Blog
本記事は、2022年度PFN夏季インターンシップで勤務された石﨑慎弥さんによる寄稿です。
1. はじめに
2022年度夏期インターンシップに参加させていただいた、京都大学大学院情報学研究科知能情報学専攻1回生の石﨑慎弥です。普段は自動運転に関連するコンピュータビジョンの研究を行っています。
今回のインターンでは、リモートセンシングデータに対する画像解析・超解像というテーマで、画像のデノイジングに取り組みました。
2. 背景
2.1. SAR画像のデスペックリング
近年SAR(Synthetic Aperture Radar)というセンシング技術が発達しています。日本語で合成開口レーダーといい、主に人工衛星などに取り付けられて地表の様子をセンシングしています。SARはマイクロ波を使ったアクティブセンシング技術であり、その物理的特性から雲や雨といった気象の影響を受けにくいという強みがあります。また、SARそのものの技術発達により、航空機に取り付けられたSARから15cmの空間分解能で地表面の画像化に成功しています。しかし、その一方で広範囲をセンシングするとその分画像のファイルサイズも大きなものになってきます。航空機上で、観測したSAR画像を準リアルタイムで通信する場合には衛星通信など帯域が限られた通信を行う必要が生じるので、特に大きなファイルサイズの画像の通信には問題が生じます。
また、SARで撮影された画像にはSAR特有のノイズが乗ることが知られており、これはスペックルノイズと呼ばれます。通常の光学画像のノイズでは加法的なガウス分布に従うノイズを考えますが、スペックルノイズは乗法的ガンマ分布に従うとされています。ノイジーな画像は、そのノイズによって画像認識を妨げる可能性があるだけでなく、画像圧縮に不向きな高周波成分を多く含み、画像圧縮を妨げる問題もあります。
上述してきたようにSARには天候や昼夜に依らず、観測したいときに高解像度で地表をセンシングできる技術である一方で、その準リアルタイムでの通信や画像認識にはスペックルノイズによる問題があり、インターンでは、これらの問題の改善に取り組みました。
2.2. この問題の難しさ
SAR画像の圧縮とデノイズ(デスペックリング)を考えた時に、この問題を難しくしている点が主に二つあります。第一に、SAR画像に正解ラベルとなるクリーンな画像が得られていません。そのため、教師あり学習の手法をとることができません。第二に、スペックルノイズがガンマ分布であるという点です。そのため、光学画像のデノイジング手法でガウシアンノイズを仮定した手法をそのまま使うことができません。
2.3. Deep Image Prior (DIP)
正解ラベルとなる画像を使わずにデノイジングできる既存手法の一つにDeep Image Prior (DIP) [1] があります。画像のデノイジングを考える場合、以下のような式を解くことが多いです。
\[
\min_x E(x; x_0) + R(x)
\]
ここで\(x_0\)はノイズ画像、\(x\)は得られた画像を指します。\(E(x; x_0)\)は\(x\)と\(x_0\)がどれだけ一致しているか、\(R(x)\)は\(x\)の正則化項になっていて、これがない場合、得られる画像は\(x = x_0\)になってしまいます。\(x\)を何かしらの関数\(f_{\theta}\)で生成することを考えたとき、Deep Image Priorで主張されていることは\(f_{\theta}\)を深層畳み込みネットワークで置き換えることで画像のデノイズができるということです。定式化すると以下のような問題を解いています。
\[
\min_{\theta} E(f_{\theta} (z); x_0)
\]
DIPでは出力画像をノイズ\(z\)から関数\(f_{\theta}\)で生成します。ノイズ\(z\)はランダムに初期化されており、学習時は固定されています。正則化項を直接設計せずCNNによって暗黙的に導入することで、上式を最適化するように学習を続けると\(x_0\)がノイズの乗った画像であるにもかかわらず、出力画像がデノイズされる、という流れです。
DIPの結果は著者のプロジェクトページで確認することができます。
2.3.1. 問題点1
Deep Image Priorを使ってデノイズした時のPSNRの結果が下図です。PSNRは二つの画像の画素値がどれぐらい近いかを示す数値でPSNRが高いほど二つの画像は似ていると言えます。下図において青のプロットが出力画像とノイズ画像とのPSNR、オレンジのプロットが出力画像とクリーンな画像とのPSNR、緑のプロットが出力の移動平均画像とクリーンな画像とのPSNRです。結果によると、学習を進めるとオレンジや緑のプロットの値が下がっていることがわかります。つまり、過学習を起こして出力画像にノイズが現れていることを指しています。
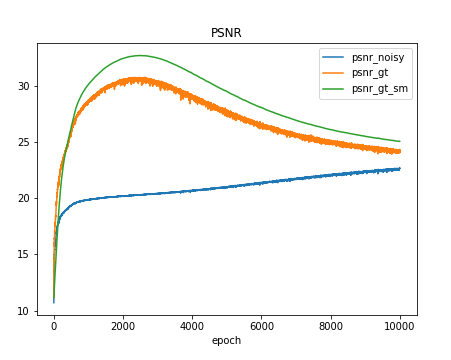
図1:過学習によるPSNRの低下
この実験では、クリーンな画像に人工的なガウシアンノイズを加えているため、クリーンな画像とのPSNRを計算することができていますが、実際の問題設定ではこれらの値は計算できません。
2.3.2. 問題点2
Deep Image Priorでは画像一枚ごとにモデルを最適化します。画像一枚の最適化には10分程度の時間がかかるため、複数の画像を一気にデノイズすることができません。そのため、できるだけ素早くデノイズするための工夫が求められます。
3. 提案手法
3.1. 提案手法1:出力画像のファイルサイズを用いたEarly Stopping
問題点1への対処として、画像のファイルサイズに着目しました。

図2:画素の平均が同じ画像に対するJPEG圧縮時のファイルサイズの違い
上図のように、同じサイズでかつ、画素の平均が同じ画像でもその模様によってファイルサイズが異なります。数値はJPEG圧縮時の結果ですが、pngなどのフォーマットでも同じ傾向にあります。画像の保存方法について、ここで詳しくは述べませんが、より高周波成分が多いほど画像のファイルサイズは大きくなります。つまり、画像がノイジーなほどファイルサイズが大きくなりやすいと言えます。この性質を利用し、出力画像のファイルサイズと、出力画像とノイズ画像のMSEを監視することでEarly Stoppingを実現します。
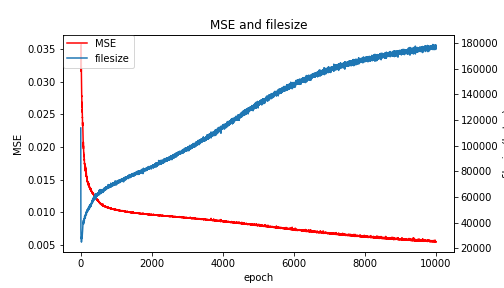
図3:学習の経過に伴うMSEとファイルサイズの挙動
DIPでの学習過程において、エポックに対するMSEとファイルサイズは上図のような挙動を示します。MSEはネットワークのロス関数でもあるため、エポックが進むにつれて単調に減少します。ファイルサイズは一度急激に小さくなった後、画像の復元が進むにつれて単調に増加します。
ここで、ファイルサイズもMSEも小さい方が望ましいということを踏まえると両者の和を指標として利用できることが考えられます。
具体的には係数\(\lambda\)を用いて\(L(\lambda) = filesize + \lambda \cdot MSE\)とし、\(L\)が最小となるエポックで学習を止めることでEarly Stoppingを実現します。
3.2. 提案手法2:事前学習による効率的なデノイジング
問題点2への対処として、複数枚の画像で一つのモデルのパラメータを事前学習しておき、活用することを考えました。
4. 実験
4.1. 提案手法1の実験
提案手法の有効性を示すために二つの実験を行いました。
まず予備実験として、ファイルサイズを用いたEarly Stoppingは実現できるのかを確かめる実験を行いました。用いる画像はBerkeley Segmentation Dataset (BSD) [2] に含まれる自然画像500枚で、400枚(train split 200枚とtest split 200枚)と100枚(val split 100枚)に分けました。各画像に人工的なノイズを付与し、Deep Image Priorで画像を復元し、10kエポックまで各エポックの出力画像のファイルサイズやPSNRを記録します。\(\lambda\)をある値に決めるとLの系列からLを最小にするエポックを求められます。そのエポックでのクリーン画像とのPSNRを最大にしたいので、400枚で共通の\(\lambda\)を用いてPSNRの平均が最大となる\(\lambda\)を求めます。その\(\lambda\)を残りの100枚に適用し、真に一番良いPSNR、エポックを10k、5k、2kで止めた時のPSNRの平均と比較します。ここで、真に一番良いPSNRとは実際には与えられていないクリーンな画像とのPSNRが計算できたとして、PNSRが最大となるエポックで最適化を終了できた場合の値です。
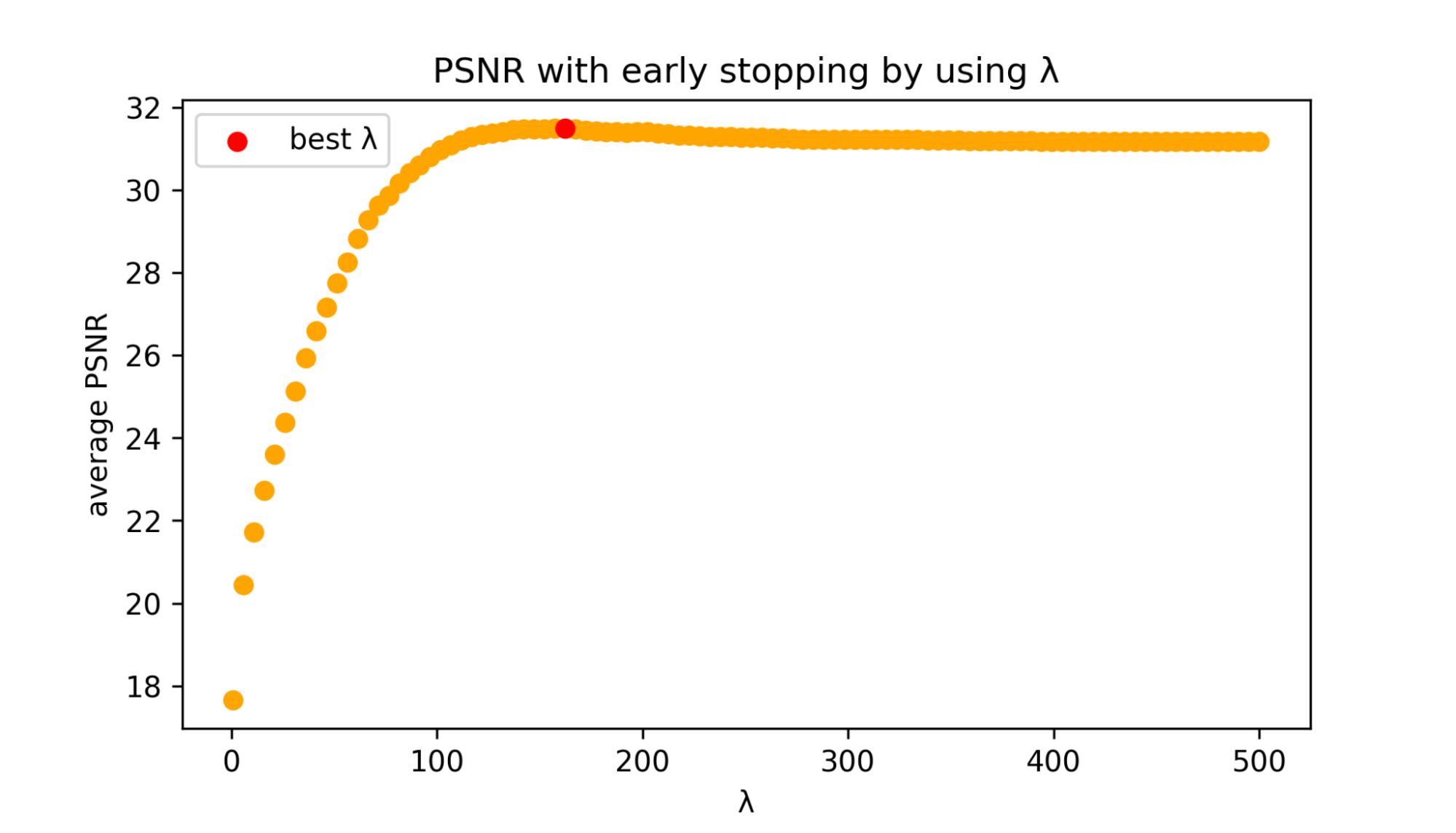
図4:BSD 400枚(train split 200枚とtest split 200枚)で\(\lambda\)を変えたときのPSNRの平均
表1:BSD 100枚(val split 100枚)での定量評価

ファイルサイズを用いたEarly Stoppingではエポックを10k、5k、2kと決めうちで止めた時よりもPSNRの値が高くなっており、その値は真に最大となるPSNRの平均に比べて差分が小さいことが確認できました。また、10kエポックで止めた時に比べてEarly Stoppingした時のPSNRが低くなる画像は100枚中3枚しかありませんでした。このことからファイルサイズを用いたEarly Stoppingに有効性がありそうだと考えました。
次に、ノイズの大きさを複数変えて実験しました。ガウシアンノイズの標準偏差を5から75まで変えて、標準偏差ごとに\(\lambda\)を求めて実験を行いました。この実験では、 予備実験の評価に用いた100枚の中から、デノイジングのベンチマークとして用いられている68枚を対象に評価を行いました。
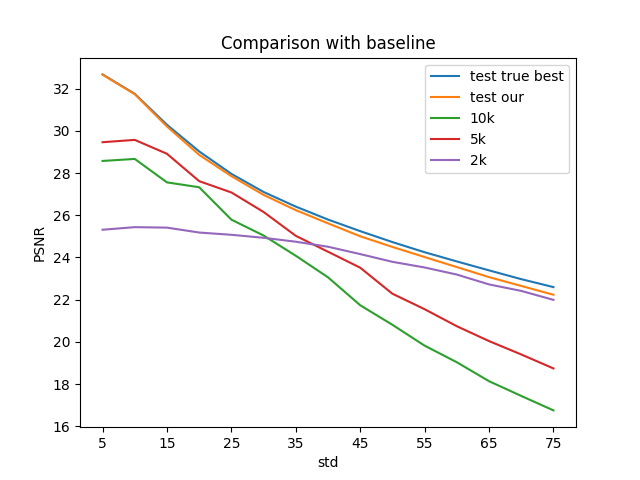
図5:ノイズの大きさを変えたときのPSNRの平均のプロット
表2:ノイズの大きさを変えたときのPSNRの平均

今回は\(L\)について\(L(\lambda) = filesize^2 + \lambda \cdot MSE\)として、ファイルサイズが大きなところでの差分についてより強い正則化をかけました。結果、提案手法では10k、5k、2kエポックのいずれで止めた時よりもPSNRの平均が良く、その画像のPSNRが真に最大となる値の平均にかなり近づけることができました。
ここで、今回ファイルサイズの二乗を用いた理由は、ファイルサイズの大きなところ、つまり復元が進んだところでの正則化をより強くかけるためです。ファイルサイズの増加具合はほぼ単調、あるいは徐々に緩やかになっていきます。達成したい目標は十分に画像が復元された点において学習を止めることであるため、復元の程度にかかわらない正則化は適切ではありません。
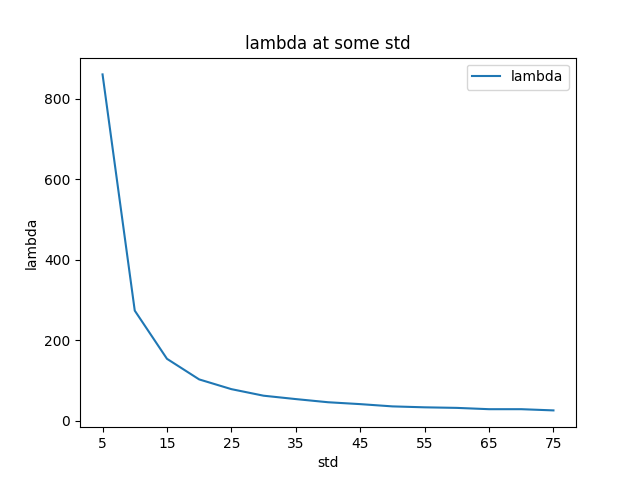
図6:ノイズの大きさを変えたときの\(\lambda\)
ノイズの大きさによって\(\lambda\)の値は変わり、上図のような結果になりました。ノイズが小さい時、MSEとPSNRの挙動にはかなり強い相関があるので、MSEが最小となるエポック\(\simeq\)PSNRが最大となるエポックになります。一方、ノイズが大きい場合、ファイルサイズが大きくなりすぎないように制限する必要があります。
4.2. 提案手法2の実験
今回最終的に復元したいSAR画像は地表を撮影しているため、RESISC45 [3] というデータセットの中のMountainのクラスに分類される画像700枚を用います。600枚の画像で一つのモデルを事前学習し、そのパラメータを初期値として100枚の各画像をDIPによって復元します。DIPではモデルの入力\(z\)はランダムな固定されたノイズですが、入力\(z\)も最適化することで早くかつ良くデノイズできるのではと考え、事前学習の有無、\(z\)最適化の有無の4パターンで実験を行いました。
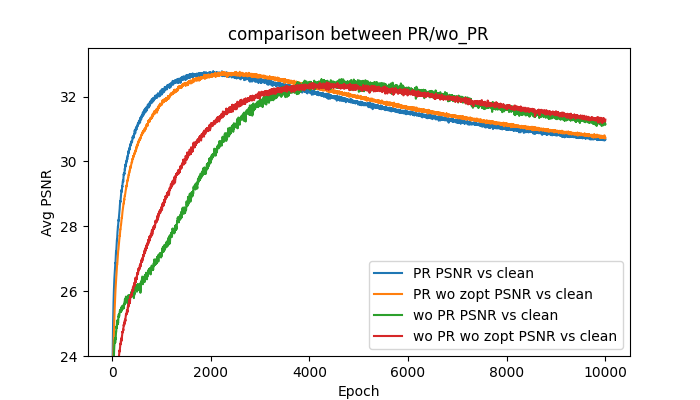
図7:事前学習の有無および\(z\)の最適化の有無に対する比較
表3:PSNRの最大値
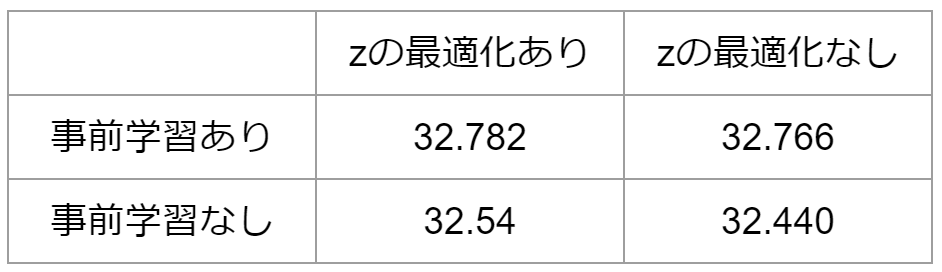
表4:PSNRが最大となるエポック数の平均

まずPSNRの最大値については事前学習の有無、\(z\)の最適化の有無にかかわらずあまり値は変わりませんでした。次にPSNRが最大となるエポック数の平均ですが、事前学習有りに比べて無しの方がエポック数は少なく、\(z\)最適化が有りに比べてなしの方がエポック数は若干少なくなりました。しかし、今回の実験での\(z\)の最適化は一回ネットワークのパラメータが更新される間に\(z\)は10回更新されており、同じエポックにかかる時間は\(z\)最適化なしの方が6倍程度速くなります。つまり、事前学習ありのモデルを用いて、\(z\)を固定していた場合が最も効率よく画像をデノイズすることができ、エポック数は0.6倍程度になりました。
5. まとめ
今回は、画像のデノイジングをテーマに、Deep Image PriorのEarly Stoppingを出力画像のJPEG圧縮時のファイルサイズを正則化項とすることで実現出来ました。自分の専攻と同じコンピュータビジョンの範囲ではありますが、デノイジングはあまり馴染みのない分野であったため、論文のサーベイや手法の理解に手間取る場面もありましたが、毎日の濃密なミーティングなどでメンターである前田さん、高木さんから多大なるサポートをいただき、結果に結びつけることが出来ました。
また、今回は大規模データセット上での実験が多く、PFNの大規模クラスターを存分に
つかうことができました。Cluster Servicesチームの皆さんにも大変お世話になりました。一ヶ月半という短い時間ではありましたが、非常に充実した毎日を過ごすことが出来ました。関わっていただいた全ての皆様に感謝申し上げます。本当にありがとうございました!
6. 参考文献
[1] Dmitry Ulyanov, Andrea Vedaldi, Victor Lempitsky, Deep Image Prior, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 9446-9454. [project page]
[2] Berkeley Segmentation Data Set and Benchmarks 500 (BSDS500). [dataset page]
[3] Gong Cheng, Junwei Han, Xiaoqiang Lu, Remote Sensing Image Scene Classification: Benchmark and State of the Art, in Proceedings of the IEEE, vol. 105, no. 10, pp. 1865-1883, Oct. 2017, doi: 10.1109/JPROC.2017.2675998.
