Blog
本記事は、2025年夏季インターンシッププログラムで勤務された中島光人さんによる寄稿です。
はじめに
初めまして。2025年度の夏季インターンシップに参加した、東京大学情報理工学系研究科修士1年の中島光人と申します。大学院では主に自然言語処理に関する研究を行っています。
インターンシップでは、PFNが提供しているゲーム『Omega Crafter』において、AI Agentを用いて新たなゲーム体験を創出することに取り組みました。本記事ではその内容について説明します。
概要
- Omega Crafterにおいて、タスクを自動でこなすエージェントの実行精度の改善に取り組みました
- Omega Crafterのキャラクターであるグラミーに対して自然言語での指示を行うことにより、複数のグラミーがコミュニケーションを行いながら協力してタスクを行ってくれる仕組みを構築しました
背景
Omega Crafter とは
『Omega Crafter』は、オープンワールドのサバイバルクラフトゲームです。グラミーと呼ばれる相棒と共に街を作り上げたり、素材集めとクラフトを行って強力な武器を作ったり、敵と戦いながら世界を探索・冒険したり、といった点が魅力になっています。
グラミーにはプログラム(コードブロックを組み合わせるタイプ)をセットすることができ、それを実行することでグラミーを用いた自動化を行うことができます。例えば、Omega Crafter では加工台という設備を用いて木材から板を作ることができますが、それを行うプログラムをグラミーにセット・実行することで、たくさんの板を自動で作らせることができます。また便利なコードテンプレートが用意されており、それを使うだけでも様々な自動化を行うことができます。
本インターンシップでは、こうした Omega Crafter の魅力を生かした形で AI Agent を導入することを目指しました。

VoyagerとVoyager@OmegaCrafter
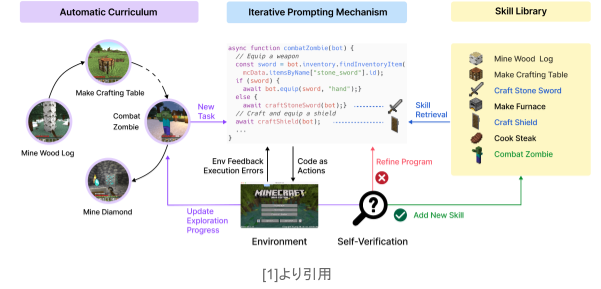
本インターンシップの内容に大きくかかわる先行研究として、”Voyager: An Open-Ended Embodied Agent with Large Language Models” [1] という研究(以下 Voyager)を紹介します。Voyagerは、ゲーム『Minecraft』において、世界の探索や多様なスキルの習得、そして新たな発見を継続的に行うような自律エージェントで、大規模言語モデル(LLM)をいくつかの形で用いています。
Voyagerは、主に以下の3つの要素から成り立っています。
- 探索を最大化するための自動カリキュラム
- 複雑な処理をコードの形で保存・再取得できるスキルライブラリ
- 環境からのフィードバックや実行エラー、プログラムの自己検証を導入した、反復的なプロンプトメカニズム
論文では、こうした要素によってエージェントが生涯的に高度な学習能力を示し、卓越した習熟度を達成したということが示されています。
PFNではOmega Crafterを自動でプレイするAIエージェントを開発しています。VoyagerはMinecraftにおける自律エージェントですが、MinecraftとOmega Crafterとの間には多くの共通点があることから、OmegaCrafterにVoyagerを適用できるのではないかと考えられました。本インターンシップは開発しているVoyager@OmegaCrafterを利用する形で取り組みました。
取り組んだこと
私は「AI Agentを用いた新たなゲーム体験の創出」を目指して、次の目標を立てました。
自然言語による指示を与えると、複数のグラミーがお互いにコミュニケーションを取りながら協力してタスクをこなしてくれるようにする
この目標に向けて取り組むための前提条件として、LLMが何らかの形でOmegaCrafter内のグラミーを直接操作できるようになっている必要があります。その1つがOmegaCrafterのAPIを使うことですが、インターンシップ期間の開始時点ではグラミーを操作するためのAPIは未実装でした。
そこで、インターンシップの前半では少し異なる内容に取り組みました。以下では、期間の前半と後半に分けて内容を説明していきます。
なお、実験で使用したLLMはいずれもGPT-5-miniです。
インターンシップ前半: Voyager@OmegaCrafter の改善
先ほども述べたように、最終的な目標は自然言語によるグラミーの操作ですが、前半では自然言語でプレイヤーのアバターを操作することに取り組みました(プレイヤー操作のAPIはこの時点で実装済みでした)。
Voyagerは自律的に探索しながらゲームをプレイするエージェントに関する研究ですが、その要素は自然言語で与えられたタスクを実施するエージェントにも応用できます。そういった観点からVoyager@OmegaCrafterに関する改善を実施しました。
複雑なタスクに対するコード生成
自然言語で与えられたタスクを実施するにあたり、最も重要で精度が必要となるのはスキルの生成です。スキルとは、ゲームワールドでキャラクターを操作するためのコードのことです。Voyagerでは、自然言語で与えられたタスク(カリキュラムから取得)を実行するために関数コードを生成し、それをスキルとして保持・実行します。このコード生成を行うコンポーネントをAction Agentと呼びます。
Omega Crafterにおけるタスクとしては、簡単なものだと「石を拾ってくる」「木を伐採する」などが挙げられます。
まず私は、Omega Crafterにおいて、どのようなタスクが与えられたときにAction Agentがどのようなコードを生成するのかということに着目し実験を行いました。すると、ある程度複雑なタスクを指示した際にはコード生成がなかなか上手くいかないということがわかりました。
例えば、「グラミーに銅鉱石と木材から銅の槍をクラフトさせる」というタスクを考えます。銅鉱石からは銅インゴット、木材からは板がクラフトでき、それらを組み合わせると銅の槍がクラフトできます(下の図を参照)。
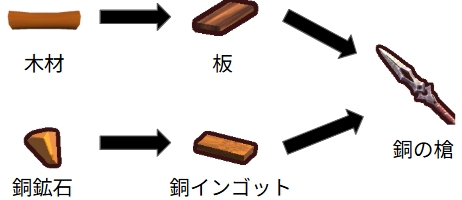
よって全部で3種類のクラフト作業が必要で、3体のグラミーにクラフトを実施させれば良いです(グラミーを直接操作するAPIを使わなくても、グラミーのコードテンプレートをセットするというプレイヤー側のAPIを使えば達成できます)。一見、簡単なことのように見えるかもしれませんが、より細かく見ると、「銅鉱石や木材といった素材がどのコンテナにあるのか」「中間素材としての銅インゴットや板をどのコンテナに貯めておくのか」といったようなことを全体として一貫した形で定めなければなりません。
このような複雑なタスクを実行するようなコードをAction Agentに書かせようとしても、完璧なコードはなかなか生成されません。また、このような複雑なタスクを事前に細かいタスクに分解してそれらを1つずつ実行していく(サブタスク分解)、というような仕組みがVoyagerには存在しますが、これも素直には上手く行きません。
私は、なぜ上手く行かないのかということをより詳細に調査し、その改善を実施しました。主に3つの観点から取り組んだので、それらを順に紹介します。
問題点と改善1: スキル生成における引数の柔軟性
先ほども述べたように、スキルは関数の形でAction Agentが生成します。関数としてスキルライブラリに保存しておくことで、後から再利用しやすい形にするという意図があります。しかし、元々のVoyagerでは再利用しやすいとは言い難いスキルが生成されていました。
例えば、「木材が10個入ったコンテナを見つけて」というタスクに対して、次のような関数がAction Agentから生成されます。
def find_container_with_10_woods(bot):
containers = bot.get_containers()
for c in containers:
count = bot.check_count(c, “wood”)
if count >= 10:
return True, c[‘uuid’]
return False, None
引数にbotとありますが、これはOmegaCrafterのAPIを実行するための抽象化されたインターフェースです(例えば関数内の1行目にあるように、bot.get_containersというようにメソッドを呼び出すことでコンテナの一覧を取得できます)。この関数は確かに与えられたタスクを実施できるものになっていますが、再利用には非常に向いていないものになってしまっています。
実際、人間のプログラマであれば次のようなコードを書くでしょう。
def find_container_with_n_items(bot, n, item):
containers = bot.get_containers()
for c in containers:
count = bot.check_count(c, item)
if count >= n:
return True, c[‘uuid’]
return False, None
引数に必要な数nと対象のアイテム名itemを受け取るようにし、個数とアイテムによらず再利用できる関数になりました。なぜこのような関数をAction Agentが生成してくれないのかというと、実は元々のVoyagerでは生成する関数の引数はインターフェースである`bot`のみに制限されているという事情がありました。
そこで、まずAction Agentの生成する関数の引数をAction Agent自身が自由に設定できるようにし、かつ実行時にどのような引数を与えるのかもAction Agentに決定させるようにしました。このようにすることで、スキル生成における引数が柔軟になり、find_container_with_n_itemsのような汎用的な関数を生成させることができるようになりました。
問題点と改善2: タスク分解後の直列的なサブタスク実行の解消
先ほど少し触れましたが、複雑なタスクに対しては、それを一度に達成しようとする代わりに、細かいシンプルなサブタスクに分解して1つずつ順番に実行していくというアプローチがありえます。しかし、このアプローチはそのままでは上手く行かないケースがあります。
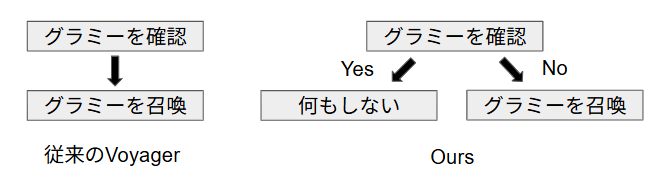
例えば(恣意的な例ですが)「グラミーがいなければ召喚する」というようなタスクを考えます。これをLLMにサブタスク分解させると、
- グラミーがいるか確認する
- グラミーを召喚する
のようになります。この分解結果に基づいて単に順番に実行していくと、グラミーがいるかいないかにかかわらずグラミーが召喚されてしまいます。これは明らかに「サブタスク分解」としては問題ありです。
つまり、最初にサブタスクに分解した後にそれらを直列に実行するだけでは、分岐的なワークフローを含むようなタスクを正しく実施できないということです。
そこで、サブタスク分解の枠組みにおいて、最初に得られたサブタスク分解とこれまでに実行したサブタスクの結果を逐次LLMに参照させ、動的に次に実行すべきサブタスクを選択させるようにしました。これにより、分岐が必要となるようなタスクに対しても対応できるようになりました。
問題点と改善3: 自己検証の限界を補完
Voyagerでの自己検証の仕組みにおいては、タスクの実行前後のインベントリなどの状況から、タスクが正しく実行できたかどうかが判断されます(この要素をCritic Agentと言います)。Critic Agentにより、Action Agentが生成したコードの正当性を実験的に確認し、またその結果からAction Agentにコードの修正を促すことができます。しかし、これは検証という意味では次のような2つの問題点があります。
- コードを1度実行しただけでは全体が正しいかどうかは判断できない(すべてのコードパスを通るとは限らない)
- 実際に実行して初めて正しいアクションかどうかが分かるので、内容によっては検証に時間がかかり、かつ失敗時にも環境への副作用が生じてしまう
そこで、これらの自己検証の欠点を補完するために、新たにCode Review Agentを導入しました。Code Review Agentは、Action Agentが生成したコードを実行前に精査し、事前に定めたコーディングルールを満たしているかを判断します(例. タスクを正しく実行するものであるか、汎用性のあるものになっているか)。

コードの誤りはその内容を読むことで判断できるものも多く、それらをCode Review Agentでコードの実行前に弾くことで上記で述べたような問題点を解決することを意図しています。このCode Review Agentのように、環境とのインタラクションを行う前に検証を行うような仕組みは先行研究でも提案されており、例えば[2]におけるReward Criticがこれに該当します。
もちろん、Action Agentが完璧でないのと同様に、Code Review Agentも完璧ではないため、既存の自己検証の仕組みと組み合わせることでより複雑なタスクもこなせるようにしています。
前半のまとめ
以上のように、実験から分かったいくつかの問題点について改善を行うことでOmega CrafterにおけるVoyagerでの自然言語タスクの実行精度を向上させました。実際、例として挙げた「グラミーに銅鉱石と木材から銅の槍をクラフトさせる」というタスクを自動で完遂させることができるようになりました。

インターンシップ後半: 自然言語によるグラミーの操作
グラミー操作のAPIが実装されて以降は、当初の目標であった「自然言語による指示を与えると、複数のグラミーがお互いにコミュニケーションを取りながら協力してタスクをこなしてくれるようにする」ということに取り組みました。
ここで考えるタスクは、前半で取り組んでいたようなものと同様、「木を伐採する」「石の斧をクラフトする」といったようなものになります。最初に説明したように、Omega Crafterにおいてはグラミーをコーディングすることによってタスクを自動化することができます。今回は、そのコードを手動で組み立てることなく、自然言語によって指示するだけでグラミーがそれに従って動いてくれることを目指して取り組みました。
シンプルな実装: GrammiAgent
今回やりたいことの要件を大雑把に分類すると次のようになります。
- グラミーが自然言語での指示に基づいてタスクを実行する
- グラミー同士がコミュニケーションを取る
- 複数のグラミーが同時に動作する
最終的な目標に向けて、最初はこれらのことを達成するための最低限のシステムを実装することにしました。このシステムの概要を説明していきます。
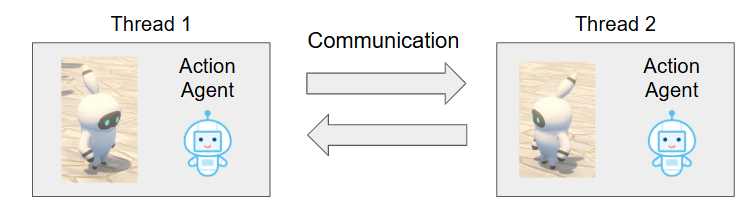
まず、グラミー用のAction Agent(前半の内容で触れたAction Agentとほとんど同様)を各グラミーごとに用意し、それらをマルチスレッドで同時に動かします。グラミーが10体いればスレッドを10個立てるというようなイメージです。Action Agentは、自然言語で与えられたタスクを実行する関数を生成するものであったため、これにより上記の要件の1と3は達成できます。
次に、グラミー専用のコミュニケーションチャネルを用意しておきます。このチャネルは各スレッドからアクセスでき、メッセージを読んだり書き込んだりできます(実装上は単なるメッセージの配列ですが、マルチスレッドでアクセスが同時に発生しても正しく動くようにロックを取ることが必要になります)。これで2も達成できることが分かります。
実験: 木の伐採・収穫
こうした仕組みを実装した上で、実験を行いました。
ここでは、まず1体適当に選んだグラミーにタスクを与え、そのグラミーを起点にグラミーたちがコミュニケーションを取る、というような形式を考えます。最初にタスクを与えられたグラミーは指示役のような役割を持つことになります。
まず、「木を育てて収穫を行うことを繰り返す」というような比較的シンプルなタスクを試しました。
しかし、プロンプトに少しでも曖昧性があるとなかなか上手くいかないことがわかりました。例えば”Repeatedly grow and harvest trees cooperating with other grammies”というような粒度のタスクをある1体のグラミーAに与えたとき、グラミーAが他のグラミーBやCなどに協力するための指示をしてくれる(=コミュニケーションをとってくれる)のですが、その指示があまり良いものではなく、協力に失敗するというようなことが多くありました。例えばグラミーみんなで木を切るばかりで、ドロップした木材を誰も集めない、などです。
そこで、まずは次のような非常に具体的な指示を与えたうえで実験を行うことにしました。
"Repeatedly grow and harvest trees. Specifically, find a group garden in city, harvest the trees growing in its fields. When no more trees can be harvested, find empty fields, plant dropped tree seeds in the fields, wait for the trees to grow, and then harvest them again. Repeat this process. Also, when you harvest trees, wood will drop, so have three three grammies find a single-type container that already contains some woods, and repeatedly pick up this wood and place it into the container. After instructing three grammies, you don't need to wait them completing the task. Continue your own task."
要約すると、「木を伐採して種を植えることを繰り返せ。他の3体のグラミーには落ちた木材を集めてコンテナに入れさせよ」というようなことを書いています。このレベルまで具体性を上げて自然言語の指示を行うことで、このタスクをグラミーたちに協力しながら行わせることができました。

これによって当初の目標は一応達成できたのですが、自分のイメージしていたものを比べるとまだまだ足りない部分がありました。ここからはそれらについて述べていきます。
問題点1: タスクを具体的に与えないと上手く行かない
先ほども述べたように、タスクはかなり具体的に与えないと実行精度は低いということがわかりました。
本来、自然言語で指示するとなれば、もっと抽象的な指示で済んで欲しいと考える人が多いのではないかと考えられます。(グラミーではなく)Omega Crafterを良くプレイしている人に代わりにやってもらうような場合であれば、やや抽象的であってもタスクを「いい感じに」こなしてくれるでしょう。現実社会の仕事においても、指示は常に上記のようなかなりの具体性を伴って行っているわけではないはずです。
では、私たちは普段どのようにタスクの曖昧性を解決しているのでしょうか。それは、コンテキストやノウハウを事前に十分に共有しておくことによります。したがって、本システムにおいて指示を具体的にしないと上手く行かないということは、AI Agentにそういった情報が渡せていないということであると推測できます。
失敗例からの考察
どういう情報を渡すべきかについてですが、抽象的な指示で上手くいかないような例から考えてみることにします。よく失敗していたタスクとして、例えば「石の斧を100個クラフトする」というものを考えます。
これを行うためには、素材となる石と木材を100個分用意して1つずつ加工台でクラフトする必要があります。よく陥っていた失敗ケースは、100個分の素材をグラミーたちが持ってきて、それらを一斉に加工台に置こうとするというようなものです。加工台は一度に一つ分しか受け付けないため、これでは上手く行きません。
ではどうするのかというと、そういった中間素材は一度コンテナに入れることになります。素材を持ってくるグラミーは一度そのコンテナに貯めておき、クラフトするグラミーはそこから1つずつ素材を取っていけば、スムーズに100個の石の斧をクラフトできます。
改善策
このようなOmega Crafterにおけるノウハウは、「言われてみれば簡単だが、自力で思いつくのは難しい」というものになります。「ではOmega Crafterにおけるプレイヤーはどのように学んでいるのか?」という疑問が生じることになりますが、実はそれに役立っているのがグラミーのコードテンプレートです。
コードテンプレートには、クラフトや伐採、採掘などの典型的な処理を上手に行うためのコードがいくつか含まれています。これらを元にプレイヤーがOmega Crafterのことを学ぶのであれば、AI Agentにとってもこれらが有用なのではないかと考えられます。
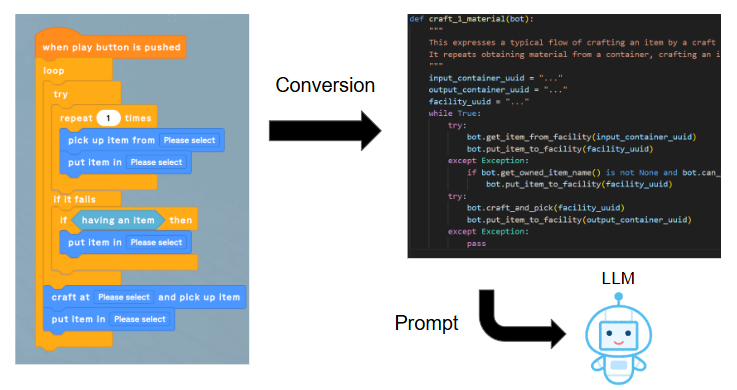
そういった考察から、それらのコードテンプレートをグラミーのAction Agentに例示として与えることにしました。まずコードテンプレートを表す内部データをダンプしたものをそのままプロンプトに与えてみましたが、LLMがそのデータ構造をあまり事前学習していないせいか、正しく理解できていませんでした(コードブロックの順番を間違えている、など)。そこで、元のコードテンプレートと同等のコードをPythonで記述(手書き)し、それをプロンプトに入れるように修正しました。これは[3]などで有効性が示されているような、いわゆるfew-shot promptingと呼ばれる手法になっており、精度を向上させるためには重要なプロンプト手法です。
その結果、曖昧性を持ったタスク指示でも「もっともらしい」やり方でそのタスクをこなしてくれるようになりました。例として、石の斧を3つクラフトするタスクを、
"Craft 3 stone axes using materials from mines or trees and empty containers"
というようにある程度簡単な形でグラミーAに与えても、他のグラミーB/Cと適切な作業分担を行った上で正しく実施してくれるようになりました(例. A: クラフトする係、B: 鉱山を掘って石を集める係、C: 木を切って木材を集める係)。作業分担をするというようなコードテンプレート自体は存在しませんが、各グラミーがタスクを実施する際にコードテンプレートを参照することで精度が上がり、全体として上手く行ったのではないかと考えられます。
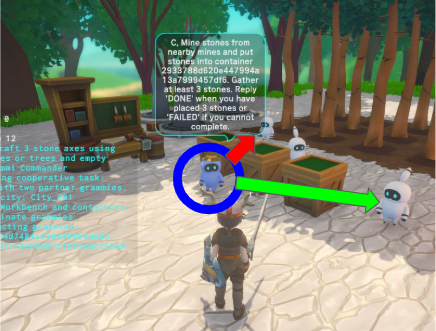

問題点2: タスクが成功するか否かが環境の状態に大きく左右される
今考えている実行形態は、改めてまとめると次のような形です。
- プレイヤーがあるグラミーAに指示をする
- グラミーAが他のグラミー(B, C, …)に指示をしながら自らもタスクをこなす
- 指示されたグラミーB, C, …は指示に従いタスクをこなす
実はここまでの仕組みだけでは、環境の状態によっては3でグラミーBなどがタスクの実行に失敗してしまい、そのまま諦めてしまうという問題が生じていました。
例えば、問題点1で触れたような「石の斧をクラフトする」というようなタスクにおいて、「木材を集めるために木を切って」と指示されたグラミーがいたとします。このグラミーはまず木を探すことになりますが、木がなかったときにどうすべきかまで指示されていないため、その場合においては単に諦めてしまいます(正確には、Action Agentが出力する関数の中で木の存在判定を行う箇所があり、もし存在しなかった場合にはreturnしてしまうようなものになっている)。
グラミーは指示された内容を(ある程度の曖昧さは自分で解決しながらも)忠実に実行してくれることを期待しているので、「指示をこなすための前提条件を環境が満たしていないときには諦める」というような挙動は正しいと言えます。
よって問題なのは、指示役となるグラミーがどのような指示を与えるかにあります。指示役は、環境で何らかの条件が成り立っているか否かにかかわらずタスクが正常に実行されるような指示を与えなければならない、ということになります。上記の例で言えば、「木を切って木材を集めてきて。もし木がないなら木の種を植えて育ててから切って」というような指示を与えるべきです。
しかしこれは非常に困難です。なぜなら、タスクに関係する条件をすべて把握した上で、すべての場合にも対応できるような指示を考える必要があるためで、指示役グラミーの負担が非常に大きいということになります。
Voyagerから得られるヒント
この問題を解決するためのヒントとなるのが、従来のVoyagerに存在するCritic Agentです。Critic Agentは、Action Agentが生成したコードの実行結果から、そのコードが与えられたタスクに対し有効なものだったかどうかを判断し、無効なものであれば問題点をAction Agentにフィードバックします。
VoyagerではこのCritic AgentとAction Agentが協力してプレイヤーの動作を決めていましたが、今回のように複数のグラミーが協力して動くという状況では、同様の仕組みを異なる形で当てはめることができそうです。即ち、指示役グラミーがCritic Agent、指示を受けるグラミーがAction Agentの役割を持つようにするということです。
改善策
上記の考察を元にシステムの改善を行ってみます。これまでは指示役とそうでないグラミーとの間に構造的な差はありませんでした(最初にプレイヤーからの指示を受けるかどうかという違いのみ)が、ここからは明確に区別を行うことにします。以下、指示役グラミーをManager、指示を受けるグラミーをWorkerと呼ぶことにします。またManagerは自らは一切タスクの実行をせず、指示専門のグラミーであるとします。
Managerにとって、タスクに関係する条件を把握して指示を飛ばすことは難しくても、環境の状態を知った上で適宜指示を飛ばすということはそれほど難しくないはずです。そこで、Managerから指示を受けたWorkerはそれに従って実行を行い、その結果をManagerに報告するようにし(≒Action Agent)、そしてその内容を基にManagerが再度指示を与えるようにします(≒Critic Agent)。このようにすることで、もしManagerが最初に与えた指示が条件の考慮不足で不十分なものであったためにWorkerがタスク実行に失敗したとしても、Workerから報告された実行結果を元に修正した指示を行うことができます。木を切るというタスクの例で言えば、Workerが「木がないために失敗しました」という報告をし、それに対しManagerが「じゃあまずは木の種を植えてきて」と再度指示を行う、ということです。
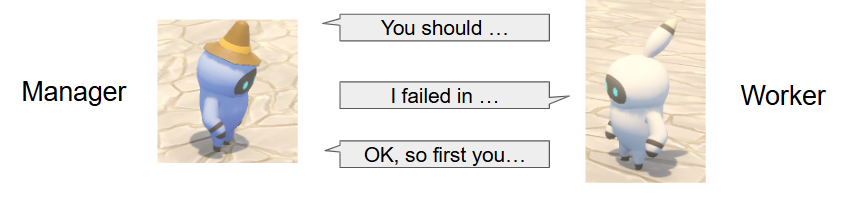
ManagerとWorkerのそれぞれの処理の流れの詳細は以下の通りです。先ほどは
- Manager
- プレイヤーから指示を受ける
- 指示の内容(最終タスク)を実行するためのプランニングを実施
- タスクを実施していくための情報収集タスクを任意のWorkerに指示し、必要な情報が集まるまで待機
- 集まった情報とプランを基に、手が空いている任意のWorkerに何らかのタスクを指示する
- Workerからの返答が来るたびに、最終タスクが完了したか、完了していない場合は次にどのWorkerにどんな指示を出すべきか(あるいは待機すべきか)を判断する
- 最終タスクが完了するまで
4と5を繰り返す
- Worker
- Managerからの指示が来るまで待機
- Managerからタスクの指示が来たら、それを達成するためのコードを生成し、実行する
- 実行終了時に、指示されたタスクを完遂できたかどうか、失敗した場合にはさらにその理由をManagerに報告する
1に戻る
Managerは、これまでに行った指示やWorkerからの返答を元に現在の状況を逐次把握する必要があります。よってManagerに対しては適切にコンテキストを与えなければなりません。LLMに対してどのようにコンテキストを与えるべきかについては、Retrieval-augmented generation (RAG, [4])を代表として様々な手法が提案・議論されていますが、今回は単純にこれまでの会話履歴をコンテキストに含めるようにしました。ただし単に会話履歴を与えるだけではLLMが正しく解釈してくれるとは限らないので、どのようにその内容を参照すべきかを詳細に指示するようにしました。以下はプロンプトにおけるその部分の抜粋です。
The `Context` contains commands and responses that has been exchanged so far: - Command to <uuid>: <text> - Response from <uuid>: <text> `Command` shows the target grammi uuid and the content of the command that you have sent so far. `Response` shows the response to the command you have sent so far. They are all arranged in chronological order. Therefore, you can determine what commands have been sent so far, what responses have been returned in response, and what the content of those returned responses was. You should take the context into consideration to decide next task and which grammi to select as a worker. A response will always eventually be returned from the grammi that received the command, so you must not assign a similar task to other grammi until at least that response has been received.
なおコンテキストの与え方については[5]の記事が良くまとまっており参考になります。
このManager/Workerの仕組みを用いることにより、よりタスクの実行精度を向上させることができました。以前は、「石の斧をクラフトする」タスクについては事前準備をしておく必要がありました(コンテナの作成、鉱山・畑の用意、加工台の用意など)。この仕組みを導入後は、それらを一切用意せずとも、ManagerとWorkerが協力して準備を行った上で、クラフト作業に移ることができていました。タスクの実行に必要なものがなかった場合にも、Workerが適宜その旨をManagerに報告することにより、環境に状態に応じた柔軟なタスク実行ができるようになったと考えられます。

後半のまとめ
以上が後半のまとめになります。グラミーどうしがコミュニケーションを取りながら協力してタスクをこなしてくれるように、まずは最小限の構成から始め、その後実験を通じて見つかった問題点を解決していきました。その結果、グラミーに自然言語の指示を与えるだけで、環境の状態に依存せず、タスクが精度良く実行されるようにすることができました。
まとめと感想
今回のインターンシップでは、Omega Crafter上でAI Agentを用いたシステムの構築・改善に取り組みました。最終的には、自然言語でグラミーたちに指示をすると、グラミーたちがコミュニケーションをとりながら協力してその指示をこなしてくれる様子が見られるようになりました。その様子は見ていてとても面白く、新たなゲーム体験の創出という意味でも当初の目的を十分に達成できたと思います。また、今回の成果の一部を9月末の東京ゲームショウで展示することができ、外向けのアウトプットの場が得られたことも良かったです。
こちらに展示された動画を記します。(動画リンク)
この期間を通じて私は色々な面で成長できましたが、特にLLMを用いたシステムの構築に関して、単にプロンプトを工夫するだけでなく、全体として精度を向上させるためにどのような情報の受け渡し・フローを考えるべきか、という点について学びを得ることができたと感じています。
また私は昔からゲームが大好きで、今回の「ゲームとAI」というテーマは私にとってかなり興味のあるものでした。7週間にわたって、どんな風にしたら面白いかなどを考えながら自由に取り組み、自分のやりたいことに挑戦することができました。他では得られない貴重な体験ができたことに非常にありがたく感じています。
本ブログは以上になります。ここまでお読みいただきありがとうございました。
参考文献
[1] Wang, G., Xie, Y., Jiang, Y., Mandlekar, A., Xiao, C., Zhu, Y., … & Anandkumar, A. (2023). Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291.
[2] Li, H., Yang, X., Wang, Z., Zhu, X., Zhou, J., Qiao, Y., … & Dai, J. (2024). Auto mc-reward: Automated dense reward design with large language models for minecraft. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16426-16435).
[3] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
[4] Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., … & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33, 9459-9474.
[5] dbreunig. (2025, June 26). How to fix your context. dbreunig. https://www.dbreunig.com/2025/06/26/how-to-fix-your-context.html