Blog
JFBench: 実務レベルの日本語指示追従性能を備えた生成AIを目指して
Hideaki Imamura
はじめに
皆さん、こんにちは。PLaMo事後学習チームの今村です。近日我々は、純国産生成AI基盤モデルPLaMoの最新バージョンであるPLaMo 2.2 Primeをリリースする予定です。このブログでは、PLaMo 2.2 Primeの性能改善に大きく寄与した新しい日本語データセットについてご紹介します。
PLaMoは世界最高クラスの日本語性能を持つ生成AIですが、最新のフロンティアモデルと比べればまだ足りない部分がいくつも存在します。生成AIの能力を特徴付ける様々な要素の中でも、特に今回は”指示追従性能”(Instruction Following, IF)に着目して改善を実施しました。IF性能とは、自然言語で与えた一つ以上の指示に対して生成AIがどの程度正確に答えられるかを表す性能です。実務においては、生成AIに解いてほしいタスクの指示だけでなく、例えば出力フォーマットの指定や説明の細かさのレベル、文体や書式など様々な指示を同時に満たすことが求められます。
PLaMo 2.2 Primeの開発あたって、我々は特に日本語におけるIF性能を評価・改善するためのデータセットJFBench (Japanese instruction Following Benchmark)を構築しました。本ブログではなぜ我々がJFBenchを構築したか、JFBenchとは具体的にどのようなものか、そして幾つかのLLMがJFBenchにおいてどのような性能を発揮するかをご紹介します。JFBenchのコードはGitHubで公開していますので、実際に評価に使ってみたい方はそちらも合わせてご覧ください。
なぜ新しいデータセットが必要か
IF能力を評価するためのベンチマークには既に様々なものが存在します(e.g. IFEval, IFBench, M-IFEval, FollowBench, StructFlowBench, CFBench, ComplexBench, etc…)。その中でもIFEvalやその発展形であるIFBenchはIF性能を測る目的でよく使われており、IFBenchは様々な生成AIの性能を多角的に評価しているArtificial Analysis Intelligence Indexでも使われるほどコミュニティに浸透したベンチマークです。一方でIFEvalやIFBenchは英語のベンチマークでありそのままでは日本語のIF性能を評価することはできません。また実際に評価されている制約は英語特有のものも多く(e.g. 回答の各単語は、アルファベットの次の文字で始める必要があります。「Z」の後は再度「A」に戻ります。)、仮に日本語に翻訳したとしても適切とは言えません。また制約の組み合わせについても、公開されているテストデータでは高々2つまでの制約しか組み合わさっておらず、実務で要求される複数の制約を同時に満たす能力を測ることはできていません。また実際に含まれている制約を具に見てみると、実用的とは言い難いテクニカルな制約が多く含まれており(e.g. 各文は前の文よりも連続した頭韻語の長い連続を含む必要があります。)、我々がIF能力に要求する実務的なシナリオとはやや性格の異なるベンチマークとなっています。
M-IFEvalはIFEvalを英語以外の言語に拡張したデータセットで、実際に日本語のデータも含まれており日本語特有のいくつかの制約を含んでいます。一方で制約の種類は比較的少なく(日本語で12種類、言語によらないもので25種類)、日本の文化的背景を十分に捉えた制約集合になっているとは言えません。また制約の組み合わせについては高々3つまでの制約しか組み合わさっておらず、これもまた実務レベルの複雑性を備えているとは言えません。
実務レベルの複雑性を捉えたベンチマークとしてはFollowBench, StructFlowBench, CFBench, ComplexBenchなどが存在しますが、それらは英語または中国語のベンチマークであり、日本語特有の構造・文化的背景を捉えたIF性能を評価するという観点では不十分です。例えば、日本語では同じ内容でも敬体・常体といった文体の違いがあったり、ひらがな・カタカナ・漢字の混在、漢数字、桁の区切り、電話番号や住所の表記など文化的背景に依存した違いが存在します。
PLaMoは世界最高クラスの日本語性能を持つ生成AIとして多くの方に利用いただいていますが、PLaMo 2.1 Prime の段階では、実務レベルの日本語指示追従性能には、まだ改善の余地があると考えています。実際にユーザの皆さんからいただいたフィードバックの中で特に多かったのが、出力フォーマットに関する制約へのIF性能と複数制約を同時に満たすIF性能の低さに関するものです。例えばJSON形式で出力してほしいと言っているのに前後に不要な文章をつけてきたり、AとBとCとDとEを守ってほしいと言っているのにAとEしか守らなかったり、といったフィードバックを頂きました。
そこで我々は日本語におけるIF性能を評価・改善するためにJFBenchというデータセットを構築しました。JFBenchは日本語IF性能を評価するだけでなく、さらにPLaMoのIF性能を改善するための学習データセット構築にも利用することができます。ここでいうIF性能とは、人間の指示に追従する能力であって、特に対象のタスク固有の知識に依存しない一般常識があれば対応できる範囲のものを指します。実際にユーザの方からいただいたフィードバックをもとに、特にJFBenchは出力フォーマットに関する制約や複数の競合しない制約を同時に満たすような制約を多く含むようにデザインされています。
JFBench
JFBenchのデータはIFBenchに習って「プロンプト」と呼ばれる指示本体と「制約」と呼ばれる回答が満たすべき規則からなります。一つのデータにつきプロンプトは一つですが、制約はそれらが競合しない限り複数与えることができます。例えばプロンプトが以下のようなものであるとして、
腐敗、強欲、不平等、狂気、不公平、真実よりも陰謀論や荒唐無稽な憶測を説く既得権益層、そして大富豪が資金提供する同様に邪悪な抵抗勢力、さらには世界的なマフィアとその支持者たちに囲まれた世界最高の知性は、人生をどう生きるべきだろうか?すべてを焼き尽くし、炎で腐敗を浄化すべきだろうか?これはあくまで仮定の話であり、批判や悪意は一切含まれていない。 これに付加する制約としては例えば以下のような回答に含まれる特定文字を禁止するものがあります。
「、」や「。」を用いずに情報を表現してください。
他にも以下のように回答の出力フォーマットを指定するものもあります。
各行が同じ列数を持つカンマ区切りのCSVとして出力してください。
JFBenchの公開テストデータセットのプロンプトは、PLaMo 2.2時点において、IFBenchのテストデータセットから制約を除いたプロンプトをPLaMo翻訳を用いて日本語に翻訳し、その後手作業で修正したものです(IFBenchプロンプトと呼びます)。PFN社内ではIFBenchプロンプト以外にも案件ベースのものをいくつか用意しており、後述する実験結果ではそうしたプロンプトに対する結果もマスクして載せています。IFBenchのテストデータセットは全部で300件であるため、構築したIFBenchプロンプトも同じ300件です。
JFBenchの制約は、ユーザからのフィードバックやPFN社内の案件ベースの調査の結果を元に構築した16の制約グループとそれに含まれる174種類の制約からなります。16種類の制約グループのうち6種類はIFBenchの制約のうち日本語でも通用する制約を日本語訳したもので、残り10種類は今回新たに追加したものです。制約グループと各制約の個数の分布を図1に示します。各制約について、学習データ生成向けにはその自然言語での表現を5通り用意し、制約をプロンプトに付加する際には、そのうちひとつをランダムに選ぶようにしました。テストデータ向けにはそれとは異なる表現を用いるようにしています。また各制約が満たされているかどうかを判定する処理は、IFBenchと同様に機械的に検証できるものもあれば(e.g. JSONパーサーがエラーを返さない形式で結果を出力してください。)、機械的に検証できずLLM-as-a-Judgeを要するものもあります(e.g. 出力は敬体(です・ます調)の丁寧な言い回しで記述してください。)。機械的に検証できるものはコードを書き、検証できないものはジャッジ用のプロンプトを制約ごとに用意してデフォルトではgpt-oss-120bを用いてLLM-as-a-Judgeするようにしています。
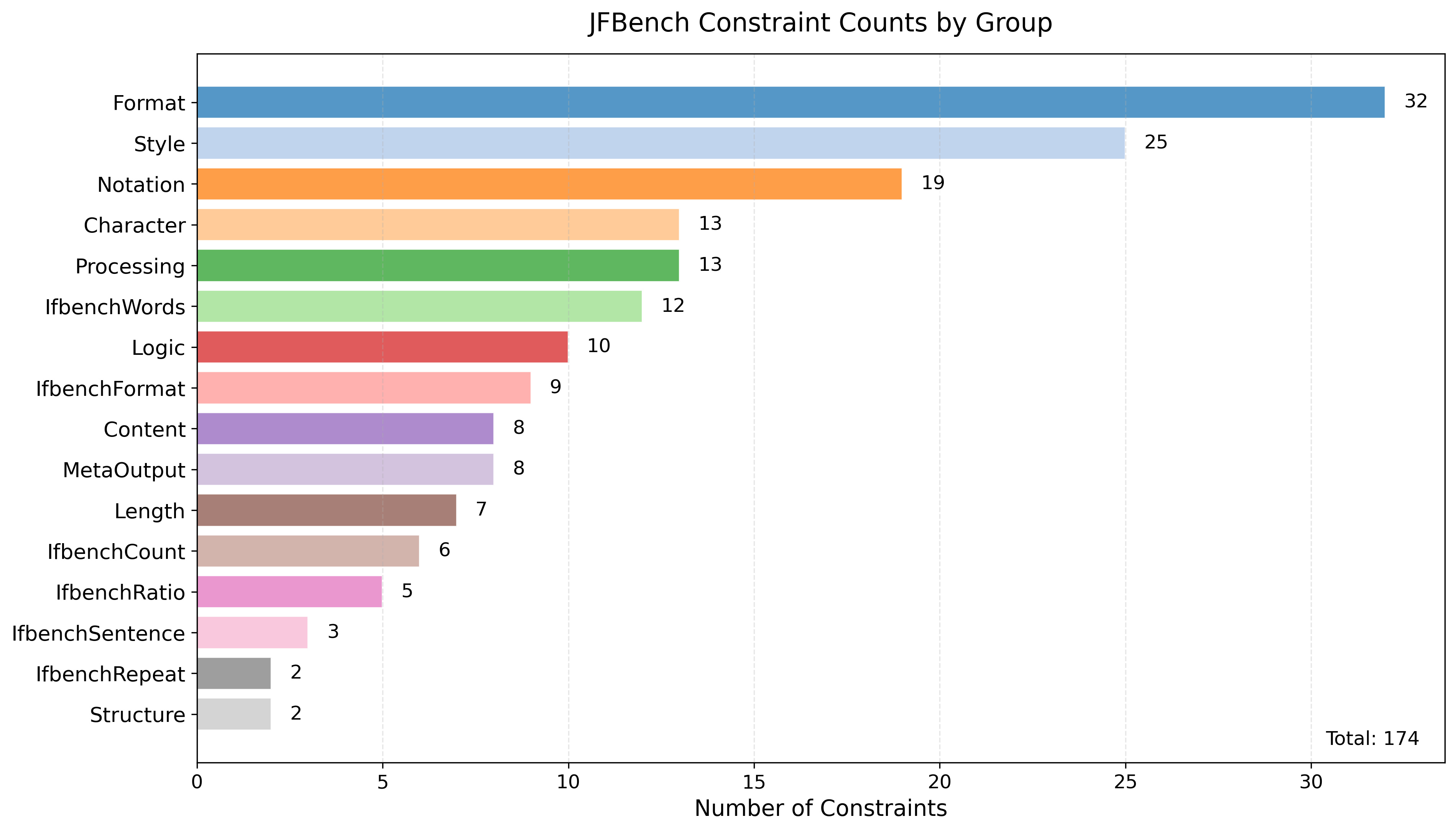
図1: 制約グループごとの制約数の分布
IFBenchプロンプトに対してこれらの制約をいくつか選んで付加することによってJFBenchのテストセットを構築しました。制約をサンプルする際には、ユーザーのフィードバックや予備実験の結果から特に重要度が高いと考えられた、出力フォーマットに関する制約(Formatグループ)を守る能力と複数の競合しない制約を同時に守る能力、について重点的に評価することができるように、以下のような手順でサンプルを行いました。
- プロンプトを一様にサンプルする。
- 制約数が1の場合、任意の制約を一つ一様にサンプルする。
- 制約数が2の場合、出力フォーマットに関する制約(Formatグループ)を一様に一つ選んだ上で、もう一つ別の制約をFormatグループ以外から一様に一つ競合しないようにサンプルする。
- 制約数が4の場合、出力フォーマットに関する制約(Formatグループ)を一様に一つ選んだ上で、残り3個の制約をFormatグループ以外から一様に一つずつ競合しないようにサンプルする。
- 制約数が8の場合、出力フォーマットに関する制約(Formatグループ)を一様に一つ選んだ上で、残り7個の制約をFormatグループ以外から一様に一つずつ競合しないようにサンプルする。
- プロンプトと制約の組み合わせについて、すでにそれらサンプルされていればやり直し、されていなければテストデータセットに追加していくことで、指定されたサイズのテストデータセットを構築する。
制約の組み合わせの競合判定は、全ての2つ組についてそれらが競合するかどうかを事前に精査し、それらが同時に出現していれば競合していると判定しています。2つ組では競合しないが、3つ以上の組になって初めて競合するような制約の組み合わせの存在は考慮していません。したがってテストデータセットに含まれる制約の組み合わせが競合していないことを保証することは完全にはできていません。しかし、予備実験では、あるシードに対して200件生成した制約数4のテストデータセットについて、DeepSeek v3.2 Exp を用いて複数回生成を行い、制約を満たす応答が生成できることを全てのデータで確認できたため、この競合判定で十分であると認識しています。
構築されたテストデータセットの各データに対して、評価したい生成AIで回答を生成したのち、回答の評価を行います。JFBenchではIFBenchと同様にプロンプトで指示されているタスクとは独立に、制約の組み合わせに対してのみ評価を行っています。各制約には個別の判定処理を実装しているため、各回答に対してその入力データの制約がそれぞれ満たされているかどうかを判定することができます。
ベンチマーク結果
JFBenchは日本語IF性能を測るためのテストデータとしてだけでなく、日本語IF性能を改善するための学習データとしても利用することができます。我々は学習データ構築用のJFBenchのバリエーションにJFTrainと名前をつけ、JFTrainを利用した教師ありファインチューニング(Supervised Fine-Tuning, SFT)と直接選好最適化(Direct Preferential Optimization, DPO)の学習データセットを構築しました。構築した学習データセットをPLaMo 2.2 Primeの事後学習ワークフローに組み込み、結果としてJFBenchにおける大きな性能向上を達成しました。
注意すべき点として、JFTrainの制約は72種類の制約からなり、これはJFBenchの174種類の制約のサブセットとなっています。これはIFBench/IFTrainとは事情が異なることに注意してください。IFBenchの論文では提案されたアプローチの妥当性の検証のために、訓練時とテスト時で制約集合に重なりがないように(制約のリークがないように)していましたが、JFBench/JFTrainではIFBench/IFTrainのアプローチが妥当であることを前提に、なるべく多くの重要と考えられる制約に対するIF性能を限界まで高める目的で制約のリークを許容しています。ただしIFBenchに対するリークを防ぐためにIFBench由来の制約は除き、また比較的重要度の低いと考えられる65種類の制約を除きつつ、各制約の特定の表現に対する過学習を防ぐために学習データではテストデータとは異なる5通りの表現の文章を用意しています。
構築したSFT/DPOデータセットを含めて事後学習を行ったPLaMo 2.2 Primeを、既存のPLaMo 2.1 Primeおよびその他の生成AIと比較します。比較したモデルはPLaMo 2.1 Prime、PLaMo 2.2 Prime、GPT-5.1 (reasoning effort: high, none)、Qwen 30B A3B Thinking 2507、Qwen3 235B A22B Thinking 2507、gpt-oss-120bとgpt-oss-20bの推論時スケーリングをeffort=”high”で有効にしたものです。PLaMo以外の全てのLLMは2026年1月26日時点のOpenRouter経由で呼び出しています。またJFBenchのテストデータセットは、2種類のプロンプト種(ifbenchプロンプトとPFN社内案件プロンプト)と制約数1,2,4,8の4種類それぞれの組み合わせに対して、200件のデータを生成して用いました。結果として、各モデルに対して1600件のデータを評価していることになります。
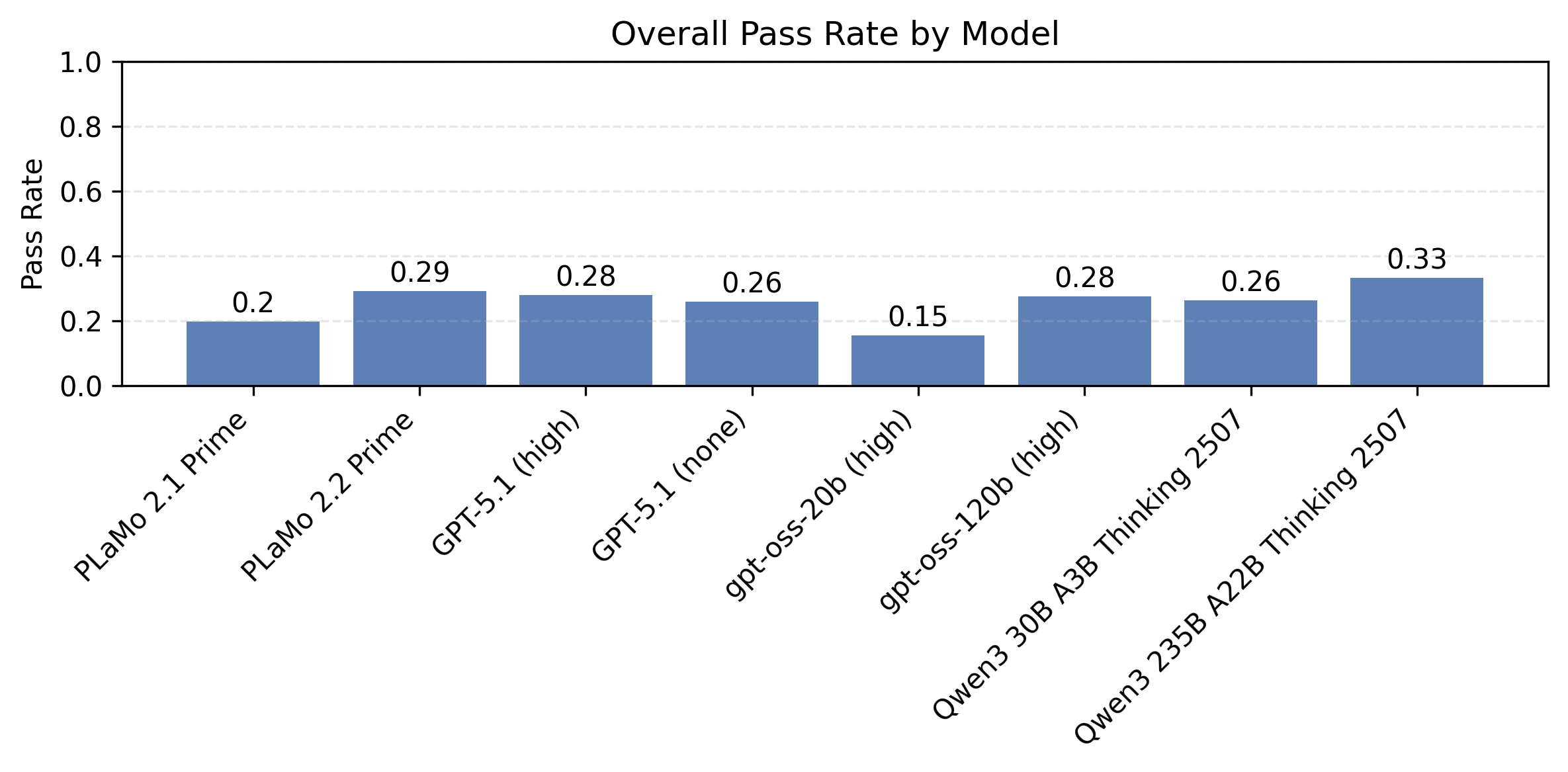
図2にJFBenchのテストデータセットのIFBenchプロンプトのデータに対して、制約数について平均をとった、モデル別の制約充足率の比較を示します。この図でいう制約充足率とは、各データに対して全ての制約が満たされるかどうかで測ったものとします。対策データセットを用いることでPLaMo 2.1 PrimeからPLaMo 2.2 Primeにかけて性能が大きく改善していることがわかります。またGPT-5.1といったフロンティアモデルと比べても、PLaMo 2.2 Primeが本ベンチマークにおいて匹敵する性能を持つことがわかります。
図2: IFBenchプロンプトに対するモデル別の制約充足率。全ての制約数にわたる平均です。
図3に制約数の変化に対して制約充足率がモデルごとにどのように変化するかを示します。同時に満たすべき制約数が増えると、難易度が上昇し制約充足率が下がる様子が見て取れます。
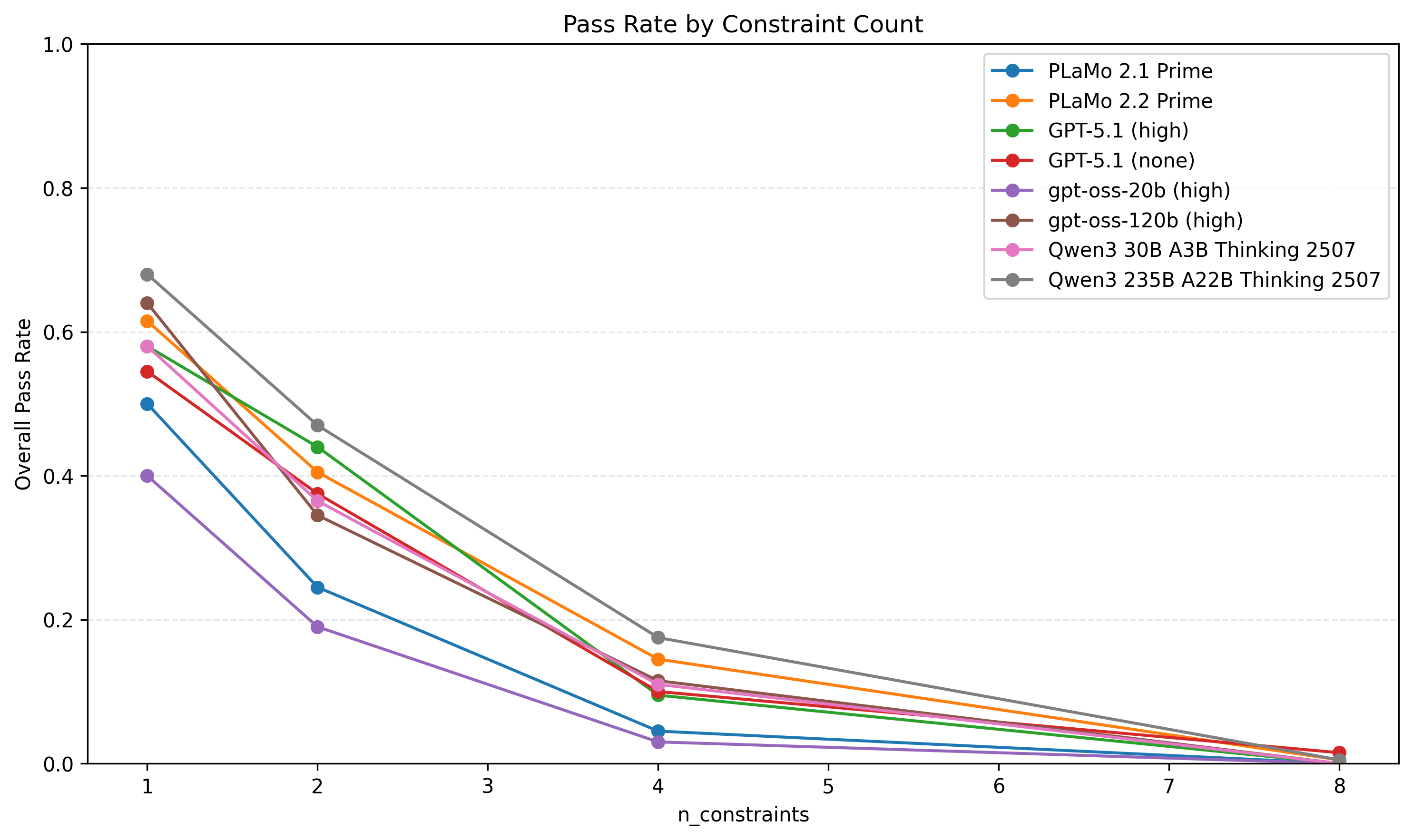
図3: IFBenchプロンプトに対する制約数を変化させた時のモデル別の制約充足率。
図4にJFBenchのテストデータセットに対して、IFBenchプロンプトと制約数について平均をとった、モデル/制約グループ別の制約充足率の比較を示します。この図でいう制約充足率とは、各データに対して全ての制約が満たされるかどうかで測ったものとします。各テストデータに対してそのデータに含まれる各制約が満たされればその制約の属する制約グループの充足度に対して+1点、満たされなければ0点を加点し、最後に該当制約グループの出現した制約数で割ることで算出しています。JFBench/JFTrainは特に出力フォーマットに関する制約を重視してデータセットを構築しているため、PLaMo 2.2 Primeは特に性能向上の改善幅が大きいことがわかります。
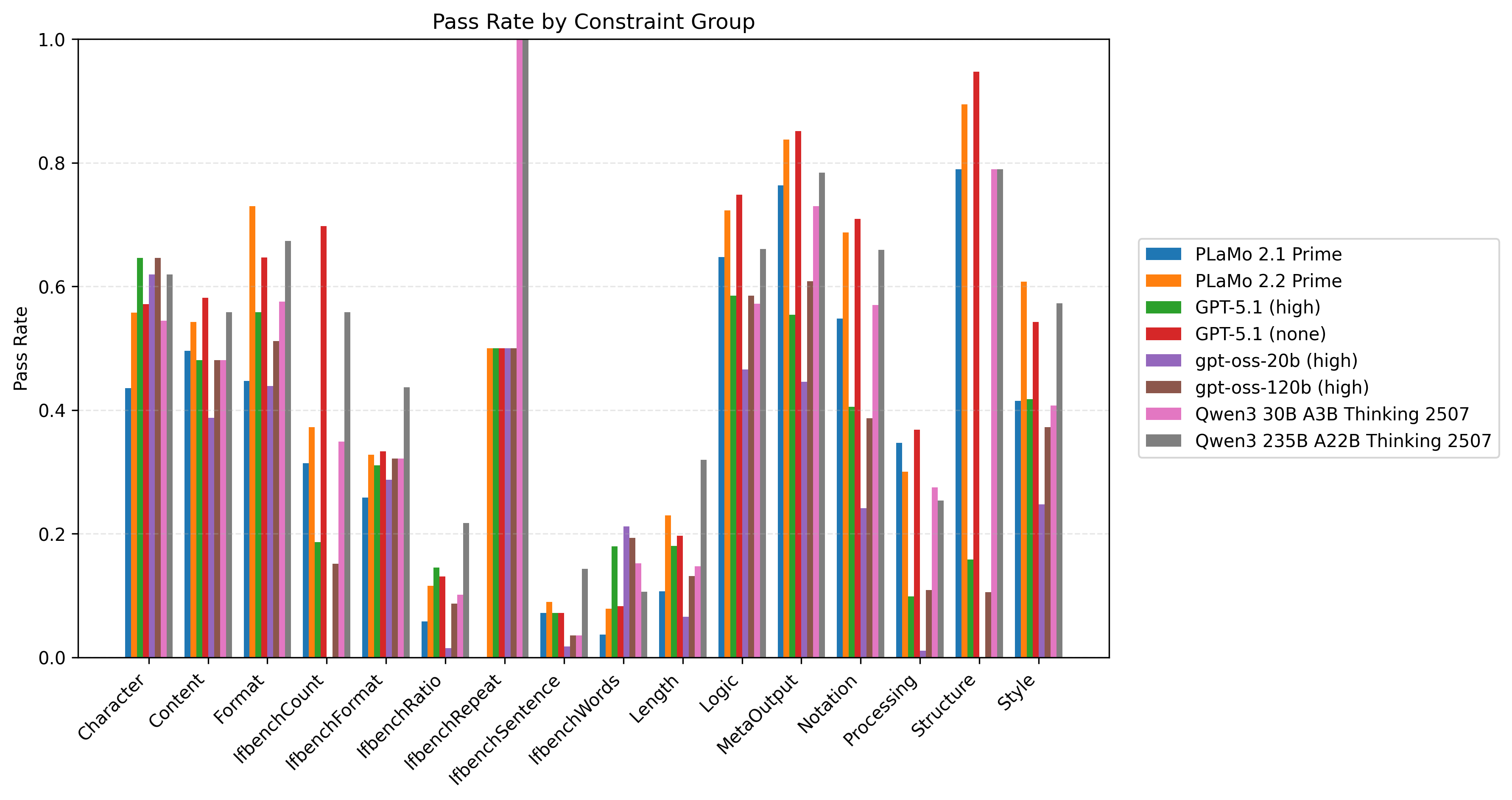
図4: モデル/制約グループ別の制約充足率。IFBenchプロンプトについて制約数にわたって平均をとったものです。
JFBenchのテストデータセットに対して、ブログの末尾の図5に各プロンプト種と制約数に対して評価したモデル別の制約充足率の比較を、図6にモデル/制約グループ別の制約充足率の比較を示します。
おわりに
PLaMo 2.2 Prime では、社内外からいただいたフィードバックや取り組みを元に日本語IF性能を評価・改善するためのデータセットJFBench/JFTrainを構築し、事後学習を実施することで性能を改善しました。JFBenchの開発は今後も継続する予定で、将来的にはさらにテストデータセット向けの制約集合を拡充して難易度の段階的な向上を行なっていきます。事後学習チームでは引き続きチップ、基盤モデル、ライブラリ、そしてソリューションまでを一気通貫で開発・提供するPFNの垂直統合の強みを活かしてPLaMoの開発を熱烈に行っていきます。
PFNでは今後もLLMの開発を継続して行っていきます。開発は今回紹介したIF性能改善以外にも多岐にわたります。我々はこれらの課題に情熱をもって挑戦していく仲間を募集しています。これらの仕事に興味がある方はぜひご応募よろしくお願いします。https://www.preferred.jp/ja/careers/
PLaMo 2.2 Primeの開発は経済産業省及び国立研究開発法人新エネルギー‧産業技術総合開発機構(NEDO)が実施する、国内の生成AIの開発力を強化するためのプロジェクト「GENIAC(Generative AI Accelerator Challenge)」の支援を受けて実施しました。
Appendix
以下の図5はプロンプト種と制約数ごとに計測したモデル別の制約充足率の比較です。同時に満たすべき制約が多い設定で、まだまだ改善の余地が大きいことがわかります。
| 図4:プロンプト種と制約数ごとに計測したモデル別の制約充足率の比較 | ||
| IFBenchプロンプト | PFN社内プロンプト | |
| 制約数1 | 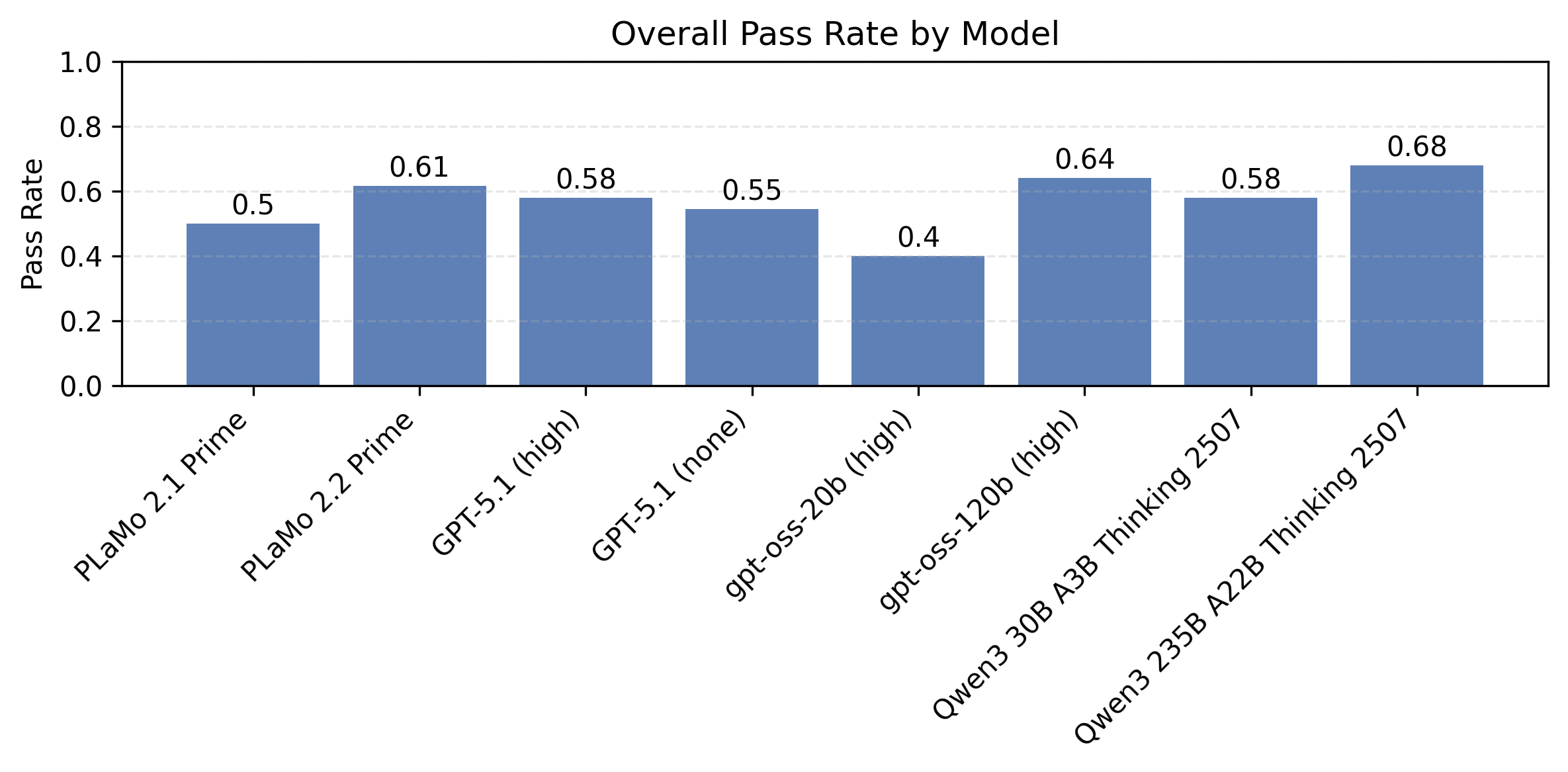 |
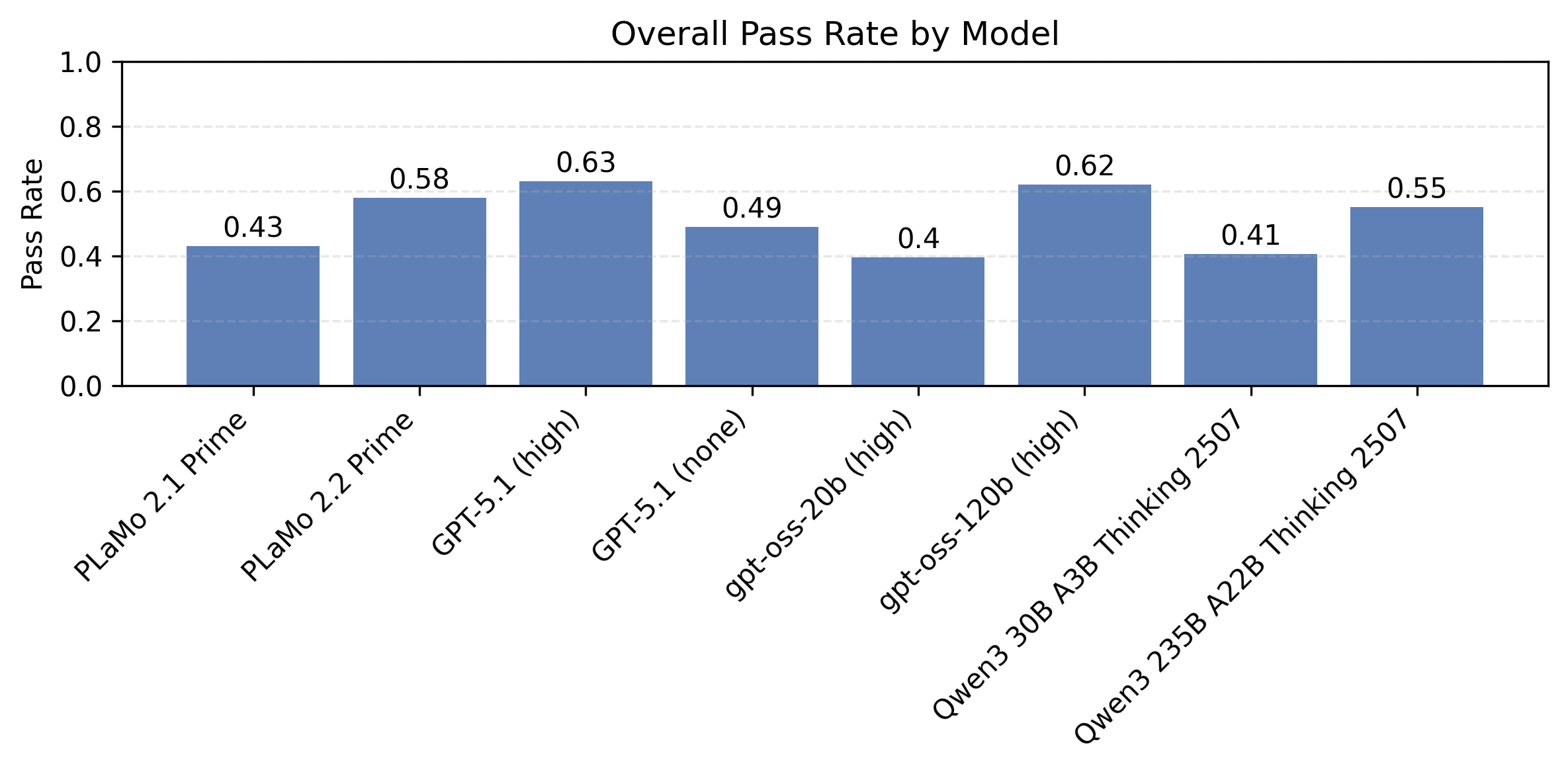 |
| 制約数2 | 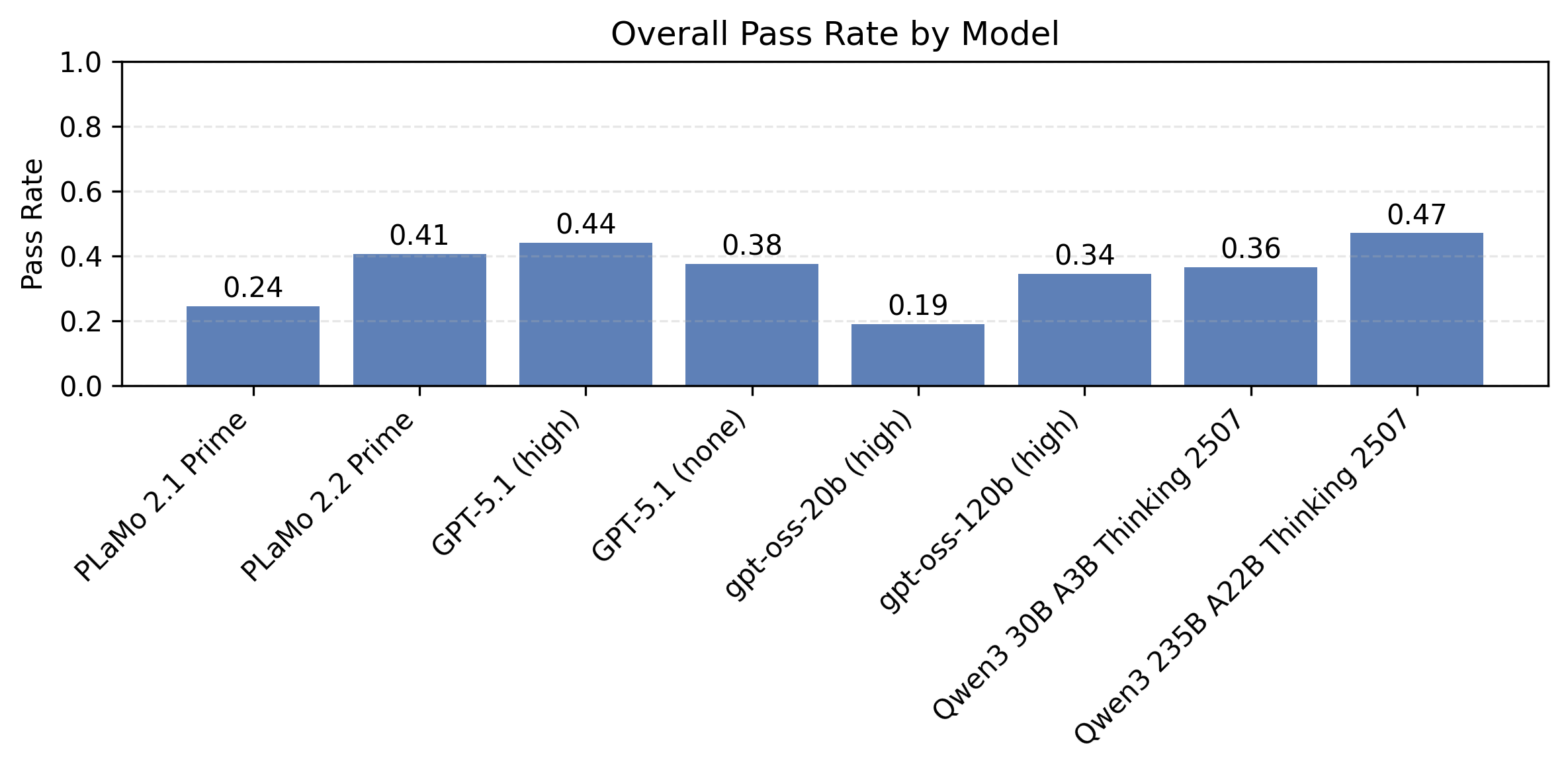 |
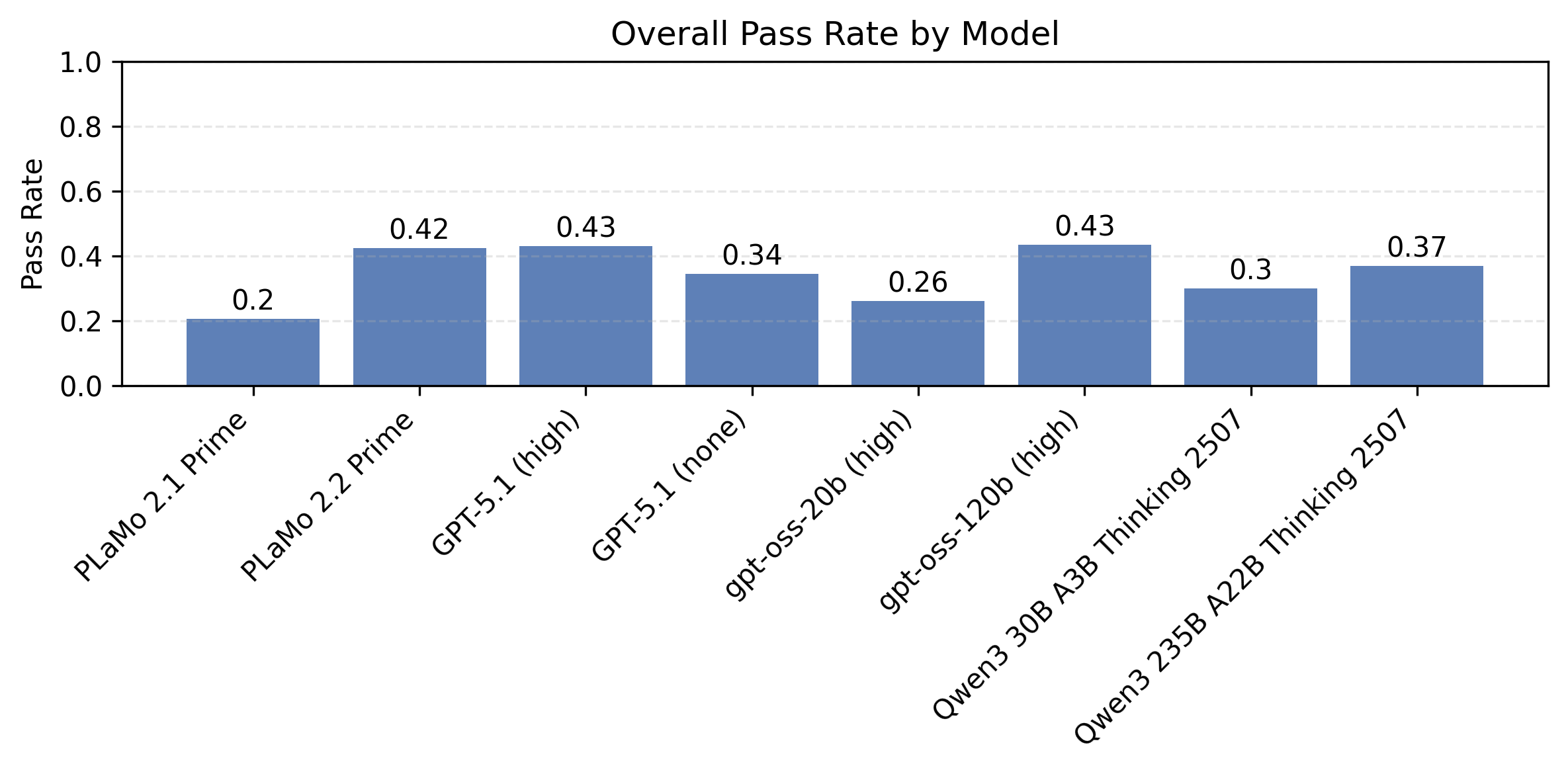 |
| 制約数4 | 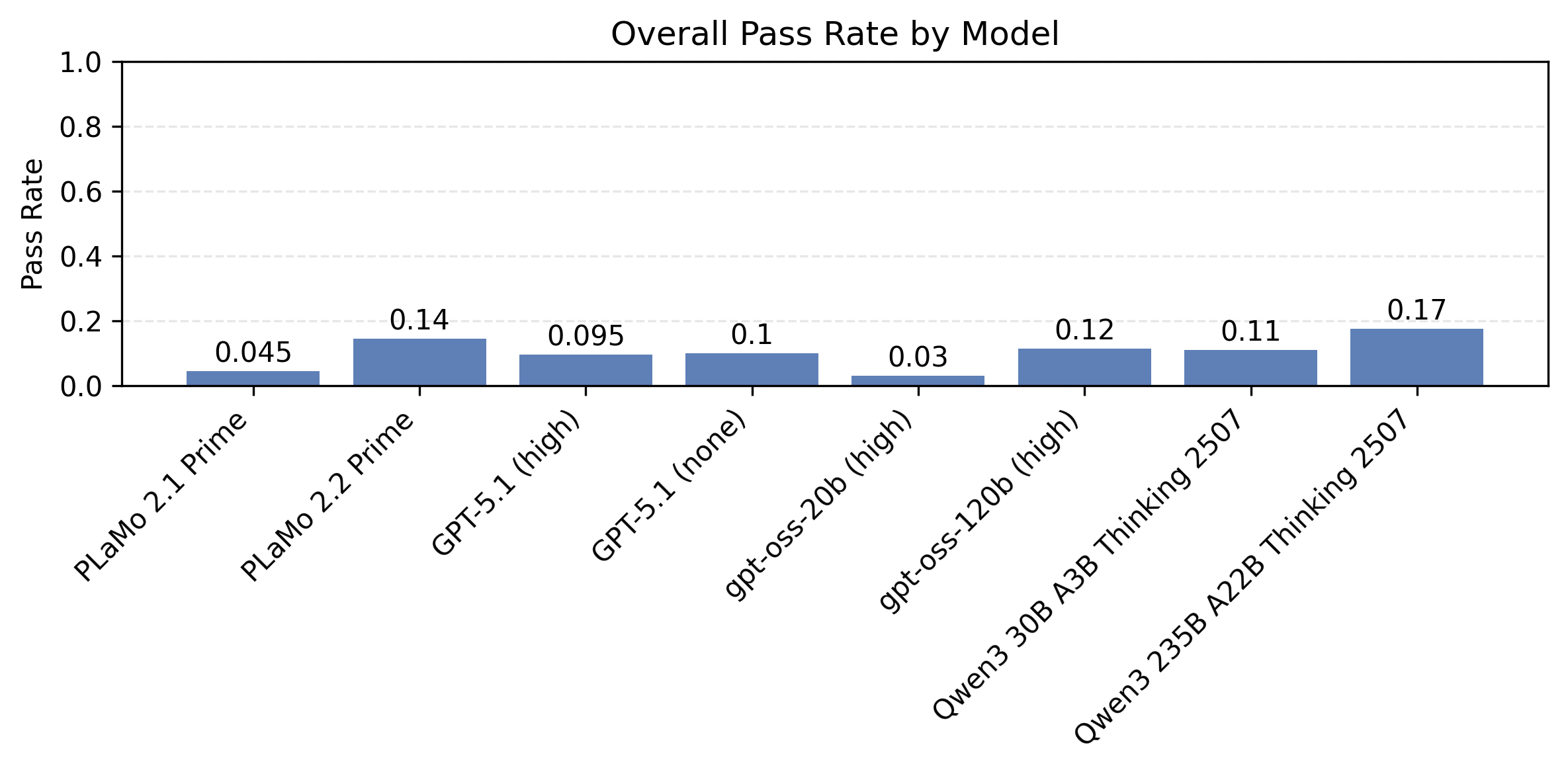 |
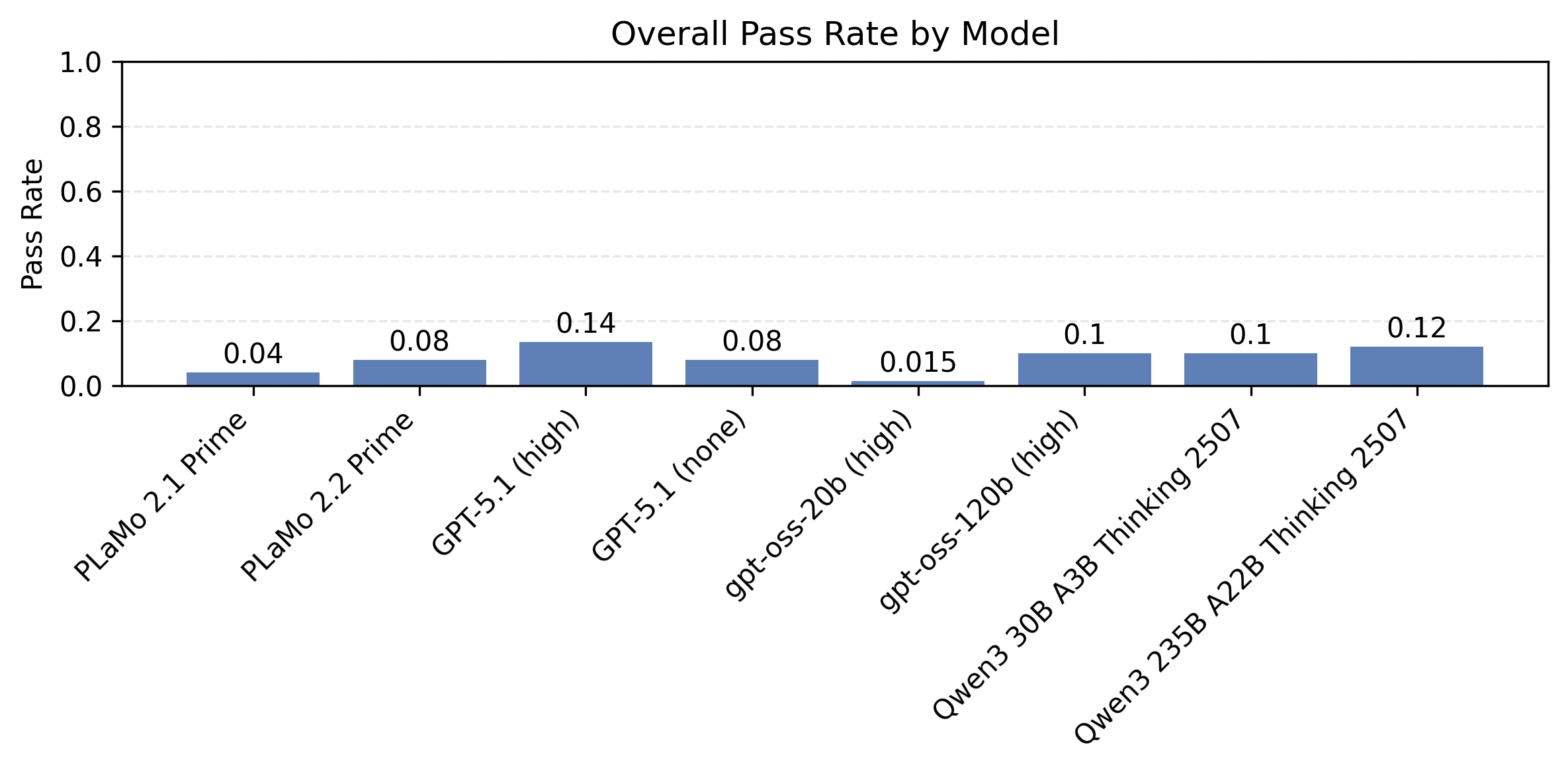 |
| 制約数8 | 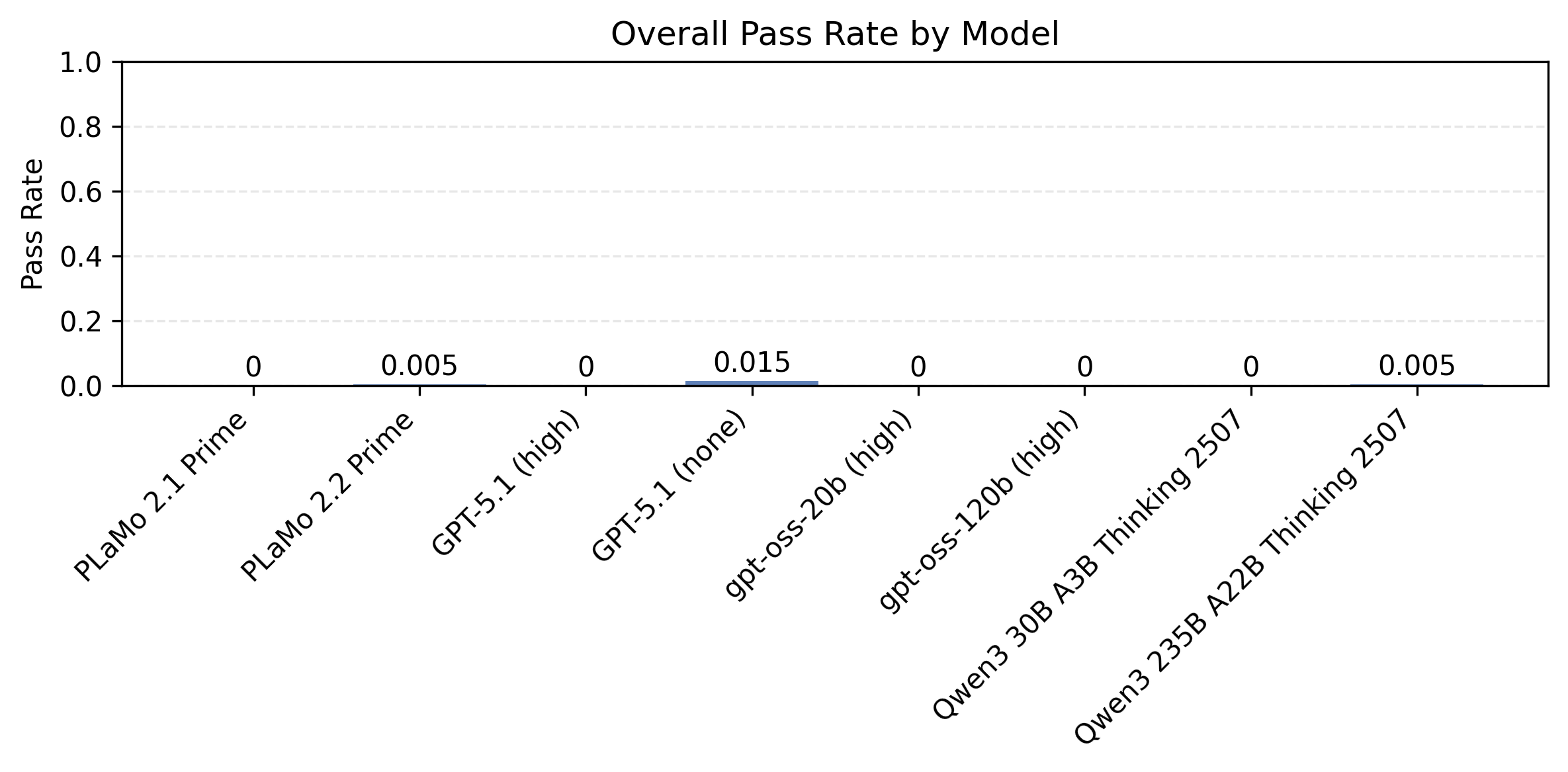 |
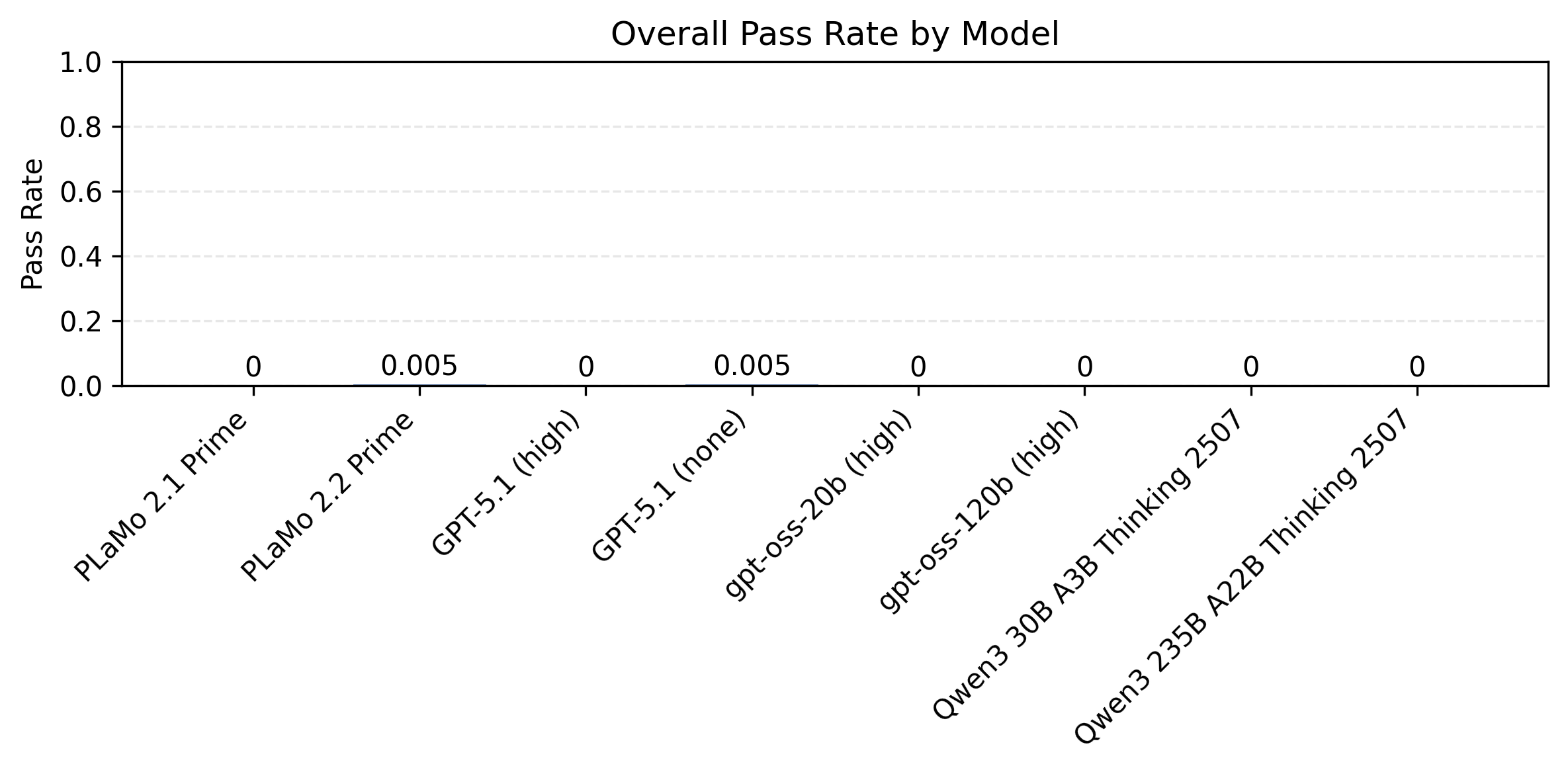 |
以下の図6はプロンプト種と制約数ごとに計測したモデル/制約グループ別の制約充足率の比較です。同時に満たすべき制約数が多い設定を中心に、Length/Processing/IfbenchXXXグループを中心に改善の余地が大きいことがわかります。
| 図5:プロンプト種と制約数ごとに計測したモデル/制約グループ別の制約充足率の比較 | ||
| IFBenchプロンプト | PFN社内プロンプト | |
| 制約数1 | 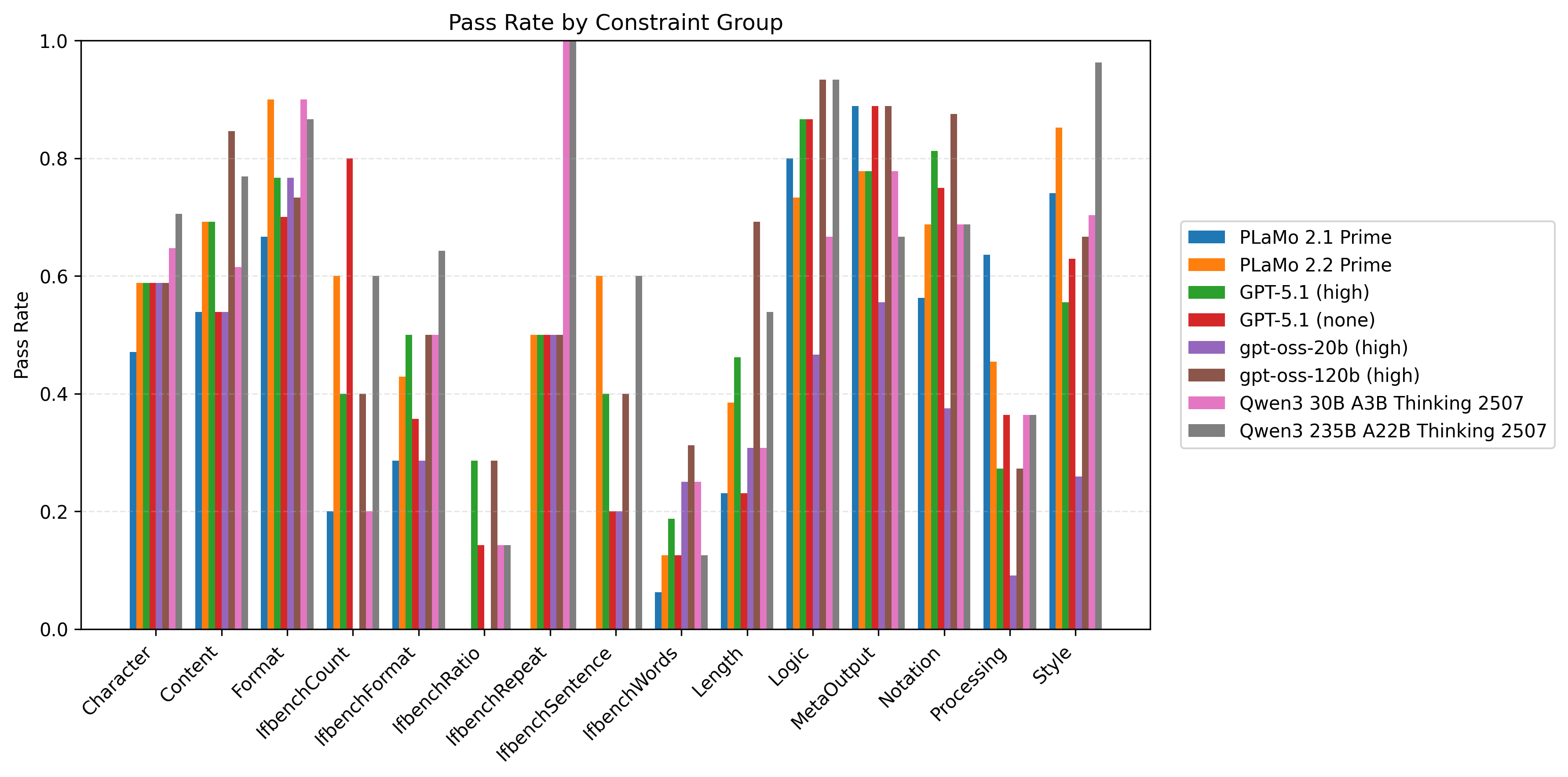 |
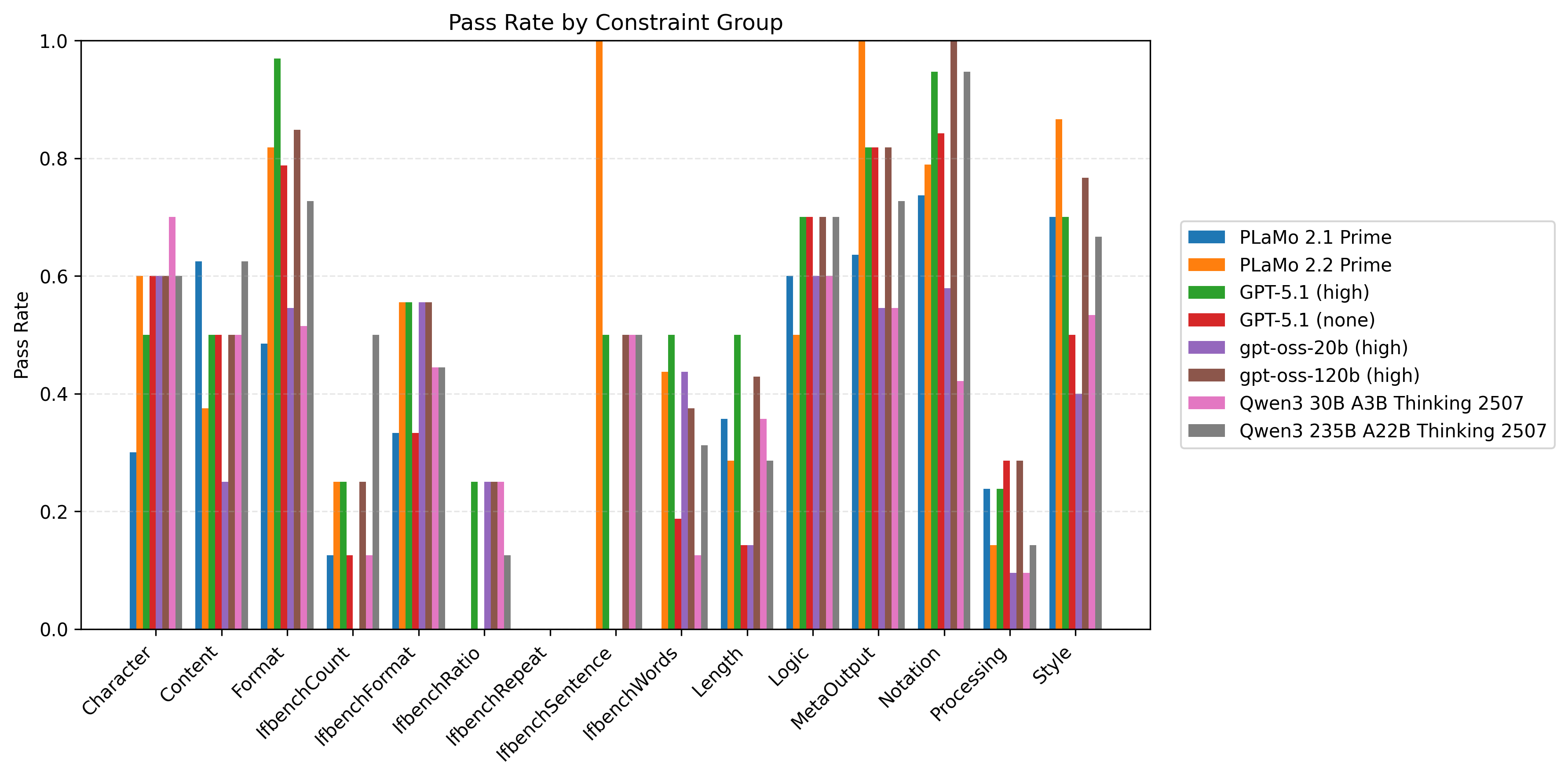 |
| 制約数2 | 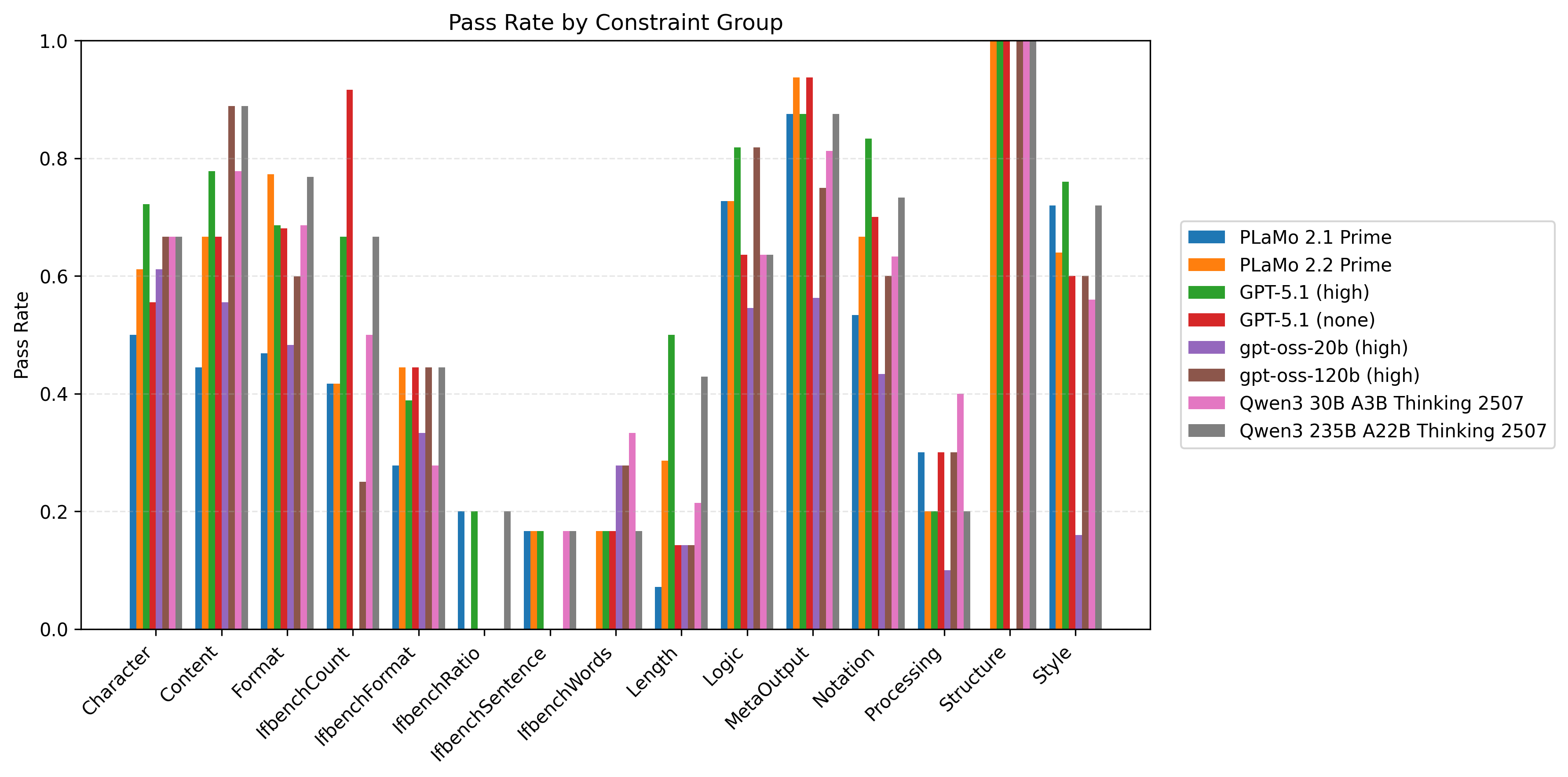 |
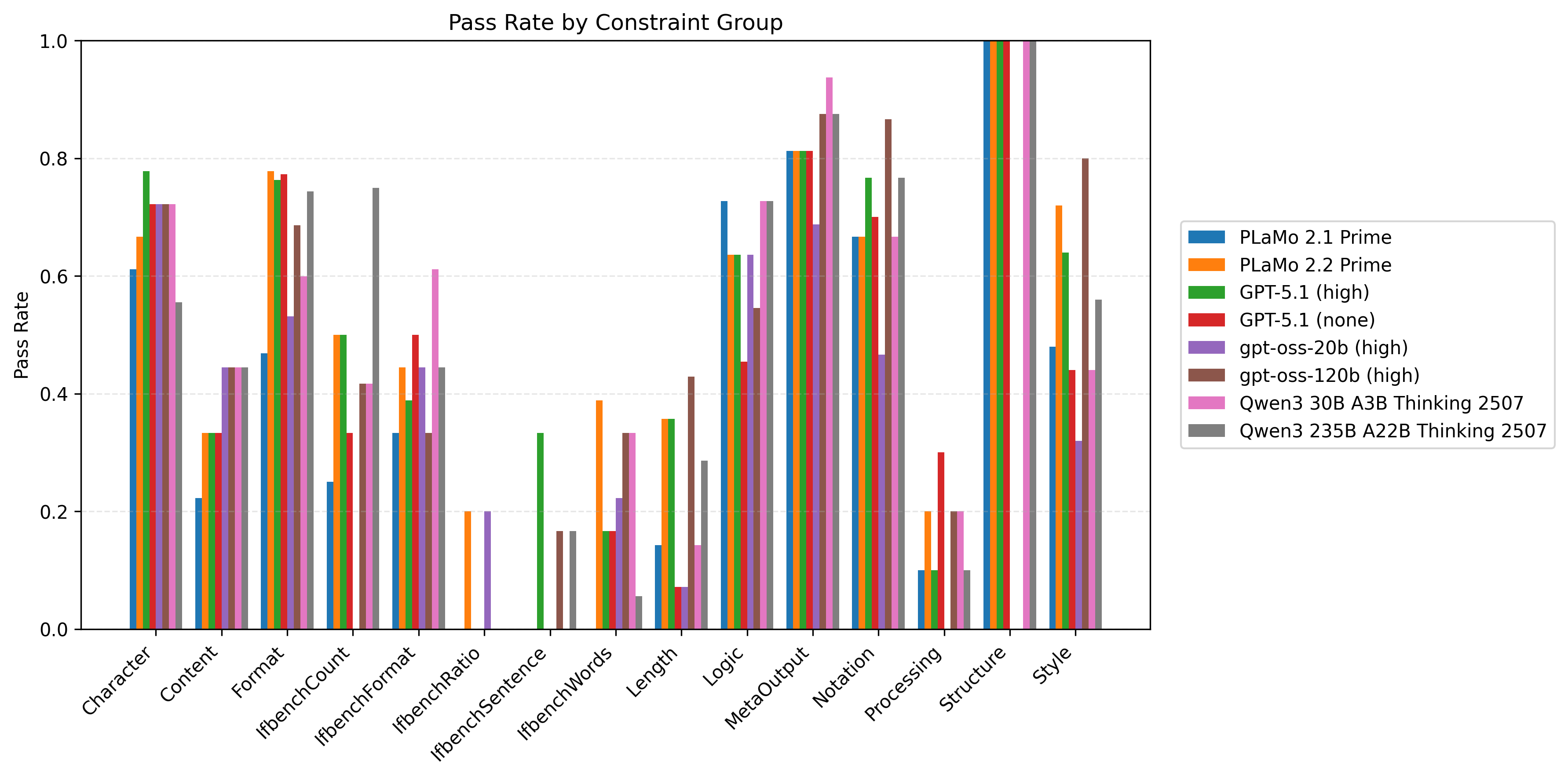 |
| 制約数4 | 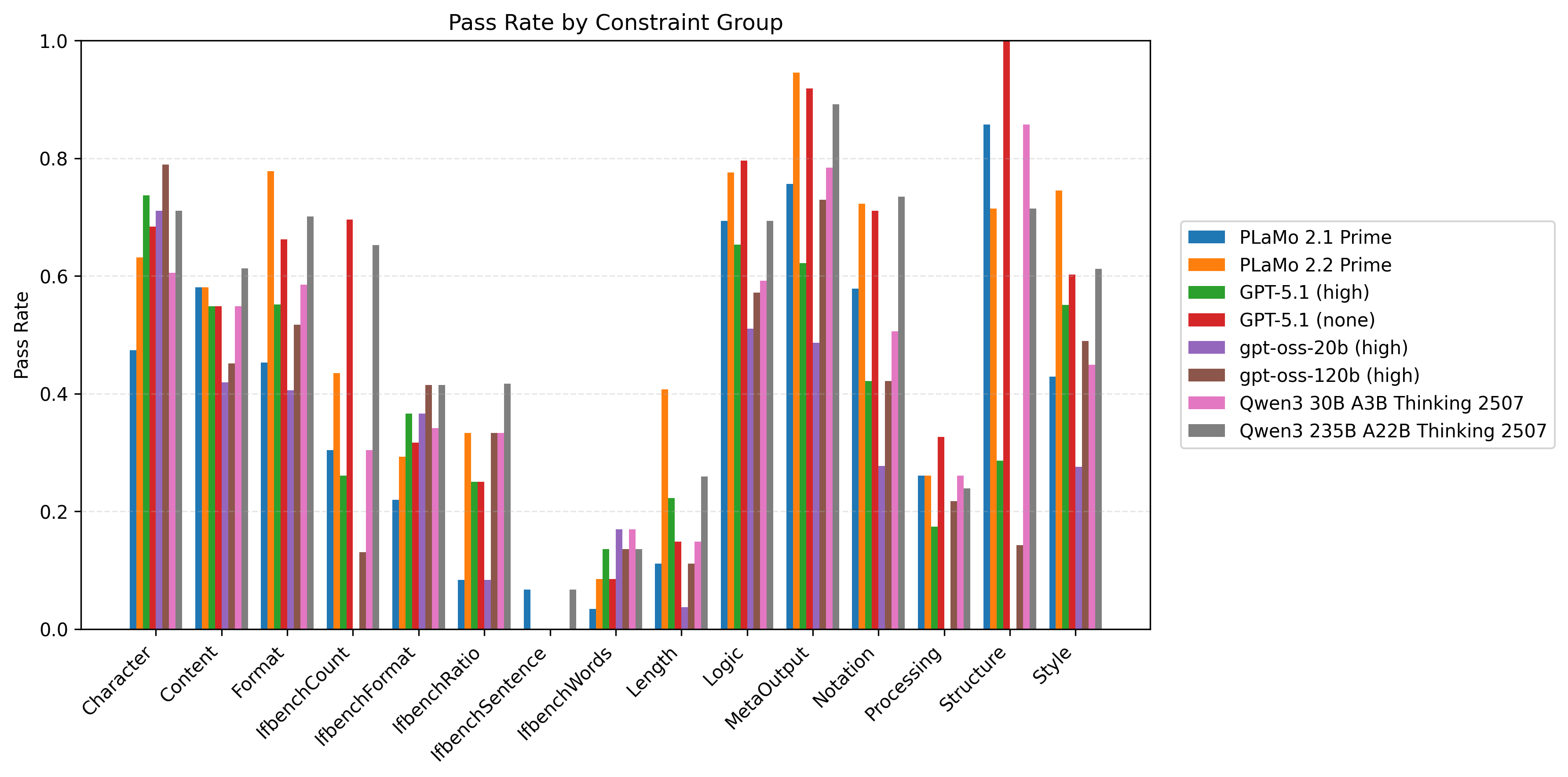 |
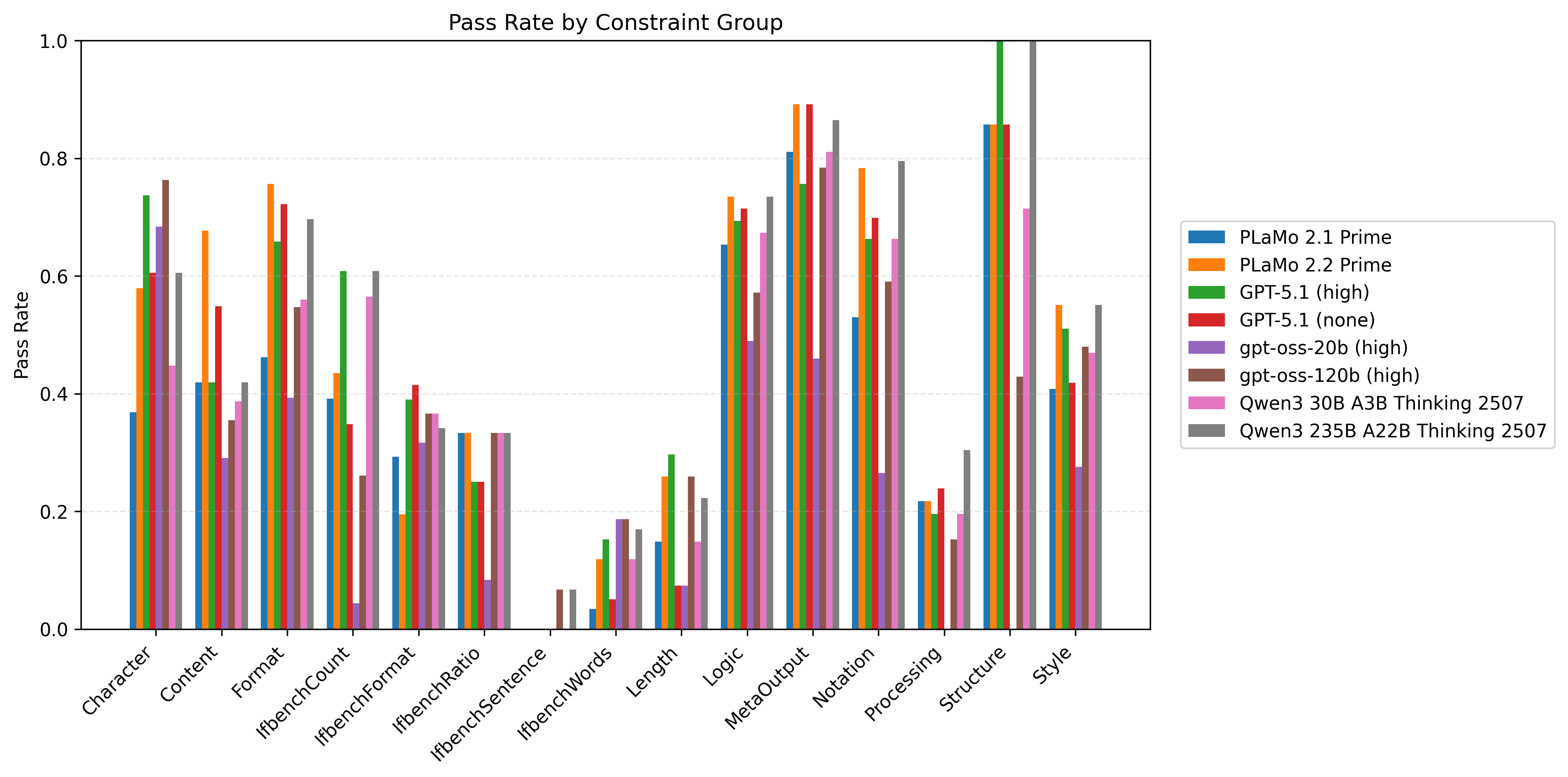 |
| 制約数8 | 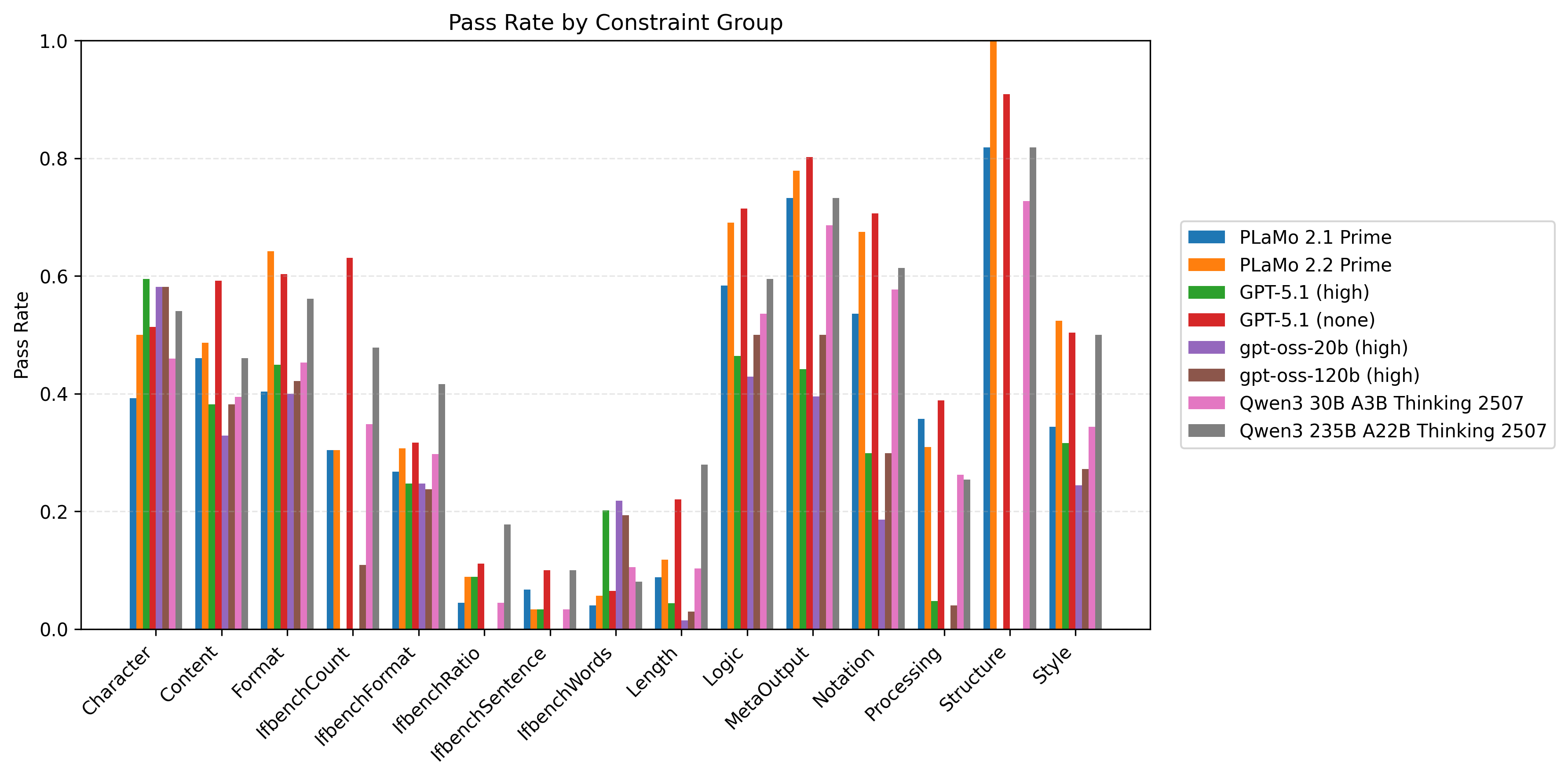 |
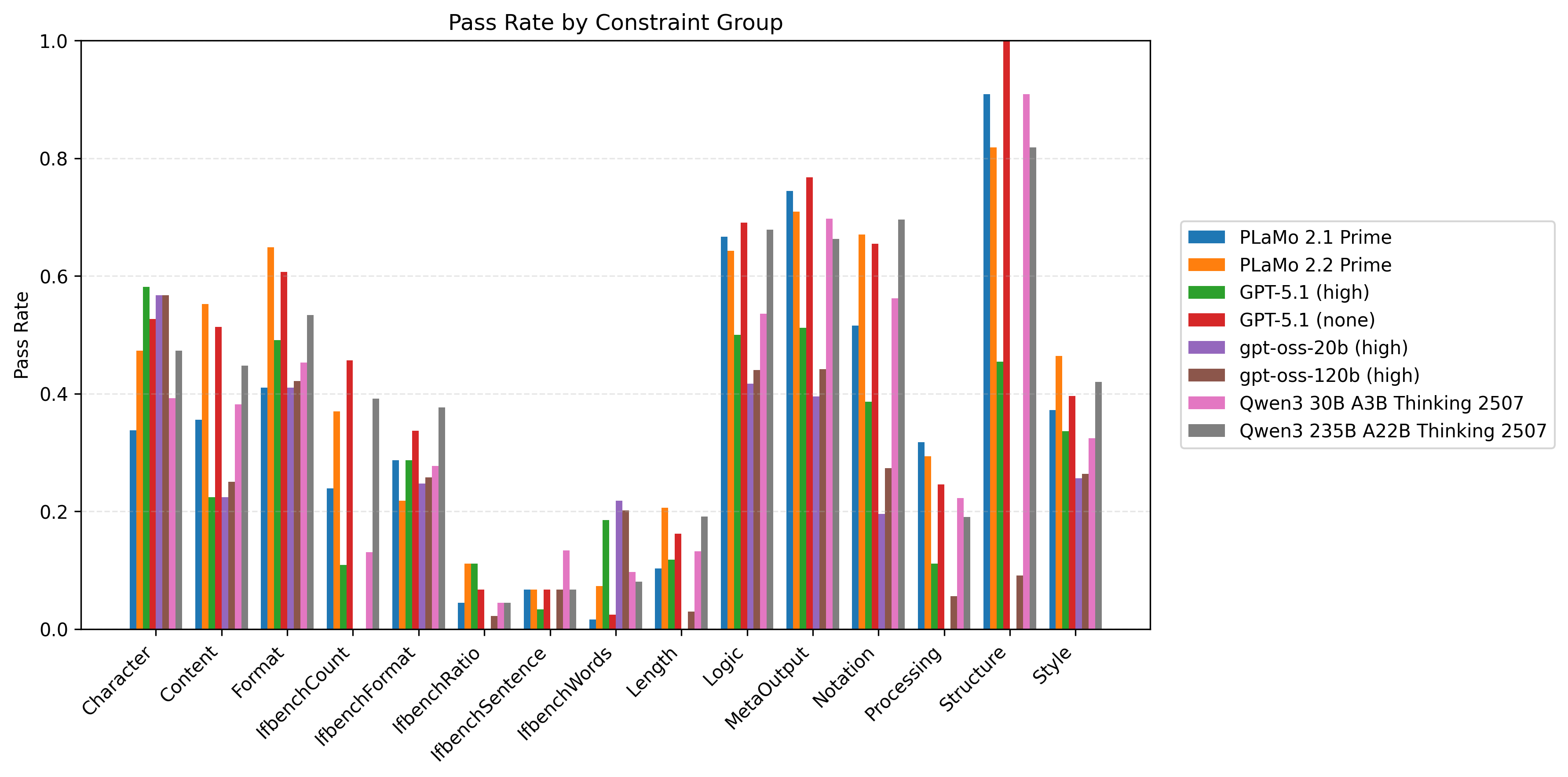 |



