Blog
はじめに
Preferred Networks (以下PFN) 子会社のPreferred Elements (以下PFE) は、PLaMo 2シリーズの開発を進めており、その成果の一部としてPLaMo 2 1BおよびPLaMo 2 8Bの事前学習済みモデルを先日公開しました。モデルの詳細は以下の記事をご覧ください。
PLaMo 2の開発は、高品質データセットをどれだけ構築できるかが重要なポイントと考えています。実際、高品質データセットを使用したPLaMo 2 8Bは、8BというサイズでPLaMo-100Bに相当する性能をJMMLUやJHumanEvalで獲得しています。
事前学習チームでは、その源泉となった高品質データセット作成を支えるためにvLLMとAWS ECS (Elastic Container Service) を用いたLLM推論クラスタを運用しています。
本記事では、推論クラスタの構築や運用時のトラブルシューティング等を紹介します。
なお、PLaMo 2の開発は、経済産業省及び国立研究開発法人新エネルギー・産業技術総合開発機構 (NEDO) が実施する、国内の生成AIの開発力を強化するためのプロジェクト「GENIAC (Generative AI Accelerator Challenge)」の支援を受けて実施しています。
運用目標と要件
繰り返しですが、PLaMo 2は事前学習データセットの品質向上をポイントとしており、様々な実験を行っています。
LLMによる推論を使ったデータセットの前処理もその1つで、AWSは推論を使ったデータ生成をメインに活用することにしました。
しかしLLMを使った推論タスクを実施するとき、これまでは特定の推論タスク用に確保したローカルGPU上で行っていましたが、以下のような課題がありました。
- GPU処理能力に余裕があっても複数の推論タスクを同時並行で処理できない、もしくは複数の推論タスクをまとめて実行できるようにしないといけない
- モデルデータは数10-100 GiB規模になるためジョブの実行開始には時間がかかる
- モデルごとに最適なGPU数や設定が異なるため制御が必要
小規模データによる大量の推論タスクは、GPUの推論性能を引き出すために大規模バッチ処理化が必要です。
そのため大量の推論タスク (= リクエスト) を自動的にバッチ処理することが許容されるAPI方式は、GPUの推論性能を最大化するという観点でベストだと考えます。
また、高品質なデータセットの構築とそれを学習したモデルの評価に注力したいので、なるべく利用や保守コストを小さくしたいです。
推論クラスタの要件を以下にまとめます。
- OpenAI API compatibleである
- すでに広く利用されており学習コストが低い
- サーバーのデプロイが自動化されている
- ヘルスチェックにより自動的に再起動する仕組みがほしい
- 多様なモデルをデプロイできる
- GENIAC第1期で開発したPLaMo-100Bを含む、各推論タスクに最適化なモデルを活用したい
以上の要件を考えると、広く支持され開発も活発なvLLMは最適な選択と考えられます。
すでに社内実験での利用実績もあったため、今回はvLLMのOpenAI API compatible実装を用いた推論クラスタを構築しました。
今回の要件は、社内ユーザーだけで利用しRTT (Round-Trip Time) に制限がない状態とした場合です。
プロダクションレベルにおける要件は、Cloud Operator Days Tokyo 2024での弊社太田の発表スライドもご参照ください。
AWSを用いた推論クラスタの実装
GENIAC第2期ではAWSが計算プラットフォームとして提供され、H100を搭載したp5.48xlargeインスタンスが提供されています。
大量のGPUを用いるという特徴はありますが、vLLMを使った「ユーザーのリクエストを複数台のサーバーへ適切にロードバランスするWebサービスを構築・運用する」という、IaaS型クラウドでは一般的なユースケースです。
OpenAI API compatibleな推論APIの機能はすでにvLLMが実装しているので、スケーラブルな推論APIサービスとして運用するには以下の設計が必要になります。
- 複数台のvLLMサーバーを管理する
- リクエストの負荷分散を適切に行う
- AWSと社内ネットワークを安全に接続するための通信経路
以下に実装した推論クラスタの構成を示します。
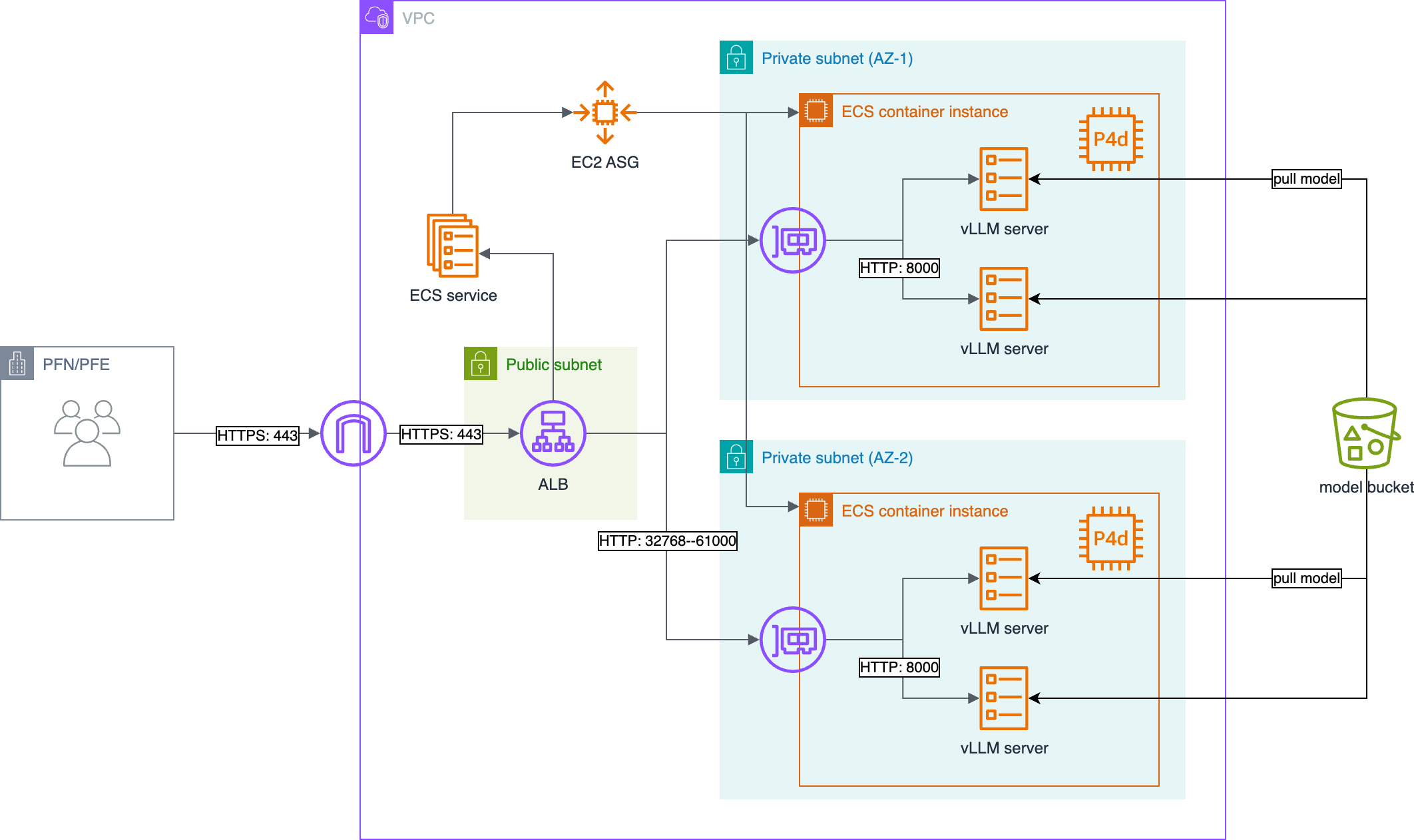
図1 OpenAI API compatibleな推論クラスタの構成
vLLMサーバーの管理にはAWS ECS (Elastic Container Service) を利用し、ECSサービスとして立ち上げてアプリケーション実行環境の一元化、ヘルスチェックやサーバー更新の自動化を行います。
推論タスクはリクエストごとに負荷が異なるので、HTTP/HTTPSリクエスト単位でサーバーへ振り分けることができるようにALB (Application Loader Balancer) を利用します。
主に弊社クラスタのネットワークから推論リクエストを送信しますが、ネットワーク設定上はインターネットを経由する必要があるため、リクエストはすべてHTTPS通信としています。 (ただし、機密データは推論クラスタへ投入しません)
vLLMサーバーとして実行するDocker imageはAWS ECR (Elastic Container Registry) に保存し、実行するモデルデータは、Amazon S3に用意したバケットに保存します。
これによってvLLMサーバーはAWS外部との通信が不要になり、かつPyPiやDocker Hub、HuggingFace Hubなどの外部リポジトリサービスに依存せず、AWS内で完結して運用できます。
一般的なユースケースであることから、各AWSのサービス (ECS、ALB、S3、ECR…) を使ったWebサービスとしての技術詳細は省略し、推論クラスタを運用したときのトラブルや改良について紹介します。
Large Model Inference container by Amazon SageMaker AI
上記を構築する代わりに、Amazon SageMaker AIで提供されているLMI (Large Model Inference) コンテナという選択肢もあります。
boto3を使ってLMIを使ったvLLMサーバーを起動し、OpenAI API compatibleなエンドポイントを容易に作成できますが、2024年10月初旬の時点で、LMIはvLLM v0.4.6をベースとしたイメージでした。
vLLMのリリース頻度が高いこともありますが当時の最新バージョンがv0.6.2で、この間に追加・バグ修正されたモデルを利用するにはSageMaker AIで動くカスタムイメージを作成する必要があります。
加えて検証に使用するモデルのいくつかは、vLLMの修正が必須でした。
私達はすでにECSの知見は持っていたため、ECSベースのほうが実現までの工数が少ないと判断しました。
ECSタスクへ割り当てるネットワークインターフェイス
使用するp5.48xlargeはインスタンスあたり8台のH100が接続されています。
推論タスクの場合、モデルサイズや量子化の有無等に依存しますが、100B相当の規模だと4 GPU (320 GiB memory) で実行することが可能です。
PLaMo-100Bを含め、多くのモデルはEC2インスタンスあたり複数のvLLMサーバーを起動可能ですが、vLLMサーバーを起動した各ECSタスクはALBからのトラフィックを受け取るために専用のネットワークインターフェイスを割り当てる必要があります。
ECSタスクのネットワークモードは複数種類あり、一番容易なのはawsvpcですが、p5.48xlargeはLinux + awsvpcモードでは複数のECSタスクを実行できない、と記載されています。
今回はawsvpcの代わりにbridgeネットワークモードを設定し、dynamic port mappingを使ってEC2インスタンスに複数のvLLMサーバーをデプロイ、ALBに登録しています。
起動したECSタスクがALBヘルスチェックで弾かれる
テスト環境はT4やV100といった1 GPUを使い、3Bなど小さいモデルで検証作業を行っていました。
しかし本番環境でPLaMo-100BのvLLMサーバーをデプロイすると、ECSタスクが初期化中に再起動を繰り返しvLLMサーバーが立ち上がらない状態になりました。
PLaMo-100BはBF16で持つと約200 GiBのデータになりますが、同一リージョン内とはいえS3からのダウンロードに時間がかかっていたため、ALBヘルスチェックのしきい値を超えており、通知を受けたECSサービスがタスクを再起動していたようです。
デフォルトパラメータでは、ECSタスクがALBに登録されてから1分以内にvLLMサーバーがrequest readyの状態にならないといけません。
極端に言うと、S3からダウンロードする速度が3.4 GiB/s以上で、かつGPUへモデルを転送するといった初期化コストがゼロである必要があります。NVMeストレージのREAD速度相当を要求しており、困難とわかります。
初期化に実行がかかる場合の対応として、Load balancerやコンテナなどで動いているすべてのヘルスチェックを無視しECSタスクがreadyになるまでの猶予期間を設けるhealthCheckGracePeriodSecondsパラメータがあります。
推論クラスタで利用したいモデルはPLaMo-100Bが最大規模と考えていたため、PLaMo-100BのvLLMサーバーが起動するまでに必要な時間を計測し、正常範囲と言える猶予期間を設定しました。
ただしこのパラメータを指定してもヘルスチェック自体は行っており、結果を無視するだけなので、この猶予期間までにhealthyな状態に移行しないとunhealthyとマークされてECSタスクが終了します。
vLLMがリクエストを処理しなくなることがある
私達が実装したPLaMo-100B用のvLLMモデルコードのバグか、vLLMのバグか未だ突き止められていませんが、vLLMサーバーが推論リクエストを一切処理しない状態に陥ることがあります。
vLLMサーバー自身はリクエストを認識しておりpending requestsとしていますが、vLLMが計測しているテキスト生成速度はゼロになり、 nvidia-smiのGPU利用率もゼロ、というデッドロックのような状況になります。
このとき/healthエンドポイントをリクエストしても、vLLMサーバーは通信できているので問題を検知できません。
vLLMサーバーは/metricsエンドポイントからPrometheusのメトリクスを取得可能で、いま処理されているリクエストや保留中リクエストの総数、推論速度などが取得できます。
そこで専用のスクリプトを作成してECSコンテナのヘルスチェックに設定し、pending requestsを持っているにもかかわらず生成速度がゼロになっている場合にunhealthyとするようにしました。
これにより、デッドロック状態でリクエストが処理できなくなったECSタスクは自動的に再起動できるようになりました。
検出できない内部エラー
一方、推論タスクによってはvLLMサーバーが不安定な状態になることがあり、それは解決できていません。
vLLMの推論処理はpythonのasyncioで動作していますが、一部のasyncioスレッドがリクエスト処理中の例外により異常状態になることがあります。
しかし、他のasyncioスレッドは正しく処理してリクエストに応答しているため、クライアントからは正常状態に見えています。
先に書いたヘルスチェックでは、このような一部だけ止まっている状態を検知できないので、さらなる対応が必要と考えています。
4ヶ月ほど運用してみて
GENIAC 2.0は2024年10月から開始し、今回実装した推論クラスタを約4ヶ月にわたり運用・活用しています。
保守コストが低い = 手離れよく推論クラスタを運用しデータ生成を行う、という目標を掲げていましたが、約4ヶ月のうち保守作業を行っていた時間は約10日ほどでした。
保守作業期間中はクラスタが利用できなかったとしてもサービス稼働率は90%を超えており、保守コストが低い状態で推論によるデータ生成を実現する、という目的は達成できたと考えています。
おわりに
今回実装した推論クラスタは先日公開したPLaMo 2 1Bおよび8Bの開発に利用され、先日公開した記事で紹介したようなデータセットのフィルタリングや言い換えに活用されています。
PFN/PFEでは、今後も事前学習・事後学習を問わず様々な技術を駆使して基盤モデルの開発を行っていきます。
本記事で紹介したような仕事に興味のある方はぜひ以下をご覧ください。



