Blog
はじめに
2023年度夏季インターンシップに参加させて頂きました、京都大学大学院情報学研究科知能情報学専攻1年の田村駿弥です。今回のインターンシップでは、拡散モデルを活用した商品画像のData Augmentationを行い、商品の分類精度を向上させるというプロジェクトに取り組みました。
背景
リテールチームでは、何の商品かを画像から推論する商品分類モデルを作成しています。商品分類モデルの学習にあたって、対象商品を3Dスキャンしたデータを用いて、架空の商品棚に対象商品を陳列させてレンダリングします。得られた大量のアノテーション付きCG商品画像を用いて商品分類モデルを学習させることで、高精度な商品の分類が可能となっています。

レンダリングしたCG商品画像の例
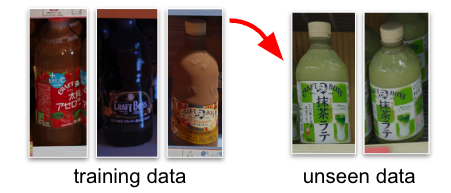
しかし、日々開発される新商品を全て3Dスキャンすることは非現実的であるため、3Dスキャンなしで分類精度を上げる手法が、特に数枚の商品写真のみを用いたfew-shotでの商品分類の実現が求められていました。そこで、近年注目を集めている拡散モデルを用いて、その数枚の商品画像から、配置等に多様性のある同じ商品の大量の画像を生成し、その画像を用いて商品分類モデルを学習することを検討しました。

学習に利用可能な商品画像の例
拡散モデル
Stable Diffusionの公開を皮切りに注目を集めるようになった拡散モデルとは、画像に微小なガウシアンノイズを無限に足し合わせると、最終的にガウシアンノイズになるという仮定のもとで、その逆過程を学習し、ノイズから画像を生成させるというものです。
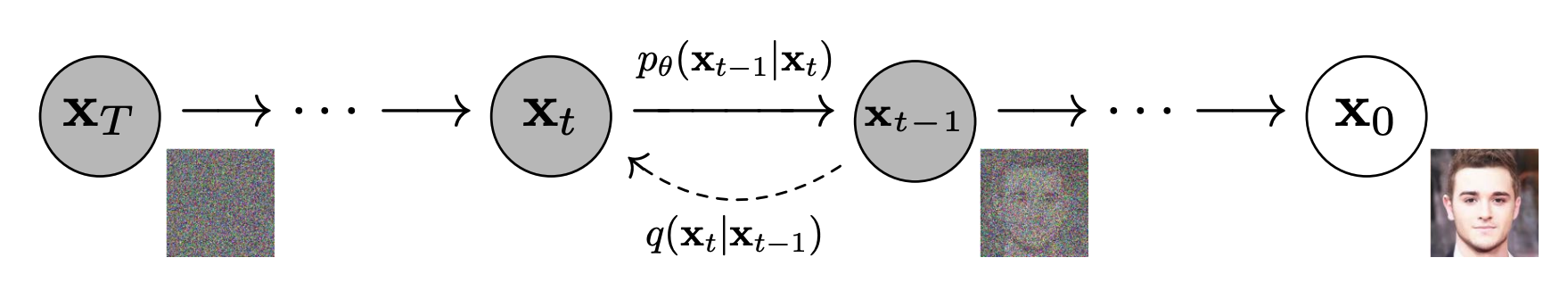
拡散モデルの概念図([1]より引用)
ただしこれでは、H x W x C のピクセル空間において生成を行う必要があり、高解像度の画像を生成するためには、計算量が膨大となってしまいます。そこで提案され、Stable Diffusionにも用いられているのがLatent Diffusion Modelというもので、この拡散モデルを次元圧縮した潜在空間において学習し、デコーダーを用いてピクセル空間に戻すことで画像を生成させるというものです。

Latent Diffusion Modelの概念図([2]より引用)
Low-Rank Adaptation (LoRA)
Stable Diffusionの公開モデルでは、今回必要な商品棚に置かれたような対象商品の商品画像を生成させることは難しいため、その用途に適したモデルとなるようにfine tuningする必要があります。しかし、Stable Diffusionのような大規模なモデルの全てのパラメータをfine tuningするには、膨大な計算量が必要となります。そこで近年LLMの文脈から提案されたものがLoRAと呼ばれる手法です。これは、学習済みの重みは保持しつつ、2つの低ランク行列のみを用いてfine tuningを行うことで、更新が必要なパラメータ数を大幅に削減して学習を行うというものです。
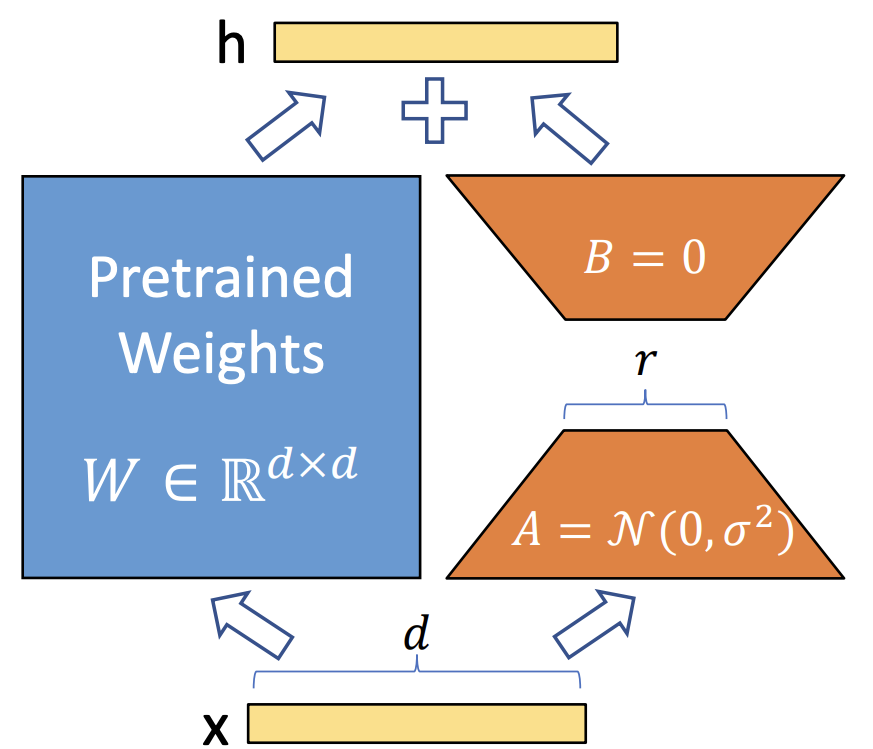
LoRAの概念図([3]より引用)
sd-scriptsを用いたLoRAモデルの作成
セットアップ時間の短縮化
Stable DiffusionをLoRAでfine tuningするスクリプトとして公開されているものの中で、特に開発が活発なものにsd-scriptsというリポジトリがあります。元々の実装では、学習のセットアップ時に全ての画像とそのキャプションファイルを一度読み込むようになっており、学習させる画像の枚数に伴って線形に時間が増加してしまうという問題がありました。特に、今回最大で約200万枚の画像を用いて学習を行いましたが、その際に20時間以上もの時間がセットアップ時にかかってしまいました。
そこで、全ての画像サイズとキャプションを商品クラスごとに1つのjsonファイルにまとめ、そのjsonファイルを読み込んで辞書型で保持し、適宜その辞書から参照するように実装しました。また、PFN社内のシステムを用いることで、再度画像にアクセスする必要がある場合はキャッシュから読み込むように実装しました。これらの実装を行うことで、セットアップ時間を数分単位にまで大幅に短縮することができ、実験を円滑に進めることができるようになりました。
GeneralモデルとSpecializedモデル
LoRAモデルを作成するにあたって2つの方針を検討しました。1つ目がGeneralモデルで、学習用CG商品画像の全てを用いて学習を行うという方針です。これは商品が商品棚に置かれているという状況自体を学習させることができ、未知の商品であってもその商品の特徴を残しつつ、商品棚に置かれたような画像が生成できることを期待したものです。2つ目がSpecializedモデルで、生成させたい商品と同系列のシリーズ商品のみを学習させるという方針です。同系列の商品であればデザインが似通っているため、学習可能な画像枚数が少なくとも、Generalモデルよりも生成品質が向上することを期待したものです。

Generalモデルのイメージ図
Specializedモデルのイメージ図
Reference Only
Reference Onlyとは、Stable DiffusionのAttention層にReference画像を直接リンクさせることで、その画像と一貫性を保った画像が生成できるというものです。この手法を用いて、生成させたい商品画像1枚をReferenceとして生成させれば、その商品と同じ商品でありつつ、多様な画像が生成されることが期待されます。
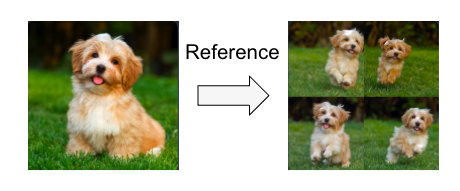
Reference Onlyの適用結果例([5]より引用)
画像生成結果
前述のReference Onlyの手法を用いて、SpecializedモデルとGeneralモデルそれぞれで商品画像を生成しました。その結果、Specializedモデルの方が、元の商品画像との一貫性を保ちつつ、多様な商品画像を生成できる傾向を確認しました。ただし、一部商品については、学習元の同系列シリーズに生成結果が寄りすぎた結果、目的の商品とはかなり見た目の異なる商品が生成されてしまい、Generalモデルの方が高品質となりました。

Specializedモデルの方が高品質な例

Generalモデルの方が高品質な例
Classificationの学習
SpecializedモデルとGeneralモデルを用いて、各商品ごとに2,000枚の画像を生成し、それらの画像を用いて商品分類モデルを学習させました。その分類モデルを用いて、実写画像を用いて分類を行った結果を比較すると、Specializedモデルを用いた方が全体的に正解クラスへのConfidenceの値が大きくなるという結果となりました。
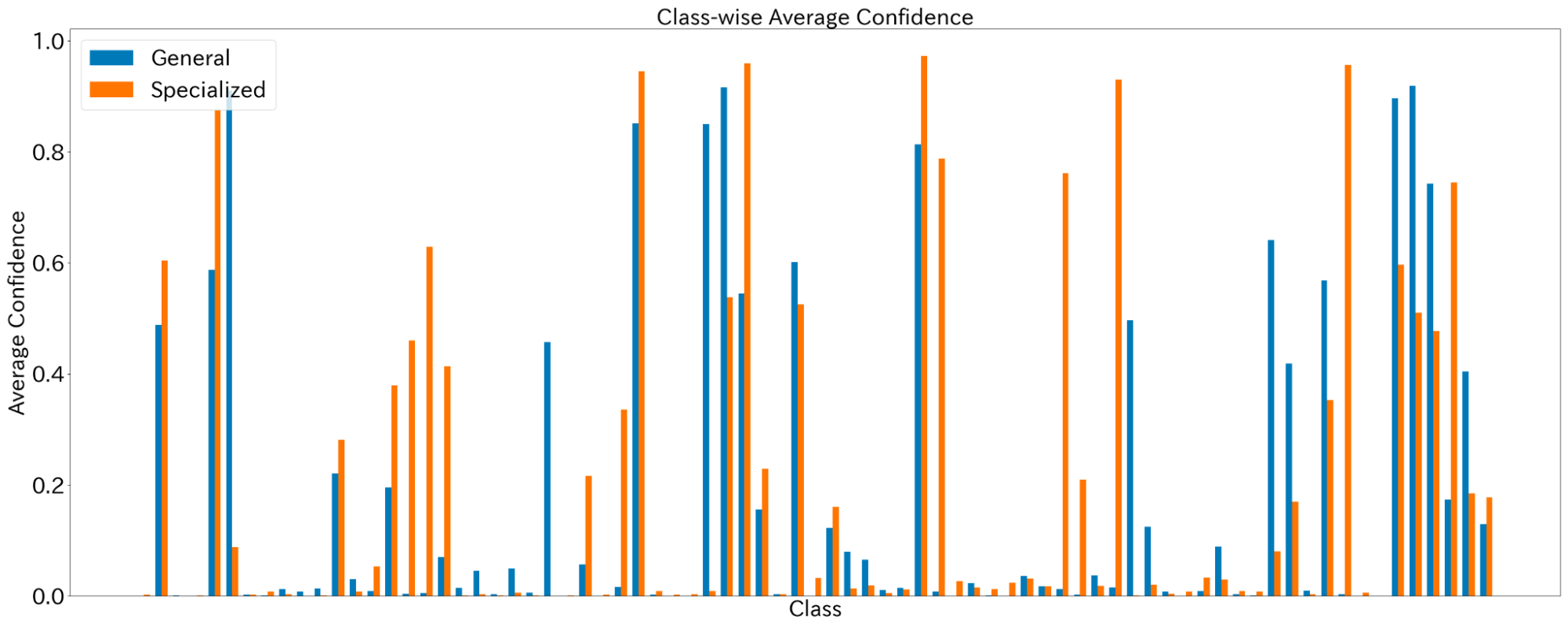
商品クラスごとの正解クラスのConfidenceの比較
しかし、商品ごとに1枚の画像のみを用いて学習させた結果(ベースライン)と比較すると、Specializedモデルの正答率が0.50であるのに対し、ベースラインの正答率は0.57となり、生成画像を用いて学習した方が却って精度が下がってしまうという結果となりました。
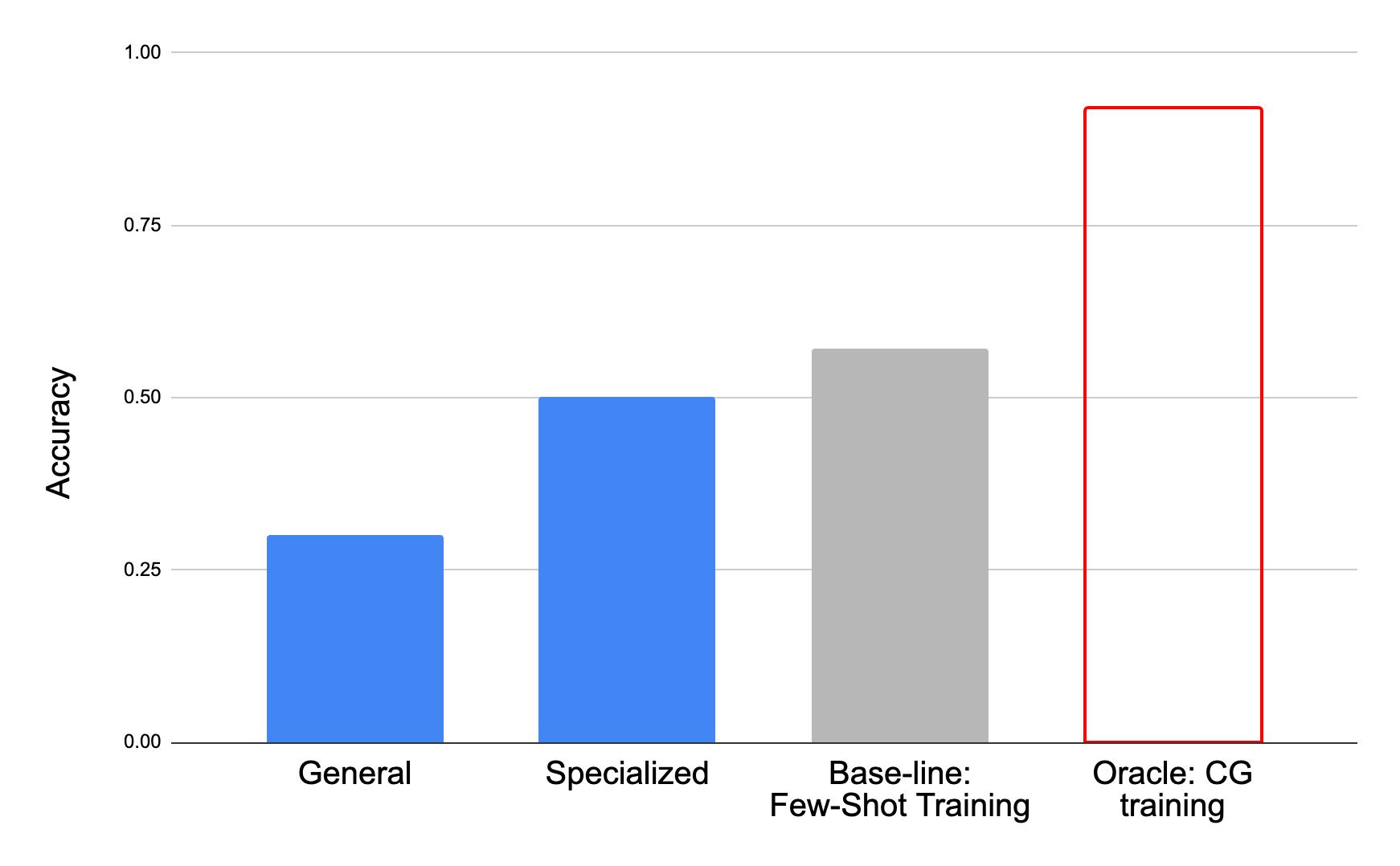
商品分類精度の比較
分類精度が下がってしまった原因として、目標の商品との一貫性が乏しいということが考えられます。今回、他にも様々な手法を試みましたが、商品の一貫性を保つことと、多様性のある商品画像を生成することにはトレードオフの関係があり、多様性を担保するためにはどうしても商品の見た目が異なるものが生成されてしまうという問題がありました。
今後の展望
今回のインターン期間中に試みた実験のうちの一つに、LoRAの学習時に指定するpromptを手作業でより詳細に記述した上で学習を行うというものがありました。その結果、学習データにはない白い缶コーラを、かなり忠実に生成することができました。この手作業による詳細なキャプショニングを自動化できれば、高品質な商品画像を生成することができ、商品分類モデルの精度向上に寄与できるのではないかと考えています。この詳細なキャプショニングの自動化には、img2txtとして有力なモデルであるBLIP2のfine-tuningが有効であると考えています。

学習時のキャプションを詳細にした実験結果
感想
今回のインターンでは、商品分類モデルの精度向上を目的として、拡散モデルを用いた様々な検討を行いました。結果的に精度の向上に寄与することができず、少し悔いの残る結果となってしまいましたが、最新の技術を多方面から検討することができ、非常に充実した時間を過ごすことができました。
また、今年度が数年ぶりのオフラインでのインターンであったということで、インターン生・社員の方々との様々な交流イベントを企画していただきました。その中で社内の多くの方とお話をする機会があり、社内文化について深く知ることができました。特に異分野の方々とお話しする中で、新しい知識を吸収するモチベーションが高まりました。
最後になりましたが、インターン生と社員の方々、特に主メンターの山田さん、副メンターのAlexisさんを始めとする、リテールチームの皆さんには大変お世話になりました。この場を借りて感謝申し上げます。
参考文献
[1] Jonathan Ho, Ajay Jain, and Pieter Abbeel, Denoising diffusion probabilistic models, Advances in neural information processing systems, (2020)
[2] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ̈orn Ommer, High-resolution image synthesis with latent diffusion models, IEEE/CVF conference on computer vision and pattern recognition, (2022)
[3] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen, Lora: Low-rank adaptation of large language models, arXiv preprint arXiv:2106.09685, (2021)
[4] sd-scripts, https://github.com/kohya-ss/sd-scripts
[5] Reference-only Control, https://github.com/Mikubill/sd-webui-controlnet/discussions/1236
Appendix
以下に生成した画像例を掲載します。
txt2img
CG学習データに存在する商品に関しては、その商品名のみをpromptとする単純なtxt2imgで生成するだけで、一貫性がありつつ、多様性も高い商品画像を得ることができました。

学習元データにある商品の生成例
Generalモデル
Generalモデルでは、特にReference画像に似た商品が学習データに少ない場合に、全く異なる商品画像が生成される傾向がありました。しかし、全く同じ条件で生成しているにも関わらず、比較的一貫性を保った商品画像が生成される場合もありました。

Generalモデルでは上手く生成できなかった例

高品質に生成できた例
Specialized モデル
Specializedモデルでは、Generalモデルよりも高品質に生成できるものが多かったですが、同系列商品に生成結果が寄せられすぎるあまり、生成させたい商品とは見た目が異なる商品が生成されてしまう場合がありました。

異種フレーバー商品に生成結果が寄せられすぎてしまう例

高品質に生成できた例
