Large Scale Distributed Deep Learning
Solve machine learning problems using extremely large scale dataset and massive computing resources
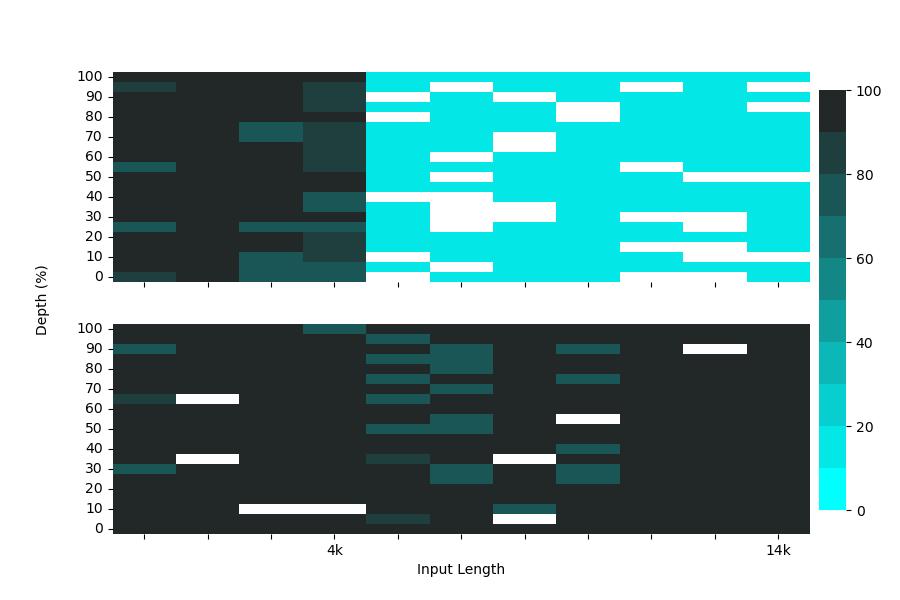
There are various challenges to utilize both vast datasets and massive computing resources, such as terabytes of data and hundreds of GPUs. Such challenges include using state-of-the-art algorithms for large-batch training, hyperparameter optimization, data storage, IO, fast inter-GPU communication on high-speed interconnects, fault tolerance, and program optimization.
Here at PFN, we operate on-premise large scale GPU clusters of 2500 GPUs in total. In addition to physical resources, PFN is also blessed with knowledge and experiences from team members with various backgrounds such as machine learning, algorithm, distributed systems, and supercomputing.
One of our important missions is to challenge large-scale problems and achieve remarkable results that are only possible with these machine and human resources.
Publications
Variance-based Gradient Compression for Efficient Distributed Deep Learning
Invited to Workshop in ICLR 2018
By : Yusuke Tsuzuku, Hiroto Imachi, Takuya Akiba
ChainerMN: Scalable Distributed Deep Learning Framework
ML Systems Workshop in NIPS 2017