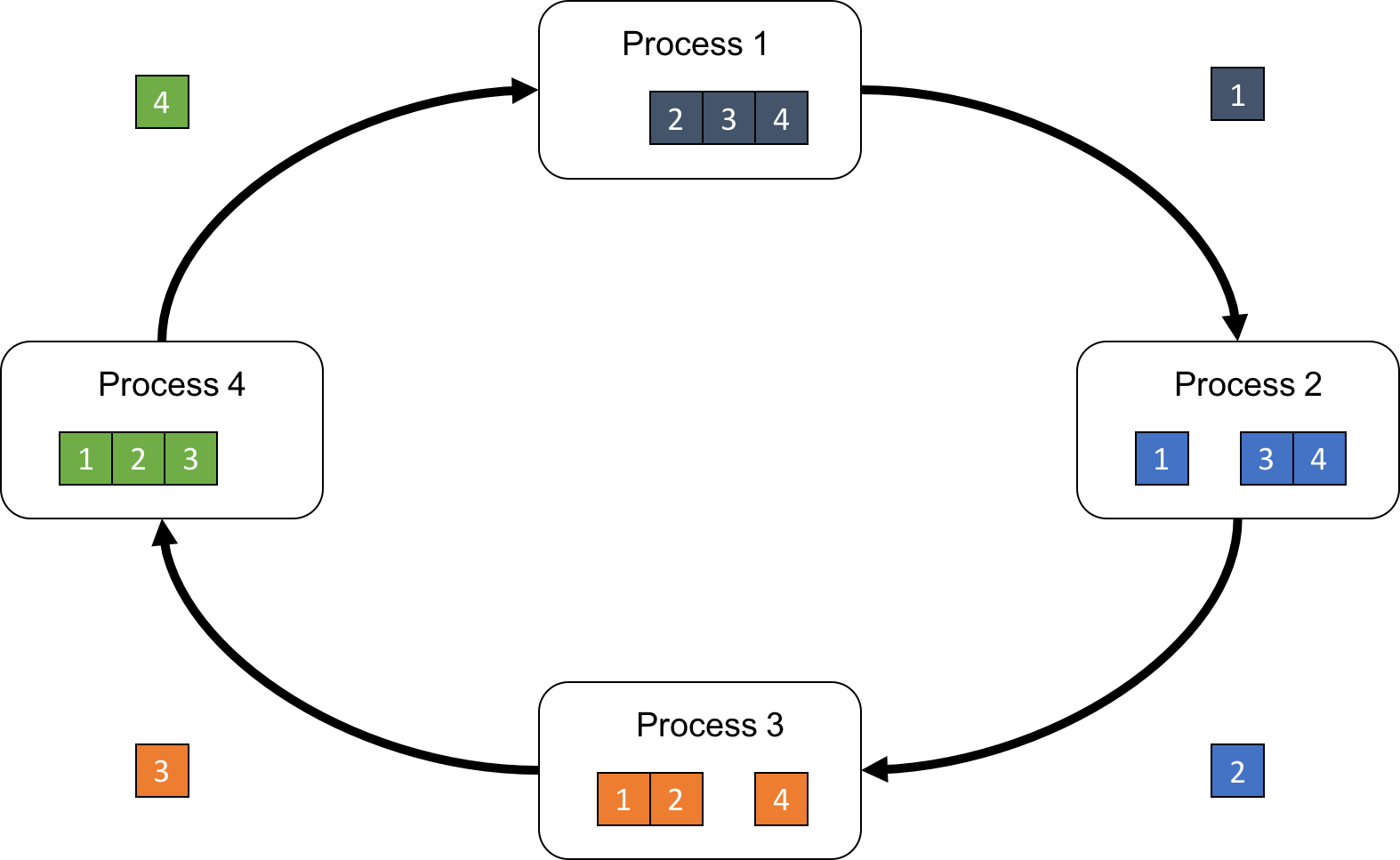
Then, process p performs the reduction operation to the received chunk[p-1] and its own chunk[p-1], and sends the reduced chunk to the next process p+1 (Fig.4).
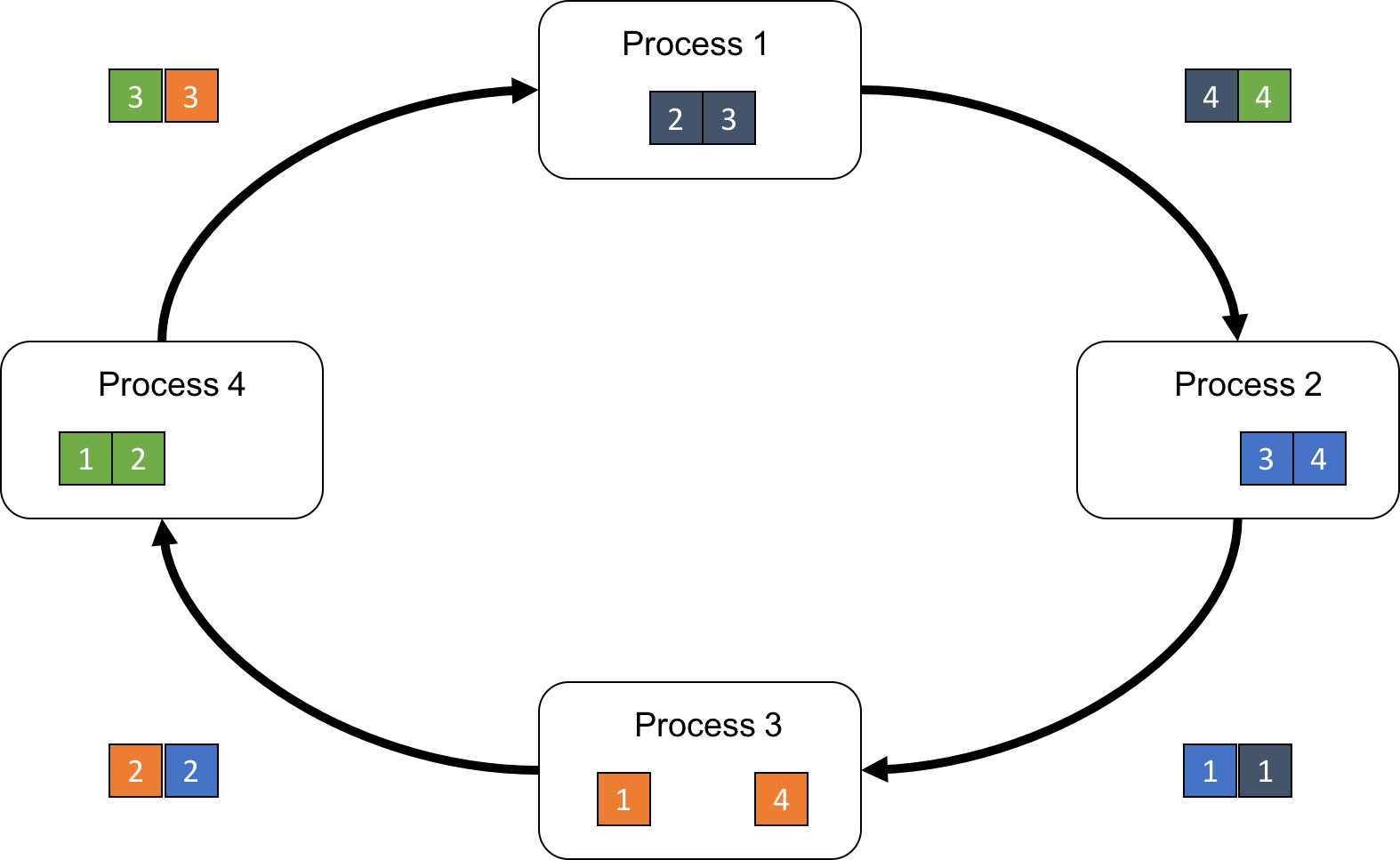
By repeating the receive-reduce-send steps P-1 times, each process obtains a different portion of the resulting array (Fig.5).
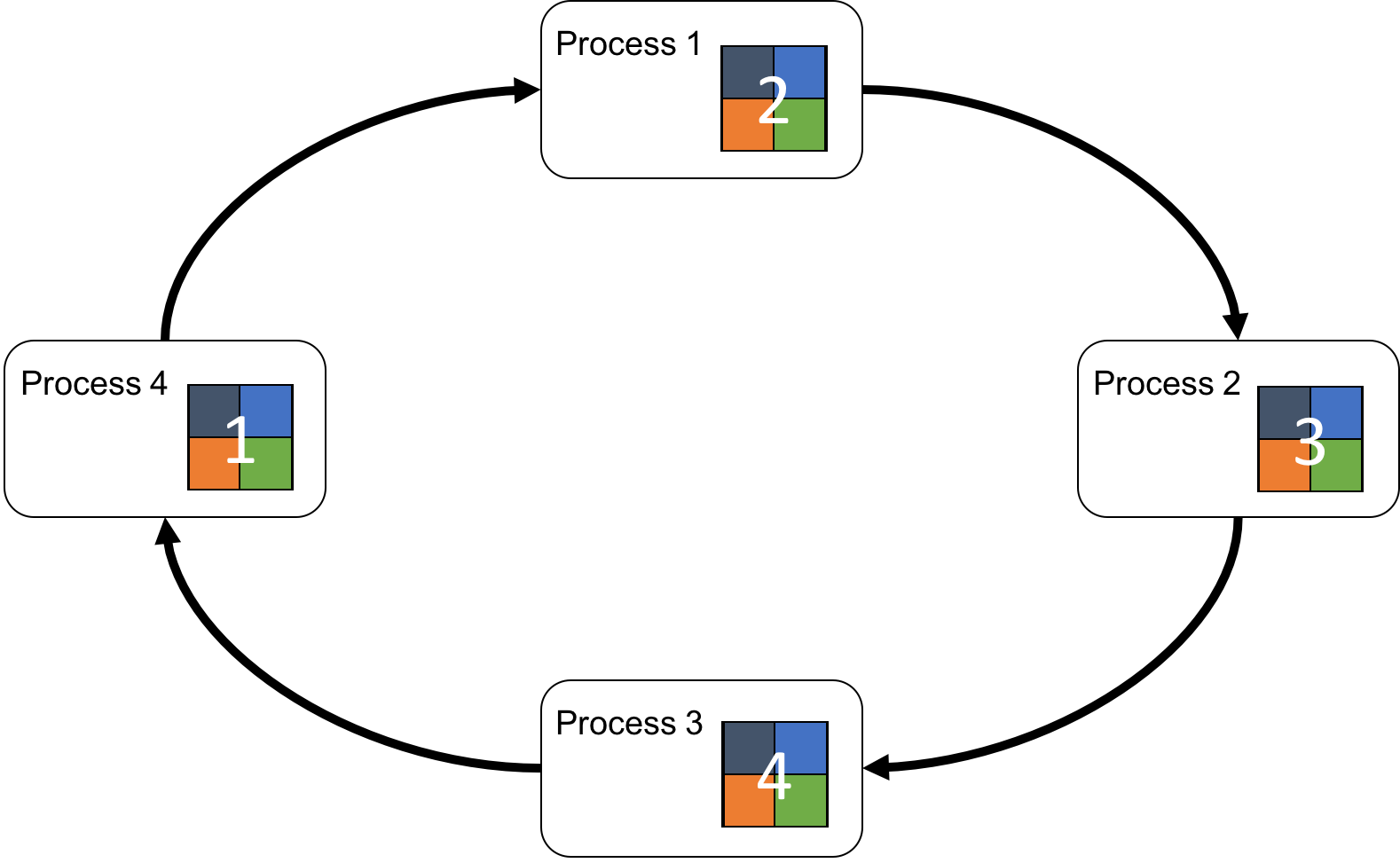
In other words, each process adds its local chunk to a received chunk and send it to the next process. In other words, every chunk travels all around the ring and accumulates a chunk in each process. After visiting all processes once, it becomes a portion of the final result array, and the last-visited process holds the chunk.
Finally, all processes can obtain the complete array by sharing the distributed partial results among them. This is achieved by doing the circulating step again without reduction operations, i.e., merely overwriting the received chunk to the corresponding local chunk in each process. The AllReduce operation completes when all processes obtain all portions of the final array.
Let’s compare the amount of communication of Ring-AllReduce to that of the simple algorithm we mentioned above.
In the simple algorithm, the master process receives all the arrays from all other processes, which means the total amount of received data is \((P – 1) \times N\). After the reduction operation, it sends the arrays back to all the processes, which is again \((P – 1) \times N\) data. Thus, the amount of communication of the master process is proportional to P.
In the Ring-AllReduce algorithm, we can calculate the amount of communication in each process in the following way. In the earlier half of the algorithm, each process sends an array, the size of which is \(N/P\), \(P-1\) times. Next, each process again sends an array of the same size P-1 times. The total amount of data each process sends throughout the algorithm is \(2N(P-1) / P\), which is practically independent of P.
Thus, the Ring-Allreduce algorithm is more efficient than the simple algorithm because it eliminates the bottleneck process by distributing computation and communication evenly over all participant processes. Many AllReduce implementations adopt Ring-AllReduce, and it is suitable for distributed deep learning workloads as well.
Implementation and Optimization
The Ring-AllReduce algorithm is simple to implement if basic send and receive routines are given. baidu-allreduce[6] is built on top of MPI using MPI_Send and MPI_Recv.
However, we tried to do further optimizations by using InfiniBand Verbs API instead of MPI. To fully utilize hardware resources, the algorithm has multiple stages such as memory registration (pinning), cuda-memcpy, send, reduction, receive, and memory deregistration, and they are processed in a software pipeline. Here, “registration” and “deregistration” are pre- and post-processing stages for DMA data transfer. Such low-level operations are abstracted out in MPI send/receive routines, and we are not able to split them into pipeline stages. To increase the granularity of the communication and computation, we further divide chunks into smaller sub-chunks. Also, we introduce a memory pool to hide memory allocation overhead.
Performance Evaluation
For performance evaluation, we compared our prototype (called PFN-Proto) to several AllReduce implementations shown in the Appendix.
Our prototype implementation currently focuses on inter-node communication; it is not optimized for intra-node communication using shared memory or GPU-to-GPU DMA data transfer. We evaluated the implementations in one process per node configuration. For Open MPI [7], our company is yet to introduce the latest version 3.x series because the most recent series has a minor issue related to GPUDirect. So, we used version 2.1.3 instead.
We used our private supercomputer MN-1 for this experiment, as shown in the “Experimental environment” below. Eight processes were run, where one process ran on one computing node. The target data size is 256MB.
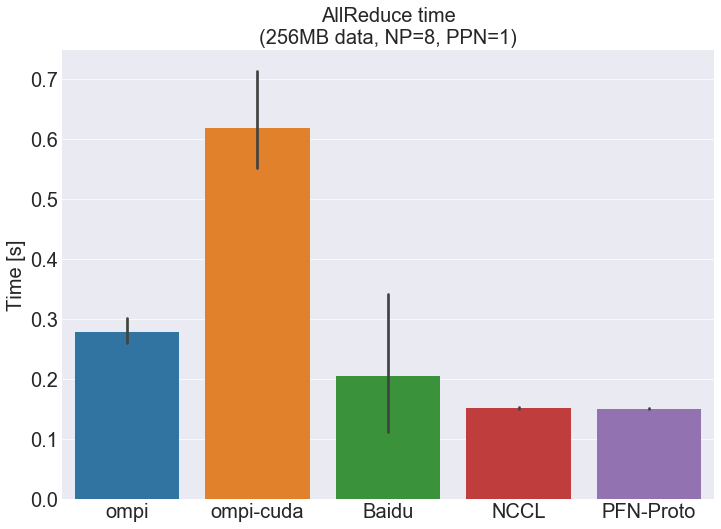
Figure 6 shows the result of the evaluation. Each bar indicates the median of 10 runs. The error bar indicates confidence intervals. The details of each library are shown in the “software versions” below.
First, let’s look at the median values. Our experimental implementation, PFN-Proto, showed the fastest time, which is approximately 82%, 286%, 28%, 1.6% better than ompi, ompi-cuda, Baidu, NCCL, respectively. One thing worth mentioning, which is not in the graph, is that Baidu achieved the fastest single-run time 0.097 [s] among all the five libraries.
Next, we focus on the variance of the performance. Maximum and minimum runtimes of PFN-Proto and NCCL are within +/- 3% and +/- 6%, respectively. In contrast, Baidu’s maximum value is 7.5x its median, because its first run takes a very long time. Its maximum runtime excluding the first run is +9.6% over the median, which is still more significant than those of NCCL and PFN-Proto.
Our hypothesis is that the performance variances of MPI and MPI-based routines are attributed to MPI’s internal behavior related to memory operations. MPI’s programming interface hides memory allocation and registration operations for InfiniBand communication. Timings of such operations are not controllable from those AllReduce implementations.
Summary
We described the AllReduce communication pattern, which is very important for distributed deep learning. In particular, we implemented the Ring-AllReduce algorithm in our experimental communication library, and it achieved comparable performance to NCCL library released by NVIDIA. The implementation efficiently utilizes available hardware resources through advanced optimization such as using InfiniBand Verbs API and software pipelining. We continue our research and development on accelerating distributed deep learning.
Caveats: our implementation is experimental, and we only demonstrated the performance on our in-house cluster. NCCL is a highly practical and usable library thanks to its performance suitability and availability on a wide range of IB-connected NVIDIA GPU clusters.
Acknowledgement
I would like to thank my mentors and the team for the kind support and feedbacks. Since my internship period last year, I have been give access to rich computation resources, and it has been a fantastic experience.
From Mentors:
This project started with a question: “how does NCCL achieve such high and stable performance?” It is an advanced and experimental topic, but Mr. Ueno achieved a remarkable result with his high motivation and technical skills.
PFN is looking for talents, not only in the deep learning/machine learning field but a full range of technical areas from hardware to software. Please visit https://www.preferred-networks.jp/en/jobs for more information.
For students who are interested in high-performance computing and other technologies, PFN offers international internship opportunities, as well as domestic programs for Japanese students. The application period has finished this year, but be ready for the next opportunity!
References
[1] Preferred Networks officially released ChainerMN version 1.0.0
[2] Akiba, et al., “Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes”
[3] NVIDIA Collective Communications Library
[4] Rabenseifner, “Optimization of Collective Reduction Operations”, ICCS 2004
[5] Jeaugey, “Optimized Inter-GPU Collective Operations with NCCL”, GTC 2017
[6] baidu-allreduce
[7] Open MPI
[8] New ChainerMN functions for improved performance in cloud environments and performance testing results on AWS
[9] Tsuzuku, et al., “Variance-based Gradient Compression for Efficient Distributed Deep Learning”, In Proceedings of ICLR 2018 (Workshop Track)
Appendix
Software versions
| Implementation | Version | Note |
|---|---|---|
| MPI (ompi) | Open MPI 2.1.3 | Trasnfer from CPU memory to CPU memory (No GPU involved) |
| CUDA-aware MPI | Open MPI 2.1.3 | From GPU memory to GPU memory |
| baidu-allreduce (baidu) | A customized version of baidu-allreduce, based on commit ID 73c7b7f | https://github.com/keisukefukuda/baidu-allreduce |
| NCCL | 2.2.13 |
Experimental environment
- Intel(R) Xeon(R) CPU E5-2667 * 2
- Mellanox ConnectX-3 InfiniBand FDR (56Gbps) x2
- NVIDIA Pascal P100 GPU (with NVIDIA Driver Version 375.20)
Tag