Blog

EnRoute by Ingrid V Taylar (CC BY-NC 2.0)
本投稿はPFN2022 夏季国内インターンシップに参加された江平智之さんによる寄稿です。
はじめに
PFN2022 夏季国内インターンシップに参加していた江平智之です。現在修士1年で、大学では分散システムやクラウド技術について研究しています。
今回のインターンシップでは、「JP04. Kubernetesにおけるコンテナ実行環境の改善」というテーマでコンテナ起動時間の高速化に取り組みました。
背景
PFNでは機械学習基盤としてKubernetesクラスタを使用しており、リサーチャやエンジニアはKubernetesクラスタ上のPod内で機械学習やシミュレーションなどの計算を行っています。スケジューラによってノードにアサインされた後にPod内にコンテナが起動されますが、ノード上にコンテナイメージのキャッシュがない場合にコンテナ起動が遅いという問題がありました。計算はPFNの研究開発における主要なプロセスの一つであるため、コンテナ起動が今よりも高速になることで、研究開発の効率化に良い影響を与えることが期待できます。
問題設定
コンテナ起動時間を計測する際の設定やPFN特有の環境について説明します。
CRI API
各ノード上でコンテナを管理するcontainerdでは、dockerコマンドやnerdctlコマンドから利用されるcontainerd APIと呼ばれるAPIのほかに、KubernetesとのインターフェースであるCRI APIが存在します。今回はKubernetesから利用される際の高速化について考えているため、特に記載のない限り、CRI APIを利用するcrictlコマンドやCRI APIのクライアントライブラリを使用したコードを用いて計測を行いました。
all-in-oneイメージ
計測のベースラインに使用するコンテナイメージとして、PFN内で汎用イメージとして用意されているall-in-oneというイメージを使用しました。このall-in-oneイメージは以下のような性質を持っています。
- PythonやPyTorch、CUDA、OpenMPIなどの機械学習に使用されるライブラリが網羅的に含まれている
- 60レイヤで構成される
- 配布時のサイズが約10GB、展開後のサイズが約25GB
イメージのキャッシュ機構
クラスタ内において、コンテナイメージは図1のようなキャッシュ機構を持っています。
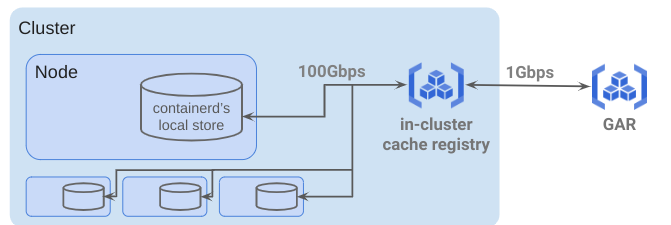
図1. イメージのキャッシュ機構
- GAR (Google Artifact Registry)
- クラスタ内イメージキャッシュレジストリ
- 各ノード上のcontainerdが持つローカルストア
コンテナイメージの保存にはGAR(Google Artifact Registry)が利用されていますが、高速なイメージ取得のためにクラスタ内にイメージのキャッシュレジストリが設置されています。なお、クラスタ内の計算ノードは分散学習などのために100GbEのNICが複数搭載されており、クラスタ内では高速な通信が可能です。
このような環境において、今回のテーマでは「ノードのcontainerdには対象イメージがキャッシュされておらず、クラスタ内キャッシュレジストリにイメージが存在する」という状況での高速化を目指しました。
ボトルネック調査
効率的に高速化を達成するためには、占める割合が大きい処理の時間を短縮することが重要です。そのための最初の段階として、インターン前半では、コンテナ起動のうち現在ボトルネックになっている箇所を特定する調査を行いました。
Podがノードにアサインされた後、コンテナ内では、Podの初期化処理、イメージのPull、コンテナ作成処理、コンテナ開始処理などが行われます。これらの処理を単純化してコンテナ起動に要する時間を計測したところ、図2のようにイメージのPullに時間を要していることが分かりました。

図2:コンテナ起動までの時間の内訳の例
次に、Pullの中でどのような処理が行われているのかを確認します。図3に示すように、イメージのPullの処理には大きくFetchとUnpackという処理が含まれています。Fetchではイメージの各レイヤをダウンロードする処理が行われ、Unpackでは各レイヤを解凍する処理と、レイヤを重ね合わせてコンテナにマウントできる形式(snapshot)に変換する処理が行われます。
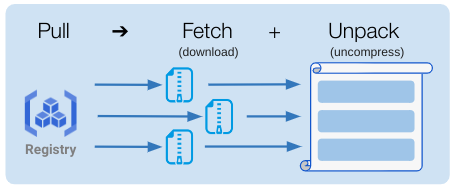
図3:PullにおけるFetchとUnpackの処理のイメージ図
ある計測において、FetchとUnpackそれぞれに要した時間は図4の通りです。この結果より、Pull全体の172秒のうちFetchは14秒ほどで終了しており、主にUnpackに時間を要していることが分かりました。
※本来Fetchと解凍処理は各レイヤで並列に処理されるためイメージ全体で考えるとFetchとUnpackは一部同時に実行されていますが、下図では全レイヤのFetchが終了した時点をFetchの終了としています。
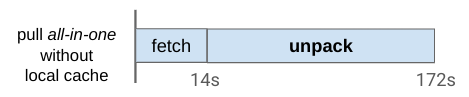
図4:PullにおけるFetchとUnpackの処理時間の例
ボトルネック調査のまとめ
- コンテナ起動のうち、イメージのPullに時間を要している
- Pullは大きくFetchとUnpackからなるが、Unpackに時間を要している
高速化のためのアプローチ
インターン後半では、高速化のためのアプローチとして以下の3つの方法に取り組みました。それぞれのアプローチの説明と取り組んだ結果について記します。
- Uncompressed, Squashedなイメージ
- Lazy Pulling
- P2Pネットワークを利用したイメージ配布
Uncompressed, Squashedなイメージを用いたアプローチ
Unpack処理に時間を要しているという点に注目し、各ノードでPullに要する時間が短くなるようにレジストリ内でのイメージの保持方法を工夫する手法について検討しました。
はじめに、Unpack処理のうち各レイヤの解凍処理の高速化を期待して検討したアプローチが、レジストリ内での各レイヤの保存形式をデフォルトのgzip形式から非圧縮形式に変更するUncompressedアプローチです(図5)。
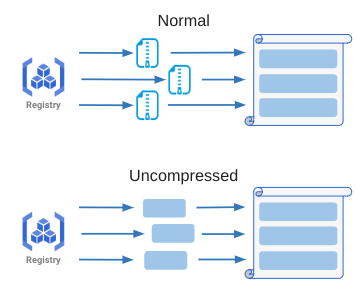
図5:Uncompressedアプローチのイメージ図
また、Unpack処理のうちレイヤを順に処理してsnapshotに変換する処理の高速化を期待して検討したアプローチが、全レイヤを統合して単一の巨大なレイヤにまとめてしまうSquashedアプローチです(図6)。
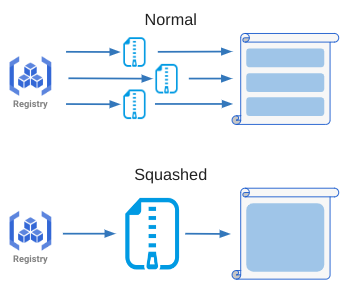
図6:Squashedアプローチのイメージ図
Uncompressed、 Squashedそれぞれの方法を組み合わせて計測を行った結果を図7に示します。
一番上のベースラインと比較してUncompressのみを適用した方法が30秒程度の高速化を達成しており、最も良い結果となりました。ダウンロードサイズが大きくなる分Fetchの時間は14秒 ⇒ 35秒と増加していますが、Unpackの時間短縮の効果のほうが大きく、全体では高速化が達成できています。一方、下2つに示されているように、Squashedを適用したイメージでは適用しない場合と比較してPullに要する時間が増加しています。これは、イメージが1レイヤにSquashされたことでレイヤ毎のFetchや解凍処理の並行性が失われたためだと考えられます。
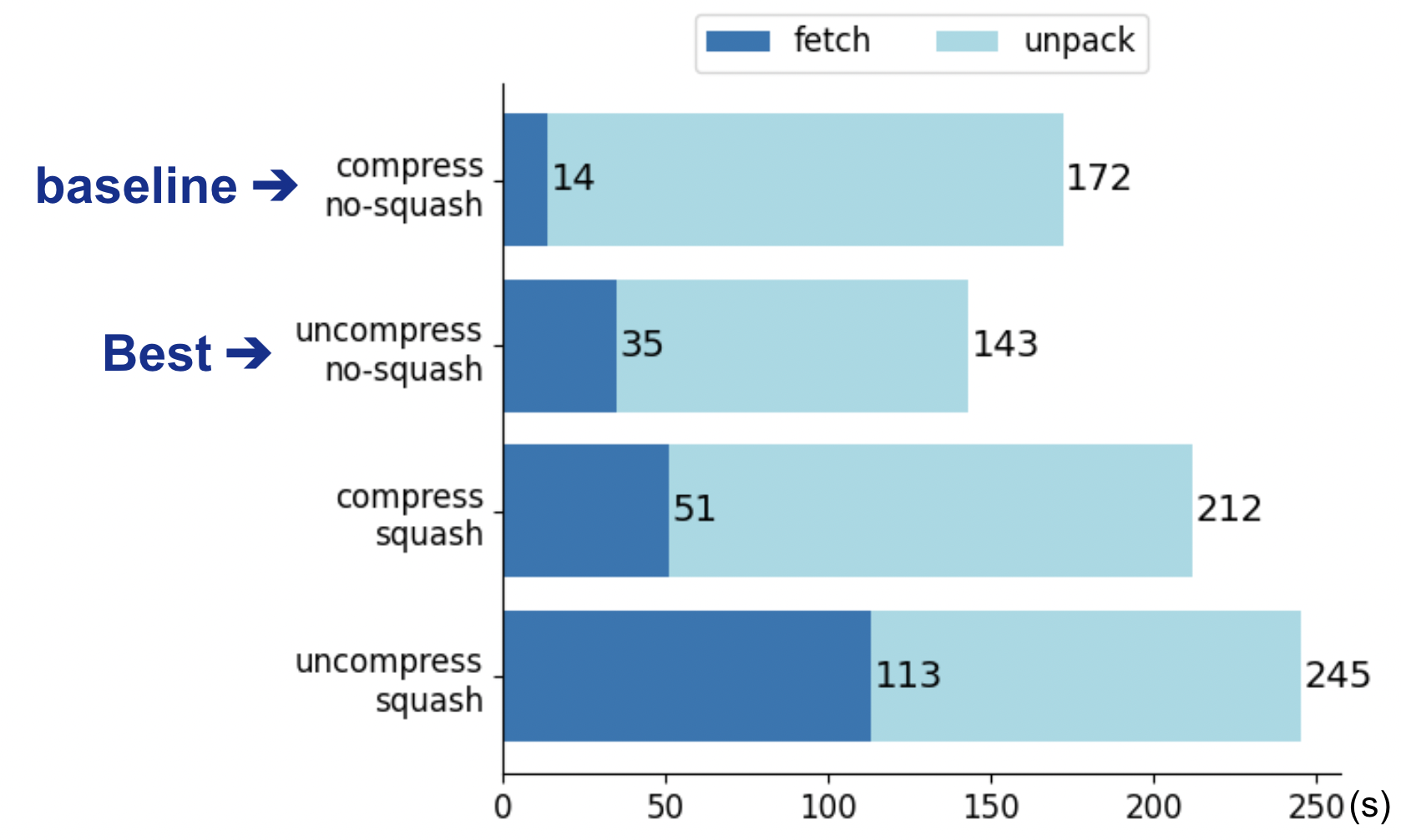
図7:Uncompressed, Squashedの計測結果
時間以外の観点も含めて、2つのアプローチの長所・短所についてまとめると以下のようになります。
Uncompressed
- 〇 各ノードで解凍処理に要する時間が減少
- ✕ レジストリで保持するイメージのサイズが増大
- ✕ クラスタ内、およびクラスタとGARとの通信の増加
Squashed
- ✕ Fetchに要する時間の増加
- ✕ Pull時やビルド時のレイヤごとのキャッシュが効かない
- ✕ ほとんど同じイメージでも全体を保持する必要があり非効率
Lazy Pullingによるアプローチ
次に、Lazy Pullingによるアプローチです。
イメージ中に含まれるファイルのうち実際に使用されるファイルは一部であり、また、コンテナ起動時に必要なファイルは限られています。all-in-oneイメージも汎用性を重視して作成されており、デバッグ用のライブラリなどの普段あまり利用されないコンテンツも多く含まれています。この特徴を利用して、最小限のファイルが揃った時点でコンテナを起動し、その他のファイルをオンデマンドで取得する手法がLazy Pullingです。
Lazy Pullingの実装としてStargz Snapshotterというconainerdのプラグインが存在して、このプラグインはeStargzというフォーマットに変換されたイメージのLazy Pullingが可能です。ここでeStargz形式のイメージとは、圧縮方法を工夫することで各レイヤのファイルが個別に取得できるようになっており、また、コンテナ起動前に準備される優先ファイルを指定することができるイメージです。
今回はこのプラグインを用いてLazy Pullingアプローチについて検討しました。
アプリケーションによってコンテナ起動時に必要とされるファイルは異なるため、Lazy Pullingの効果を最大限発揮するには各アプリケーションに合わせた最適化(どれを優先ファイルにするかの指定)が必要となります。今回はアプリケーション実行時にアクセスされるファイルを自動的に記録するctr-remoteコマンドの機能を用いて、PFNでのユースケースを考慮してMLの学習プログラムを最適化対象アプリケーションとしてoptimizedイメージを作成し検証しました。
Lazy Pullingでは必要最低限のファイルが揃った時点でコンテナを起動することができますが、コンテナ起動後にバックグラウンドでファイルが用意されるため、コンテナ上で動作するアプリケーション(機械学習の学習など)が通常と同じ時間で終了するとは限りません。そのため、Lazy Pullingについては、Pullに要する時間だけでなくコンテナ起動後に指定したコマンドが終了するまでの時間も併せて計測しました。いくつかのアプリケーション(run時に指定するコマンド)についてPullの時間とrunの時間(アプリケーション実行にかかる時間)を計測した結果の一部を表1に示します。なお、ここではイメージのPullと実行にnerdctlコマンドを利用しています。
| Application(command) | Image | pull time(sec) | run time(sec) |
| /bin/sh | all-in-one | 351 | 5 |
| /bin/sh | optimized | 6 | 3 |
| python3 -c ‘print(__name__)’ | all-in-one | 330 | 4 |
| python3 -c ‘print(__name__)’ | optimized | 3 | 2 |
all-in-oneイメージでは5,6分要するのに対してoptimizedイメージではPull自体は5秒程度で終了し、アプリケーションの時間を含めても10秒以内で終了するなど、単純な処理においてLazy Pullingの有効性が確認できました。一方で、獲得したシェルの中でコマンドを実行すると極端にレスポンスが遅いことがあったほか、優先ファイルに指定されていないファイルにアクセスする処理を実行すると数十分単位で処理が遅延するという状況も観測し、Lazy Pullingを効果的に扱う難しさも実感しました。
時間の都合上インターンシップ期間中には動作を理解しきることができず、Lazy Pullingの真価を発揮して計測することはできませんでしたが、使いこなすことができればコンテナ起動高速化を実現する上で有効な方法だと感じました。
P2Pネットワークを利用したイメージ配布のアプローチ
最後に、P2Pネットワークを利用したアプローチです。
現在、イメージのPullはクラスタ内のキャッシュレジストリを経由して行われています。しかし、イメージの多くはクラスタ内の他のノードでも使用されており、レジストリからだけでなく他のノードからもコンテンツを取ってこれるようにすることでより効率的なFetchが実現できると考えられます。このP2P的な考えをIPFS(InterPlanetary File System)というP2Pの実装を用いて実現するのがこのアプローチです。このイメージを図8に示します。
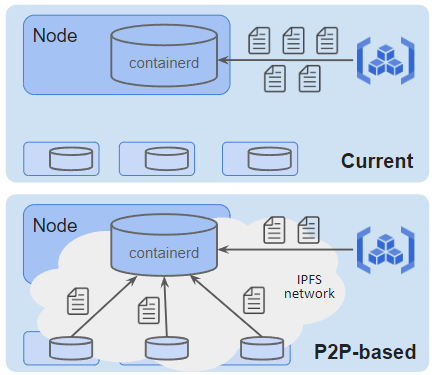
図8:IPFSを利用したイメージ配布
このIPFSを用いるアプローチもStargz Snapshotterの機能を用いることで実現する予定でした。各ノード上でIPFSデーモンを起動しクラスタ内でプライベートネットワークを構成することで、イメージやその各レイヤをIPFS上で共有することには成功しました。しかし、containerdやStargz Snapshotterとの組み込みに苦戦し、CRI経由の呼び出しではIPFSからイメージを取得していることをうまく確認できず、また、containerd API経由の呼び出しでは各レイヤのFetchの処理が並行して行われていることを確認できずうまく比較ができないと考えたため、IPFSを利用した手法の計測は中断しました。
また、今回試すことはできなかったのですが、GitpodでのIPFSを利用したイメージPull高速化のように、Stargz Snapshotterを用いずにIPFSからコンテンツを取得する方式も考えられます。PFNでIPFSを利用するとなった場合には、proxyやIPFSネットワーク内に存在するコンテンツを管理するデータベースを用いた図9のような構成が一例として考えられます。この構成におけるイメージの各レイヤの取得フローは次の通りです。
- 1. containerdからのレイヤ取得リクエストを各ノード上に配置したproxyが確認
- 2,3. 該当レイヤがIPFSネットワーク上に存在するかどうかをDBに対して問い合わせ
- 4. レイヤがIPFSネットワーク上に存在する場合、IPFSデーモンに対してレイヤ取得リクエスト
- 5. 周辺ノードからレイヤのコンテンツを取得
- 6,7. proxyを経由してcontainerdがレイヤを取得
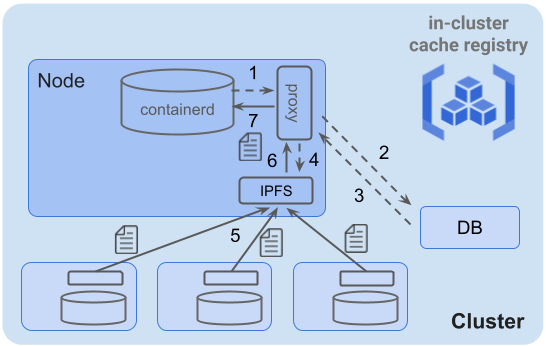
図9:IPFSを利用したイメージPullの実装例
インターンシップの感想・謝辞
改めて、今回のインターンシップでは「コンテナ起動時間の高速化」に取り組みました。目標が明確であるという点とうまくいけば運用中のクラスタに組み込むことができるという点からとてもやりがいのあるテーマでしたが、コンテナ技術について理解するのに時間を要したりIPFSの組み込みに手間取ったりと、最初に考えていた各アプローチについて検証し尽くすことができず、成果の面では少し悔いの残る結果となりました。
しかし、インターン生同士で交流したり社内の様々な文化に触れる機会があったりと、インターンシップ自体はとても充実した毎日を過ごすことができ、自分自身も様々な面で成長することができました。今回のインターンシップでの経験を活かして、今後の活動にも精力的に取り組んでいきたいと思います。
約1ヶ月半という短い期間ですが、社員の方々のサポートのおかげで非常に充実したインターンシップとなりました。特にメンターの大村さん、須田さん、薮内さん、そしてCluster Servicesチームの方々には大変お世話になりました。本当にありがとうございました!
Area