Blog
はじめに
Preferred Networks (以下PFN) では、大規模言語モデル (LLM) に関する研究開発を行っています。これまでのブログ記事では、事前学習の状況 やそのための学習データの整備など、LLMを学習するための取り組みを紹介してきました。
一方で、LLMの開発はただモデルを学習すれば良いというものではありません。学習したモデルを評価していくことも学習するのと同じかそれ以上に重要な作業です。
モデルの評価のためには適切なベンチマークタスクの用意が必要です。そのため、英語においては、様々なベンチマークが提案・利用されています。また、英語以外の言語においては、英語を翻訳したベンチマークが重要なベンチマークとなっています。日本語も例外ではなく、JMMLUやJHumanEvalなど英語のベンチマークを翻訳したものが使われています。
しかし、このようなベンチマークの翻訳は今まで大きなコスト (人、費用両面で) がかかるものであり、英語ベンチマークのうち日本語に翻訳されたものはごく一部にとどまっています。
今回、比較的軽量に英語ベンチマークを翻訳して日本語ベンチマークを作る手法を試したので、その結果と方法を紹介します。
また、実例としてBIG-Bench-Hard (BBH)を翻訳したのでこれについても紹介します。翻訳後のデータは以下のGitHubおよびhuggingfaceで公開しています。
翻訳ベンチマークの現状と紹介する手法の目標
英語ベンチマークの翻訳では、人による翻訳、あるいは機械翻訳とその後の人によるチェックが主流だと考えています。例えば、JMMLU、MGSMがこの方法で日本語ベンチマークを作成しています。
この方法は人、費用両面でコストが大きいのが課題と言えます。そのため、比較的小規模なベンチマークだったり、英語ベンチマークの一部のみを翻訳するものが多いと考えています。
これに対して、最近はLLMを使った翻訳が行われるようになっています (MMLU-ProX など)。この方法は大規模なベンチマーク翻訳を可能にできる一方で、prompt engineeringなどに工夫が必要であること、やはりかかる費用は大きいこと、などの問題があると考えています。そのため、標準的な英語のベンチマークをうまく翻訳することには向いていますが、ニッチなドメインのベンチマークや開発の中で欲しくなったものを適宜翻訳していくことは難しいです。
こうした点を踏まえ、
- 翻訳に大きなコストをかけずに済む
- 翻訳中に人の介在が不要
なベンチマークの翻訳を目指しました。
翻訳方法
今回紹介する方法は、2025年5月にPFNから公開したPLaMo Translation Modelを使って翻訳し、wikidata (https://www.wikidata.org/wiki) を利用して専門用語などの知識を補うというものです。
翻訳専用のモデルを使うことで、prompt engineeringの必要をほぼなくし、またモデルサイズを抑えることで翻訳に必要なコストも抑えることを目指しました。
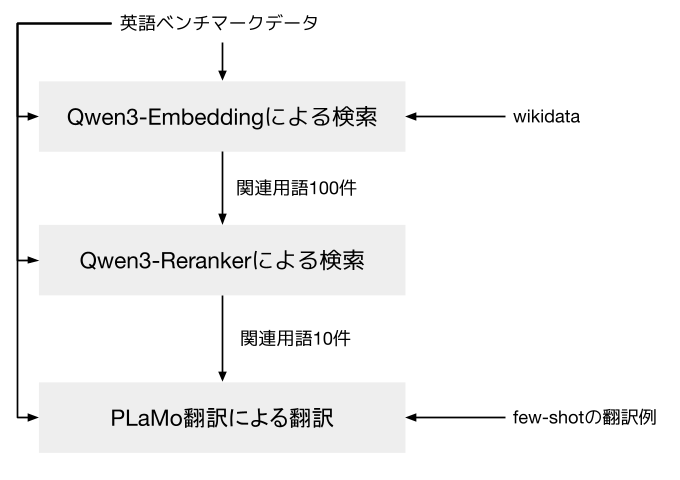
図1: 翻訳ワークフローの全体
wikidataによる辞書作成
PLaMo Translation Modelは高性能な翻訳モデルではありますが、8Bクラスのモデルとしての知識の限界は存在します。特に専門用語についてはうまく訳せないケースもありました。例えば実験では、「characteristics of the ring」を「標数」と訳すことに失敗するというようなケースが見られています。
こういった問題に対処するため、wikidataを様々なジャンルに対する英日単語帳として利用することとしました。Qwen3 Embeddingを用いた検索により、翻訳対象に関連する用語を10件取り出しました。
なお、Qwen3 Embeddingの利用前にはBM25などのDNNを用いない特徴量も試しましたが、これは単語の類似などに引きづられて不適当な項目を抽出することが多かったため利用しないこととしました。
翻訳
ベンチマークの翻訳では、もとの構造 (質問、選択肢、答え、など) を保ったまま翻訳することが必要不可欠です。
これを実現するため翻訳対象のデータを以下のフォーマットでテキスト化して翻訳しました (図2, 3)。
JSONなどのデータフォーマットを使うことも考えましたが、文字のエスケープ (\nなど) があると学習データの大半を占める通常の文章とは違ったものになってしまうのが懸念で使用をやめました。markdownはこの懸念なく使える既存のフォーマットですが、ベンチマーク内にmarkdown記法が含まれる可能性を考慮して使用をやめました。
== {項目名1} ==
{内容1}
== {項目名2} ==
{内容2}
...
図2: 構造保持のためのフォーマット
== question == What is the capital of Japan? == option_0 == Tokyo == option_1 == Osaka == option_2 == Kyoto == option_3 == Hokkaido == answer == Tokyo
図3: Q&Aに適用した例
そして、このフォーマットに確実に従わせるため及び翻訳後の文体を揃えるため、few-shotで例示して翻訳を行います。このfew-shot用のデータの作成方法は特に決めていませんが、後述するBBHの翻訳ではPLaMo Translation Modelの0-shotで生成した後目視での確認、修正を行って作成しました。
前述した用語データの利用方法を説明します。用語データは自動的に抽出したものであるため、実際には不要なものも含まれます。こういったデータに引きづられて翻訳結果がおかしくならないように、用語データは説明とともに先頭にfew-shotデータのように与えることとしました。
few-shotデータとして単語例を提示するというのは、学習データにはおそらく含まれていない使用方法です。しかし、この例示によって文脈に応じて用語のデータを参照するようにできました。こういったprompt engineeringによる生成結果の改善ができるのはLLMベースの翻訳の長所と言えると思います。
まとめると、翻訳promptは以下のようになります。
<|plamo:op|>dataset translation <|plamo:op|>input lang=English ¶000 Tokyo special wards in the eastern part of Tokyo Metropolis in Japan, that used to form a single city ¶001 Kyoto Prefectureprefecture of Japan <|plamo:op|>output lang=Japanese ¶000 東京 日本の都市 ¶001 京都府 日本の都道府県 <|plamo:op|>input lang=English == question == What is Japan's highest mountain? == answer == Mount Fuji <|plamo:op|>output lang=Japanese == question == 日本で一番高い山は? == answer == 富士山 <|plamo:op|>input lang=English == question == What is the capital of Japan? == option_0 == Tokyo == option_1 == Osaka == option_2 == Kyoto == option_3 == Hokkaido == answer == Tokyo <|plamo:op|>output lang=Japanese
図4: 翻訳promptの例。用語データについてはhttps://www.wikidata.org/wiki/Q7473516 及び https://www.wikidata.org/wiki/Q120730 を利用
PLaMo翻訳モデルにはここで使った例示以外にも様々な機能があります。より詳しい仕様を知りたい方は問い合わせフォームよりモデル仕様詳細資料の請求をしてください。
翻訳例: BBHの翻訳
上記ワークフローの利用例として、BBHを翻訳したのでこれを紹介します。翻訳後のデータは以下のGitHubおよびhuggingfaceで公開しています。
BBHは2022年に公開された、主にLLMのchain of thoughput (CoT) の能力を測るベンチマークです。
最近のいわゆるfrontierモデルでは、性能は上限に達しつつありますが、SLM向けにはまだ測る価値のあるベンチマークと言えます。また、比較的小さい学習規模でも性能の改善が見られることから、CoT能力、Reasoning能力に関する実験では利用価値が高いと考えています。
BBHに着目したのは、日本語におけるCoT、Reasoningの能力を計測する手段を探していたためです。既存ベンチマークだと、MGSM、BenchMax (GPQA)、MMLU-ProXがCoT能力の計測に利用できます。しかし、MGSMは算数に特化している、BenchMaxとMMLU-ProXは難易度が高すぎて性能の変化が見にくい、という問題がありました。
BBHは色々なカテゴリの問題を含む難しすぎない難易度のベンチマークとしてモデル開発における利用価値が高いと考えています。
実際の作業では、まずは公開されているデータのダウンロードなどの前処理とfew-shot sampleの準備を数時間かけて行いました。
few-shot sampleについては、cot-promptから各subject 1問ずつ選びPLaMo Translation Modelで翻訳した後目視での確認、修正を行って作成しました。
修正したケースは、以下の例のように英語のまま残さないと問題として意味をなさないようなケースが大半でした。
原文
== Question == Sort the following words alphabetically: List: oven costume counterpart ...
PLaMo翻訳の出力
== 問題 == 以下の単語をアルファベット順に並べ替えてください。リスト:オーブン、コスチューム、対義語 ...
図5: 手直しが必要だったfew-shot sampleの例。原文はhttps://github.com/suzgunmirac/BIG-Bench-Hard/blob/main/cot-prompts/word_sorting.txt より
その後H100をのべ1.5時間ほど利用してワークフローを流しました。
比較的単純な翻訳が多かったため、1-shot sampleで翻訳を行いました。また、もとのBBHはinput (質問) とtarget (答え) という2つのfieldしかありませんが、パーサーを書いて選択肢など質問中にある構造を抽出して翻訳を行いました。
H100はPFNで構築したk8sクラスタ (https://speakerdeck.com/pfn/20240615-cloudnativedayssummer-pfn ) を利用しました。仮にAWSを使う場合、翻訳自体にはp5.48xlarge (H100 8台, $55.04/hour(執筆時点)) を0.2時間使うことになり$11程度かかる計算になります。その他Qwen3-Embeddingの利用などはさらに規模が小さいので、全体としてはAWSでやった場合には$20以内に収まり、当初目標の大きなコストをかけない、というのは達成しているのではないかと思います。
やってみてわかったこと・議論
few-shotサンプルの用意は必要か
ほとんどのケースでfew-shot sampleがなくともほぼ問題ない翻訳ができました。実際、few-shot sampleは0-shotで翻訳を行ったものに対して必要に応じて微修正しただけです。
しかし、few-shot sampleを作る過程で一通りベンチマークの実際の問題を見ることで、現在のPLaMo Translation Modelでは難しいケースなどに気づけるといった利点があると考えています。
そのため、ある種最低限のmanual checkとしてfew-shot sampleの用意は行うようなワークフローとしました。
パーサーの記述のコスト・必要性
今回、パーサーを書いて選択肢などの情報を抜き出してから翻訳することで、確実に元の問題と同じ構造の問題を生成するようにしました。
この方法は、翻訳後の問題のフォーマットや翻訳結果の質を安定させる効果がありますが、パーサー記述のコストが多少かかることも事実です。
現状のLLMのコーディング能力を考えると、この部分もLLMにまかせて自動化することは可能ではないかと思います。あるいは、翻訳モデルの能力向上によってこういった前処理・後処理が不要になる可能性もあると思います。
いずれにせよ、前処理・後処理の工数削減は今後の課題の1つと考えています。
おわりに
LLMの開発においては、モデルを学習することと同時に適切に評価していくことも重要です。
PFNでは昨年事前学習モデルの評価ベンチマークとしてpfgen-benchを公開しました。今回の取り組みは事前学習モデルの評価に関する2つめのベンチマーク公開となります。
今後もモデルをただ学習するだけでなく、高性能なLLMを学習するために全力を尽くしていきます。
仲間募集中
PFNでは今後もLLMの開発を継続して行っていきます。開発は今回紹介した以外にも多岐にわたります。我々はこれらの課題に情熱をもって挑戦していく仲間を募集しています。
これらの仕事に興味がある方はぜひご応募よろしくお願いします。
https://www.preferred.jp/ja/careers/



