Blog
大規模言語モデル(以下、LLM)で扱えるトークン数(以下、コンテキスト長)が長ければ長いほど、LLMを利用できる場面は増えます。例えば、以下のような場面です:
- 本やマニュアルのようなページ数の多い文書
- RAG [Lewis+, 2020](複数のテキストをの入力として、質問応答などのタスクを解く)
- 往復数の多いチャット
多くのLLMでは、対応可能なコンテキスト長は、事前に決められていますが、仮に短いコンテキスト長を持つモデルであっても入力プロンプトを工夫することで、コンテキスト長より長いトークン系列を扱えます。例えば、小説に関する質問応答を考えます。この時、小説の本文と質問指示をLLMの入力のプロンプトにした場合、以下のような簡易な手法が考えられます
- モデルの対応するコンテキスト長未満までトークン系列を圧縮:要約や小説の重要そうな部分だけをプロンプトに含める
- Map-reduce:小説をコンテキスト長までの異なる部分文字列に分割し、その分割ごとに質問応答させ、その結果を集約する
しかし、いずれの手法でも本来入力したい本文よりも情報量が減るため、期待した出力が得られない場合があります。また、タスクによっては具体的な実装が異なるため、素直に長文をそのまま入力した方が汎用性があります。
Transformer [Vaswani+, 2017] をベースにしたDecoder-only LLMでは、位置情報のバイアスをトークンごとに付与します 。明示的に位置情報をトークンに与えるためには、Positional embedingsがよく使われます。特に過去数年ではRoPE [Su+, 2021] と呼ばれる手法が、例えばLLaMA 1 [Touvron+, 2023] やPLaMo [Preferred Elements, 2024]で採用されています。
多くのPositional embeddingsは、学習時にコンテキスト長の上限を決める必要があるため、学習後にLLMのコンテキスト長を延ばすのは非自明です。コンテキスト長を延ばすために、LLMの事前学習をやり直すことは計算リソースの点で現実的ではなく、事後学習でコンテキスト長を延ばす方が計算コストを抑えられます。加えてAttentionの計算は、短いコンテキスト長のほうが時間あたりのトークン処理効率が良いため、事前学習後にコンテキスト長を延ばすことが一般的で、例えば、Llama 3 [Llama Team, 2024] で採用されています。本ブログでは、事前学習済みのPLaMo-100B のコンテキスト長4096(以下4k)を事後学習で4倍の16384(以下16k)まで延ばした取り組みを紹介します。
前準備:RoPE
今回採用した手法を理解するために、PLaMo採用されているPositional embeddingsのRoPEを簡単に紹介します。RoPEは、AttentionのQueryとKeyに対する操作を行います。簡単のために長さ\(T\)のトークン系列に対する単一ヘッドの Scaled-dot product attention [Vaswani+, 2017] (以下、SDPA)を考えます:
\[ \mathrm{softmax} \left(\frac{\boldsymbol{Q}\boldsymbol{K}}{\sqrt{D}}^\top \right) \boldsymbol{V}, \]
ただし、\(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V} \in \mathbb{R}^{T \times D}\) は、それぞれQuery, Key, Valueの \(D\)次元の特徴量ベクトルを時系列順に並べた行列です。
RoPEは、重複しない2次元の部分空間ごとに位置ごとに異なる回転行列 \(\boldsymbol{R}(t, d; \mathtt{rope\_base})\)を\(\boldsymbol{Q}\)と\(\boldsymbol{K}\)にかけます。例えば、位置\(t \in [0, \ldots, T – 1]\)]における最初の2次元に対する回転行列 \( \boldsymbol{R}(t, d; \mathtt{rope\_base}) \) は、次のように定義されます:
\begin{pmatrix} \cos t \theta_d & -\sin t \theta_d \\ \sin t \theta_d & \cos t \theta_d \end{pmatrix}
ただし、\(\theta_d = \mathtt{rope\_base}^{-2 d/ D}, d=0\)で、\(\mathtt{rope\_base}\)はハイパーパラメータです。
定義からわかる特徴は以下の通りです:
- 位置を区別(位置 \(t\) ごと異なる回転行列)
- 部分空間ごとに異なる回転行列(\(t\)固定でも、\(d\)ごとに異なる回転行列)
- 回転行列なので、KeyとQuery のトークンのベクトルのノルムは不変
- 相対距離が近いほど似た回転が行われる
RoPEの論文は、ハイパーパラメータとして\(\mathtt{rope\_base}=\)10000が使われており、LLaMA 1やPLaMoもこの値が使われています。このような相対距離を重視するバイアスは、例えばチャットの往復数が増えた場合により近い過去の発言を考慮しやすいため自然な返答をしやすいなどの観点から有利です。
ABF RoPEによるコンテキスト長延長
Xiong+ [2024]の図4にならって、説明したRoPEのコンテキスト長を4kから16kに延ばした際のSDPAの計算における影響を考えます。単純な設定として、QueryとKeyは全要素1で\(D=\)128 のベクトルとします。位置における違い見るために、\(T=\)16384とし、\(t=\)0のQuery ベクトルと全位置のKeyに対してRoPEを適用してから内積(上記のSDPAのSoftmaxの引数部分)を計算し、その値を次の図1に示します:
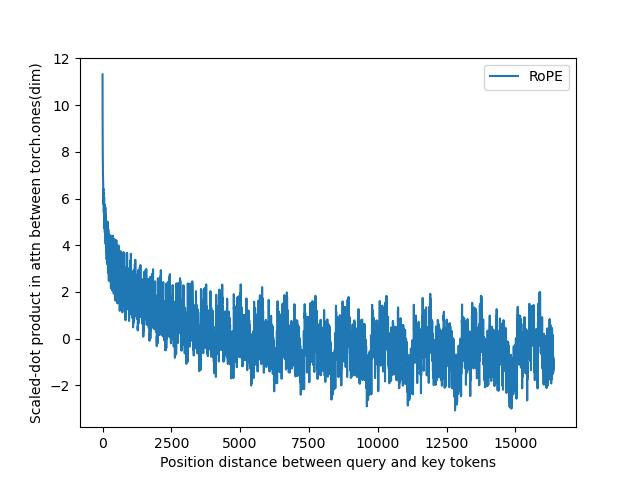
図1:\(\mathtt{rope\_base}=\)10000における位置\(t=\)0と\(T=\)16384までのベクトル間の内積の変化。
図1では、RoPEの特徴から近い距離(左側)は、遠い距離(右側)と比べて高い値になっていますが、距離が離れると内積の値は小さくなります。これにより、Attention の数値が小さくなりやすくなり、16kのようにコンテキスト長を延ばした際は長距離依存のような関係を捉えにくくなります。ちなみに長文テキストを入力にする場合は、そのテキストの後ろにLLMに対する指示をおいた方が性能が良いことが知られており [Anthropic]、RoPEの性質と一貫しているように個人的に思っています。
ABF RoPE [Xiong+, 2024] では、この問題を避けるために\(\mathtt{rope\_base}\)の値を既存の10000から500000に増やしています。これによりトークン間の距離が大きくなっても、内積は小さくなりにくくなります。ABF RoPEにおける数値結果を先ほどの図2に重ねたものを示します。
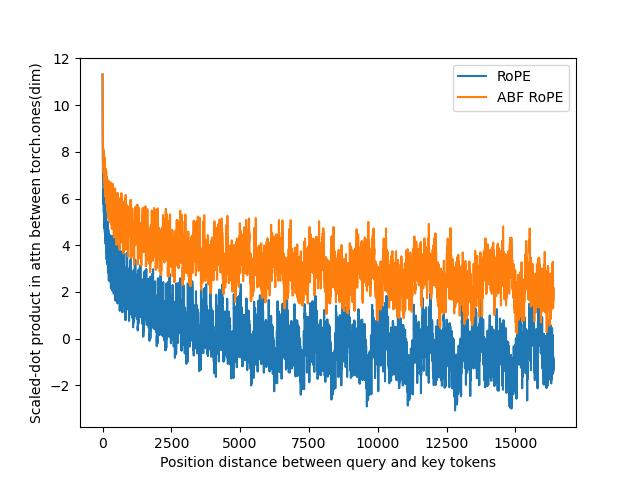
図2:\(\mathtt{rope\_base}=\)500000における位置\(t=\)0と\(T=\)16384までのベクトル間の内積の変化。青色は図1の\(\mathtt{rope\_base}=\)10000の結果。
元々のRoPE(オレンジ色)と比べるとABF RoPE(青)の方は、相対距離が大きくても内積の値が大きいです。
データセット
ABF RoPEでPLaMoのコンテキスト長を16kまで拡張したら、実際にその長さのテキストデータで事後学習します。しかし、長文のテキストデータを用意するのは困難で、ライセンス的に問題のない公開データセットは多くはありませんが、公開されている指示学習で利用できるデータセットとして、例えば、Narrative QA [Kočiský+, 2018]などが知られています。今回は、Packingを使うことで擬似的にコンテキスト長を延ばしました。Packingとは、GPUリソースを効率的に利用するために、複数の可変長のテキストを時間方向に結合し、おおよそコンテキスト長までにしてからミニバッチを作る方法で、PLaMoの事後学習で使われています。問題点として、本来異なるテキスト間でもSDPAが計算されるため、後続タスクにおける性能劣化が報告されています [Zhao+, 2024]。ちなみに、位置インデックスと適切なSDPA実装で回避できます [Lee+, 2024]が、今回はコンテキスト長の延長を優先し、使いませんでした。
Packingよりも自然な方法として、データ合成を用いてコンテキスト長の長いデータセットを構築できます。例えば、Llama 3.1 [Llama Team, 2024]では、Q&A・Summarisation・Code Reasoningといったタスクにおける学習データを機械的に構築しており、データ合成は広く使われるようになっています。今回は、翻訳用のデータセットを用いて、長い入出力のテキストデータを自社で構築しました。
具体的な生成方法を説明します。例えば、以下のような翻訳ペアが複数がある際、
英語A - 日本語A 英語B - 日本語B …
以下のようなバッチ処理を行うような1つのサンプルが合成可能です。
[入力プロンプト] 以降に書く文章全てを日本語に翻訳してください。日本語は直訳とし、返答に余計な語句は含めないでください。 英語A 英語B ... [出力] 日本語A 日本語B ...
このように合成すると、所望のコンテキスト長の入出力のデータセットを作成できます。
チャット形式を対応する場合、UniChunk [Zhao+, 2024] のように1つ翻訳ペアのサンプルを1往復のやり取りして並べることで同じように長いテキストが合成できます。
[入力プロンプト] 以降に書く文章全てを日本語に翻訳してください。日本語は直訳とし、返答に余計な語句は含めないでください。 英語A [出力] 日本語A [入力プロンプト] 英語B [出力] 日本語B ...
実験
PLaMoの事後学習におけるSupervised fine-tuning(以下、SFT)では2段階の学習を行っていますが、事前実験の結果、1段階目からコンテキスト長を16kに延ばした方が後続タスクの性能が高かったため、SFTでは、常にコンテキスト長を16kとしました。SFTと異なりDPO [Rafailov+, 2023]ではReference model が必要になるため、SFTよりもGPUリソースを必要とします。Lllama 3.1によるとDPOに関してはコンテキスト長は元の長さで良いことが報告されており、事前実験でも4kと3倍の12kで、大きく性能差がなかったため、コンテキスト長は4kにしました。
公平な実験ではありませんが、LongBench [Bai+, 2024] という長めのコンテキスト長に関するベンチマーク結果を報告します。LongBenchではライセンスが不明ないし非商標なデータセットが含まれているため、それらを除いた英語のデータセットで評価しました。また NarrativeQA [Kočiský+, 2018]は、非商用ライセンスのデータから生成されたサンプルが含まれるため、それらも除外した上で評価しました。ベータ版で使われていたコンテキスト4kのPLaMo βと今回リリースしたモデルのPLaMo Primeとで比較をしました。
| Dataset | PLaMo β | PLaMo Prime |
| narrativeqa | 18.96 | 29.48 |
| qasper | 31.35 | 38.65 |
| multifieldqa | 39.19 | 49.47 |
| hotpotqa | 43.07 | 57.98 |
| 2wikimqa | 37.30 | 51.41 |
| musique | 17.20 | 40.04 |
| qmsum | 21.36 | 23.13 |
| triviaqa | 87.27 | 88.43 |
| passage count | 4.50 | 5.00 |
| passage retrieval | 16.50 | 29.50 |
PLaMo Primeでは今回のいくつかのデータセットで大きく数値が改善しています。また、既存研究 [Lu+, 2024] と同様にqmsumとtriviaqaのデータセットでは、コンテキスト長4kと16kの間で大きな差は見られませんでした。
既存研究
今回紹介したようなLLMのコンテキスト長を事前学習後に延ばす既存の手法について簡単に紹介します。Lu+ [2024] が最近の手法について理解する際におすすめです。
Attentionを変えずに対応する手法の例が、今回採用したようなRoPEのパラメータを変更する方法です。今回採用した手法のようにFine-tuningをした方が後続タスクにおける性能が改善しますが、巨大なLLMの学習でコンテキスト長を延ばして事後学習するのは、計算機資源の面で困難があるため、学習せずにコンテキスト長を延ばす研究開発も盛んに行われています。比較的新しい手法の例として、LongRoPE [Ding+, 2024] があります。後述のAttentionの近似を用いる方法もですが、事後学習をせずにコンテキスト長を延ばす方法としても提案されています。
コンテキスト長を延ばす際に大きく問題となるのは、SDPAの計算であるため、Attentionを近似することで、必要なトークン数を減らしてコンテキスト長を延ばす手法もあります。例えば、Sliding window attentionを用いた手法 [Han+, 2024] があります。GPUメモリなど計算機資源の制約がある場合、このような手法は全トークン間のSDPAを計算しないため、必要なGPUメモリを削減できます。一方で、事前学習時とAttentionの計算方法の近似誤差が大きい場合と性能劣化は避けられず、事後学習をするなら今回のようなRoPEのパラメータを変えた方が性能が良いことが実験的に報告されています [Lu+, 2024]。
まとめ
最低限モデルの変更(ABF RoPE)と事後学習で、PLaMoのコンテキスト長を従来の4倍の16384にしたPFE Alignmentチームの取り組みについて紹介しました。
PLaMo Primeで追加された機能の概要は、 PLaMo Primeリリースにおける機能改善で紹介していますので、ぜひご覧下さい。