Blog
はじめに
Preferred Networks (以下PFN) 子会社のPreferred Elements (以下PFE) は、PLaMo 2シリーズの開発を進めており、その成果の一部としてPLaMo 2 1BおよびPLaMo 2 8Bの事前学習済みモデルを先日公開しました。モデルの詳細は以下の記事をご覧ください。
PLaMo 2の開発は、高品質データセットをどれだけ構築できるかが重要なポイントと考えています。実際、高品質データセットを使用したPLaMo 2 8Bは、8BというサイズでPLaMo-100Bに相当する性能をJMMLUやJHumanEvalで獲得しています。
事前学習チームでは、その源泉となる高品質データセットの構築を支えるためにAWS Batchを活用したバッチジョブ実行環境を運用しています。
本記事では、処理環境の概要とユースケース、運用して見つかった課題などを紹介します。
なお、PLaMo 2の開発は、経済産業省及び国立研究開発法人新エネルギー・産業技術総合開発機構 (NEDO) が実施する、国内の生成AIの開発力を強化するためのプロジェクト「GENIAC (Generative AI Accelerator Challenge)」の支援を受けて実施しています。
要件定義
高品質データセットの構築では作成と実験評価を反復するため、大量のCPUリソースを使った並列処理を複数人で同時並行作業可能な環境が必要です。
また以前の記事で紹介した通り事前学習データセットはAmazon S3に保存しているため、作成処理もAWSを使えると作業者の手間は少ないと期待されます。
すでにAWSはCommonCrawlベースデータセットの作成に活用しており、SLURMジョブで並列処理可能なsubmititを使っているcc_netをベースに、AWS ParallelClusterでクラスタを構築し処理しています。
しかしParallelClusterは、複数の作業者が並行して大小問わず様々なデータセットを処理する環境として提供するのは難しいと考えました。
ParallelClusterではジョブの投入は専用に構築されたログインノードで行う必要があり、マルチユーザーで利用するにはログインノードに都度ユーザーを追加するか、AWS Directory Serviceとの連携が必要です。
また実行するコードは共有ファイルシステムへ置くのが前提で、ローカルで実装したコードをParallelClusterで実行するにはファイル転送が必要です。
他にも様々な課題がありましたが、実行環境の要件をまとめると以下にあげるような点で、ParallelClusterをベースとしない環境が必要と考えました。
- 作業者が実行環境となるクラスタを都度立ち上げたり削除する必要がない
- ローカルで作業したコードをジョブで実行できる
- 実行状態やログをブラウザベースで確認したい
- 複数人が同時並行でジョブを投げられるようにfair share ruleを入れたい
- ジョブは数時間にわたって実行する可能性がある
- 複数のジョブを依存関係でつないで実行することがある
- データソースはウェブ上の外部リポジトリであることが多い
AWS Batch, Lambda, Parallel Computing Service
今回のように、大規模データ処理を実現できるサービスまたは実装は以下が考えられます。
ParallelClusterでは今回の要件を達成できず、またそのマネージドサービスであるPCSでもログインノードでの作業は必要で、コード管理の要件をクリアできません。
またLambdaはLambda関数1つあたりの実行時間は15分までと規定されていて、CommonCrawlのように大量のデータを読んでテキスト抽出するには短すぎるという課題があり、これも候補から外しました。
BatchはSQS + Lambda + ECSで構築していたようなジョブ実行環境をサービス化したもので、構築にはECSの設定も要求されますが、ほとんどの要件をクリアできそうです。
- 作業者が実行環境となるクラスタを都度立ち上げたり削除する必要がない
- ユーザーは構築済みクラスタがある、という認識で作業可能
- 実行状態やログをブラウザベースで確認したい
- AWSのウェブコンソール上から確認可能
- 複数人が同時並行でジョブを投げられるようにfair share ruleを入れたい
- ジョブキュー機能が実装されていて、fair shairの設定が可能
- 複数のジョブを依存関係でつないで実行することがある
- 最大20個のジョブを依存ジョブとして設定可能
- 配列ジョブ機能で最大1万並列を実現し、1つの依存ジョブとして設定可能
Lambdaのように15分までの時間制限はありませんが、EC2 or Fargateのスポットインスタンスを使う場合は優先確保による中断に耐えられるコード実装が必要です。
SQS + Lambda + ECSの実装も選択できますが、サービス間連携だけでなくジョブのfair share管理やECS上でのEC2オートスケーリング管理などコストが高い作業がいくつも必要なため、今回はAWS Batchを選択しました。
AWS Batchについて必要な用語は以下の通りです。
- コンピューティング環境
- EC2インスタンスやFargateインスタンスなど、ジョブを実行するためのECSコンテナインスタンスを管理する
- ジョブキュー
- ジョブを投入するPriority Queue
- キューあたり最大3つのコンピューティング環境を優先度付きで設定できる
- ジョブ定義
- ジョブの実行方法について設定する
- ジョブ
- Batchでの実行単位で、ジョブ定義から起動
- 実行するコマンド等はジョブ定義から上書き可能
課金対象について
Batchサービス自体には料金は発生せず、EC2やS3などのリソースに課金されます。またECSもサービス自身ではなく、計算環境として利用するEC2やFargateに課金される仕組みです。
実装環境では、以下のサービスや利用が課金対象です。
- EC2
- 通常のEC2利用金額と同額
- Fargate
- EBS (Elastic Block Store)
- EC2にアタッチするルートボリュームがメイン
- Dockerイメージの保存領域と、OSの領域、ジョブのワークスペースの領域としてインスタンスあたり一定量が必要
- ECR (Elastic Container Registry)
- ECSコンテナとして実行するDockerイメージの保存に使用
- 同じリージョン内のBatchやECSからイメージを取得する場合はデータ転送料金は無料で、ストレージ利用に課金される
- S3
- 同一リージョン内のデータ転送は無料、ストレージ利用はオブジェクトクラスに応じて課金される
ParallelClusterでEC2インスタンスを使ってデータを処理するのとほぼ同等で、追加コストはECRの利用料金のみと見込まれます。
ただしDockerイメージをECRからpullしDockerコンテナとしてジョブを実行するので、起動にかかるオーバーヘッドの分、EC2インスタンスの課金対象時間は延びます。
Fargateでは利用できるvCPU数とメモリ上限の組み合わせが定められており、例えば1 vCPUで64 GiBのメモリを使う、という指定はできません。
データセット処理では、Fargateの上限である120 GiBを超えたメモリを使いたいことも十分予見できるため、EC2インスタンスのみをECSバックエンドとしました。
ジョブ実行環境の実装
次の図に、AWS Batchをベースにしたバッチジョブ環境の概要を示します。
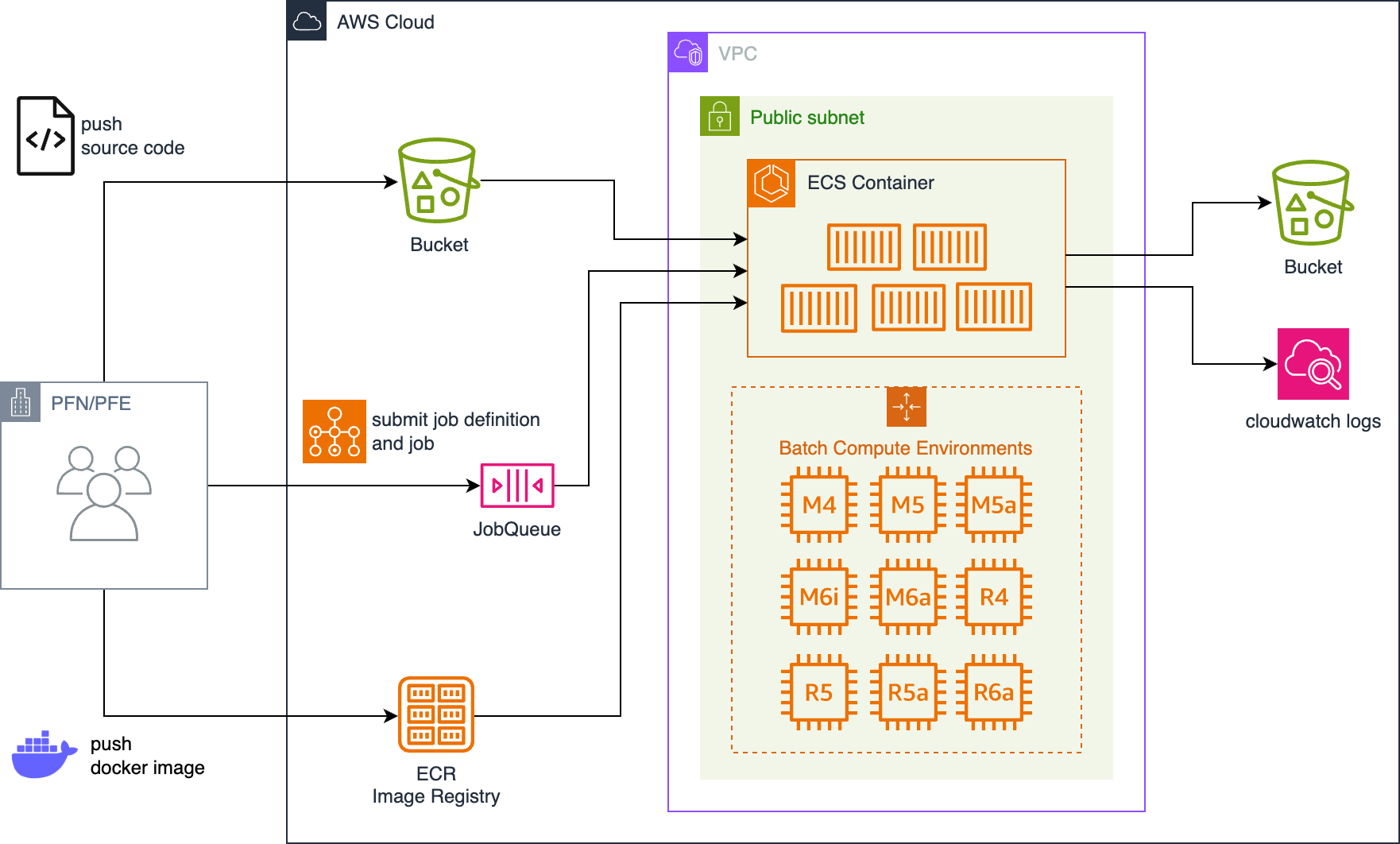
図1 データセット処理のためのバッチジョブ環境の概要
CommonCrawlやHuggingFace Hubなど外部リポジトリ上のデータを集めて処理するため、ジョブを実行するインスタンスはすべてパブリックIPv4アドレスを割り当てます。
すべてのインスタンスにはセキュリティグループまたはACLを設定し、SSHポートを含むインターネットからのすべての通信をブロックし、閉空間としています。
大量のデータを処理する一方で並列ジョブはすべて独立に実行可能 (Embarrassingly Parallel) なことを条件としたため、I/OストレージはS3のみを使います。
ジョブはユーザー任意の環境から、ジョブコンテナにする任意Dockerイメージの作成と送信、ローカルのソースコードの転送、ジョブスクリプトの投入まで行い、ジョブの監視はAWSウェブコンソールから行います。
Dockerイメージの作成やECRへのpushなどのコストですが、k8sで動いている社内クラスタでも同様の作業が必要なため、大きな負担とはなっていません。
異なるジョブキューにあるジョブの間でも依存関係を設定可能なため、スポットとオンデマンドインスタンスでジョブキューを分け、デフォルトはスポット、中断を許容できないジョブはオンデマンドと使い分けています。
Pythonクライアントライブラリの実装
ジョブの投入はAWS CLIやBoto3などのAWS SDKで行いますが、RegisterJobDefinitionとSubmitJob APIを参照するとわかるように非常に多くのパラメータがあります。
複数のIAM Roleの設定やfair shareの設定など、本環境では固定値にできるパラメータも複数含まれており煩雑なため、対象ユーザーである事前学習チームの学習コストを抑える必要がありました。
事前学習チームではArgo Workflowsおよび社内クラスタ拡張向けのヘルパーライブラリを使って、社内クラスタでモデルの学習と評価を行っています。
Argo Workflowsとして投入するk8s manifestはPythonクライアントライブラリを使って生成しているため、その使い方に倣った本環境用のライブラリで学習コストを減らせないかと考えました。
以下にサンプルコードを示します。
# SubmitJobで指定できないパラメータをジョブ定義として保存
job_definition = register_job_definition(
name="example-job-definition",
# ECRにあるdata-processing:latest imageを使う
image=ecr_repository(name="data-processing", tag="latest"),
# OOMを除きステータスコードが0でないときに5回までリトライする
retry=5,
)
# ローカルのソースコードを注入
# tarで固めたファイルをS3へ転送し、ジョブの開始時にコンテナ上に展開
inject_source(job_definition)
# 入力データを整形して出力
format_job = submit_job(
name="format-data",
definition=job_definition,
# ジョブあたり1 CPU core相当、3.8 GiBメモリ
resources=ResourceRequirements(cpu=1, memory=(3.8, "Gi"),
# 1000並列ジョブとして実行
size=1000,
command=f"""
set -eux
python3 -m pip install .
python3 ./run.py \\
s3://in-bucket/data/{source_dataset} \\
s3://out-bucket/data/out-${{AWS_BATCH_JOB_ARRAY_INDEX}}.jsonl.zst \\
;
""",
# 注入ソースコードを展開したディレクトリをworking directoryにする
working_dir="{{batch.sourcefiles}}",
)
submit_job(
name="create-metadata",
definition=job_definition,
resources=ResourceRequirements(cpu=1, memory=(1.0, "Gi"),
command=f"python3 ./create_metadata.py \"s3://out-bucket/data/out-*.jsonl.zst)\"",
dependencies=[format_job],
working_dir="{{batch.sourcefiles}}",
)
上記のコードは最初に長さ1000の配列ジョブを実行し、指定したリソースが利用可能なECSコンテナインスタンスを起動できる限り並行実行します。
すべての配列ジョブが実行完了した後、出力結果に対し処理を行う単一ジョブを実行しています。
配列ジョブはゼロから始まるID AWS_BATCH_JOB_ARRAY_INDEXと、配列ジョブのサイズAWS_BATCH_JOB_ARRAY_SIZEを使って、自身が処理するべきデータを決定することが可能です。(ref: Tutorial: Use the array job index to control job differentiation)
利用例
バッチジョブ環境は色々なジョブを投入できるように汎化されていますが、並列度が必要な処理について2つの利用例を紹介します。
CommonCrawlのWARCファイルから言語データを抽出
CommonCrawlには1 dumpあたり9万のWARC (Web ARChive format) ファイル、合計で60-100 TiBのデータが保存されています。
WARCファイルは1-2 GiB程度にshardingされ、warc.paths.gzにリスト化されているため、配列ジョブの並列化は容易に実装可能です。
task_id = int(os.environ["AWS_BATCH_JOB_ARRAY_INDEX"])
task_size = int(os.environ["AWS_BATCH_JOB_ARRAY_SIZE"])
response = requests.get(".../warc.paths.gz")
with gzip.open(BytesIO(response.content), "r") as f:
warc_files = f.readlines()[task_id::task_size]
warc_filesには子ジョブが担当するWARCファイルのリストになっているので、すべて処理してS3に保存するコードを実装すれば、インスタンスの確保や実行のスケジューリングはBatchが判断して処理してくれます。
許可されているvCPUクォータと他のジョブとの兼ね合いもあるため、事前学習チームでは最大1200 vCPUを使い、後続処理も含め数日で1 dumpをデータセット化しています。
データセットのランダムシャッフル
データセットの生成方法によっては、shardに保存されているドキュメントのカテゴリが偏っている場合があります。
データセットが大規模であるほど全体を並び替えるのは非常に大変ですが、例えば以下のような2段階のシャッフルを実装するとします。
- N個あるshardをM個に分割し、M個の中でランダムに並べ替える
- 前段のoutput shardそれぞれをランダムに並べ替える
shardの一覧はファイルで渡すことにすれば、前述のCommonCrawlと同様に配列ジョブで並列処理が可能です。
# NOTE: 簡単化のため、非効率的なコードになっています
task_id = int(os.environ["AWS_BATCH_JOB_ARRAY_INDEX"])
task_size = int(os.environ["AWS_BATCH_JOB_ARRAY_SIZE"])
with gzip.open(sys.argv[1], "r") as f:
input_shards = f.readlines()[task_id::task_size]
output_stream = {
sid: open(f"output_{task_id:04}_{sid:06}.jsonl", "w")
for range(len(input_shards))
}
# Phase 1: 1 shardをランダムにoutput shardsへ分散
for shard in input_shards:
ds = read_as_dataset(input_shards[sid]).shuffle()
for idx in range(len(ds)):
# 本来はoutput shardあたりのドキュメント数の考慮も必要
idy = np.random.choice(len(input_shards), 1)
output_stream[idy].write(json.dump(ds[idx]) + "\n")
for f as output_stream:
close(f)
# Phase 2: 各output shardをshuffle
for range(len(input_shards)):
name = f"output_{task_id:04}_{sid:06}.jsonl"
ds = read_as_dataset(name).shuffle()
write_dataset(ds, name)
半年間の運用で見えた課題
本環境は2024年8月に実装、9月から少しずつ利用を始め、約半年にわたり運用してきました。
その中で課題が見えてきたため、可能なら解決したいと考えているものを紹介します。
配列ジョブで失敗したものだけをリトライできない
Batchの配列ジョブは最大1万までサイズ指定できますが、その一部がリトライも使い切ったうえで失敗した場合、失敗したジョブだけを再実行する機能がありません。(argo retryコマンド相当がありません)
再度実行する場合、現在は同じサイズで配列ジョブを再投入し、出力ファイルができている場合は処理をスキップしてジョブを正常終了する仕組みを実装しています。
配列ジョブインデックスは環境変数で与えられるので、失敗したジョブをコピーして投入するスクリプトを実装する必要がありそうです。
確保するインスタンスに優先度をつけられない
コスト圧縮と可用性向上を両立するため、M4/M5/M6インスタンスタイプを主に利用しています。
しかしM4とM6で採用されているIntel CPUを見ると、Haswell or BroadwellからIce Lakeと5または6世代分の進化があり、簡単な比較では処理時間に倍以上の差が見られる場合もありました。
経験上はM4が最も確保しやすいのに対し、処理速度を考えるとM5やM6を優先的に活用したいのですが、Batchではジョブキュー全体のvCPU上限を設定した上で、インスタンスタイプに優先度を与えることができません。
コンピューティング環境には、複数のインスタンスファミリーおよびインスタンスタイプを指定可能ですが、優先順位は決められません。
ジョブキューはコンピューティング環境を優先度付きで最大3つ選べますが、vCPU上限はコンピューティング環境ごとに独立で、想定以上のvCPUが確保される可能性があります。
現在のBatchサービスの仕様上、解決が難しい問題であると考えられます。
おわりに
利用例にCommonCrawl dumpからのデータ抽出とデータセットのシャッフルを紹介しましたが、他にも、オープンデータセットをHuggingFace Hubからダウンロード、heuristicなテキストフィルタリング、MinHashを使ったドキュメント間の重複除去など様々な処理に利用しています。
課題はありますが事前学習チームの目的は運用ではないという前提に立つと、自分たちで運用・利用するシステムとして必要十分な機能を提供し高品質データセットの作成効率化に貢献できていると考えています。
本記事で紹介したような、より本質的な作業へ集中するためにユースケースを十分に理解した仕組みづくりも非常に重要と考えていますので、興味のある方はぜひ以下をご覧ください。



