Blog
MN-Coreコンパイラを用いた深層学習ワークロードの高速化
Hiroya Kaneko
はじめに
深層学習を軸とした研究開発には大きな計算資源が必要です。
PFNでは深層学習ワークロードに特化した計算機資源として深層学習用アクセラレータであるMN-Coreを開発し、実際に弊社のスーパーコンピュータであるMN-3に搭載し運用を行っています。本記事では、MN-Coreを利用した深層学習ワークロード高速化のためのコンパイラの概要及び、ワークロード高速化の実例について紹介します。
MN-Coreの概要とコンパイラの必要性
MN-Core(https://www.preferred.jp/ja/projects/mn-core/)とは深層学習ワークロードに特化したアクセラレータです。深層学習において頻出する畳み込み演算を高速化するために、多数の高効率な行列演算器ユニットを階層的に束ねた構造を持っています。各階層間においては縮約/放送など深層学習ワークロードでよく用いられる集団通信を行うことができます。
MN-Coreはアーキテクチャの観点では以下の特徴を持っています。
- 単一の命令で全ての計算ユニットを動作させるSIMD(Single Instruction Multiple Data)モデルのアーキテクチャを採用していること
- 一般的なプロセッサではハードウェアが自動的に制御するキャッシュや各演算器間のデータパスなどをプログラマが陽に制御可能であること
これらMN-Coreが持つアーキテクチャ上の特徴によって、MN-Coreでは一般的な他プロセッサに対して非常に多くの演算器を単一のチップに集積することに成功し、結果として圧倒的な理論性能を実現しています。
一方、大きなSIMDでかつ、HWによって制御される領域が少ないアーキテクチャであることは、適切に制御を行うことで非常に高い効率を実現できる反面、高効率に利用するためにはプログラマが考えるべきことが多いことを示します。
様々なワークロードが存在するPFNにおいては、全ての開発者がMN-Coreのアーキテクチャを理解した上で個別に性能を引き出すためのエンジニアリングをすることは現実的ではありません。そのため、我々はMN-Coreを簡単かつ高効率に利用するためのコンパイラの開発を進めてきました。
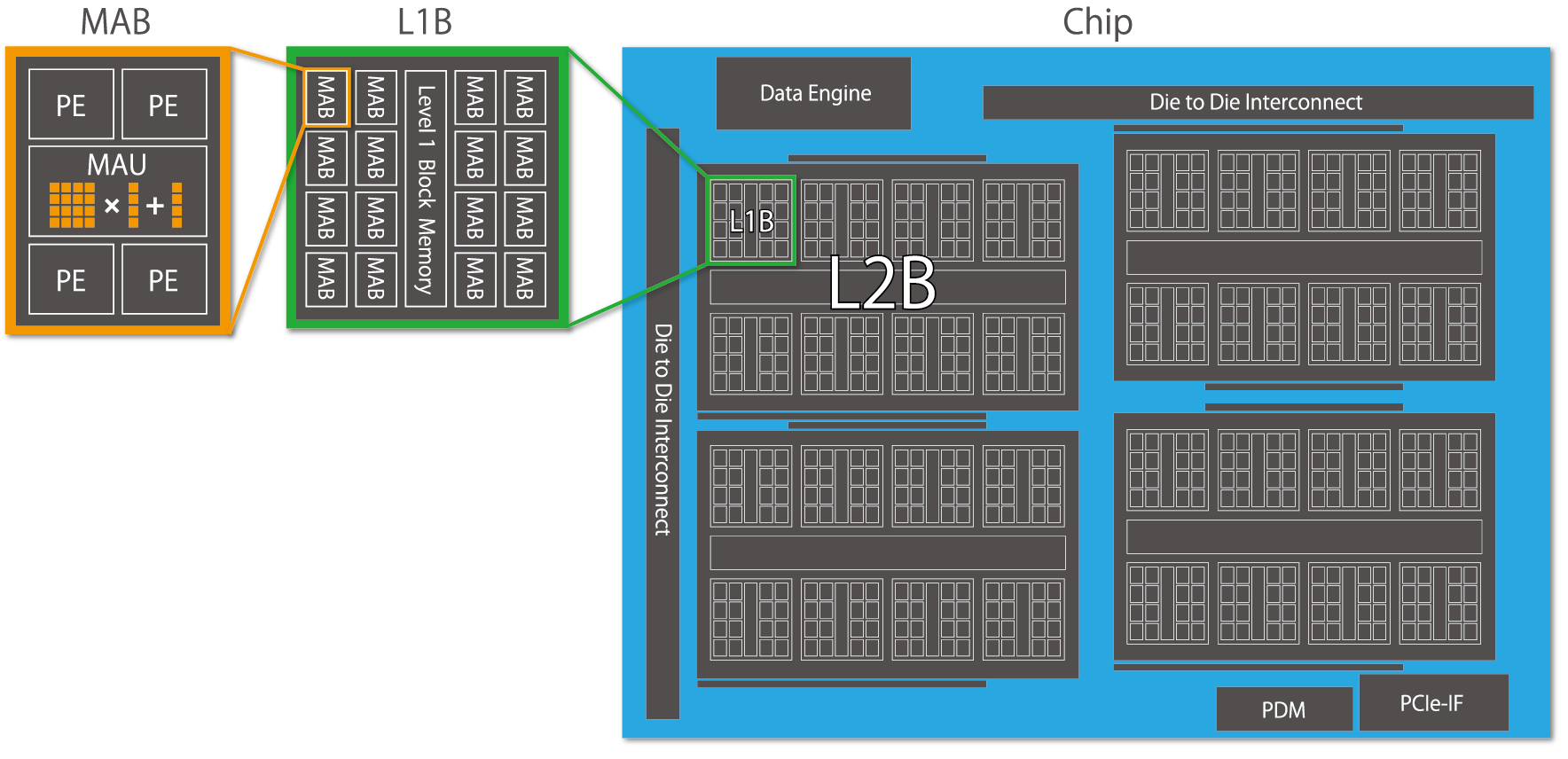
Fig.1 MN-Core Overview
MN-Coreコンパイラの構成
図2に現在開発を行っているMN-Coreコンパイラの構成を示します。
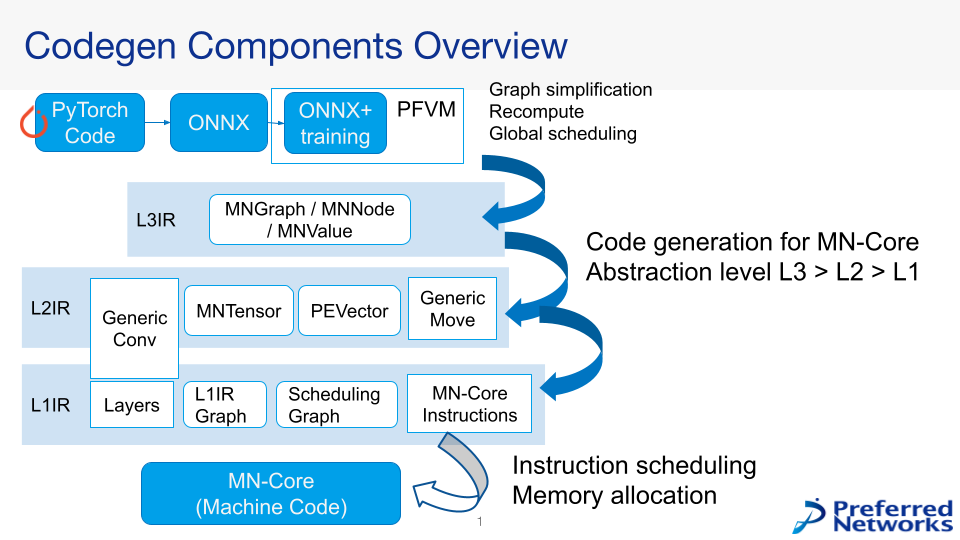
Fig.2 MN-Core Compiler Overview
設計にあたっては以下二点について注意を払いました。
- ユーザコードの大きな改変を可能な限り減らすこと
- MN-Coreの性能を活かしきること
1つめはユーザコードの大きな改変を可能な限り減らすことです。
現在PFNでは、多くのユーザが深層学習のためのフレームワークとしてPyTorchを利用し、アクセラレータとしてGPUを用いて研究開発を行っています。多くの研究開発資産がPyTorchを基盤としているため、MN-Coreを利用する上でも可能な限り既存のPyTorchコードに対して改変が少ないことが求められます。
これを満たすため、私達はMN-Coreコンパイラの入力としてフレームワーク非依存な深層学習モデルの表現形式としてONNXを採用しました。ONNXを利用することで、既存のコードに対するMN-Core対応の書き換えを最小限に抑えることができます(現実的にはいくつかの制約を満たしたONNXにexport可能であることを要請することになります)。
また、実際のワークロードをMN-Core上で動かすにあたっては、学習の計算カーネルが流れること以外にもデータの適切な供給や学習の進行状態の監視などの種々の機能が必要です。これら必要な機能の実装の手間を減らす観点で、GPUやMN-Coreを含む様々なアクセラレータで同一の学習コードを実行可能にするTrainerフレームワークの開発も並行して実施しています。Trainerフレームワークは将来的にpytorch-pfn-extras(https://github.com/pfnet/pytorch-pfn-extras)の一部として提供される予定です。
2つめはMN-Coreの性能を活かしきることです。
MN-Coreは非常に大きなSIMDプロセッサであるため、その性能を引き出すためには各演算コアに対して適切にデータを供給し続けることが非常に重要です。MN-Coreは演算器が階層化され、かつ各階層間の転送パターンに一定の制約が存在するため、高い性能を発揮させるためには必要な計算をどのように各計算ユニットにマッピングするのかを注意深く検討する必要があります。一方、マッピングの方針自体には多くの自由度があり、全てのコンパイラ開発者が大域的な計算のスケジューリングや各階層間のデータ移動パターン/レイアウトを適切に管理することは困難です。そのため、MN-Coreコンパイラでは問題を抽象度に応じて分割し、コンポーネント単位での改善を行いやすい構造をとっています。例えば図2中のL3IRと呼ばれるレイヤや主にONNXグラフから得られる情報から大域的なレイアウトや再計算戦略などの検討を行う一方、具体的なレイヤ内の演算順序については関知しません。一方、図2中のLayerやGeneric Convと呼ばれるコンポーネントは、ONNXにおけるop単位の計算手順に関する定義付けを行いますが、大域的な戦略については基本的には関知しません。このように問題の分割を適切に進めると同時に、共通的に利用されるコンポーネント/抽象化レイヤ(ex. numpy-like tensor for MN-Core)を注意深く設計することで、開発効率とMN-Coreでの高い実行効率を両立しています。
MN-Coreを用いた深層学習ワークロードの性能評価
本節ではMN-Coreコンパイラの深層学習ワークロードへの適用ついて一例を紹介します。
ここに示す全ての評価は、注記がない限り以下の条件で計測を行っています
- 実行速度の比較においては、弊社のプライベートスパコンであるMN-2(GPU搭載)と、MN-3a(MN-Core搭載)の双方で、それぞれ1アクセラレータボードを利用した場合の実機での実行速度を比較
- MN-Coreについては、前述のMN-Coreコンパイラを利用した実行コードの生成を行った
以降、以下のワークロードについて紹介します。
- CNNベースのモデルによるInstance Segmentation / Object Detection
- GCNベースのモデルによる物理シミュレーション
- Neural Architecture Search(NAS)への活用
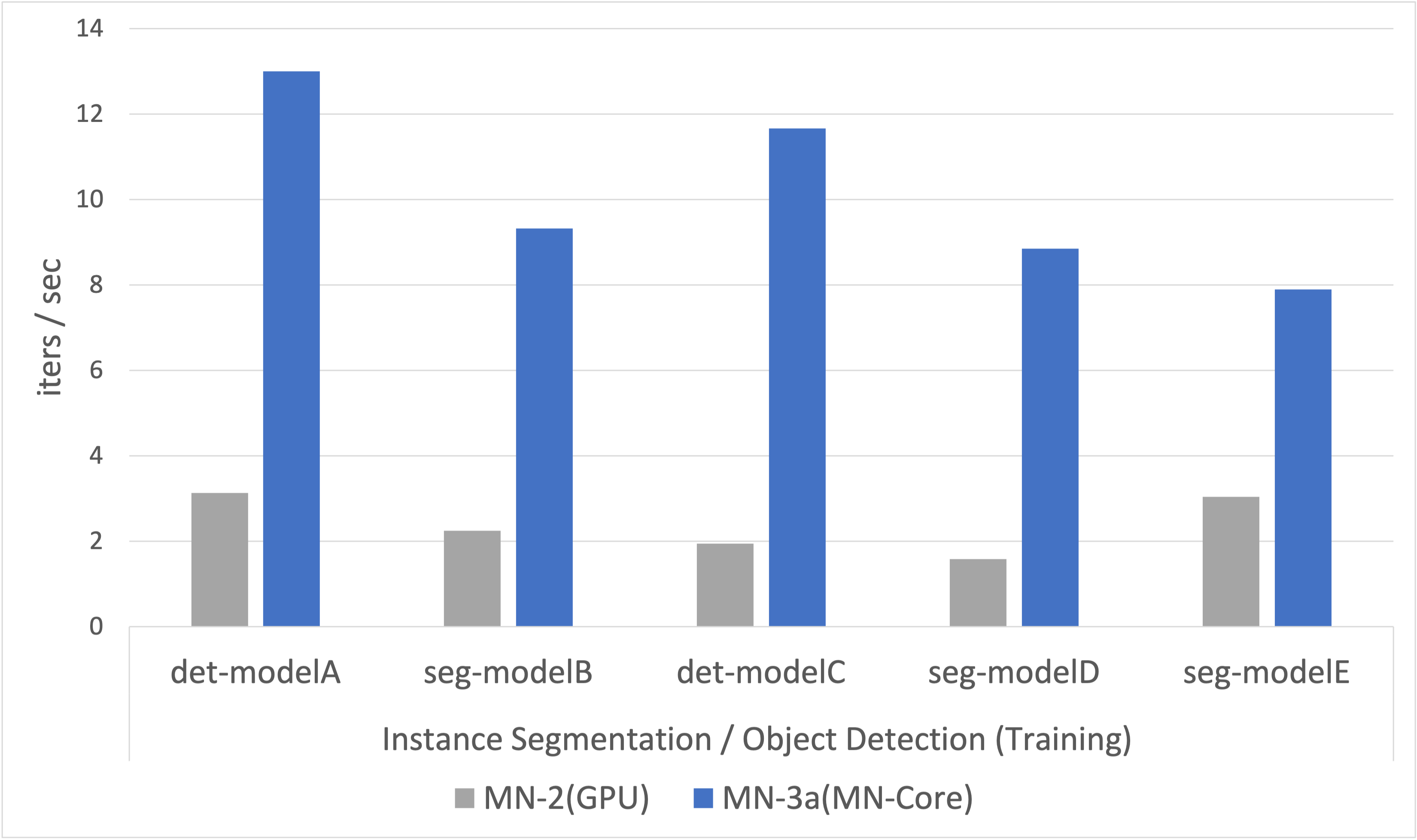
Fig.3 Performance evaluation (instance Segmentation / Object Detection, MN2 vs MN3)
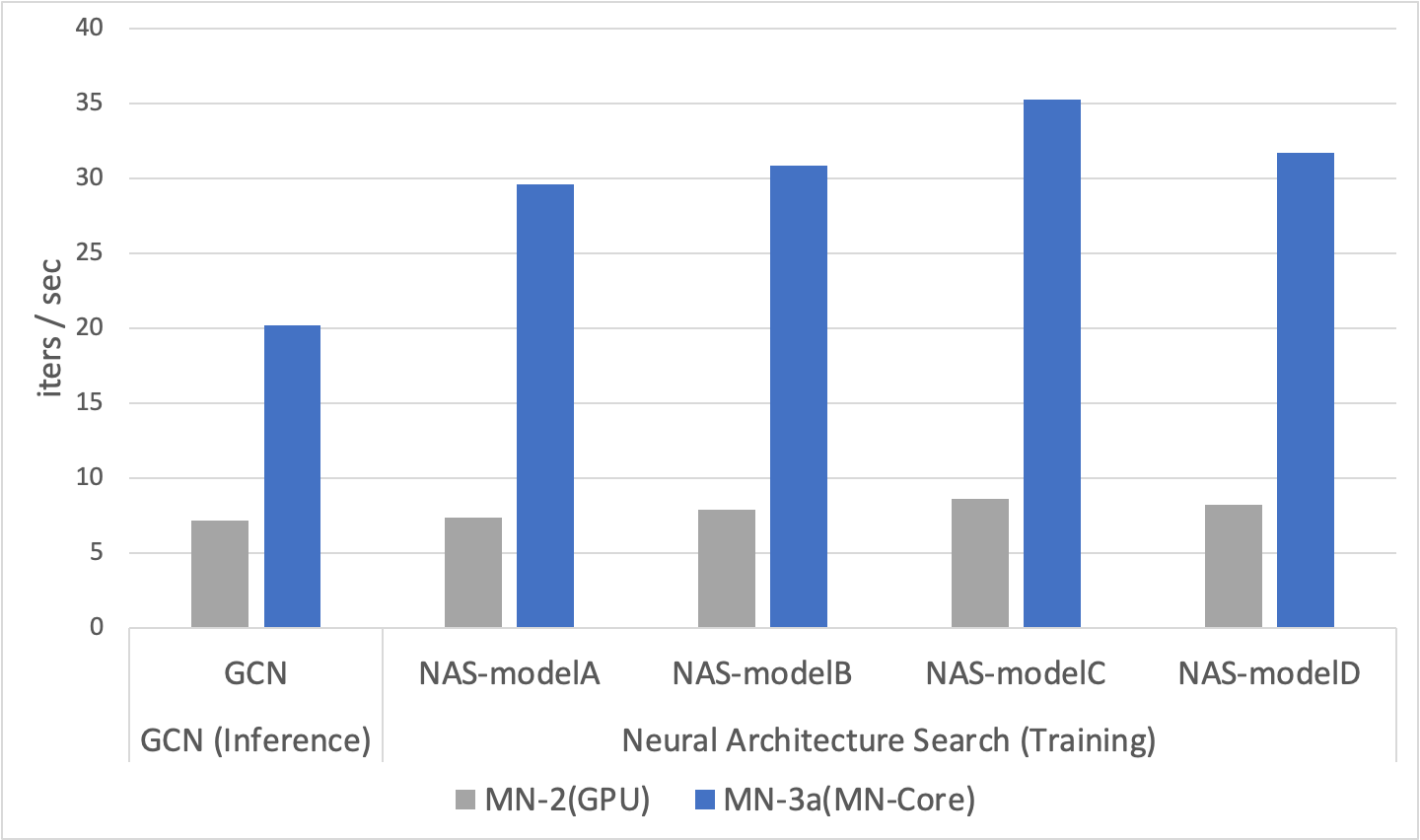
Fig.4 Performance Evaluation (GCN + NAS, MN2 vs MN-3a)
CNNベースのモデルによるInstance Segmentation / Object Detection
深層学習の典型的な適用分野としてCV(Computer Vision)があります。
CV分野において代表的な問題である、Instance Segmentation / Object Detectionを行うためのモデル学習の1iterationに要する時間を計測したデータを図3に示します。それぞれのモデルはPFN社内でベンチマークとして利用されているモデルであり、モデルの詳細については記載していませんがそれぞれCNNベースのモデルです。
図3を見ると、MN-Coreを用いることでInstance Segmentation / Object Detectionの学習速度を既存インフラに対して最大6倍程度の高速化を実現していることがわかります。ネットワークの構造や必要とされるレイヤの種別、実験の設定などによって上下はありますが、平均的にMN-Coreを利用することで既存インフラと比較して高速に学習プロセスを進めることができることが示されています。
また、詳細な評価は行っていませんが、Instance Segmentation / Object Detectionモデルの学習を十分高速に実行するためのコードが生成できることは、より簡易な問題設定とされるSemantic SegmentationやImage ClassificationなどのCVワークロードも同様にMN-Coreで実行可能であることを示しています。
GCNベースのモデルによる物理シミュレーション
次に示す例はGraph Convolutional Network(GCN)と呼ばれるモデルに関する高速化事例です。
GCNはグラフ構造に対する畳み込みであるGraph Convolutionを計算に用いるネットワークであり、グラフで表現可能な構造を深層学習で扱う際に広く用いられている手法です。PFN社内では物理シミュレーションなどのいくつかの応用に対してGCNが利用されています。本評価では一例として、GCNベースのネットワークを用いた物理シミュレーションにおける推論速度をMN-Coreで評価しました。その結果を図4左に示します。
図4左によると、MN-Coreを用いることでGCNの推論速度を既存インフラに対して3倍程度高速化できることがわかります。今回評価を行ったGCNベースの物理シミュレーションでは、しばしば推論で微分値が必要になるために推論プロセスにおいても誤差逆伝播が必要であり、かつ多くの非連続的なメモリアクセスが発生するなどCNNとは特徴が大きく異なる計算が必要とされますが、CNN同様にMN-Coreコンパイラを用いることでMN-Coreを用いたワークロードの高速化が実現できることがわかります。
Neural Architecture Search(NAS)への適用
最後に示す例は、Neural Architecture Search(NAS) への活用です 。
Neural Architecture Searchとは、深層学習モデルを設計するための一手法で、単純な精度だけでなく、推論速度やメモリ使用量などの様々な実運用の際に重要となる特性を加味した上で、トレードオフの取れたモデルを半自動的に探索する手法です。(NASの詳細については弊社ブログ – https://tech.preferred.jp/ja/blog/nas-semseg/ を参照)
NASを用いて適切なネットワークを探索するプロセスでは、NASで定義されている探索空間に従って生成された複数のパラメータの異なるモデルの学習を大量に実施する必要があります。そのため、コンパイラには特定のパラメータに向けたチューニングでは実現不能な、各種パラメータに対するロバスト性が求められます。
今回、MN-Coreコンパイラの一評価として、MobileNetV2ベースのネットワークに対する精度/Latencyを両立するアーキテクチャの探索ワークロードをMN-Core向けに移植しGPUを用いた場合と同様にアーキテクチャの探索が実行できることを確認しました。また、パレートフロント上にあるいくつかの探索されたアーキテクチャに対して性能測定を行った結果を図4右に示します。図4右によると、実用的なNASワークロードで探索された、Inferenceデバイス向けのモデルの学習においても、MN-Coreは既存インフラに対して平均で4倍程度の高速化を実現できていることがわかります。
おわりに
本記事では、MN-Coreを利用した深層学習ワークロード高速化のためのコンパイラの概要及び、ワークロード高速化の実例について紹介しました。現時点でコンパイラはまだ開発途上ですが、開発及び実用を進めている現時点においても、MN-Coreを用いることでCNNやGCNなどの多様なワークロードの高速化を汎用的な手法によって実際に実現できることがわかりつつあります。
今後もPFNではMN-Coreコンパイラの開発を精力的に進め、研究開発を加速させていきます。



