Blog
Preferred Networks エンジニアの坂田です。普段は社内向けの GPU サーバークラスタの運用管理の業務などをやっております。
先日、DevOpsDays Tokyo 2021 というイベントで、弊社 須田と一緒に PFN が Kubernetes を使って GPU クラスタを運用する中で経験してきた障害とその対応の自動化や、Kubernetes クラスタそのものの管理・アップグレードの自動化の取り組みについてご紹介しました。
SlideShare: PFNのML/DL基盤を支えるKubernetesにおける自動化 / DevOpsDays Tokyo 2021
本エントリでは、その中でご紹介した障害の事例の中から、コーナーケースとして対応に悩まされた Uninterruptible Sleep という状態に入ったプロセスの扱いについてご紹介します。
はじめに
PFN のクラスタでは「現実世界を計算可能にする」という目標のもと、機械学習を始めとしたさまざまなワークロードが日々稼働しています。これらのワークロードは、GPU はもちろん、CPU、ストレージ、ネットワークなどのさまざまなハードウェアリソースを活用して計算を行っています。
一般的に計算資源としてのハードウェアは、何らかの入力に対して出力を返してくるものと捉えることができますが、それは即座に返ってくるものではなく、一定の時間を必要とします。そして、ハードウェアからの応答に時間がかかる場合、プロセスはスリープ状態に入って待機することがあります。Linux におけるこうしたスリープ状態には、Interruptible と Uninterruptible という異なる種類が存在します。
今回取り上げる後者の Uninterruptible Sleep ですが、それ自体が問題というわけではありません。ただ、この状態になったプロセスの取り扱いに注意しないと、Kubernetes 上の GPU といったハードウェアリソースの管理に不整合が生じ、例えばリソースとして空いているはずの GPU をなぜかユーザーが利用できないといった問題が起きることがあります。以下ではこのスリープ状態と、Kubernetes を使っている上で問題となりうること、PFN での対応について説明します。
Interruptible Sleep と Uninterruptible Sleep
Interruptible Sleep と Uninterruptible Sleep の違いは、その名前の通り、スリープ状態が割り込み可能か不可能かという点にあります。ここでの割り込みとは、例えば SIGTERM や SIGKILL といったシグナルによるプロセスへの割り込みのことを指します。
この Uninterruptible Sleep は、例えば Linux の ps コマンドでプロセスの状態を見た時に ‘D‘ という文字であらわされるものです。このスリープ状態に入るには、OS やカーネルドライバーなど何らかのカーネルコードで、プロセスの状態に TASK_UNINTERRUPTIBLE をセットする必要があります。また、スリープから復帰する場合も、同じくカーネルコードでの明示的なスリープからの解放(Wake Up)が必要です。このような割り込み不可のスリープ状態のメリットは、例えばディスクの I/O などの処理の間、割り込みを受け付けないことでドライバーやアプリケーションのロジックをシンプルにしやすい点があります。
Uninterruptible Sleep の困る点
この Uninterruptible Sleep は、短時間で抜けるのであれば、発生すること自体は特に問題ではありません。しかし、もしこの状態が予期せず長く続く場合、どのように対応するのがよいか判断に困ることがあります。
例えば、正常な待機だとしても、いつまで待てばよいか判断するのは簡単ではありません。ハードウェアの故障やドライバーの不具合など、何らかの原因により待機が異常に長くなっている場合でも、その原因が外からは分かりにくいことがあります。また、Uninterruptible Sleep に入ってしまうと SIGKILL でもプロセスを中断できないため、途中で処理をあきらめてそのプロセスだけを終了したい場合でも、OS 自体の再起動が必要になってしまいます。
さらに、PFN のように Kubernetes を使ってクラスタを管理している場合、Uninterruptible Sleep に入ったプロセスのいる Pod を削除しようとしても、SIGKILL でもプロセスが終了しないため、Pod が “Terminating” と呼ばれる終了中の状態になったまま残り続けます。Kubernetes では、そのような状態の Pod でも、実体のプロセスやコンテナの削除を待たずに、強制的に Pod のリソースだけを削除することも可能です。より具体的には、Kubernetes では Pod のような Kubernetes 特有のオブジェクトの情報を、etcd と呼ばれる分散 Key-Value ストアを使って管理していますが、この強制削除では実際にホスト上で動いているプロセスやコンテナの状態は無視して、この etcd 上から Pod に関連する情報の削除だけを行います。ただ、このように Pod が強制削除されると、問題のプロセスが Kubernetes の管理から切り離されてしまいます。結果的に、管理できない問題のプロセスだけが取り残されてしまうため、この点も注意を要します。
実際、PFN で利用しているクラスタ全体で Uninterruptible Sleep に入っているプロセスの数をモニタリングしてみると、一時的なものも多く含まれているとは思いますが、常に一定数存在しています。
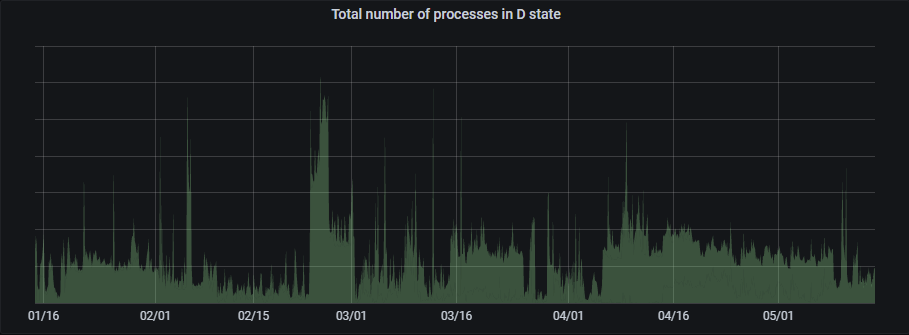
図:PFN クラスタ全体における Uninterruptible Sleep に入っているプロセス数
これらのプロセスすべてに問題があるわけではありません。しかし、例えば GPU を利用していたプロセスが Uninterruptible Sleep になったままとなり、さらに Pod が強制的に削除されてしまった場合、Kubernetes 上はこの GPU リソースは空いていると判断されてしまいます。そうなると、次の Pod に同じ GPU が割り当てられてしまい、実際に利用しようとすると、先の問題のプロセスにより GPU が利用中のためエラーが発生してしまうという問題が起こりえます。実際、社内のユーザーからこの問題の発生について何度か報告を受けたことがありました。
PFN での対応
上記のようなプロセスは、待っていれば解消されるものもありますし、全てが悪いわけではありません。ただ、ユーザーの意図に反して異常に長く続く場合や、Pod が削除されてしまうなどして Kubernetes の管理から外れてしまった場合には何らかの対応が必要です。そこで PFN のクラスタでは、以下のような対応を行っています。
- Pod の強制削除の禁止
- Node Problem Detector によるプロセスの監視と Node Operation Controller を使った Remediation による自動復旧
1 のPod の強制削除の禁止ですが、不用意な Pod の強制削除は、問題のあるプロセスを Kubernetes の管理から切り離すことになり、プロセスが使っていたリソースが解放されたと誤って認識されてしまうことでさらに状況が悪化します。そのため、社内のユーザーにはできるだけ行わないよう呼びかけるとともに、管理者による設定等でユーザーによる強制削除自体ができないような仕組みの導入も検討中です。
2 の Node Problem Detector によるプロセスの監視による対応については、すべての Uninterruptible Sleep に入っているプロセスが悪いわけではなく、ユーザーとしても処理を待っているだけというパターンもあるため、すぐさま OS の再起動などの対応が必要かの判断が難しい所です。そこで、今のところ PFN では、少なくとも Pod が削除されておらず、Kubernetes の管理下にある場合は、ユーザーが意図的に待機しているものとみなして静観しています。しかし、その後ユーザーにより Pod の削除が試みられた場合には、意図しない問題のある Uninterruptible Sleep であると判断し、OS の再起動などの復旧処理を行います。この時、どのプロセスがどの Pod、コンテナに紐づくのかを、OS や Kubernetes、Docker の API から取得した情報をもとに、プロセスがユーザーのワークロードに関連づくものかを判断しています。ただ、完全に Pod が削除されてしまった場合、プロセスを Pod、コンテナに結びつける情報が失われてしまうため、完全に問題を解消できない場合もあります。
なお、上記の判断とは別に、問題を検知した後の OS 再起動といった復旧作業の自動化のために使っているツールや仕組みについては、冒頭で紹介した DevOpsDays Tokyo 2021 で使ったスライドで説明していますので、ご興味のある方はそちらも見ていただければと思います。
おわりに
本エントリでご紹介した Uninterruptible Sleep に潜在する問題は既に認識されており、SIGKILL といった重要なシグナルであれば、割り込み可能とする TASK_KILLABLE というスリープ状態が Linux kernel 2.6.25 から導入されています。TASK_KILLABLE であれば、SIGKILL を受け付けた時にクリーンアップ処理も適切に行うことで、ハードウェアやドライバーなどの異常が発生した場合も、OS 全体を再起動することなく、影響範囲をより軽減できる可能性があります。実際、NFS client などでも導入されているようです。[1]
ただ、先にご紹介した PFN のクラスタで発生している Uninterruptible Sleep のプロセスの数を見てもわかるように、このスリープ状態はドライバーなどを含めてカーネルコードのさまざまなところで使われているようです。そのため、こうした問題の発生は依然として避けて通れないものとして、PFN では上記でご紹介したような対策は続けていく必要があると考えています。
リンク
Area
