Blog
はじめに
Preferred Networks (以下PFN) 子会社のPreferred Elements (以下PFE) は、PLaMo 2シリーズの開発を進めており、その成果の一部としてPLaMo 2 1BおよびPLaMo 2 8Bの事前学習済みモデルを先日公開しました。モデルの詳細は以下の記事をご覧ください。
PLaMo 2の開発は、高品質データセットをどれだけ構築できるかが重要なポイントと考えています。実際、高品質データセットを使用したPLaMo 2 8Bは、8BというサイズでPLaMo-100Bに相当する性能をJMMLUやJHumanEvalで獲得しています。
高品質データセットを構築する手段として、LLMによるデータセットの生成は重要です。この目的のために、事前学習チームでは、vLLMを用いたLLM推論クラスタを運用してきました (詳細)。
この推論クラスタは、決まった枚数のGPUを活用して様々な試行錯誤を効率よく行うという観点ではうまく動いています
一方で、データセット生成の開発が進むにつれ、試行錯誤よりも同じデータ生成手法を大規模に実施することが多くなっています。このような用途では、以前紹介したLLM推論クラスタだと問題が生じるケースもでてきました。
そこで、事前学習チームでは新たにLLMを利用して大規模データ生成するためのシステムを構築、運用を始めました。
本記事では、このシステムについて紹介します。
なお、PLaMo 2の開発は、経済産業省及び国立研究開発法人新エネルギー・産業技術総合開発機構 (NEDO) が実施する、国内の生成AIの開発力を強化するためのプロジェクト「GENIAC (Generative AI Accelerator Challenge)」の支援を受けて実施しています。
解決したい問題と要件
まずは、以前紹介したLLM推論クラスタの概略と、本記事で説明するシステムに求めるものを説明します。
以前に紹介したLLM推論クラスタは、AWS上にvLLMを使ったLLMの推論サーバーが複数あり、ここにAPIリクエストを送ることでデータを生成します.
この方法だと、様々なデータ生成手法のリクエストを同じサーバーで実行できることがメリットです。データ生成手法を試す際、最初から大規模に行うことはほとんどなく、少量のデータ生成を行って様子をみるのが第一歩となります。このような少量のリクエストをまとめて処理することで効率の良い推論が可能となります。
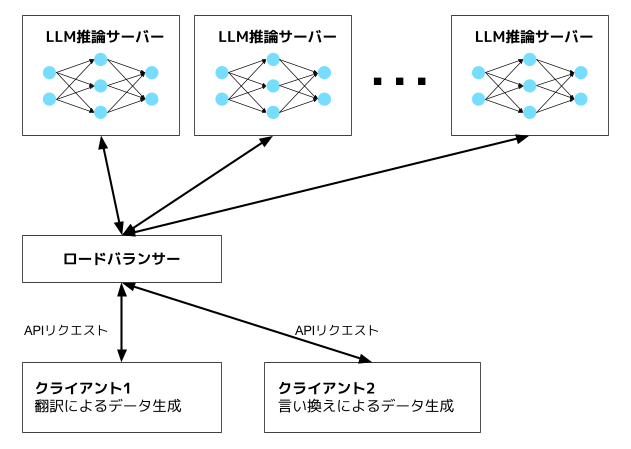
図1: 以前紹介したLLM推論クラスタの概略。推論サーバーに対して複数のクライアントからAPIリクエストを投げることでデータを生成する
一方、本記事では、大規模なデータ生成を目的としています。この目的のためには、可能な限り多くのGPUを使い続けることが重要です。したがって、推論用に割り当てているGPUだけでなく、学習やLLMの評価に使うGPUも空いていたら使用する必要があります。
空いているGPUを使う最も単純な方法は、LLM推論クラスタを空いているGPUに構築し、そこへクライアントからリクエストを送る方法です。データ生成に用いているGPUが学習・評価で必要になればvLLMサーバーをとめて学習・評価に回します。これであれば、仕組みとしては元のLLM推論クラスタをほぼそのまま使用できます。
しかし、この方法の場合、サーバー台数に応じて十分かつ過負荷にならない数のクライアントを用意する必要があります。つまり、サーバー台数が変わった場合は連動してクライアント台数も調整しなければなりません。この台数調整が遅れるとGPUを十分に使い切れなかったり、過負荷によってシステム全体が不安定化したりすることになります。
実際、学習用のGPUと推論クラスタを併用していた時は、学習の様子を見て学習が終わったのを見てクライアントの台数を増やす、学習が始まる前に台数を減らす、などの作業が必要でした。このような人手での作業は作業忘れなどのリスクを増やすため避けたいです。
本記事で紹介するシステムは、このような問題を解決しLLMによる大規模なデータ生成を実現することを目的としています。
要件をまとめると、
- 学習や評価で使われていない空きGPUを使って定型的なデータ生成処理ができる
- 他の用途 (学習実験など) でGPUが必要な時はそちらを優先してGPUの利用が止められる
- 使用するGPU数が変わる時に人による作業を必要としない
の3点となります。
データ生成システムの実装
LLMの学習や評価はk8sを使ったクラスタで行っており、今回のデータ生成システムもk8sを用いた構成となりました。
以前紹介したLLM推論クラスタとの一番の違いは、vLLMのAPIサーバーとクライアントを同じpodに収容する点です。
こうすることで、使用するGPU台数が変わった時、サーバー台数とクライアント台数のバランスを確実に揃えることができます。一方、1台のvLLMサーバーでいろいろなデータ生成リクエストを処理する、など柔軟な処理はできなくなっていますが、そもそも定型処理を大規模に行うことが目的なので問題ではないと考えています。
また、生成に関するデータの置き場所として、Amazon Simple Queue Service (SQS) およびAmazon S3を利用しました。SQSに入力データを置き、データ生成結果をS3に保存します。ただし、実装上はSQSのメッセージサイズの制限を超えるデータを保存するため、入力データもS3においてSQSにはそのkeyだけを保存しています。
そして、k8s上のpodがSQSを利用するconsumerとして振る舞いデータを生成します。
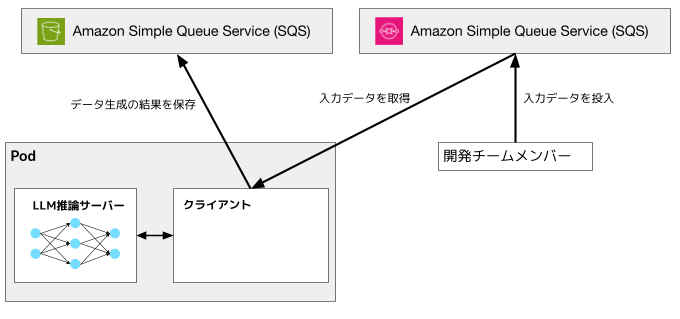
図2: 大規模データ生成システムの概略。LLM推論サーバーとクライアントを同一のpodに収容する点が図1と異なる。
※ Amazon Web Services、”Powered by Amazon Web Services”ロゴ、およびかかる資料で使用されるその他のAWS商標は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。
現在の状況
現在、事前学習チームではWebデータの翻訳にこのシステムを利用しています。英語のWebデータは大量にあり、翻訳は試行錯誤の余地が少ないことから、「定型的なデータ生成を大規模に行う」という目的に合致したワークロードと考えています。
また、GEANIC 第2期ではもともと翻訳にはPLaMo-100Bを用いてきましたが、この翻訳にはPLaMo 2 8Bを利用することにしました。1GPUで確実に動作する8Bモデルのほうが空いているGPUを利用するという目的にはふさわしく、英日翻訳の能力もPLaMo-100BとPLaMo 2 8Bでほぼ同じというベンチマーク結果が得られたためです。
PLaMo 2 8Bの事前学習が終わった2025年2月にこのシステムを構築し、現在までに約2TBのデータを日本語に翻訳しました。このデータは事前学習の検証などに活用を始めています。
オープンな大規模日本語データセットとしてFineWeb-2がありますが、これは1.5〜1.7TBのデータセットです。したがって、翻訳によって作ったデータは日本語データセットとしてはすでにかなり大きい規模になっていることがわかります。
データサイズはフィルタリングをどうかけるかなどによって変わる面が強く、大きいデータがよいというわけではないのも確かです。しかし、フィルタリング等をする元となるデータを多く用意しておくことは高品質なデータセットを大量に用意するために重要と考えています。
表1にデータセットの初期検証として1Bモデルを100Bトークン学習した結果を示しました。
日本語での知識を問うJMMLUではfineweb2よりも良い性能を示しており、日本語データセットとして十分利用価値のあるものであることがわかります。
一方で、日本語でのみ登場するような日本固有の知識を問うJMMLU日本問題及びpfgen-benchではfineweb2のほうが良いという結果となりました。これは英語のWebデータの翻訳データであることを考えれば当然の結果だと考えています。
| データセット | JMMLU (continuation, 5-shot, acc_norm) |
JMMLU 日本問題 (continuation, 5-shot, acc_norm) |
pfgen-bench |
| fineweb2 (日本語のみ) | 0.317 | 0.67 | 0.469 |
| 翻訳データセット | 0.354 | 0.52 | 0.396 |
終わりに
LLMの事前学習向けデータセットを生成するシステムを紹介しました。LLMの事前学習は大量のGPUを必要とするため、その有効活用は非常に重要な課題です。事前学習の実効効率をあげるなど学習そのものだけでなく、様々な観点からGPUを有効活用できるように工夫しています。
PFN/PFEでは、今後も事前学習・事後学習を問わず様々な技術を駆使して基盤モデルの開発を行っていきます。
本記事で紹介したような仕事に興味のある方はぜひ以下をご覧ください。