Blog
本記事は、アルバイトとして勤務されている澤田恵里さんによる寄稿です。
はじめに
本記事では、Optuna v4.8からv4.9 にかけて段階的に導入される GPSampler の並列化強化について紹介します。
GPSampler は、ガウス過程に基づくベイズ最適化の sampler です。連続関数の最適化で特に高い性能を発揮し、Optuna v3.6 で導入されて以降、制約付き多目的最適化への対応、高速化など、さまざまな機能拡張や強化が行われてきました。
一方、v4.7 までの GPSampler の実装では、評価済みのサンプルだけを用いてガウス過程回帰を行い、獲得関数の最適化を行っていました。そのため、バッチ最適化では同じ評価済みデータに基づくほぼ同一の回帰モデルから次の候補点が選ばれ、結果としてほぼ同じ点が繰り返し提案されてしまう、という問題がありました。
この問題を解決するため、Optuna v4.8 では制約なし単目的最適化において Constant Liar を用いた並列化強化を導入しました。また Optuna v4.9 では制約あり・多目的最適化において Kriging Believerを用いた並列化強化を導入予定です。これにより、評価中の点(running trials)も考慮しながら次の試行点を提案できるようになり、バッチ最適化においてより多様で有意義な点が提案されるようになりました。これらの機能は特別な引数を必要とせず、通常どおり並列最適化を実行するだけで自動的に有効になります。
この記事では、今回導入したアルゴリズムの概要を説明した後、可視化結果とベンチマーク結果を紹介します。
GPSampler における評価中の点の扱い
今回の並列化強化では、Constant Liar と Kriging Believer に基づく実装を行いました [1]。これらの手法では、評価中の点に対して仮の目的関数値を与え、その点がすでにその値で評価されたかのように扱って回帰モデルを図1のように更新します。これにより、評価中の点を考慮した次の評価点の提案を可能にします。
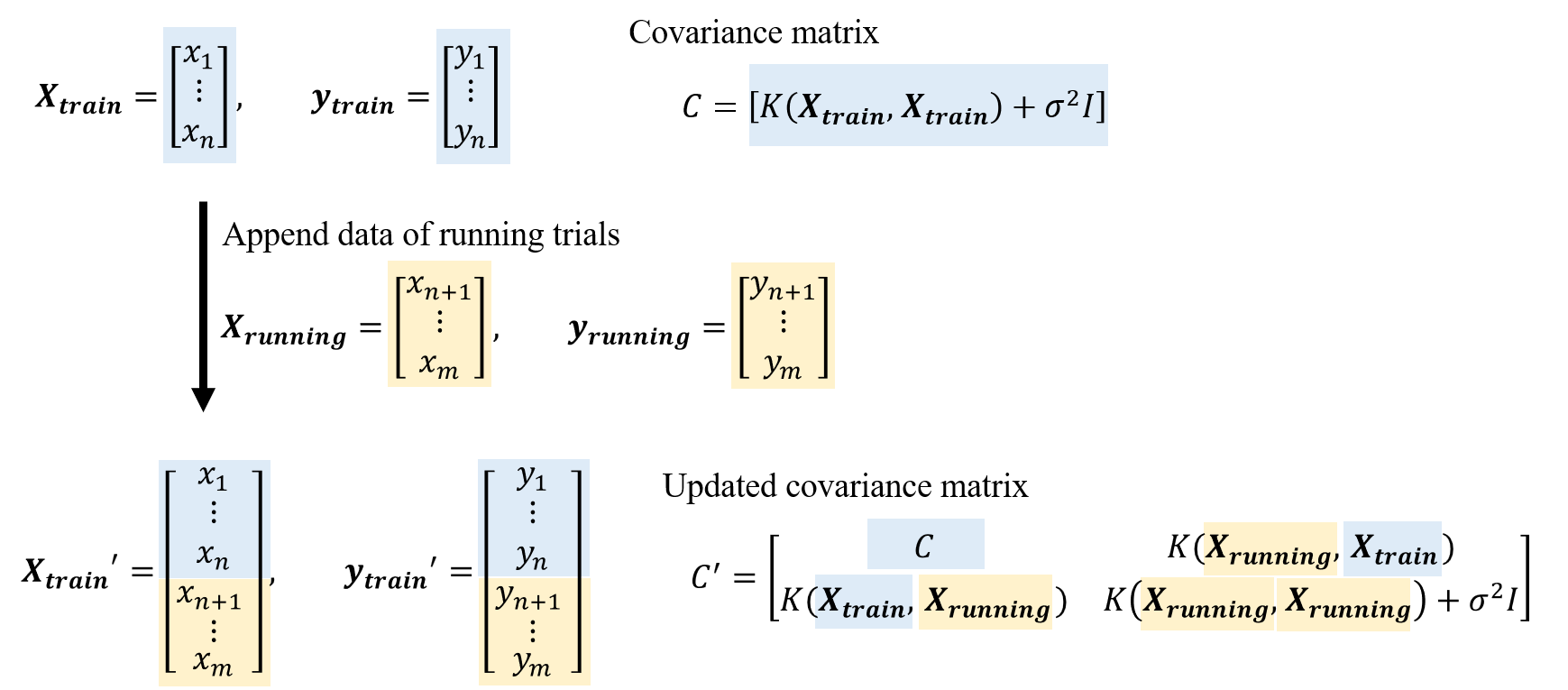
図1: 評価中の点(running trials)のデータを用いて、共分散行列を更新する。
Constant Liar では、評価中の点に対して一定の仮の値を与えます。具体的には、これまでの探索で得られた最良値、最悪値、あるいは平均値を仮の値として用いる方法があります。最良値を用いるとより活用寄り、最悪値を用いるとより探索寄りの振る舞いになります。後述するようにベンチマークの結果に基づき、GPSampler の単目的・制約なし最適化では、仮の値として最良値を用いる方針(Constant Liar [best])を採用しています。
Kriging Believer では、評価中の点に対する仮の値として、評価済みの点のみから学習した回帰モデルの予測値を用います。この方法の利点は、多目的最適化や制約付き最適化にも自然に拡張しやすい点にあります。これらの設定では、Constant Liar のように「現在の最良値」や「現在の最悪値」を単純に定義することが難しく、仮の値の選び方が自明ではありません。一方、Kriging Believer ではモデルの予測値をそのまま用いるため、目的関数や制約の数が増えた場合でも同じ考え方で扱うことができます。これらの理由から、v4.9でリリース予定の多目的最適化・制約付き最適化における並列化強化では、Kriging Believerを採用しています。
バッチ最適化において提案する点の可視化
まず、バッチ最適化において GPSampler がどのような点を提案するかを可視化しました。ここでは Branin-Hoo function[2] を用い、制約なしの単目的最適化を行っています。GPSamplerにおいて、最初の 10 Trial はランダムに選択されます。その後、バッチサイズを 5 として合計 50 Trial 分の提案を行いました。これら 50 Trial で提案された点を図2の赤点で示しています。
図2(a) に示すように、Constant Liar などの並列化戦略を用いない場合、すなわち v4.7 以前では、ほぼ同じ点が繰り返し提案されていました。そのため、バッチ最適化において実質的に同じ候補を何度も評価してしまう状況が生じていました。
一方、図2(b)に今回v4.8で導入したConstant Liar [best] を用いたときの提案した点の分布を示します。図が示すように、今回導入した並列化強化によって評価中の点が考慮されるようになった結果、同じ点が繰り返し提案されることが大幅に減少しました。これにより、各バッチでより多様な候補点が選ばれるようになり、最適化性能の向上につながります。
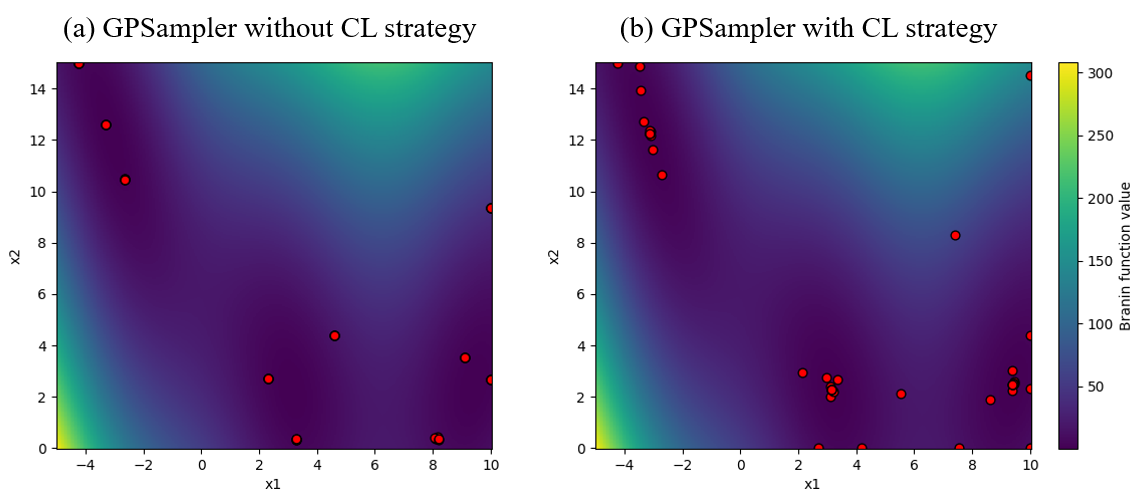
図2: バッチ最適化において GPSampler が提案した点の分布。(a) 並列化戦略を用いない場合には、ほぼ同じ点が繰り返し提案されている。一方、(b) Constant Liar Strategy を用いた場合には、評価中の点を考慮することで、より多様で意味のある点を提案できている。
ベンチマーク結果
次に、最適化性能を定量的に評価するためのベンチマークを実施しました。比較したのは以下の 5 つの方針です。
- Ignore running trials:v4.7 以前の評価中の点を考慮しない実装
- CL[best]:評価済みの点の最良値を running trials の仮の評価値として与える
- CL[worst]:評価済みの点の最悪値を running trials の仮の評価値として与える
- CL[mean]:評価済みの点の平均値を running trials の仮の評価値として与える
- KB:回帰モデルの予測値を running trials の仮の評価値として与える
実験設定
ベンチマーク問題:以下の8種類の制約なし単目的最適化問題で比較を行いました。
- BBOB問題:5種
- HPO(ハイパーパラメータ最適化)問題:3種
- 評価パラメータ:上記の8種の問題それぞれについて、以下の2つの要素を組み合わせた全12パターンの設定をそれぞれ用意します。
- 試行回数 (n_trials): [25, 50, 75, 100]
- バッチサイズ (batch_size): [5, 10, 50]
評価指標と統計的手法
精度の高い比較を行うため、以下のステップで各手法を比較します。
- 反復試行: 各設定において、乱数シードを変えて100回の実行を行い、それぞれの最良値を取得
- 統計検定: 手法間で one-sided Mann–Whitney U test (有意水準:alpha = 0.05)を実施
- 勝ち数の集計: 検定の結果、他手法と比較して「有意に優れている」と判定された回数を「勝ち数」としてカウント
計算機環境
ベンチマークは、x86_64 アーキテクチャのUbuntu 24.04 環境で実施しました。CPUはIntel 12th Gen Core i7-1260P(12 コア16スレッド、最大 4.70 GHz)を使用しました。
結果は以下の通りです。
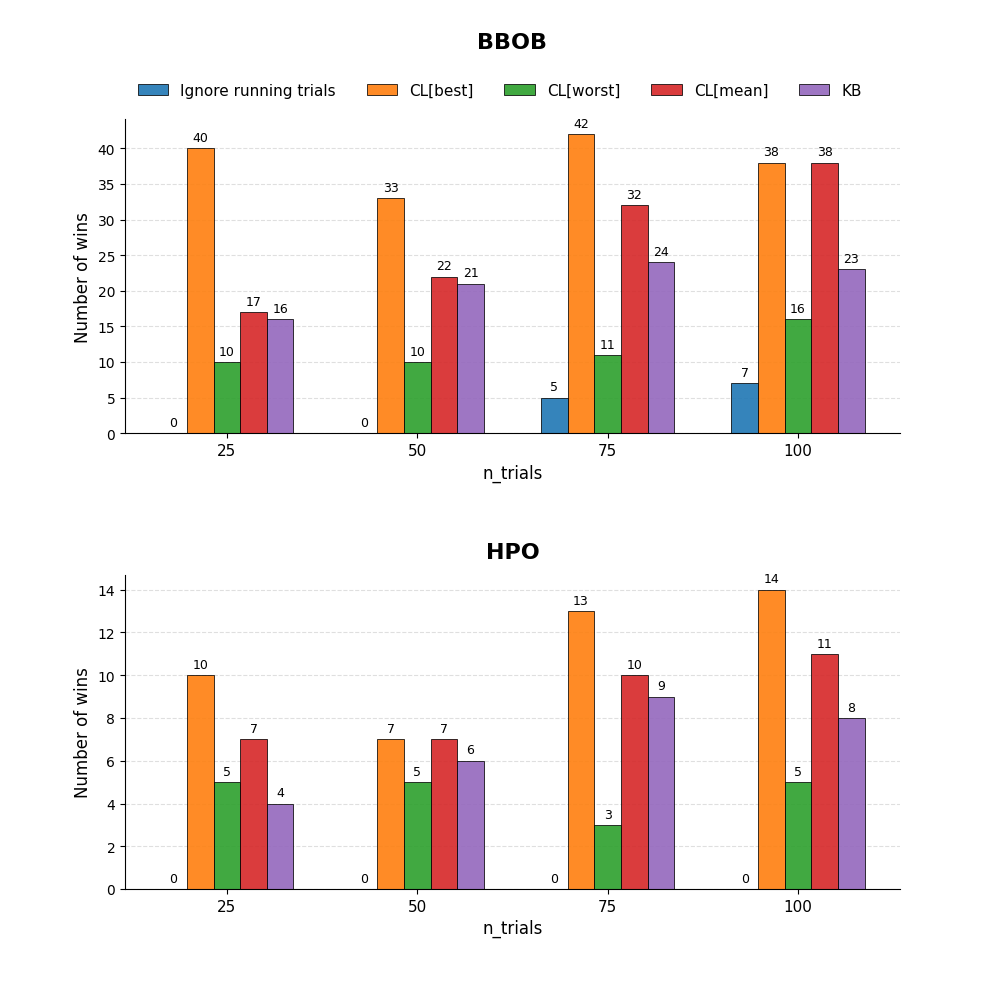
図3: さまざまな問題設定における Ignore running trials(v4.7以前)、CL[best]、CL[worst]、CL[mean]、KB の最適化性能比較。最良値について各手法間で有意差検定を行い、他手法に対して有意に優れていた回数を勝ち数として集計した。CL[best]、CL[worst]、CL[mean]、KB のいずれも、従来の Ignore running trials より良い結果を示し、特に CL[best] は最も高い性能を示した。
評価中の点を考慮しない従来の方針と比べて、評価中の点を考慮する手法は、多くの問題設定で有意に良い結果を示しました。中でも CL[best] は最も多い勝ち数を示しており、今回のベンチマークでは特に有効であることが分かりました。これは、今回用いた問題の多くが、比較的なめらかで大域的にも単純な構造の目的関数を持ち、良い値を示す領域の周辺にも有望な候補が存在しやすい性質を持っていたためだと考えられます。今回のベンチマーク結果を踏まえ、Optuna では単目的・制約なし最適化において CL[best] を採用しました。
一方で、一部の設定で従来の実装が有意に良い結果を示したケースもありました。これは、BBOB の Sphere Function [3] を用いた問題設定で起こっています。Sphere Function は、最適解からのユークリッド距離の二乗を目的関数とする、きわめて単純な問題です。そのため、初期段階で最適解近傍に到達することができ、その後周辺を繰り返し探索する挙動が結果として有利に働いたと考えられます。
終わりに
Optuna v4.8、 v4.9 では、Constant Liar と Kriging Believer を用いることで、GPSampler の並列化を強化しました。これにより、バッチ最適化において同じ点が繰り返し提案されることを防ぎ、多くのベンチマークにおいて最適化性能が有意に改善することを確認しました。今後はモンテカルロ法ベースの獲得関数なども導入し、GPSampler における並列化戦略をさらに強化していく予定です。ぜひ楽しみにしていてください!
参考文献
[1] Ginsbourger, D., Le Riche, R., & Carraro, L. (2010). Kriging is well-suited to parallelize optimization. In Computational intelligence in expensive optimization problems (pp. 131-162). Berlin, Heidelberg: Springer Berlin Heidelberg.
[2] Branin, F. H. (1972). Widely convergent method for finding multiple solutions of simultaneous nonlinear equations. IBM Journal of Research and Development, 16(5), 504-522.
[3] The blackbox optimization benchmarking (bbob) test suite (https://hub.optuna.org/benchmarks/bbob/)