Blog
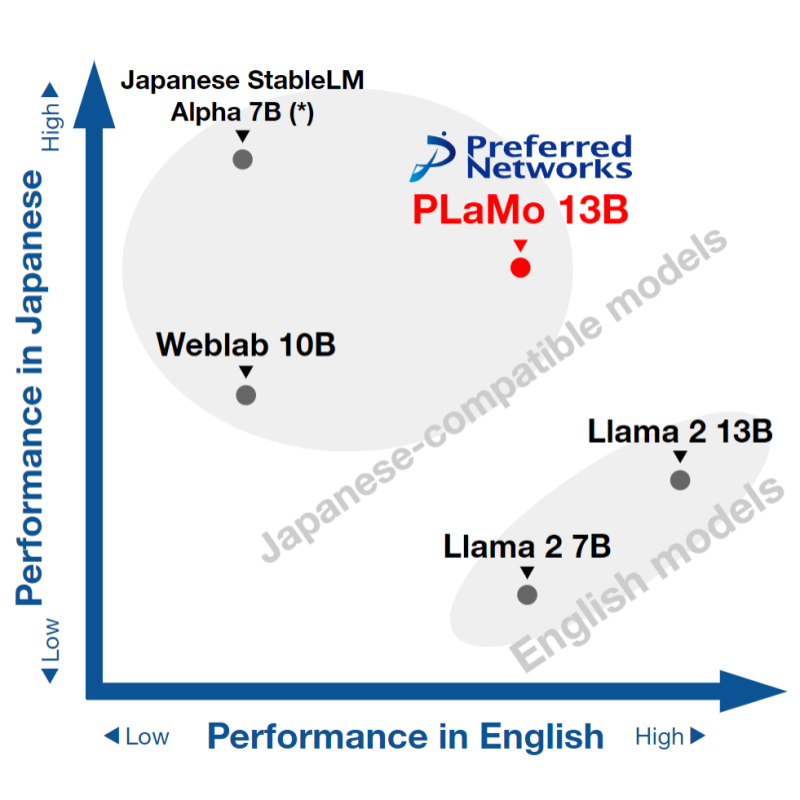
Fig1: Performance comparison of Japanese and English benchmark tasks (please see Appendix B for details)
Preferred Networks released a large language model called PLaMo-13B on Sep/28. PLaMo-13B has demonstrated one of the world’s highest performances on benchmark for Japanese and English combined among currently available pre-trained models with similar parameter sizes. We used MN-2 (the private supercomputer) for preparations and developments, and used “1st ABCI Large-scale Language Model Building Support Program” of AI Bridging Cloud Instructure (ABCI).
Overview of PLaMo-13B
PLaMo-13B is a neural language model with 13 billion parameters.
PLaMo-13B has demonstrated high performance on benchmark tasks for both Japanese and English. LLMs used in Japan obviously require high Japanese proficiency. On the other hand, we believe that English proficiency is also important when not reading or writing English text using an LLM. Most programming languages are based on English, and APIs of external tools (such as search engines) use English keywords. Hence, the ability to understand English is indispensable even for an LLM designed for Japanese.
Also, PLaMo-13B has been trained on only publicly available datasets and is an Open Source Software (OSS) released under the Apache License 2.0. The Books3 dataset was withdrawn in mid-August. PLaMo-13B adjusted to this change and has been trained without the Books3 dataset. PLaMo-13B can be used for various kinds of applications without limitations, such as generating or filtering a dataset. Please note that since PLaMo-13B is an LLM, it has the potential to generate content that is factually incorrect or does not align with societal values. Please use it appropriately, bearing in mind these characteristics of LLMs.
Usage
You can try PLaMo-13B by the following Python code:
import transformers
pipeline = transformers.pipeline(
"text-generation", model="pfnet/plamo-13b", trust_remote_code=True
)
print(
pipeline(
"The future of artificial intelligence technology is ", max_new_tokens=32
)
)
Details and Characteristics of PLaMo-13B
In this section, I will describe the details and characteristics of PLaMo-13B.
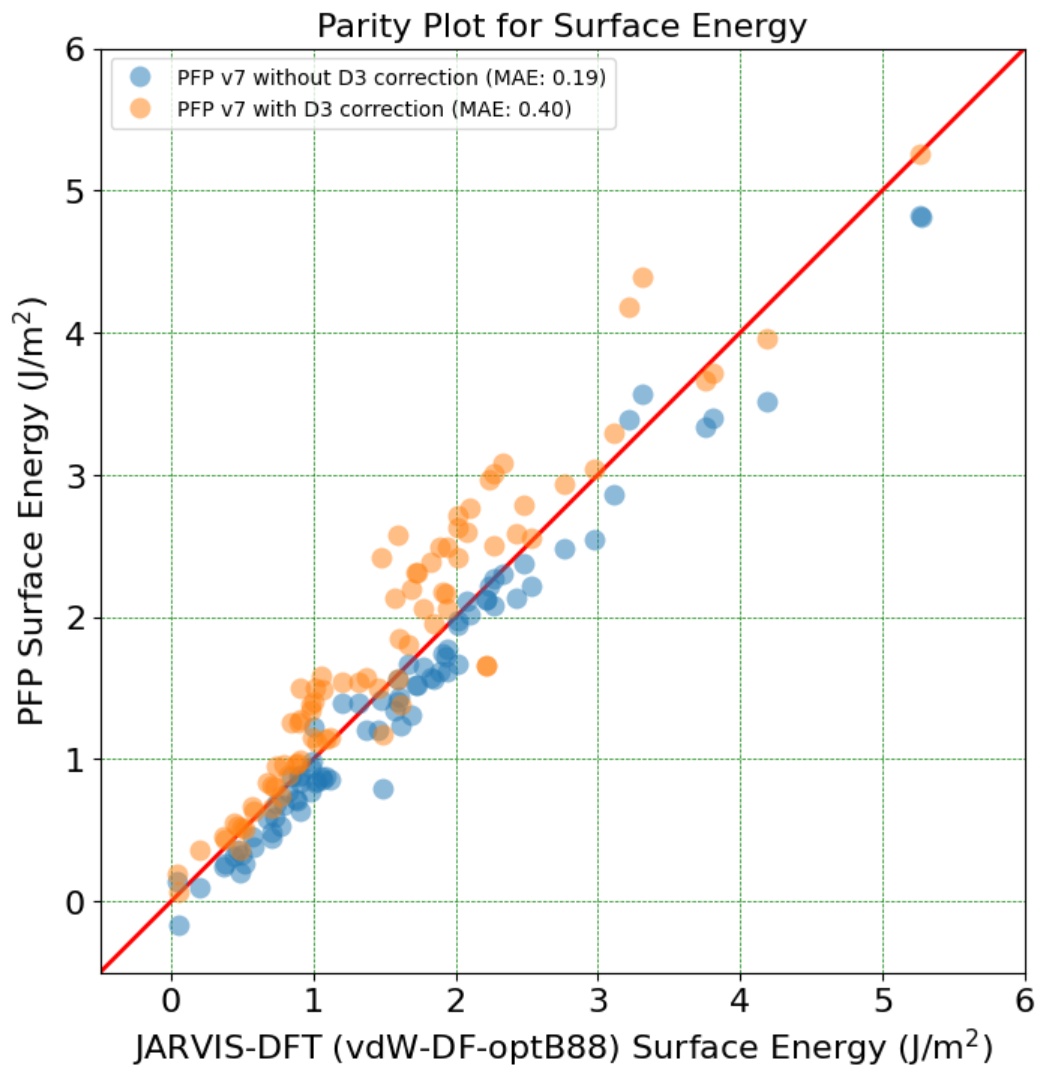
Result on Benchmark Tasks
First, let’s introduce some benchmark task results, which highlight the features of the model. Please refer to Appendix A for further details and evaluation settings.
Many Language Learning Models (LLMs) undergo a process of pre-training, followed by fine-tuning according to the intended use case. PLaMo-13B is a pre-trained model that hasn’t undergone any fine-tuning. Hence, we will compare it with a few pre-training models (models that do not include fine-tuning).
In terms of LLMs trained in Japanese, we will consider the Japanese StableLM Alpha 7B released by Stability AI and the weblab-10B released by Matsuo Laboratory at the University of Tokyo. For LLMs primarily focused on English, we will look at the 7B and 13B models from LLaMA-2.
| Japanese | English | |||||
| JCommonsenseQA (acc_norm) | MARC-ja (acc_norm) | JSQuAD (exact_match) | arc_challenge (acc_norm) |
arc_easy (acc_norm) |
piqa (acc_norm) |
|
| PLaMo-13B | 53.4 | 95.8 | 70.6 | 40.3 | 64.8 | 76.1 |
| Japanese StableLM Alpha 7B | 27.7 | 96.7 | 70.6 | 33.7 | 63.3 | 73.4 |
| Japanese StableLM Alpha 7B (with prompt modification by PFN) |
75.9 | 96.7 | 70.6 | 33.7 | 63.3 | 73.4 |
| LLaMA 2 7B | 29.2 | 86.0 | 58.4 | 40.6 | 53.6 | 76.9 |
| LLaMA 2 13B | 40.0 | 38.9 | 76.1 | 44.2 | 58.0 | 79.1 |
| weblab-10b | 61.6 | 82.1 | 62.9 | 35.0 | 63.2 | 76.3 |
Based on these benchmark results, we can say that PLaMo-13B,
- has comparable performance with other Japanese-trained LLMs in Japanese benchmarks,
- offers similar performance to LLaMA 7B in English benchmarks,
- falls short in English benchmark performance when compared with LLaMA2 13B.
These results mean that:
- Compared with a 7B class model emphasizing one language, PLaMo-13B has similar performance in the prioritized language (for example, PLaMo-13B has the similar English performance of LLaMA2 7B).
- PLaMo-13B falls short in the prioritized language when compared with a 13B class model that puts emphasis on that language (for instance, it has lower English performance than LLaMA2 13B).
Japanese StableLM Alpha 7B and weblab-10B are the largest Japanese-trained LLMs, and we can say that PLaMo-13B has top-tier ability to understand Japanese, along with a higher English comprehension ability than those models.
Training Configurations
I will describe the configuration of PLaMo-13B training.
dataset
We used the following three datasets used for training. The proportion of the data leans more towards the English datasets.To efficiently handle Japanese, we trained a tokenizer by using SentencePiece.
| name | Language in the dataset | ratio |
| RedPajama (excluding books3) | English | 87.7% |
| mc4 (Japanese only) | Japanese | 12.0% |
| wikipeda (Japanese only) | Japanese | 0.3% |
DNN architecture
The basic structure of PLaMo-13B follows that of LLaMA [1]. To create more opportunities for future acceleration, we made the following two changes to LLaMA:
- Use Grouped Query Attention (GQA) [2]
- Use Parallel Layers [3]
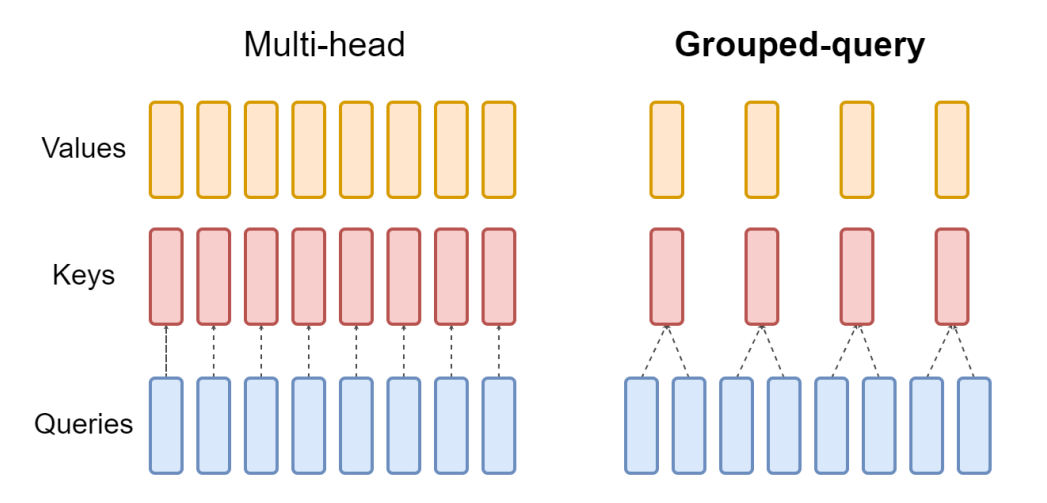
Fig2: Grouped Query Attention (from https://arxiv.org/pdf/2305.13245.pdf)
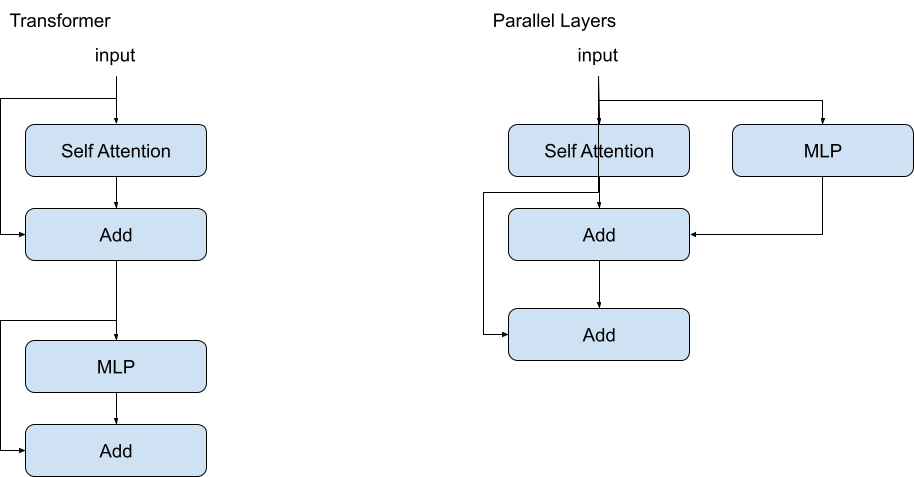
Fig3: Parallel Layers and original Transformer
Technical Details of PLaMo-13B Pretraining
In this section, I will describe characteristics of our pretraining process in detail.
Use of Our in-house Supercomputer (MN-2)
PFN operates our own supercomputers (MN-2 and MN-3). The number of GPUs required to train PLaMo-13B significantly exceeds any DNN training that PFN has performed before. The computational resources of MN-2 and MN-3 were not enough. So we use ABCI to train PLaMo-13b.
However, we also use our supercomputers to train PLaMo-13B. MN-2, a supercomputer that utilizes GPUs, served two major purposes.
The first one was as a testbed for various training methods. In terms of total time, we used 128 A100 GPUs for about a month, and other GPUs (A30 and V100) were also extensively utilized for debugging and experimenting with smaller-scale models.
The second purpose was to serve as the Continues Integrations (CI) system for the overall learning process. Training an LLM takes time, even on a smaller scale, making it challenging to check accuracy through regular CI, such as GitHub Actions. We use the idle times on MN-2 for CI purposes, which helps discover issues that are usually hard to detect through regular CI.
Approaches to Improve FLOP efficiency
Next, we introduce the flop efficiency in the pre-training of PLaMo-13B. Training an LLM usually requires a vast amount of computational resources and more time than regular DNN training. Thus, it is crucial to increase flop efficiency to reduce necessary computational resources and learning time.
The table below shows the flop efficiency of PLaMo-13B compared with the LLM models trained on GPUs by other organizations:
| Model | FLOP efficiency [%] | Context length | GPU |
| PLaMo-13B | 41.0 | 4096 | A100 40GB x480 |
| GPT-NeoX-20B [3] | 37.5 | 2048 | A100 40GB x96 |
| LLaMA-65B [1] | 46.5 | 2048 | A100 80GB x2048 |
Despite using the same GPU and having a larger context length, PLaMo-13B was trained with higher flop efficiency than GPT-NeoX. We believe this reflects the effects of our optimization.
On the other hand, PLaMo-13B’s flop efficiency is lower when compared with LLaMA-65B’s training. Three possible reasons for this could be: 1) The use of different GPUs, where LLaMA training had more GPU memory, 2) LLaMA having a shorter context length, and 3) There are still inefficiencies in PLaMo-13B’s training code.
While we have optimized PLaMo-13B’s training code as described later, there are several improvements and optimizations that we could not implement yet. The code used for training is as of the end of July 2023, but we are still developing and aiming for further performance improvements.
Distributed Training Method
From here, I will introduce some characteristics methods we took to improve FLOP efficiency.
The first one is the distributed training method. In LLM training, model parallelism such as 3D parallelism [4] is often adopted due to the lack of GPU memory.
However, we chose to use only data parallelism to train PLaMo-13B. We did not employ any model parallelism at all. The reasons for this are as follows:
- We can use the same feature (data parallelism) for both small and large scale model training. This helps reduce the occurrence of complex bugs that may only appear in large-scale models.
- By improving the distributed training methods, we can reduce the communication cost compared to model parallelism.
Let me describe more on the second point. GPU memory would be insufficient with general data parallelism algorithms (for example, PyTorch’s DistributedDataParallel). Therefore, we planned to use the Zero Redundancy Optimization stage-3 (ZeRO stage-3, FSDP in PyTorch) [5].
ZeRO stage-3 reduces GPU memory consumption to 1 / #GPUs but comes with the issue of requiring one additional communication exchange when compared to regular data parallelism. In the training of PLaMo-13B, we improved ZeRO stage-3 (hereinafter referred to as ZeRO In-Node stage-3) so that this extra communication is confined within the node. In the ABCI’s GPU node, NVSwitch provides very high-speed communication between GPUs inside the node. It allowed significant reductions in communication time. On the flip side, memory consumption increases more than the ZeRO stage-3, but this didn’t pose a problem in our training.
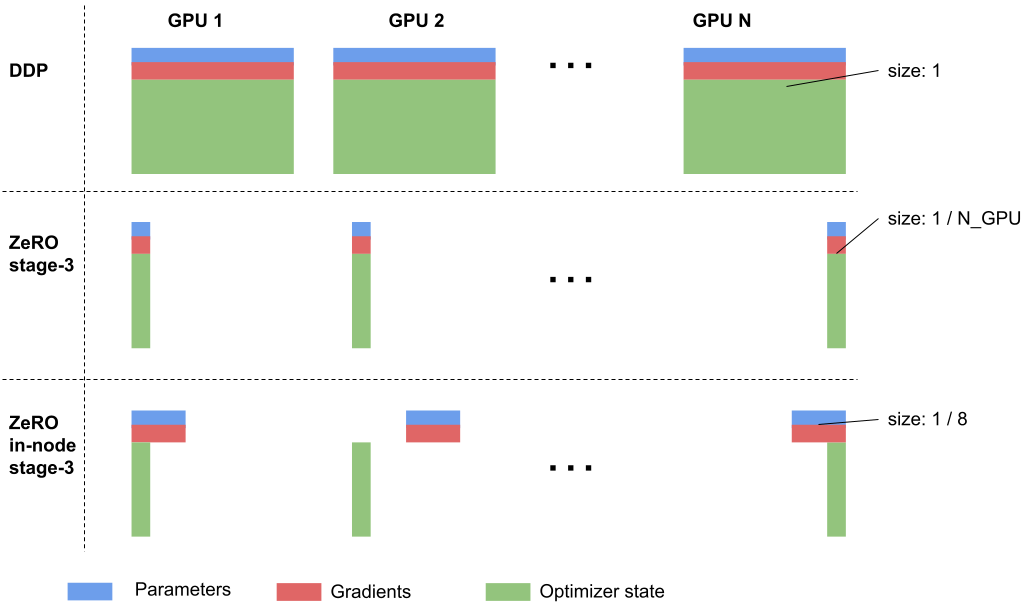
Fig4: Memory consumption of each distributed training method
Similar to ZeRO In-Node stage-3, Tensor Parallel [6], a type of model parallelism, is often used as a method that can reduce memory consumption through in-node communication. However, in the configuration of PLaMo-13B’s training this time, as shown below, ZeRO in-node stage-3 requires less communication than Tensor Parallel.
| collective | Size of Tensor | Communication Data Size (half prec.) | |
| TensorParallel (token/GPU=8192) | All-Reduce | 320M elements | 1280MB [a] |
| ZeRO In-Node stage-3 | All-Gather | 300M elements | 600MB |
[a]: All-Reduce requires twice the communication of the tensor size.
Reducing Communication through Data Quantization
The second point is quantization of communication. In data parallelism using ZeRO, a communication called AllGather is required to synchronize DNN parameters.
In PLaMo-13B’s training, we reduced this communication data size to 1/4 using a method called double quantization [7]. Profiling with MN-2 confirmed that the communication time could be almost reduced to 1/4, and the performance of the trained model hardly changed. Also, by storing the quantized data and converting it back to the original numerical format as needed, we were able to reduce the consumption of GPU memory. Although this reduction in memory consumption was not essential for the training of PLaMo-13B, it was advantageous that it became easier to confirm training with fewer GPUs.
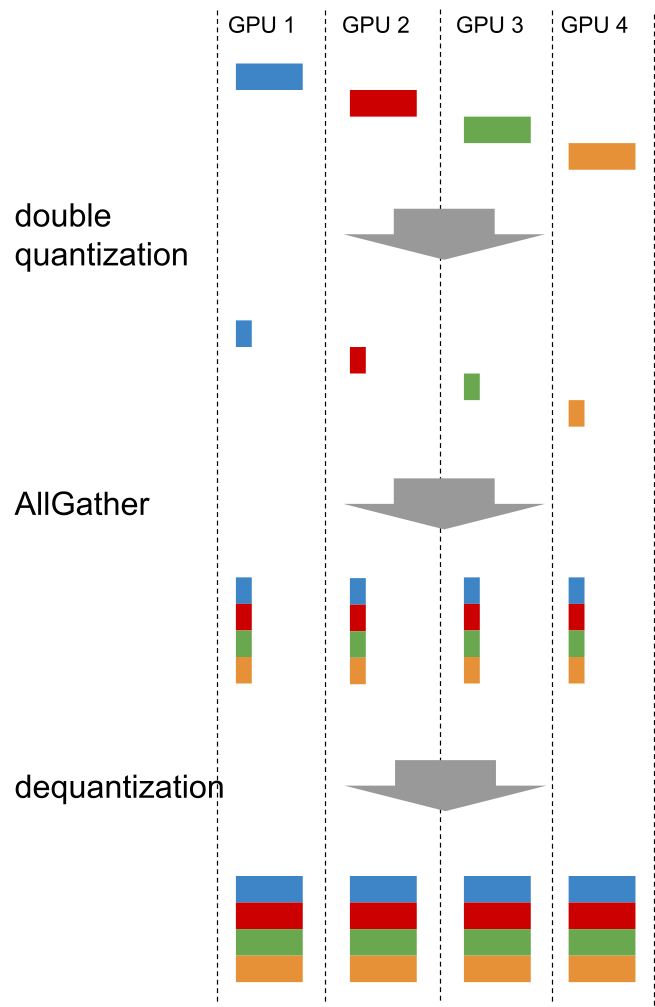
Fig5: AllGather with Double Quantization
To the best of our knowledge, PLaMo-13B training is the largest scale LLM training using numerical representations of less than 16 bits for communication. Among the technologies and methods introduced to PLaMo-13B, I think this quantization was the most ambitious undertaking.
CUDA Kernel Implementation
While LLM (Transformer) training is dominated by matrix product computations, it does not mean there are no other processes. When we profiled using MN-2, we found that there were quite a lot of times spent on things other than matrix multiplication, so we implemented CUDA kernels for two processes, Rotary Positional Embedding (RoPE) [8], and RMSNormalization [9], tailored for the A100.
By implementing custom CUDA kernels for these two operations and profiling them on MN-2, we were able to reduce training time by about 10%. While we wrote CUDA kernels, these are still large rooms for improvements in our CUDA kernels. However, it was an interesting point in the acceleration towards PLaMo-13B that even rudimentary CUDA writing can provide significant acceleration effects relative to time and effort spent.
Challenges
The training of PLaMo-13B was our first large-scale effort towards LLM training in PFN, and many issues were identified through this training.Here, we pick up and introduce two of them.
The difficulty of efficiently learning multilingual LLMs
In PLaMo-13B, we pursued training with a focus on use in Japanese, but we believed that knowledge of English would also be necessary for some practical use case (e.g., the use of external tools). Looking at the benchmark results, we can say that this goal was somewhat successful. However, when looking at just English or just Japanese, a model of about half the size could achieve equivalent performance.
Learning a multilingual LLM efficiently is a challenging task, and we believe that we need to consider methods for this in the future.
Creating and maintaining appropriate benchmarks
One of the ways we imagined using the LLM was to “use external tools with Japanese as the input,” but we haven’t been able to create an appropriate benchmark to measure this performance yet. We believe we could have prepared some benchmarks and introduced their results. But we don’t know whether such benchmarks correlate with the ability of using external tools.
In the future, as we carry out PLaMo-13B, we aim to gain insights and prepare benchmarks to measure improvements in future models.
We are hiring
In PFN’s LLM development, PLaMo-13B is the first step, and we will continue to develop LLMs in the future. Development ranges from improving computational efficiency, as introduced in this blog, to improving DNN architectures, devising strategies for datasets, and securing computational resources for learning LLMs. We are looking for teammates who are passionate about challenging these issues.
- Software Engineer – Foundation Models
- Foundation Model Service Development Engineer (Large-scale Language Model / Image Basic Model) )
- Large-scale Computation Infrastructure Engineer (Infrastructure)
- Large-scale Computation Infrastructure Researcher (Infrastructure)
- Engineer, Storage
Policy
We have developed PLaMo-13B based on PFN’s technology development policy. If there are any points you notice, please contact us through our inquiry form.
Reference
- [1] LLaMA: Open and Efficient Foundation Language Models
- [2] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
- [3] GPT-NeoX-20B: An Open-Source Autoregressive Language Model
- [4] Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
- [5] ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- [6] Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- [7] QLoRA: Efficient Finetuning of Quantized LLMs
- [8] RoFormer: Enhanced Transformer with Rotary Position Embedding
- [9] Root Mean Square Layer Normalization
Appendix
Appendix A: Details of Benchmarking Results
Benchmarks on Japanese
| JCommonsenseQA (acc) | JCommonsenseQA (acc_norm) | JNLI (acc) | JNLI (acc_norm) | MARC-ja (acc) | MARC-ja (acc_norm) | JSQuAD (exact_match) | |
| PLaMo-13B [a] | 55.9 | 53.4 | 41.0 | 36.5 | 95.8 | 95.8 | 70.6 |
| Japanese StableLM Alpha 7B | 33.4 | 27.7 | 43.3 | 37.8 | 96.7 | 96.7 | 70.6 |
| Japanese StableLM Alpha 7B (with prompt modification by PFN) [a] |
79.2 | 75.9 | 43.3 | 37.8 | 96.7 | 96.7 | 70.6 |
| LLaMA 2 7B | 52.6 | 29.2 | 28.2 | 30.2 | 86.0 | 86.0 | 58.4 |
| LLaMA 2 13B | 74.9 | 40.0 | 22.0 | 30.2 | 38.9 | 38.9 | 76.1 |
| weblab-10b | 66.6 | 61.6 | 53.7 | 49.7 | 82.1 | 82.1 | 62.9 |
- [a] Please note that only jcommonsenseqa uses prompt version 0.3, while the other benchmarks use 0.2.
- With jcommonsenseqa, it was observed that if Japanese StableLM Alpha 7B remains on prompt version 0.2, PLaMo-13B’s performance may appear unjustifiably high. Therefore, we have also included the measurement results of Japanese StableLM Alpha 7B with prompt version 0.3. It is possible that the performance of other models might also improve with a different version of the prompt.
- The other benchmark settings follow the specifications described on https://github.com/Stability-AI/lm-evaluation-harness.
- The results for benchmarks other than JcommonsenseQA of Japanese Stable LM Alpha 7B, as well as the results of other models, were obtained from the following sources:
- https://github.com/Stability-AI/lm-evaluation-harness/blob/jp-stable/models/stabilityai/stabilityai-japanese-stablelm-base-alpha-7b/result.json
- https://github.com/Stability-AI/lm-evaluation-harness/blob/jp-stable/models/llama2/llama2-7b/result.json
- https://github.com/Stability-AI/lm-evaluation-harness/blob/jp-stable/models/llama2/llama2-13b/result.json
- https://github.com/Stability-AI/lm-evaluation-harness/pull/85/files#diff-a759330cbe9163a0a0f6f4094cf577558e87848c4d8d84da069c14a3707168c9
Benchmarks on English
| arc_challenge(acc_norm) | arc_easy(acc_norm) | boolq(acc) | hellaswag(acc_norm) | openbookqa(acc_norm) | piqa(acc_norm) | winogrande(acc) | |
| PLaMo-13B | 40.3 | 64.8 | 67.2 | 70.2 | 40.6 | 76.1 | 65.3 |
| Japanese StableLM Alpha 7B | 33.7 | 63.3 | 64.6 | 63.3 | 38.6 | 73.4 | 62.8 |
| LLaMA 2 7B | 40.6 | 53.6 | 71.1 | 73.0 | 40.8 | 76.9 | 67.1 |
| LLaMA 2 13B | 44.2 | 58.0 | 69.0 | 76.6 | 42.0 | 79.1 | 69.6 |
| weblab-10b | 35.0 | 63.2 | 65.2 | 64.4 | 34.2 | 76.3 | 62.4 |
- The benchmark settings follow the default settings of lm-evaluation-harness (https://github.com/EleutherAI/lm-evaluation-harness ).
Appendix B: Method for calculating the scores in Figure 1
We plotted the average standard deviation of the benchmark scores in Appendix A as the score for each language. However, we excluded JNLI from the Japanese benchmarks. This is because JNLI has a problem where the label ratios are not equal, and we believe that we currently cannot evaluate the performance of the model correctly with accuracy. JNLI is a three-class classification task, and the label with the highest frequency constitutes about 55% of all labels. Therefore, if we create a simple model that straightforwardly outputs the most frequent label and evaluate it with accuracy, we get a score of 55. This score ends up being higher than the accuracy for other models, so we believe it is challenging to evaluate with accuracy at this stage, and thus we have excluded JNLI.
Area
Tag