Blog
この記事は、パートタイムエンジニアとして勤務していただいている藤井一喜さんによる寄稿です。
はじめに
Preferred Networks (以下PFN) では、大規模言語モデル (LLM) に関する研究開発を行っています。これまでのブログ記事では、事前学習の状況 やそのための学習データの整備など、LLMを学習するための取り組みを紹介してきました。
学習データがモデルに与える影響は大きく、次々と公開されるオープンデータセットや社内で開発したデータセットの品質を迅速に判断できることはモデル開発において非常に重要です。しかし、あるデータセットを採用するかどうか判断する際に、LLMをfrom scratchから学習して比較していては莫大な計算資源と時間を要してしまい現実的ではありません。現実的には、数B規模のPre-trainedモデルから継続学習することでアブレーションを行う方法が用いられていますが、計算コストは無視できず、より簡便な方法が求められています。
今回、Bits Per Character(BPC)を利用しベンチマークスコア(HumanEvalとMMLUのスコア)を予測することが出来ないか検証を行いましたので、その結果と方法を紹介します。
検証した手法のモチベーションと目標
データセットAとBどちらを学習に採用するべきか判断する最も確実な方法は、LLMをそれぞれのデータセットだけで学習し、同じトークン数学習したある時点でのベンチマークスコアを比較することです。しかし、この方法には2つの実用上無視できない問題があります。
1つ目は、必要な計算コストの大きさです。ベンチマークタスクによっては1B未満の小規模モデルでは十分な性能が獲得できず、意味のある比較ができないことがあります。そのため、学習するモデルサイズは一定パラメータ数以上とする必要があります。加えて、from scratchからの学習では、比較可能な水準に至るまでに学習トークン数が多く必要となり、必要な計算コストを増加させる要因となっています。2つ目は、from scratchの学習に利用できるほどのトークン数(数100Bトークン以上)があるデータセットでないと比較できない点です。
from scratchではなく継続学習により比較を行うことで、必要トークン数の削減による計算コストの削減と、それに伴いより小さなデータセットでも比較可能になるメリットはありますが、依然として、計算コストは無視できない水準です。また、1M サンプル未満の少量データセットの検証を単独で行うことが難しい問題は未解決です。
上述の背景から、小さなモデルで少量のデータを学習するだけでデータセット間の比較が可能な手法が求められています。そこで直接ベンチマークタスクスコアを比較するのではなく、Compression Represents Intelligence Linearlyを参考に学習データに対するBPCやベンチマークタスクのデータセットに対するBPCを計測することでベンチマークタスクのスコアを計測することを代替することができないか検証を行いました。HumanEvalやMMLUのようなベンチマークは、一定のコード生成能力、QAで問われる知識をLLMが有していないと解けないため、1B未満の小さいモデルではスコアが0付近となる、または選択肢の場合は乱択に近い値となり上手く性能を測定するのが困難であるという問題がありましたが、BPCは小さなモデルでも値を算出することが可能であるため、これらの問題を解決することができる可能性があります。
こうした点をふまえ、
- BPCによりオープンLLMのベンチマークタスク性能を予測できるか
- BPCにより異なるデータで学習されたLLMの性能の大小関係を予測できるか
をコード生成タスク(HumanEval)とマルチタスクQA(MMLU)にて検証を行いました。
なお、BPCは以下の式で計算されます。(\(X\) はコーパス、\(N\)は\(X\)の総トークン数、\(T\)は\(X\)の総文字数を表します)
\[ \text{BPC} = – \frac{\log_{2} p_{\text{model}}}{T} = \frac{\sum_{i=1}^{N} -\log_{2} p_{\text{model}}(x_{i}|x_{1:i-1})}{T}\]
検証1: コード生成タスクとBPC
Stack-Eduに対するBPC
コード生成タスクとしてHumanEvalを選び、Compression Represents Intelligence Linearlyが実際に成り立つのか検証を行いました。まず、論文中では、GitHubから収集したコードデータに対するBPCを計測していますが、今回の検証では、stack-eduから8000サンプルを抽出し、これらに対するBPCを計測しました。その結果、図1が示すように高い相関係数を示し、論文の結果を概ね再現することができました。
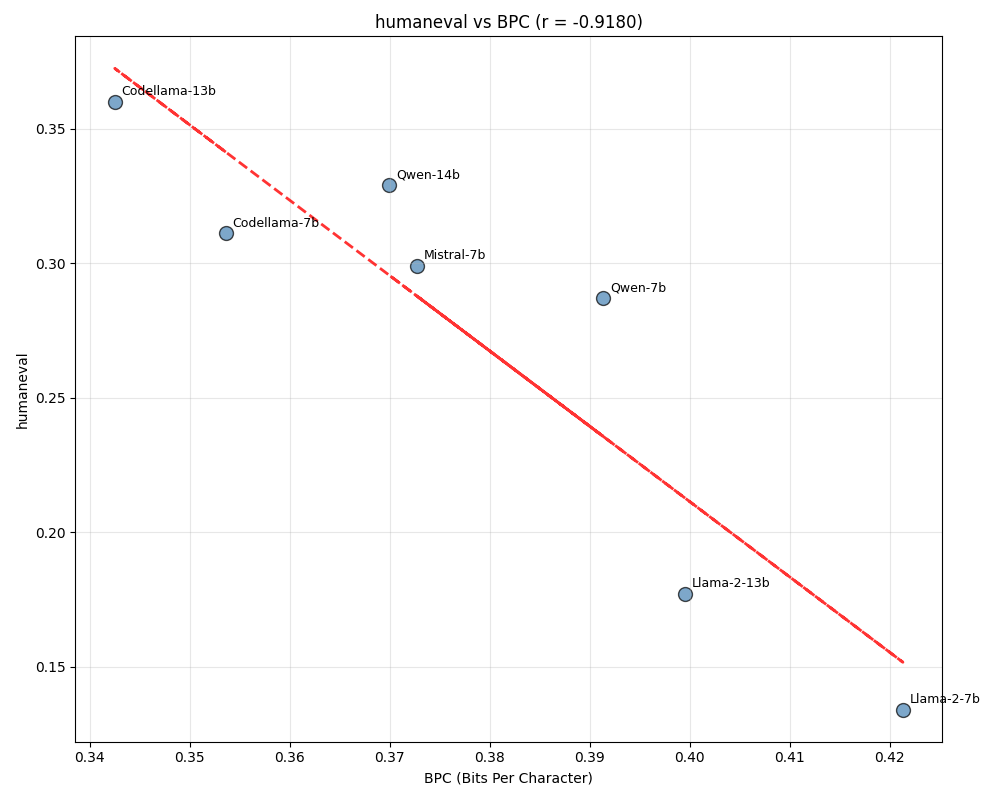
図1: 2023年末までのモデルにおけるBPC(stack-edu) vs HumanEval
BPCを算出するデータセットをGitHubからstack-eduに変更することが問題でないと判明したため、論文中では調査されていない近年公開されたモデルを中心にプロットするモデル数を増やしました。すると、図2が示すように、相関係数は大きく低下し、主に3つのモデルグループに分かれる現象が確認されました。
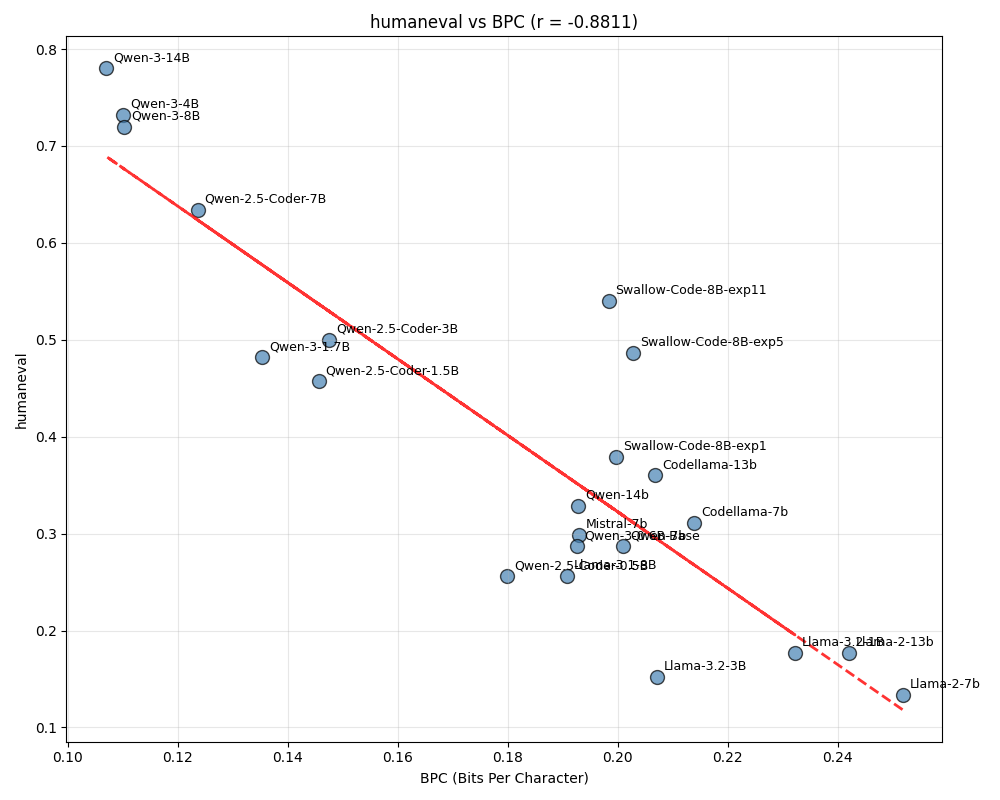
図2: 2024年以降のモデルも含めた BPC(stack-edu) vs HumanEval
分析の結果、Qwen-2.5-Coder、Qwen-3はともに学習データとしてLLMから出力された合成データを利用しており、これらのモデルが生成するコードはフォーマット、コメントの量などがstack-edu中に含まれるデータとは異なることが判明しました。
学習データに含まれる合成データにより、出力されるコードの形式がベンチマークの答え (ground truth) とは大きく異なるものとなり、BPCとHumanEvalのスコアの関係が大きく変化することが判明ししました。この影響を除いてBPCの信頼性を上げるため、pfgen-benchを参考に、many-shotによる出力の制御を行いました。pfgen-benchは質問と100字程度の回答を20 shots与えることで、事前学習モデルの出力を100字程度となるように制御しています。同様に、コメントやPythonのtype hintを排除した回答例を20サンプル与えた上でBPCを測定することで、それぞれのLLMが生成しがちなフォーマット、コメントの量の特徴を抑え、BPCとHumanEvalスコアとの間に高い相関が得られないか検証を行いました。
<HumanEval プロンプト 1> <コメント、type hintを排除したsolutionコード 1> <HumanEval プロンプト 2> <コメント、type hintを排除したsolutionコード 2> ...
図3: LLMが生成するコードを誘導するmany-shotsの様子
しかし、SwallowCodeのアブレーションモデルの中で調べると、BPCが低いモデルほど、高いHumanEvalスコアであることが期待されるところ、逆の関係を示しており、stack-eduに対するBPCの大小関係からHumanEvalのスコアの大小関係を予測することが依然として困難であることが判明しました。
HumanEvalのsolutionに対するBPC
stack-eduに対するBPCを計測することによりHumanEvalのスコアを予測することが難しいと判明したため、方針を変えることにしました。具体的には、BPCを計測する対象を最新のLLMの出力結果に変えることで、高いコード生成能力を示すモデルが出力しがちなフォーマット、コメントの量を考慮したBPCの計測が可能になると考え、Qwen-3-32B-BaseにてHumanEvalのsolutionを生成させ、そのsolutionに対するBPCを各モデルで計測することにしました。
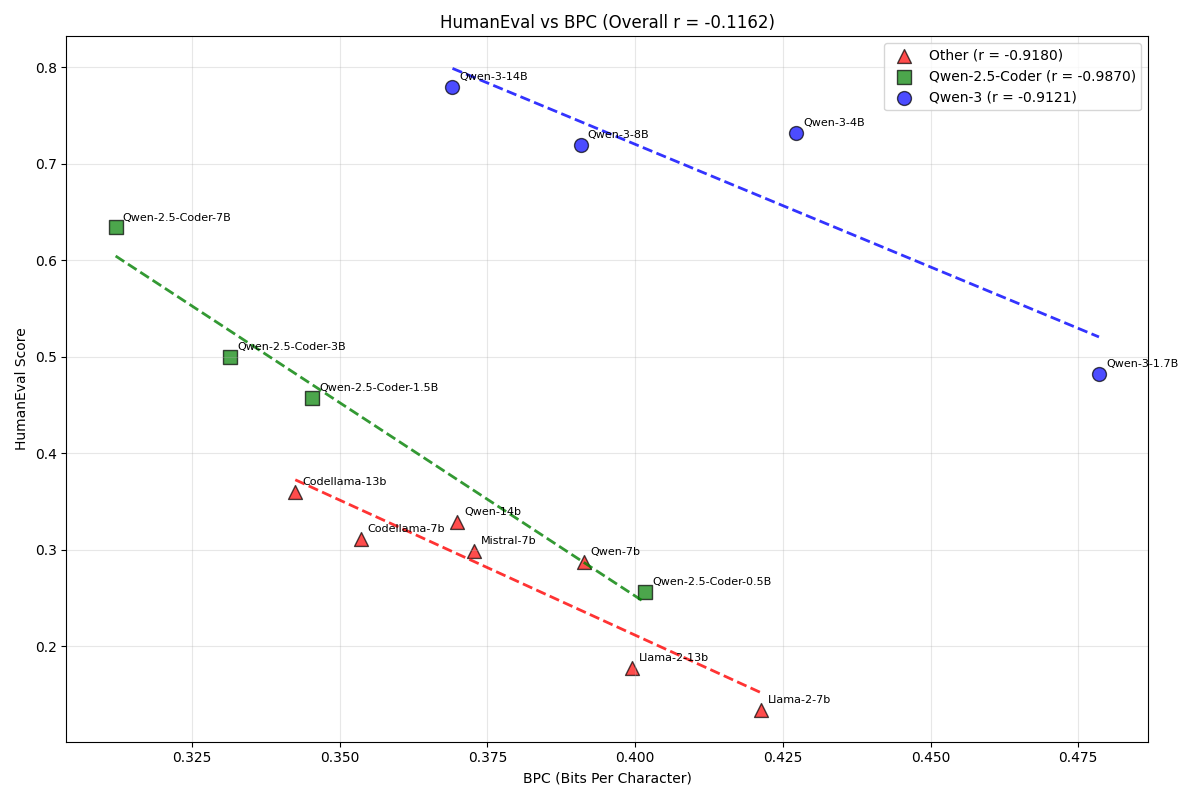
図4: BPC(HumanEval solution vs HumanEval)
図4が示すように、相関係数は図2よりも改善したものの、SwallowCodeのアブレーションモデルexp1, exp5の関係性がBPCから予測されるHumanEvalの大小関係と実際の値が逆になる現象は改善されていないなど、すべてのモデルで正確に予測できるわけではないことが判明しました。以上から、BPCをHumanEvalの代わりとすることは難しいと結論付けました。
検証2: マルチタスクQAとBPC
マルチタスクQAとしてMMLUを選び、「正解の選択肢を選ぶ、または正解の選択肢に相当する答えを出力するには、問題文をLLMが理解できているはずである」と考え、問題文(question)に対するBPCとMMLUのaccuracyの関係性を検証しました。
その結果、図5が示すように、仮説通りBPCとMMLU accuracyの間に高い相関係数をみとめることができました。しかしながら、HumanEvalでも観察されたように、いくつかのモデルにおいてはBPCから予測されるaccuracyの大小関係と実際のaccuracyの大小関係が逆転する例がいくつか存在し、MMLU question BPCによりMMLU continuation accuracyを完全に予測することは難しいと結論付けました。
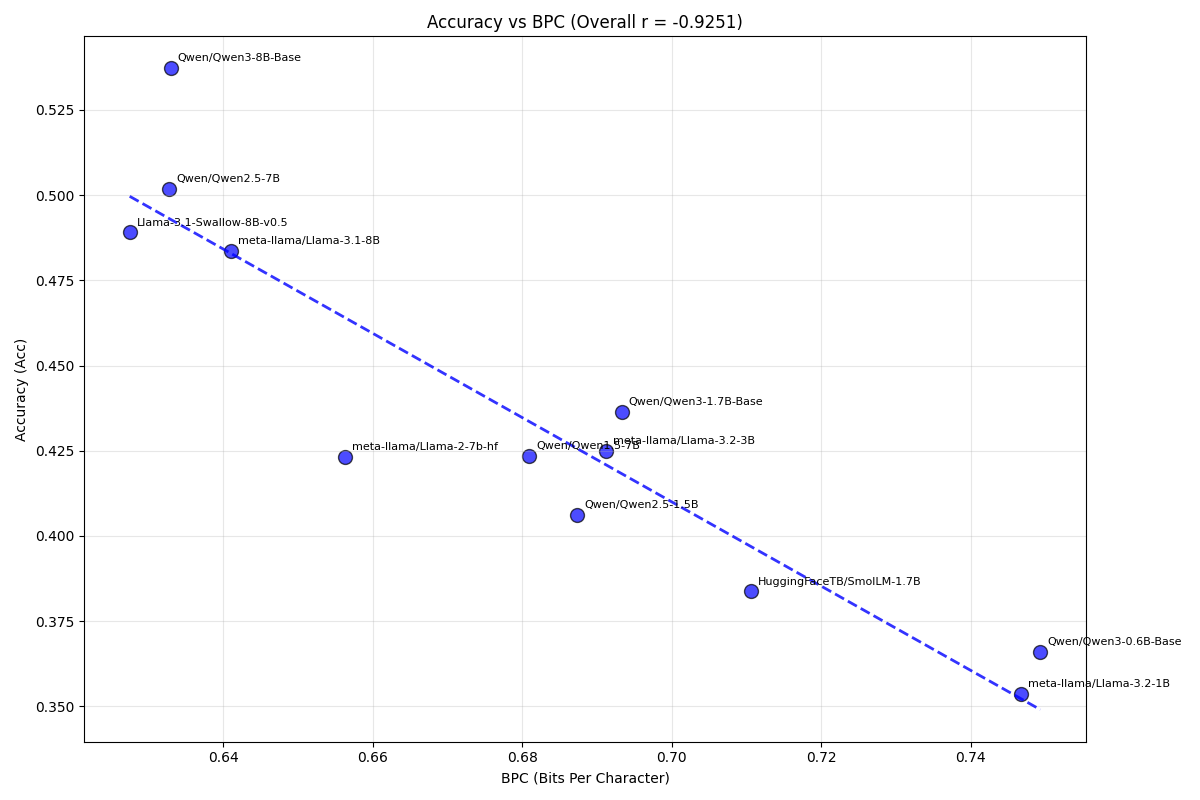
図5: BPC(MMLU question) vs MMLU continuation
検証結果
BPCはベンチマークスコアの代替として機能するか
BPCの計測方法を工夫することでベンチマークスコアと高い相関を得ることは可能ですが、学習データの採用/不採用を決めるような場合にベンチマークが示す大小関係とは異なる結果を出力しうる手法を単独で利用することはできないため、十分に信頼できるベンチマークスコアの代替とはBPCスコアをみなせないことが検証を通じて判明しました。
合成データがBPCに及ぼす影響
BPCは、合成データが持つフォーマット等の特性に敏感であり、図2で示したようにBPCを測定する対象によってはベンチマークスコアとの相関係数すら非常に低くなってしまうことが判明しました。様々なデータ生成方法が提案されている今日において、BPCのようにフォーマットに敏感な指標をモデル開発における意思決定に使うことは現状では難しいと考えています。
おわりに
LLMの開発において、データセットの品質を正しく評価することは非常に重要です。今回の検証では、実験サイクルを早く回す上で有用な方法とBPCの有用性を模索しましたが、採用することが出来ませんでした。しかし、今後もモデルをただ学習するだけでなく、高性能なLLMを学習するために全力を尽くしていきます。
仲間募集中
PFNでは今後もLLMの開発を継続して行っていきます。開発は今回紹介した以外にも多岐にわたります。我々はこれらの課題に情熱をもって挑戦していく仲間を募集しています。
これらの仕事に興味がある方はぜひご応募よろしくお願いします。
Area



