Blog
少数の病変部位アノテーションを活用したMultiple Instance Learningの拡張
Yohei Sugawara
本記事は,2020年インターンシッププログラムで勤務された髙木優介さんによる寄稿です.
はじめに
PFN2020夏季インターンに参加させていただいた,名古屋工業大学大学院修士1年の髙木優介です.研究室では,医用画像に対する機械学習,メタ学習の研究を行なっています.今回のインターンではMultiple Instance Learning (MIL) と呼ばれる手法において,病変部位のアノテーションを含まない画像に加え,一部のみ病変部位のアノテーションが付与された画像も使用できる設定で学習を行う研究に取り組みました.
背景
近年,医用画像(X線画像,CT画像,病理画像など)に対して機械学習を用いて,診断補助や臓器のセグメンテーションなどを行う研究が数多く存在します.しかし,医用画像を機械学習で用いる上で2つの大きな問題点が存在します.
1つ目は,医用画像が大抵の場合,機械学習で扱うには大きすぎるという点です.例えば病理画像(図1)の場合,画像サイズは数万 x 数万ピクセルになります.
図1 病理画像のイメージ.[1]から引用
このような画像に対して分類問題を行う際は,元画像をリサイズするか,小さい画像を切り出して学習に用いるのが一般的です.しかし,医用画像においてはそのどちらも不適切な処理となってしまう場合があります.例えば病理画像にみられるようなギガピクセル画像を機械学習で扱いやすいサイズに縮小すると,ほとんどの情報が失われてしまうことになります.また,病変部位(≒ 分類に寄与する領域) が画像の局所的な部分にしか存在しない場合,画像を切り出すことでそうした重要な情報が失われてしまう可能性があります.
2つ目は,病変部位アノテーションを得るのにコストがかかるという点です.大量に蓄積された全ての画像に対して,どの部分が病変部位なのかという領域を示すアノテーションを専門医に付けてもらうのは時間や労力の面で現実的ではありません.こうした背景から,多くの大規模医用画像データセットでは,各画像に病名のラベルはついているものの,病変部位アノテーションまで付与されている画像は存在しない(もしくは一部の画像にのみ付与されている)のが一般的です.
このように,画像サイズが大きく領域アノテーションが存在していない設定で分類問題を行う際によく用いられるのが,Multiple Instance Learning (MIL) と呼ばれる手法です.
Multiple Instance Learning
Multiple Instance Learning (MIL) [2] は弱教師あり学習の一種で,各インスタンスにはラベルが存在していませんが,インスタンスの集合である”bag”にはラベルがついていて,bagに対する分類を行うという問題設定になっています.MILを画像分類で用いる場合は,1枚の大きい画像から複数枚画像(これらの画像を以降パッチと呼びます)を切り出してbagを作り,そのbagを分類します.(図2参照)
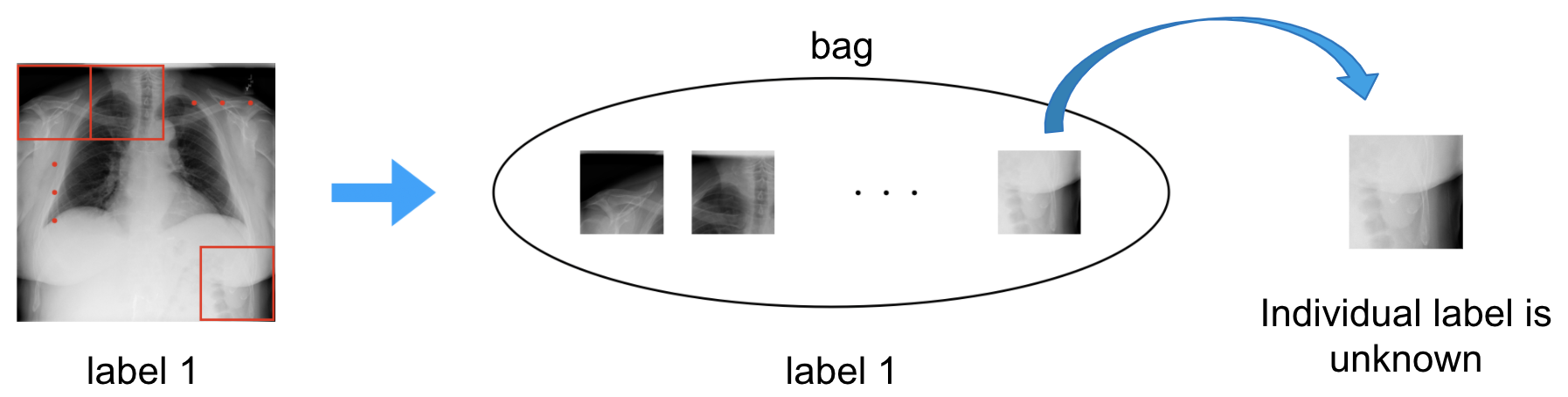
図2 画像に対するMILの例
例えば2値分類の場合,bag内に少なくとも1つポジティブなインスタンスが存在するbagとそうでないbagを分類します.(図3参照)
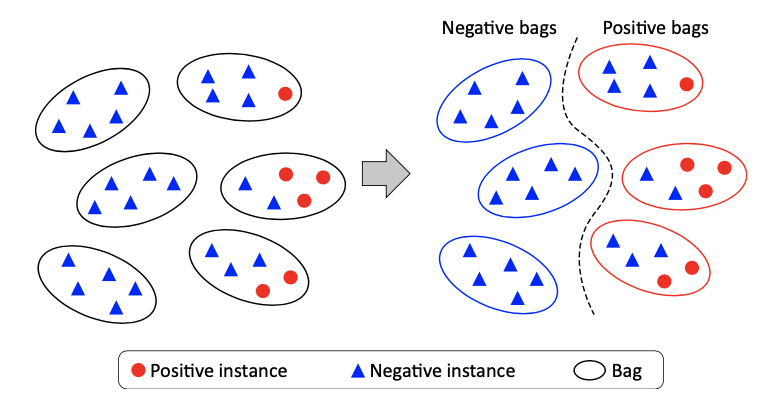
図3 MILの2値分類の例.[1]から引用
深層学習ベースのMILでは,Attention-based MIL [3] がよく使用されます.今回の研究でもこのAttention-based MILを使用しているため,図4を用いて構造を説明します.
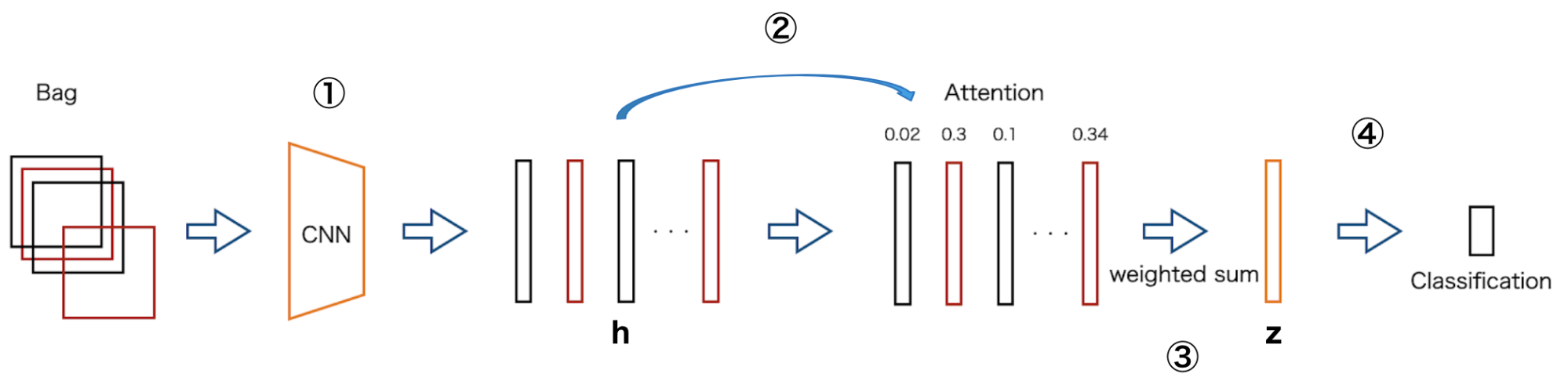
図4 Attention-based MILの概要図
- bagに含まれる各パッチをCNNに通して特徴ベクトルhに変換します.
- hを用いてどのパッチが分類に有用なのかを表すAttentionの重みa_kを以下の式で計算します.なお,wとVは学習するパラメータです.
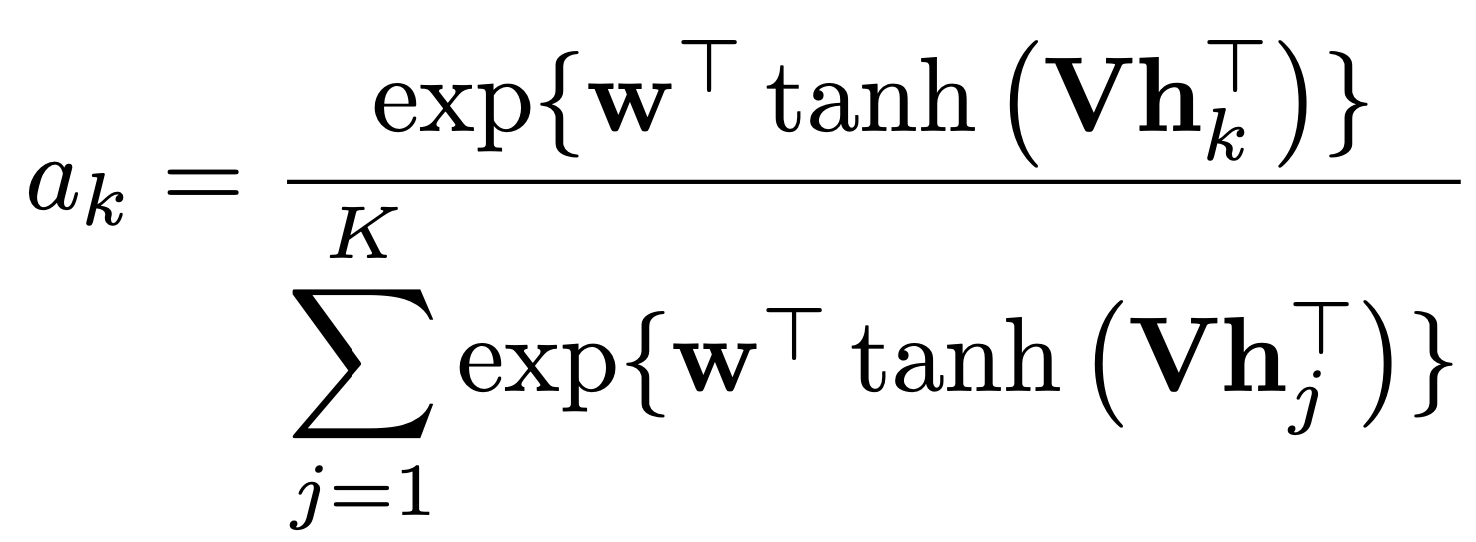
- 計算されたAttention値を用いて特徴ベクトルを集約し,特徴ベクトルzを作成します.
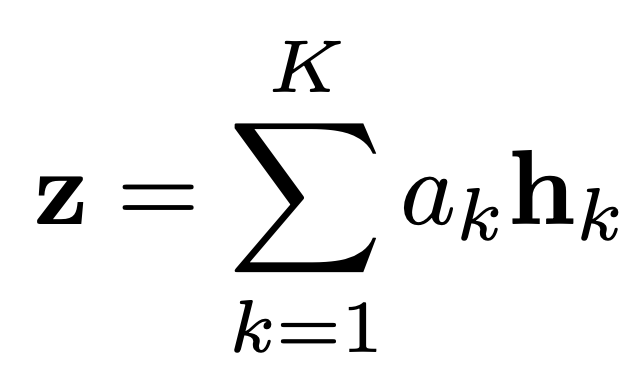
- zを用いてMLPなどで分類を行います.
学習する対象はCNNのパラメータ, AttentionのパラメータwとV,分類器のパラメータになります.
このAttention-based MILは解釈性に優れる利点があります.計算されたAttentionの重みはbag内での分類におけるインスタンスの重要度と考えられ,それを可視化することで,モデルがどこを重要視して結果を返したのかを確認することができます.(図5 参照)
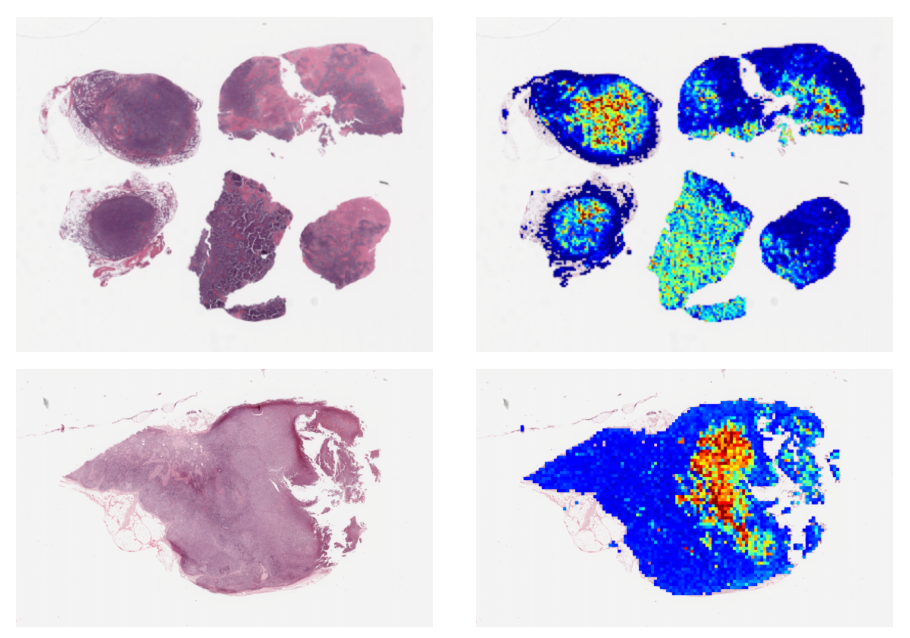
図5 Attention-based MILにおけるAttentionの可視化例.[1]から引用
右列の赤くなっている部分がAttentionの大きい部分
研究のモチベーションと提案手法
これまで見てきたようにMILは領域アノテーションを使用することができない問題設定でした.しかし,現実の問題への応用を考えた場合,領域アノテーションが一切手に入らない状況は考えにくく,少数の領域アノテーションが得られて,学習時に使用できる設定の方が自然であると考えられます.また,MILのAttentionの値が画像内の重要度とみなせるのであれば,その値をパッチの疑似ラベルとして使用できるのではないかと考えました.
そこで,このインターンではMILにPseudo Labelingを用いた半教師あり学習(Semi-supervised learning, SSL)の枠組みを取り入れたSSL-MILを提案しました.
図6に提案手法の概要図を示します.提案手法は大きく分けて,MIL phaseとSSL phaseに分かれており,それらを交互に行なっていきます.
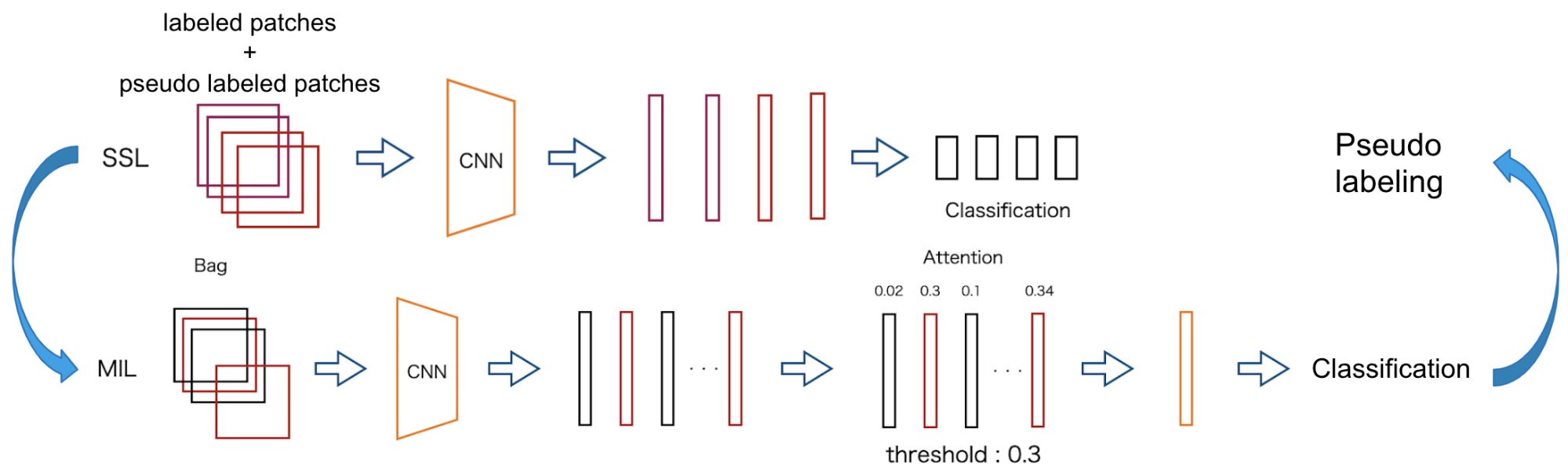
図6 SSL-MILの概要図
MIL phase
MIL phaseでは,領域アノテーションや疑似ラベルの情報は使用しない通常のAttention-based MIL学習を行います.今回はデータセットがMulti-labelであるため,これを拡張し,複数のAttenitonを持ったモデル(Multi-attention MIL, MA-MIL)にしています.(図7参照)
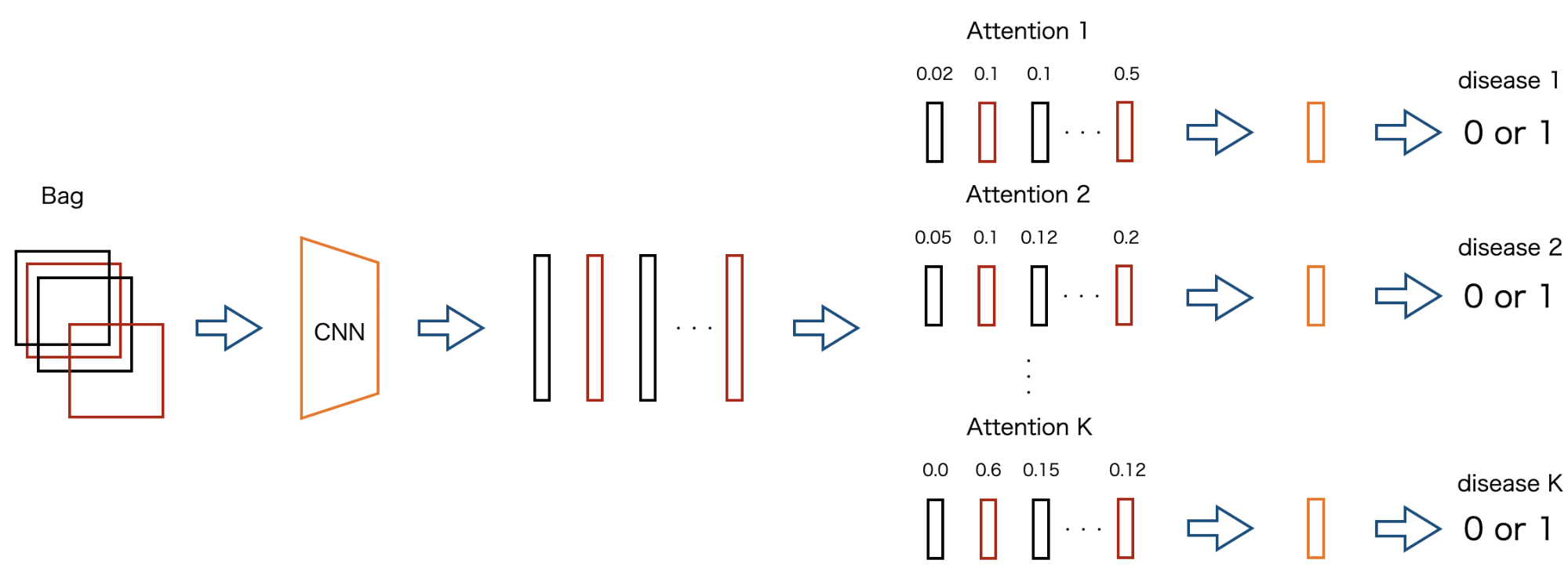
図7 MA-MILの例.
K種類の分類を行う際にK個のAttentionを用意し,各ラベルであるかを0/1で分類を行う.
SSL phase
SSL phaseでは,Pseudo labelingと学習を行います.Pseudo labelingは以下の2つの方法で付与します.
MILで分類に成功したbag
あるbagがラベルkに属しており,MILでその予測を正しく行えた場合,予測確率が閾値を超えたパッチに対して,ラベルkであるという疑似ラベルを付与します.(図8参照)
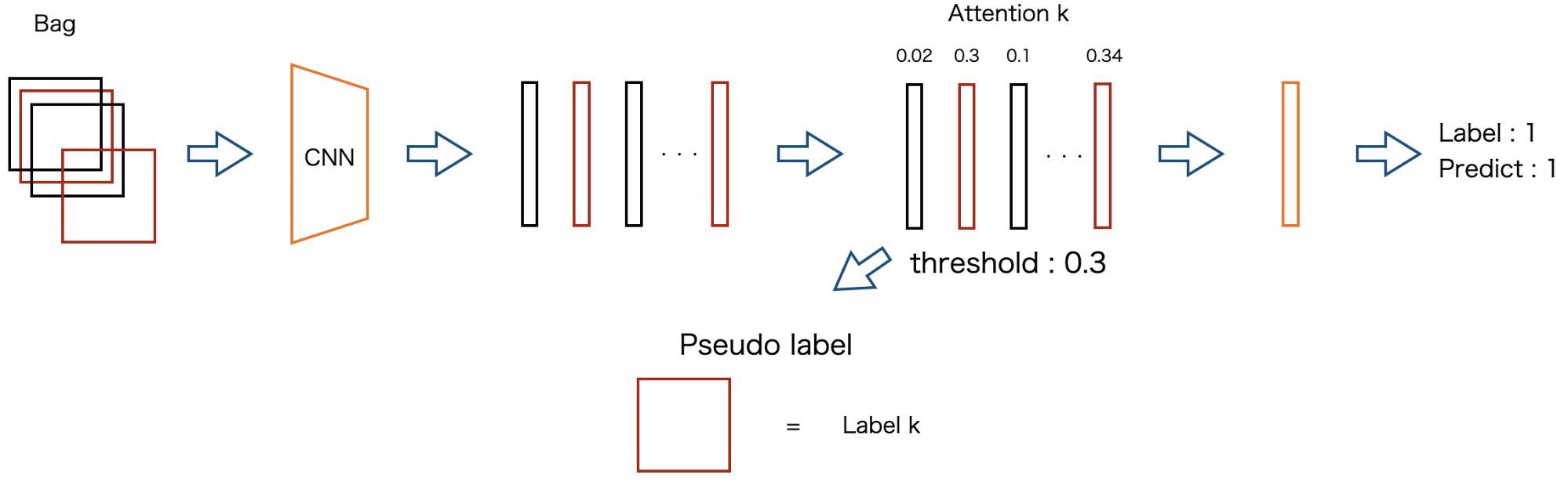
図8 MILで分類に成功したbagでのPseudo labeling
MILで分類に失敗したbag
あるbagがラベルkに属しているが,MILでその予測を間違えた場合,各パッチの特徴ベクトルを分類器に入力し,そのラベルkにおける予測確率が閾値を超えたパッチにラベルkであるという疑似ラベルを付与します.(図9参照)
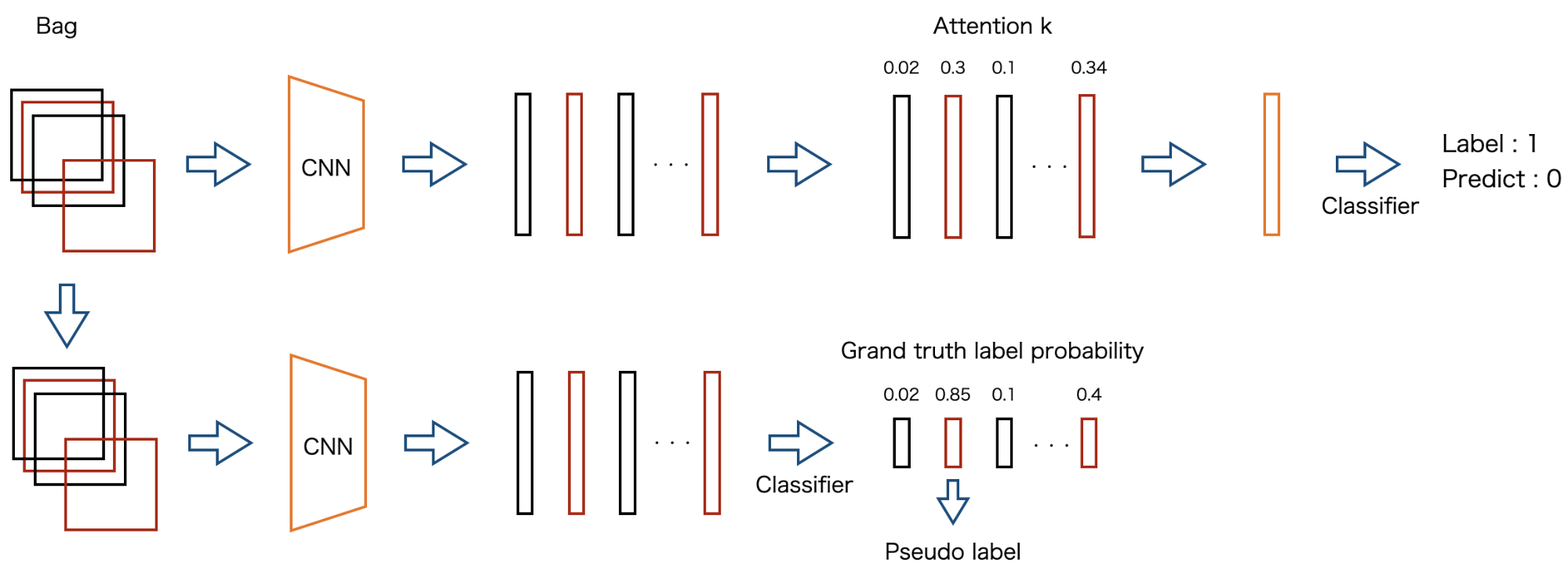
図9 MILで分類に失敗したbagでのPseudo labeling
Pseudo labelを付け終えたら,アノテーションがついているパッチと疑似ラベル付けされたパッチを用いてパッチレベルでの学習を行います.(図10参照)
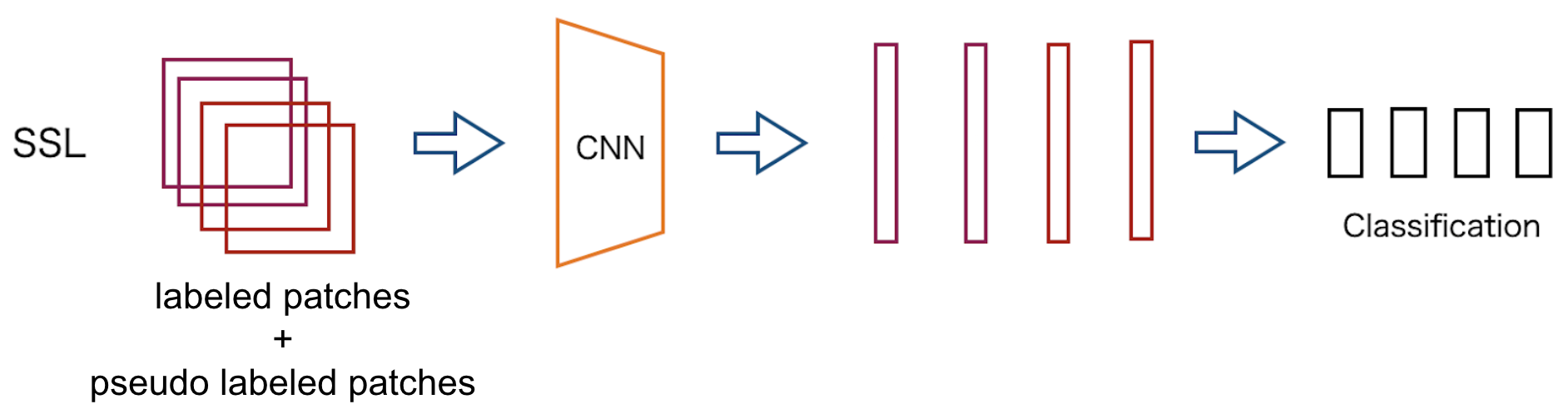
図10 SSL学習
実験
今回使用したデータセットはChestX-ray14 Dataset [3] です.このデータセットには胸部X線画像と,14種類の疾患有無のアノテーションが含まれており,各画像は複数の疾患に該当する可能性があるMulti-class問題になっています.全画像枚数は112,120枚で,その内880枚の画像には,追加で病変部位を示す矩形のアノテーションがついており,病変部位アノテーションが存在する疾患は8種類です.
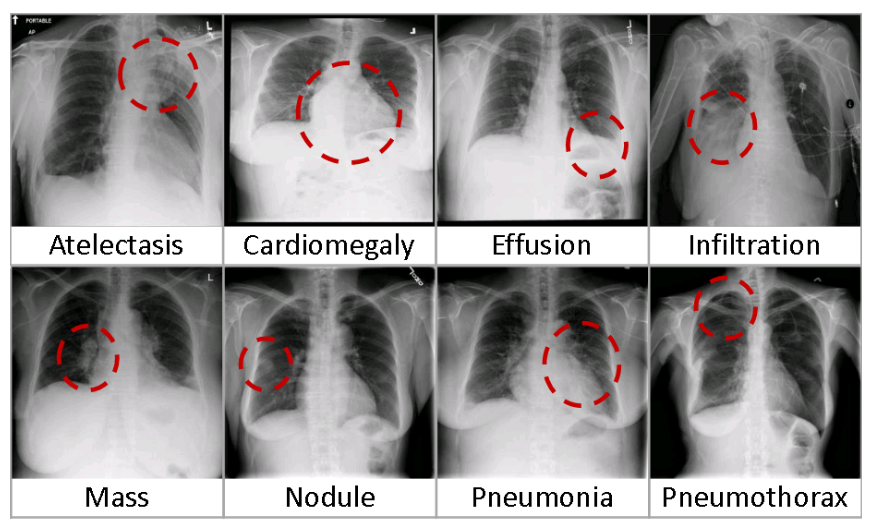
図11 ChestX-ray14 Datasetの例
実験ではCNN部分にImagenetで事前学習済みのResNet50を用います.ベースラインは通常のMA-MILとし,評価には各疾患毎のAUCを使用します.データはTrain : Validation : Test = 7 : 1 : 2で分割し,5-fold cross validationを行います.今回の画像は1,024 x 1,024ピクセルのため,256 x 256のパッチをstride=128で7×7の計49枚切り出し,1つのbagとしています.
結果と考察
表1にベースラインと提案手法の結果を示します.
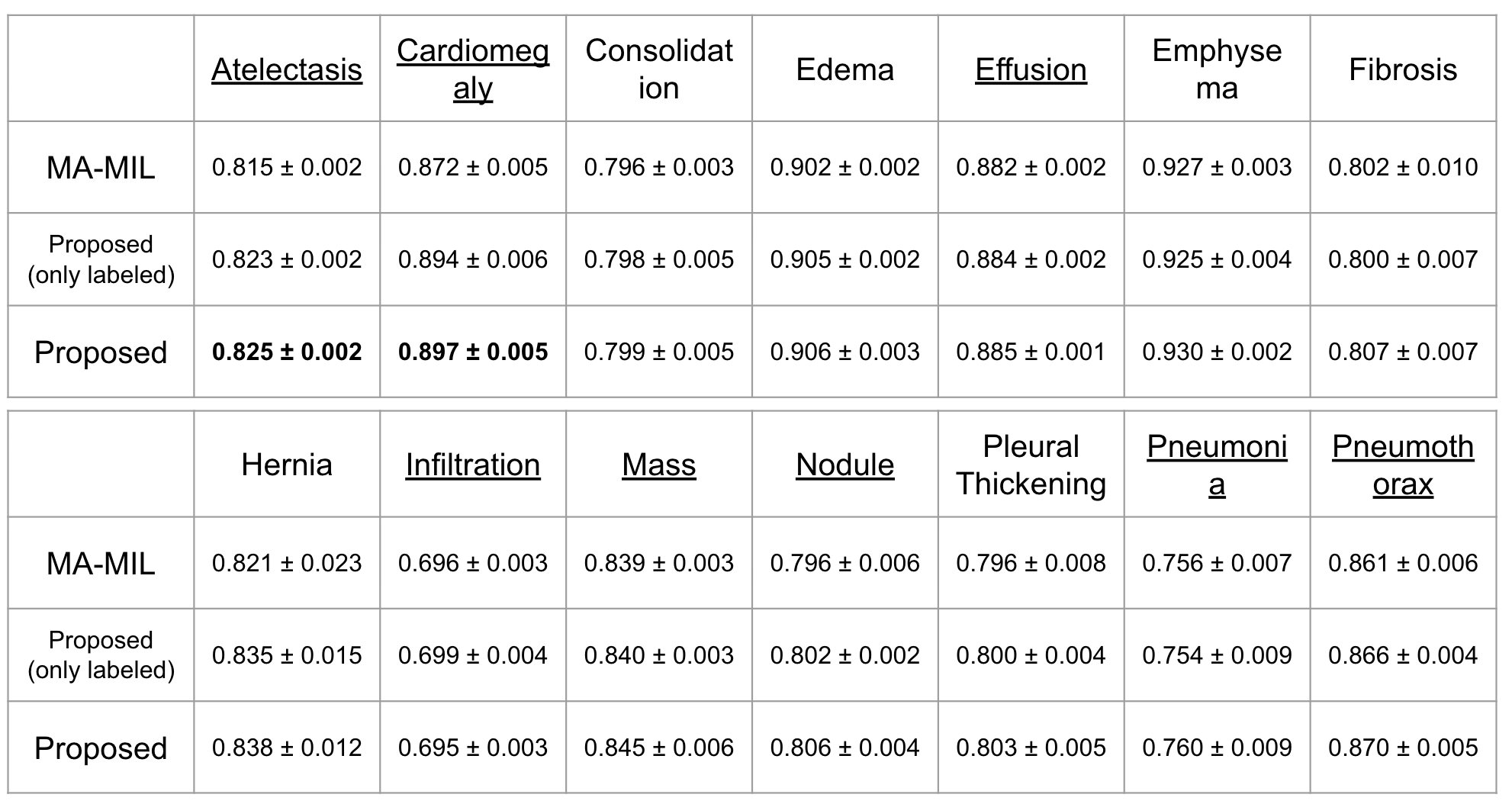
表1 AUCの結果.
※ Proposed (only labeled) は提案手法で疑似ラベル付けを行わずに
病変部位アノテーションがついたパッチのみでSSLを行なったもの.
下線は病変部位アノテーションがついた画像が存在している疾患を表しています.表1を見ると提案手法ではAtelectasis(無気肺)とCardiomegaly(心肥大)で精度が向上していることが見てとれます.AtelectasisとCardiomegalyは比較的病変部位の範囲が広く,アノテーション枚数が多めです.そのため,SSL-MILは疾患の一部分だけでなく病変部位アノテーション情報を用いて広い領域を見て学習することができていたのではないかと考えられます.(可視化の章でもこれを確認します.)
その他のほとんどの疾患では少しの精度向上でしたが,病変部位アノテーションが存在しない疾患でも精度が向上しています.逆に疑似ラベル付けを行わずに病変部位アノテーションがついたパッチのみでSSLを行なった場合では,EmphysemaやFibrosisで精度が低下しています.この結果から,疑似ラベルの効果が現れていると考えられます.
また,ほとんどの疾患で少しの精度向上しか見られなかった理由として,ChestX-ray14 Datasetのラベルにノイズが多いという点も考えられます.ノイズに対して疑似ラベル付けを行なってしまった場合は,学習の足を引っ張ることになってしまいます.
Attentionの可視化
次に学習して得られたモデルを使用してテストデータのAttentionの可視化を行います.初めに,MA-MILとSSL-MILのAttentionとAttention + Grad-CAM [4]の可視化結果を図12に示します.
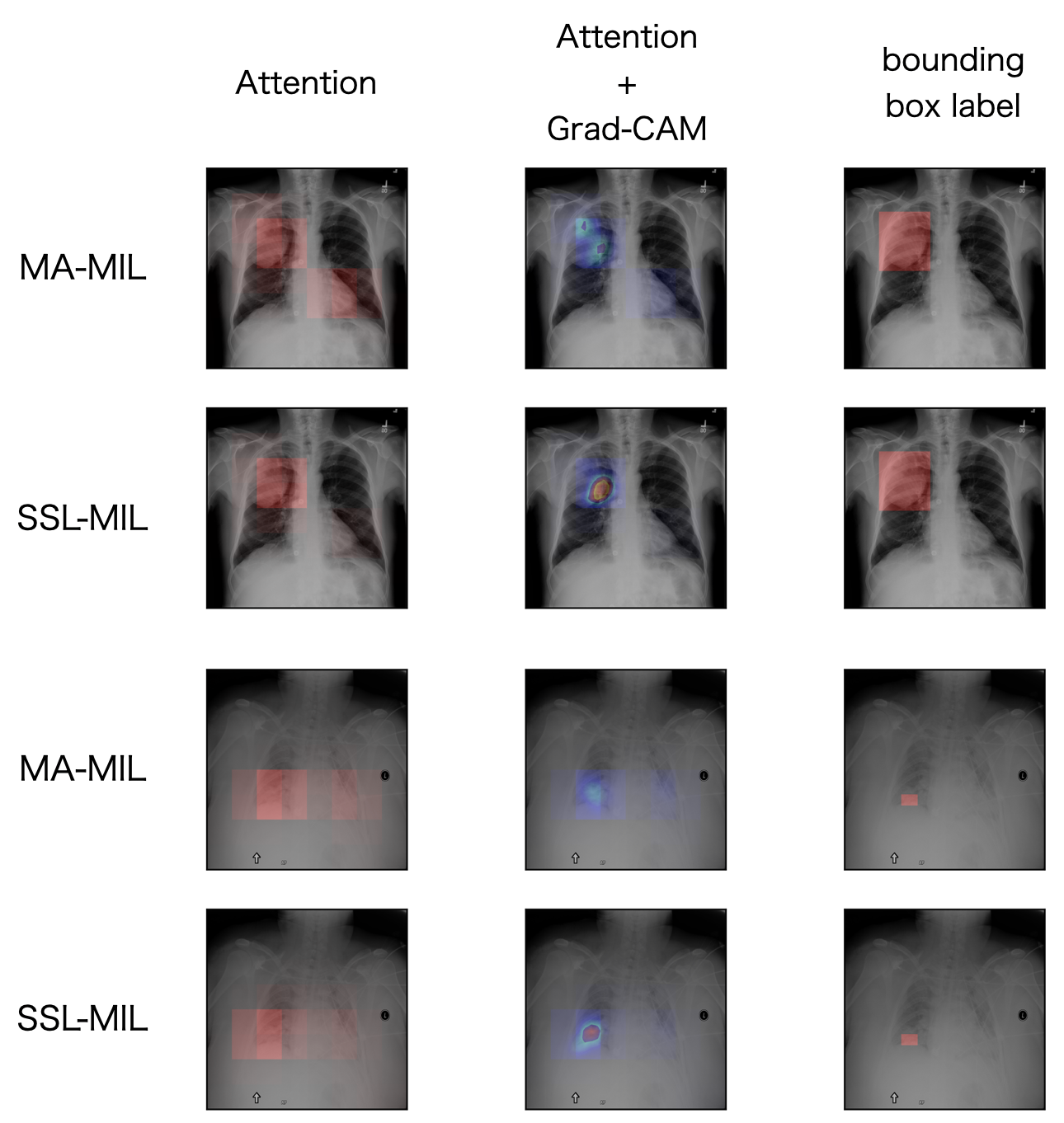
図12 MA-MILとSSL-MILの可視化結果.
最も右は正解のbounding box.提案手法はMA-MILに比べて病変部位をより注目している.
この2つの例はどちらも分類を正解していますが,提案手法はMA-MILに比べて病変部位をより注目していることがわかります.次に,MA-MILとSSL-MILのAttentionがepoch毎にどのように変化するか図13に示します.
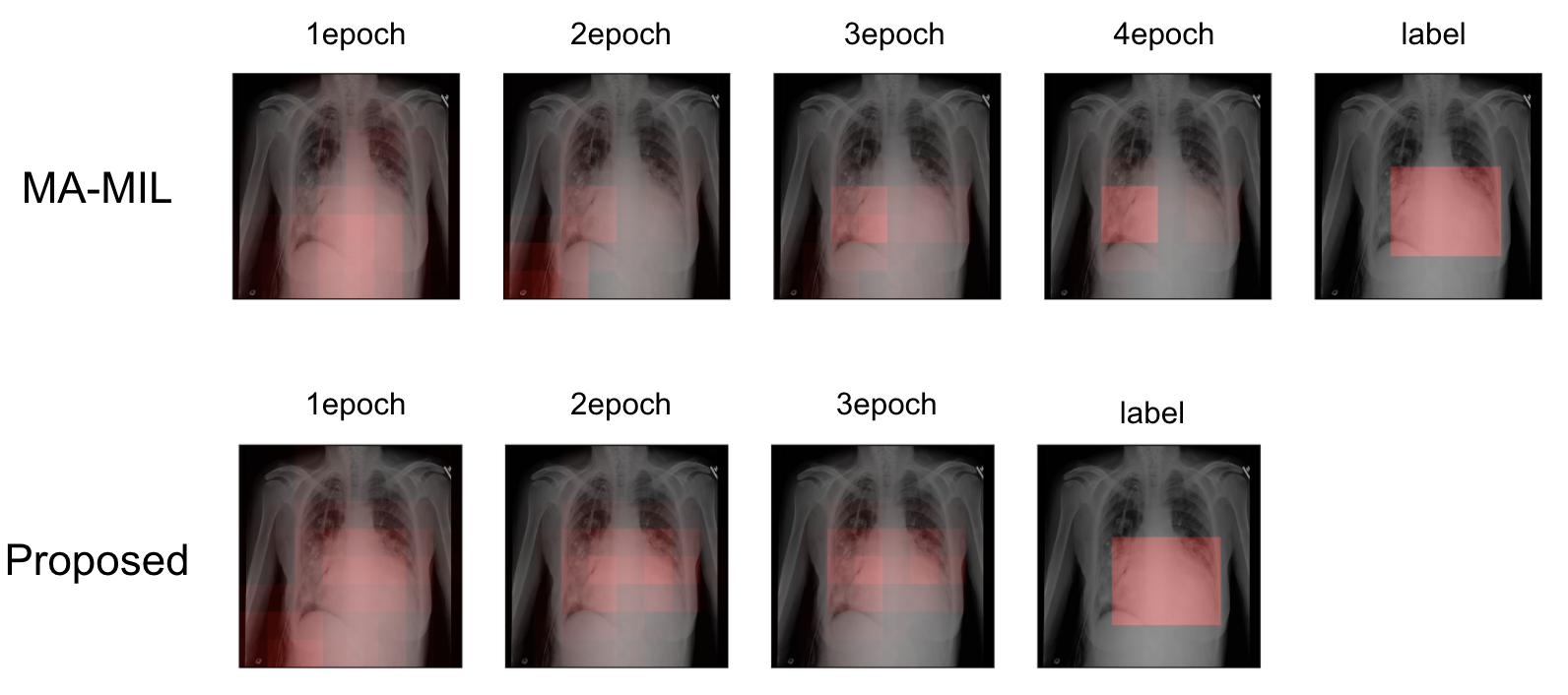
図13 MA-MILとSSL-MILのEpoch毎のAttention可視化例.
提案手法ではより広い領域に注目している.(MA-MILとSSL-MILでepoch数が
異なるのは各実験でvalidation lossが最小となるモデルを使用しているため.)
この例もMA-MIL, SSL-MIL共に正しく分類できていたものですが,SSL-MILの方がより病変部位の広い範囲を見ていることがわかります.そして比較的病変部位が大きい画像でこのような傾向が見られました.
まとめ
今回のインターンでは,少数の病変部位アノテーションが得られて,学習時に使用できる設定におけるMILの研究を行いました. そしていくつかの疾患でAUCの改善が見られ,既存手法よりも病変部位の広い範囲に注目できることをAttentionを可視化して確認しました.今後の課題として,病変部位アノテーションを用いてAttentionの重みを更新する方法や,Metric learningのアイデアを導入することなどがあります.
謝辞
最後に,約5週間という短い間,さらにオンラインでの開催という中で,社員の方のサポートのおかげで非常に充実したインターン生活を送ることできました.特にメンター,副メンターの菅原さん,平野さんには毎日のミーティングの中で色々な意見をいただき,多大なサポートをして頂きました.誠にありがとうございました.
参考文献
[1] Hashimoto et al. Multi-scale Domain-adversarial Multiple-instance CNN for Cancer Subtype Classification with Unannotated Histopathological Images. CVPR 2020
[2] Dietterich et al. Solving the multiple instance problem with axis-parallel rectangles. Artificial intelligence, 1997
[3] Wang et al. ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. CVPR 2017
[4] Selvaraju et al. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. CVPR 2017
