Blog

はじめに
PFNエンジニアの上野です。Cluster Servicesチームという、PFNの機械学習基盤を開発・運用するチームに所属して、日々基盤の改善や新機能の開発を進めています。
本記事は、以前にヤフー株式会社のAIプラットフォームチームと共催したイベント「オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜 #1」のPFNパートをざっくりまとめて、2022年のPFNの機械学習基盤について紹介するものです。 イベントの第二回を 8/29 に開催して、さらに新しい取り組みについても紹介しますので、ぜひこちらから参加登録をお願いします。
PFNのオンプレML基盤の取り組み
スライド全体はこちらからアクセスできます。
もくじ
オンプレクラスタの概要

PFNエンジニアの上野です。2021年に新卒で入社し、PFNの機械学習基盤を開発・運用するCluster Servicesチームに配属されました。 元々大学で、スーパーコンピュータを使った深層学習とその高速化に取り組んでいたこともあり、性能最適化や計算基盤に興味を持っています。

PFNがオンプレクラスタを選ぶ理由として、PFNのVisionに「現実世界を計算可能にする」というものがあります。 現実世界を計算可能にするために必要なものの一つとして、シミュレーションや深層学習が挙げられますが、これらは膨大な計算リソースを必要とし、これこそがPFNの競争力になると考えています。
また、大規模な計算を息をするように、つまり必要となる計算リソースを気にすることなく実施したい、と考えています。 これは既にPFNでは実現できていて、16 GPU以上を使った分散学習が日常的に行われていたり、過去にはMN-1の全系である1024 GPUを使った ImageNet-1K による画像分類器の学習 [1] を15分で行う挑戦に成功していたりします。
このように計算基盤に関する全てを自社で受け持つことで、ソフトウェアなどの上から、ハードウェアまでの下までを全てコントロールしています。 例えばノード内外の通信やI/Oの最適化は、分散学習や日々高速になっていくアクセラレータの性能を出し切るためには重要で、これら全てを改善することによりはじめて、高速な学習が可能になります。 これを実現するために、さまざまな技術バックグラウンドをもつメンバーが集結しています。

(補足:このスライドはイベント開催当時のPFNの計算インフラを紹介するものですが、既に古くなっているので こちら をご参照ください。 現在は、JAMSTEC横浜研究所にMN-2a, MN-2b, MN-3の3つのクラスタが稼働しています。)

Kubernetesクラスタとしては、JAMSTEC内の3つのクラスタ(MN-2a, MN-2b, MN-3)を全てまとめて、1つのKubernetes クラスタを実現しています。 この中ではMN-2aは最初に作ったクラスタで、NVIDIAのVolta世代のデータセンタ向けGPUであるV100を計 1024 GPUs 搭載したものです。 各計算ノードには8つのGPUと4つの100 GbpsのNICを搭載しており、ノード内でも複数ノードを束ねても、AllReduce [2] を使った高速なデータ並列型分散学習が可能です。
MN-3aは、MN-Coreという独自アクセラレータを搭載したクラスタです。Green500 で世界一位の電力効率を獲得したクラスタ [3] でもあります。
(補足:MN-2bはイベント当時には稼働していませんでしたが、NVIDIAのAmpere世代のデータセンタ向けGPUであるA100とA30を搭載したクラスタで、今年の7月から運用を開始しました。詳しくは こちら をご参照ください。)
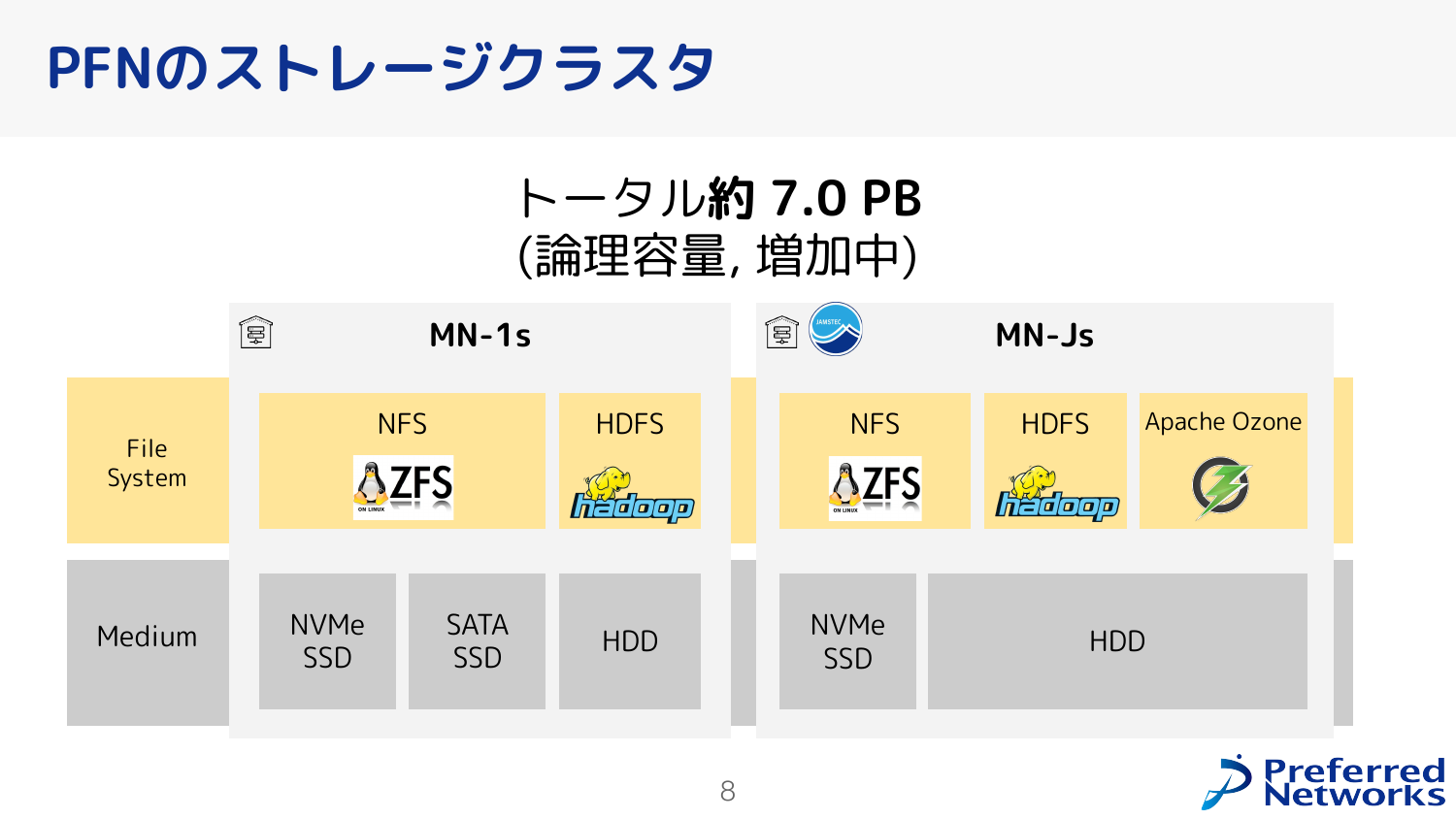
アクセラレータが高速になり続けている今、アクセラレータに入力データを供給するストレージも重要です。PFNでは、拠点ごとにストレージクラスタを持っており、用途ごとにNFS, HDFS, Apache Ozone を運用しています。 NFSは小さいデータを便利に(マウントしたり)使うことができ、オブジェクトストレージは大きなデータを分散管理し必要に応じてスケールアウトさせることができます。

このスライドではPFNの機械学習基盤に求められる要件を列挙しました。
まず、多様なリテラシのユーザが使いやすく、例えば入社初日からクラスタで大規模に実験をして成果を出せる環境を目指しています。 実際、今年のインターンさんも入社2日目からクラスタにアクセスして開発を始められています。
また、リソースを効率的かつフェアに利用できることも重要視しています。 効率的とは、スケジューリングや性能最適化を進めることで、同じ計算機でたくさんの機械学習ワークロードを捌けることを目指したり、クラスタを大きく管理することで、計算機を余らせることなく使い切ることをさしています。 フェアとは、各ユーザがこれまでに利用した量に基づいて、繁忙期には計算を停止させたりすることをさしています。
最後に、信頼性や運用効率も重要であると考えています。 例えばプロビジョニングの自動化、健全性の自動診断、保守の省力化などがここに対応します。
使いやすい環境
「使いやすい環境」に関連するトピックを紹介します。
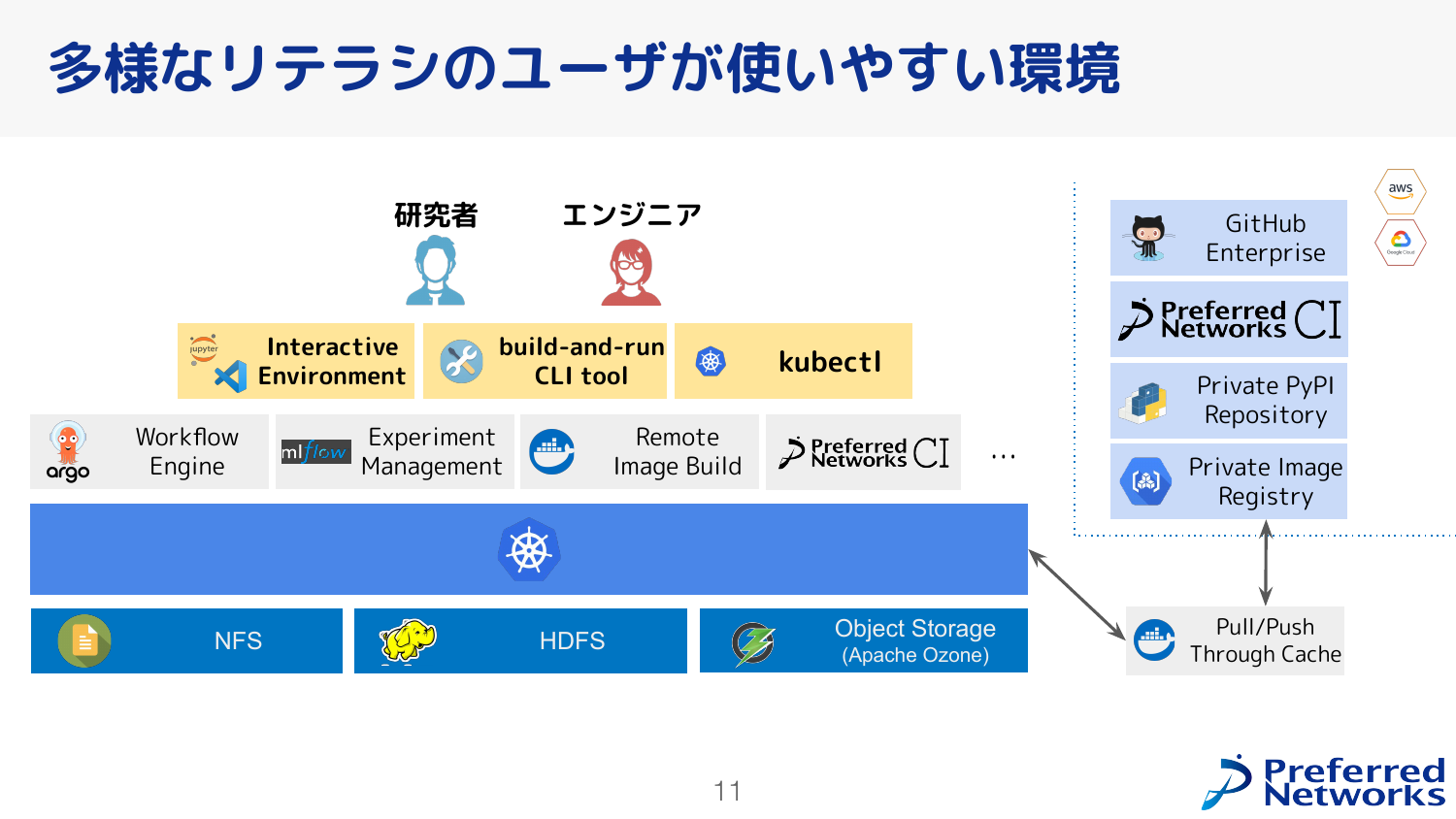
PFNにはエンジニアやリサーチャーが所属しており、計算基盤を使った研究開発を行っています。 その中にはKubernetesの専門家もいますが全員がKubernetesに精通しているわけではなく、各々の得意とするドメインがKubernetes以外、例えばコンピュータビジョンや計算化学の方もいます。 よってそのままのKubernetesを提供するだけでは不十分で、より簡単にKubernetesを利用できる仕組みも重要です。 そのために、通常のKubernetesの利用フローであるkubectl以外に、簡単にJupyterやcode-serverをインタラクティブに利用できる仕組みや、コマンドラインで実験をするようにKubernetesにジョブを投げる仕組みを提供しています。 また、複数のジョブからなるような計算、ワークフローを実現するための Argo Workflow や、実験管理のための MLFlow、Kubernetesを利用する上では欠かせないコンテナイメージを高速にビルドするためのリモートイメージビルドサービス、内製のCIなどがデプロイされています。
コンテナイメージの保存にはクラウド内のイメージレジストリを採用しています。 これによりイメージレジストリの運用業務が不要となりますが、クラスタ内でイメージを必要とするたびにクラウドからイメージを取得する必要があります。 クラウドとオンプレミスの間での通信量を削減しつつ、より高速なコンテナ起動を実現するため、クラスタ内にイメージのキャッシュサーバを運用しています。 例えばDaemonSetで利用されるような全ノードに配布する必要があるイメージであったとしても、クラウドからイメージを取得するのは1回で済み効率的です。 さらにイメージのpull時だけではなくpush時にキャッシュサーバを経由させることで、キャッシュサーバにヒットさせやすくする工夫を行っています。
そして、データを長期的に保存するためにNFS, HDFS, オブジェクトストレージであるApache Ozoneのストレージサービスを提供しています。 (補足:Apache Ozone については こちら をご参照ください。)

もう一度ユーザの面から見てみると、大きく分けて3つの使い方(インタラクティブに使えるJupyterやcode-serverを起動するための仕組み、手元でコードを開発しつつ分散学習まで実現する仕組み、kubectlを使うやり方)があります。
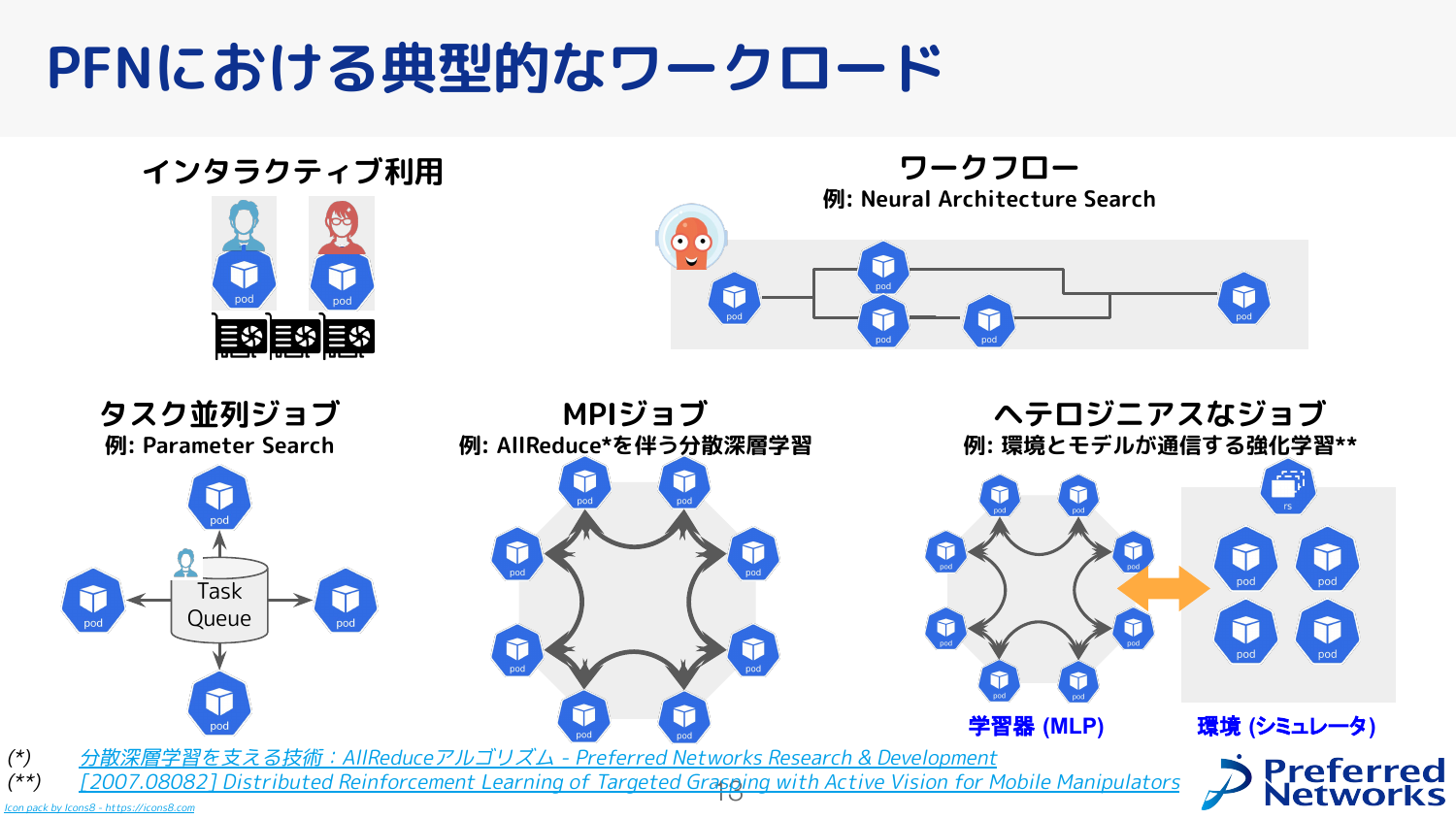
PFNにおける典型的なワークロードとしては、先ほど説明したインタラクティブな利用やワークフロー、AllReduceを使ったデータ並列型分散学習の他にも、Optunaを使うようなタスク並列ジョブや、複雑な例だと学習器と環境が分かれた強化学習ジョブなどもあります。
リソースの効率的かつフェアな利用
「リソースの効率的かつフェアな利用」について説明します。これはまとめると、「スケジューラで工夫しつつプリエンプションも使っていく」ということになります。

リソースを効率的に利用する、という観点では、1つの大きなKubernetesクラスタに複数のプロジェクトを載せたマルチテナント構成にすることで、クラスタの利用率を高く保つ、ということが挙げられます。 また、スケジューリングでは、よりコストの高いGPUジョブを優先したスケジュールをしたり、マルチノード分散学習の場合にどれか1つのノードが早くスケジュールされても使えないので「全てがスケジュールされるかされないか」の状態にするGang Scheduling、ノードをできるだけネットワーク的に近いところに配置するUnique Zone制約などをサポートしています。 パフォーマンスでは、複数の100G NICを1ノードに搭載して、それらによるRoCEv2によるRDMA (正確には GPUDirect RDMA [4] ) ができるようにするために、SR-IOVを使用してPodに直接VFを割り当てています。 これにより、1つのネットワークにGPU間通信のトラフィックとストレージ系のトラフィックを混載させ、二重投資を防いでいます。 また、継続的な通信性能の評価も行っています。

リソースをフェアに利用する、という観点では、PriorityClassを使った優先度制御を行っています。 ビジネス的な要求からくる優先度を、各PriorityClassで同時に利用できるリソースの量に割り当てており、例えばAプロジェクトは今月末まで優先的に 16 GPUs まで利用できる、といった割り当てが行えます。 high以外の低い優先度クラスは、同時に利用できるリソースの量に上限を設けていません。 また、ユーザがこれまでに利用した量(ノード時間積)を考慮して、スケジューリングやプリエンプションを行っており、よく使っているユーザはスケジュールされづらかったり、混雑時にワークロードが停止しやすかったりするなど、フェアに利用できる工夫もしています。
信頼性・運用省力化
信頼性と運用省力化について説明します。
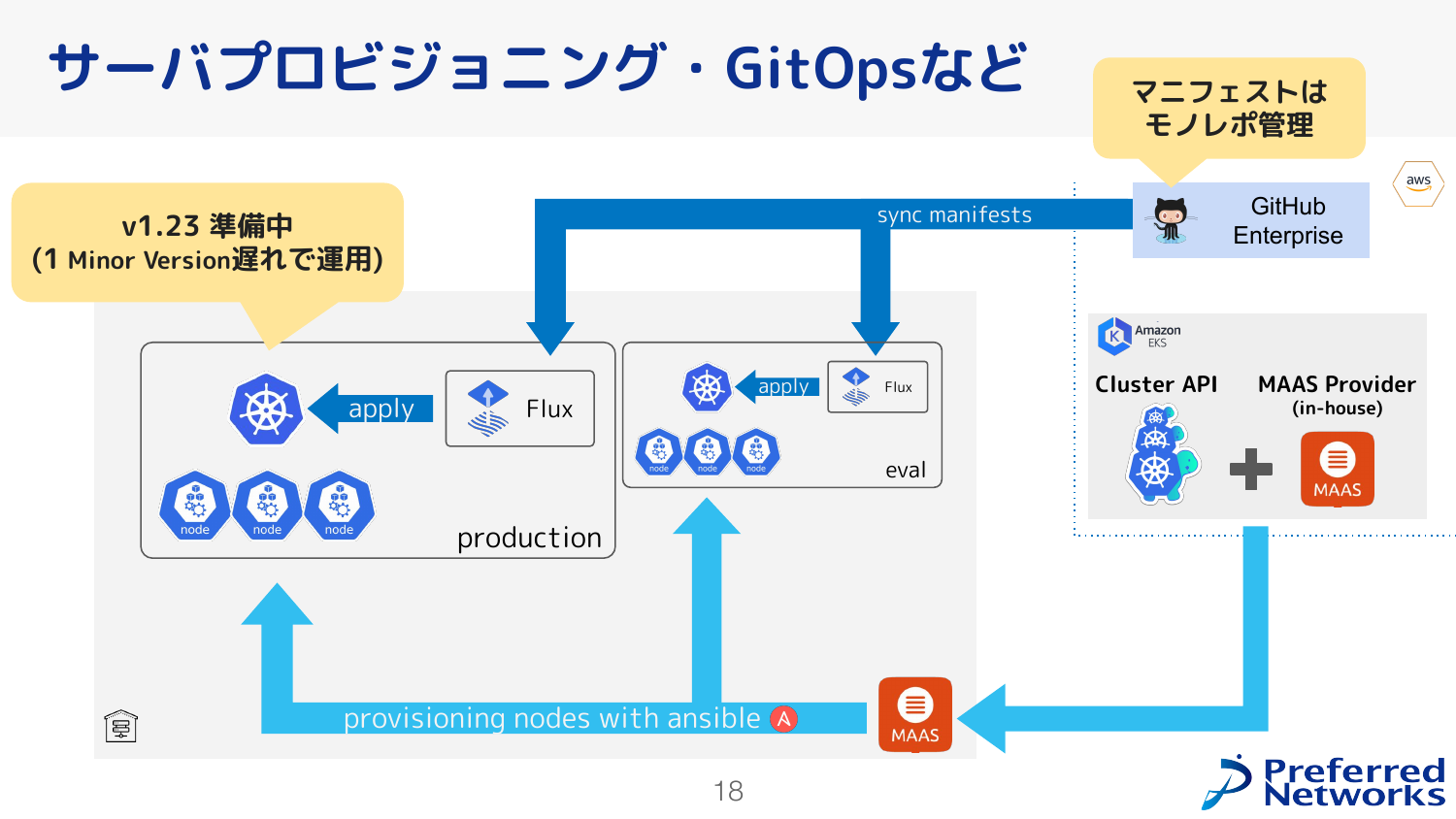
まず、実際にユーザが利用するproductionのクラスタと、クラスタ管理者が利用するevalのクラスタの2つをもっています。 ここに適用するKubernetesのマニフェストは、Gitリポジトリでモノレポ管理しているものがFluxによって適用されるようになっています。 このクラスタ自体は、Cluster APIとMAASというベアメタルを管理するOSSを連携させて実現していて、Cluster APIとMAASを連携させるコンポーネントについては内製しています。 MAASはOSイメージをインストールすることまでできるので、そのあとのセットアップはAnsibleによって実現しています。
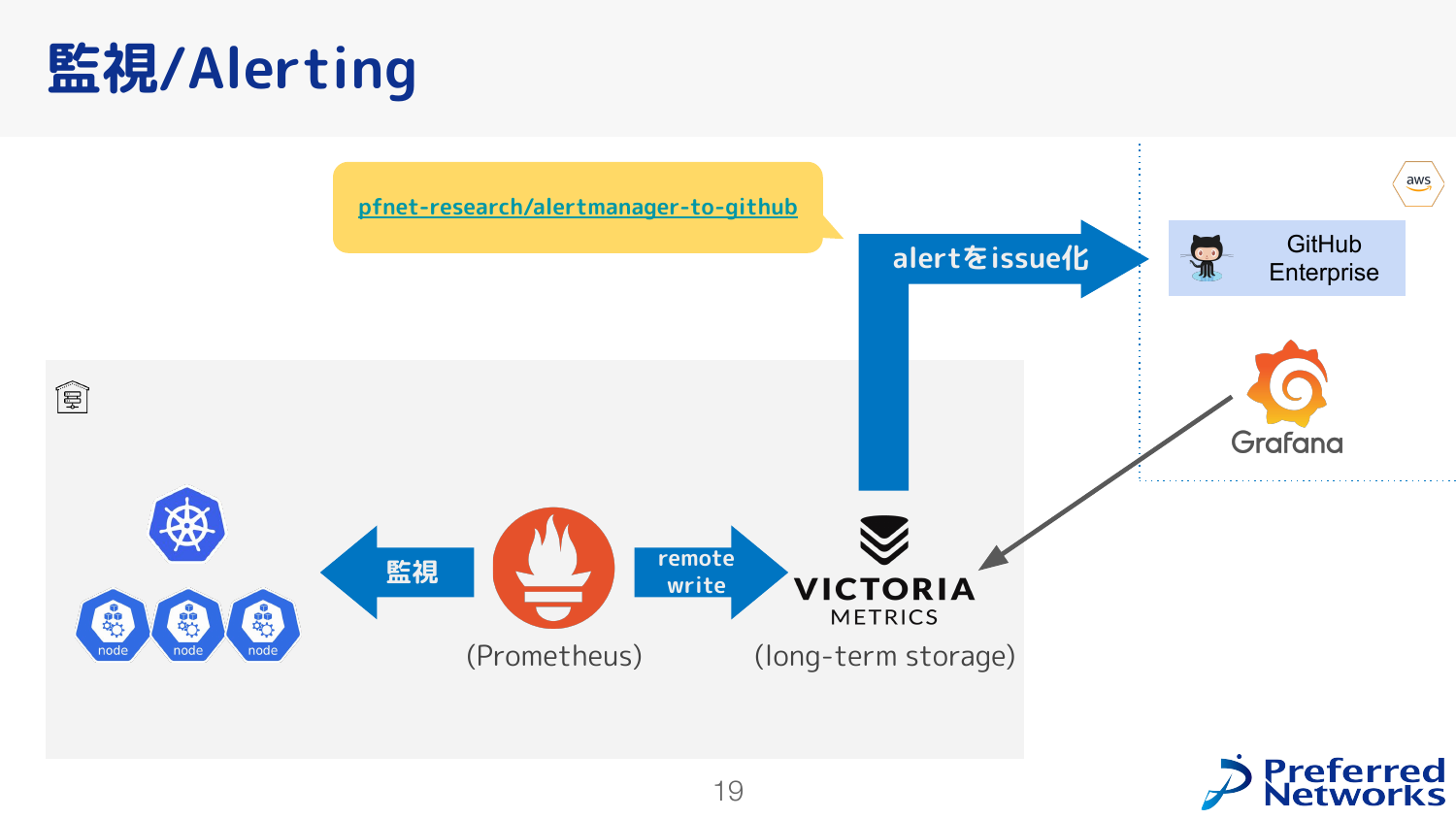
監視とアラートは、ノードにGPUやその他の状況を監視するexporterをPrometheusからスクレイプするという、標準的な構成をとっています。 このスクレイプした内容をVictoriaMetricsで長期的に保存していて、Grafanaから見たり、今後のクラスタ設計を考える際の材料として使ったりしています。 また、内製している alertmanager-to-github というソフトウェアがあり、これがアラートをもとに GitHub に起票してくれて、これによりアラートの対応を行っています。
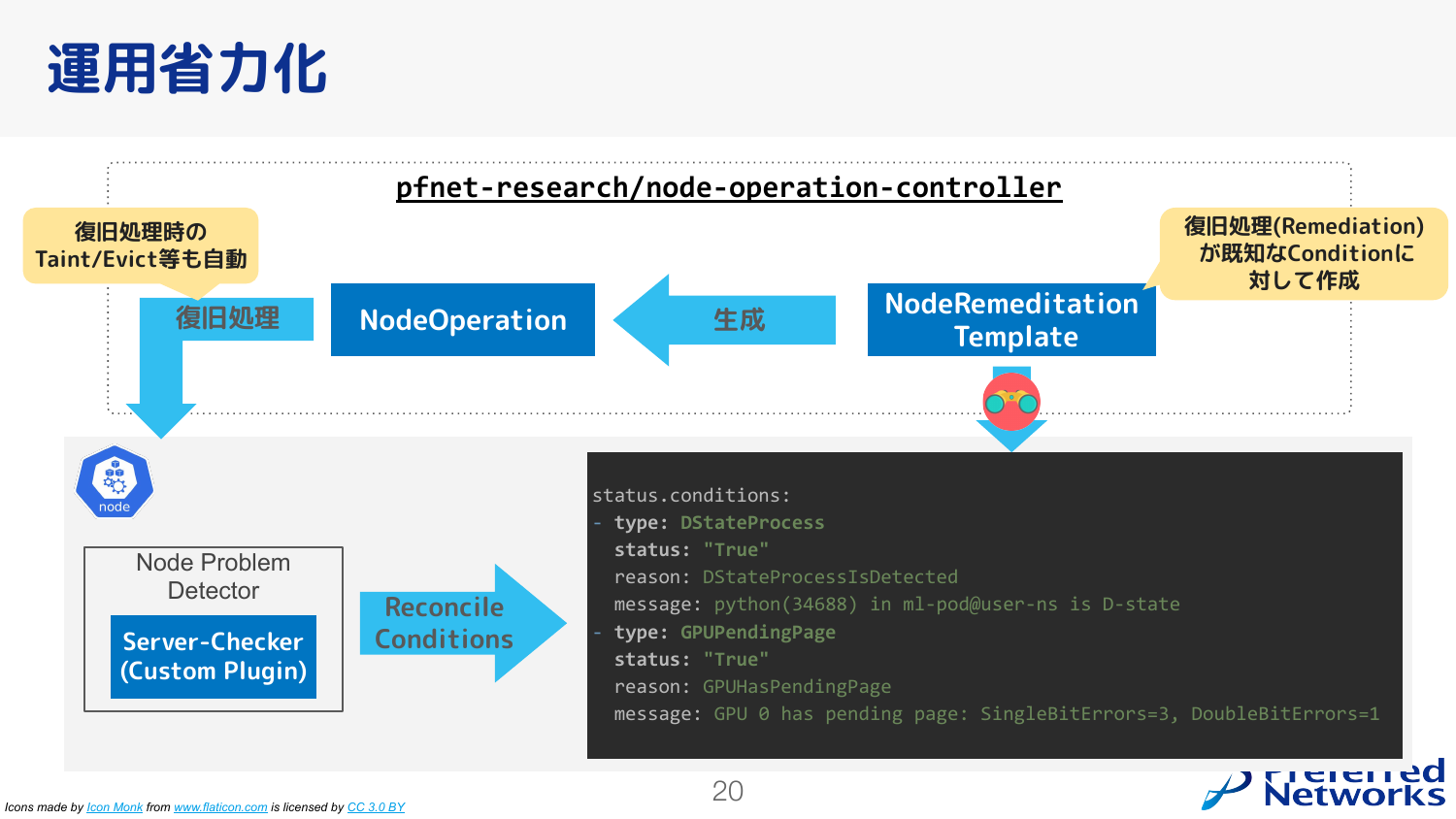
運用省力化の面でも自動化を進めています。例えばよくあるノード障害の例としては、GPUのメモリエラーが発生するとか、プロセスがD-stateになって終了できなくなる、などがあります。 このような場合は、ノードのステータスを更新して、それに対する解決策がわかっている場合はそれを自動的に実施する、ということが行われています。
クラスタに関わる組織
クラスタに関わる組織について説明します。
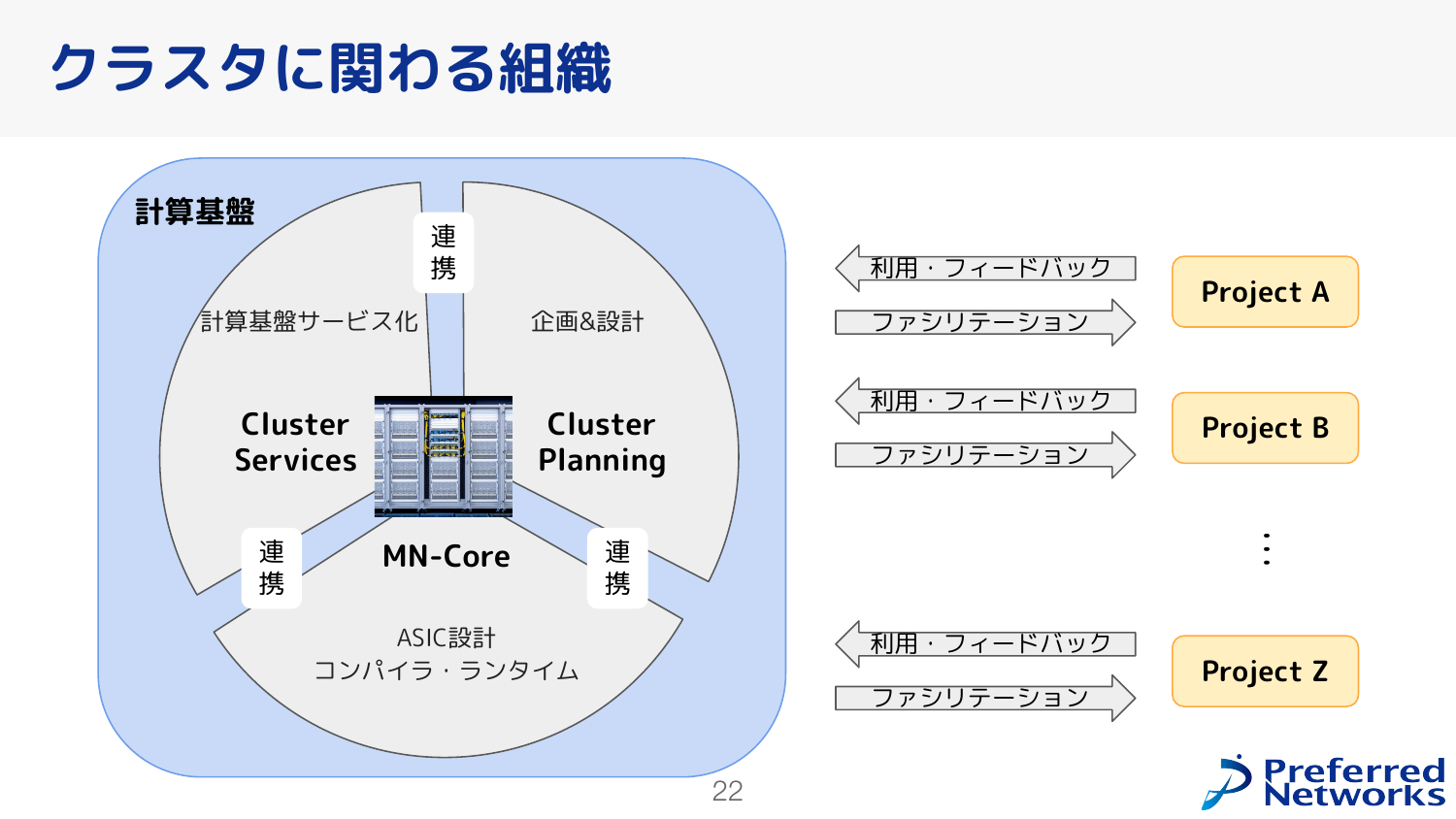
ざっくり、クラスタに関わる組織は3つあり、計算基盤のサービス化を行うCluster Servicesチーム、計算基盤の企画と設計を行うCluster Planningチーム、計算基盤に搭載するチップやコンパイラ・ランタイムを開発するChipチームがあります。 また、社内の計算機を使うチームとの連携も密にとっていて、各チームにあらかじめCluster Serviceチームのメンバを割り当てて、利用する中で出た問題や困りごとなどを聞いて改善をしていく、というような活動も行っています。
さいごに
本記事では、「オンプレML基盤 on Kubernetes #1」のPFNパートについてざっくりまとめて、2022年のPFNの機械学習基盤について紹介しました。 「オンプレML基盤 on Kubernetes #2」も新しい情報を盛り込んで 8/29 に開催しますので、ぜひ参加登録をお願いします。
また、上野が所属するCluster Servicesチームは こちら 、Cluster Planningチームは こちら で採用を行っています。 PFNの競争力を支える機械学習基盤を上から下まで一気通貫して開発・運用したい方のご応募をお待ちしております。カジュアル面談も行っていますので、お気軽にご連絡ください。
参考文献
- [1]: Akiba, et al., “Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes”
- [2]: 分散深層学習を支える技術:AllReduceアルゴリズム – https://tech.preferred.jp/ja/blog/prototype-allreduce-library/
- [3]: PFNの深層学習用スーパーコンピュータMN-3、39.38GFlops/Wの電力効率を記録しGreen500ランキングで3度目の世界1位を獲得 – https://www.preferred.jp/ja/news/pr20211116/
- [4]: GPUDirect RDMA :: CUDA Toolkit Documentation – https://docs.nvidia.com/cuda/gpudirect-rdma/index.html
Area
