Blog
ハイパーパラメータ自動最適化フレームワークOptunaの4回目のメジャーリリースを行いました。リリースノートをぜひチェックしてください!
Optunaは2018年の公開以来、多くの機能開発を経て沢山のユーザに使われるソフトウェアに成長してきました。GitHub star数は1万を超え、月間ダウンロード数300万以上、利用プログラム数1万5千以上、論文引用数5000以上、Kaggleでの言及数1万8千以上などさまざまな分野で広く使われており、ハイパーパラメータ最適化OSSとして最もよく使われるライブラリの1つとなっています。
我々は以下のような目標を掲げてv4.0の開発を進めてきました。
- ユーザ間での機能の共有を手軽に
- 機能共有プラットフォームOptunaHubにより、誰でも手軽にOptunaの新規アルゴリズムや可視化機能を公開・共有できます。
- 生成AIの最適化や多様なコンピューティング環境に役立つ機能を強化
- 生成した画像や学習済みモデルをOptuna上で管理するArtifact Storeの正式サポートを開始しました。
- NFS経由での分散最適化を可能とするJournalStorageの安定化を行い、MySQL等のRDBが使えない環境への対応を強化しました。
- 重要な機能やアルゴリズムを全てのユーザに届ける
- 多目的TPESamplerの大幅な高速化、Terminatorアルゴリズムの新規追加など、重要な機能を一層強化し、提供します。
ユーザ間での機能の共有を手軽に
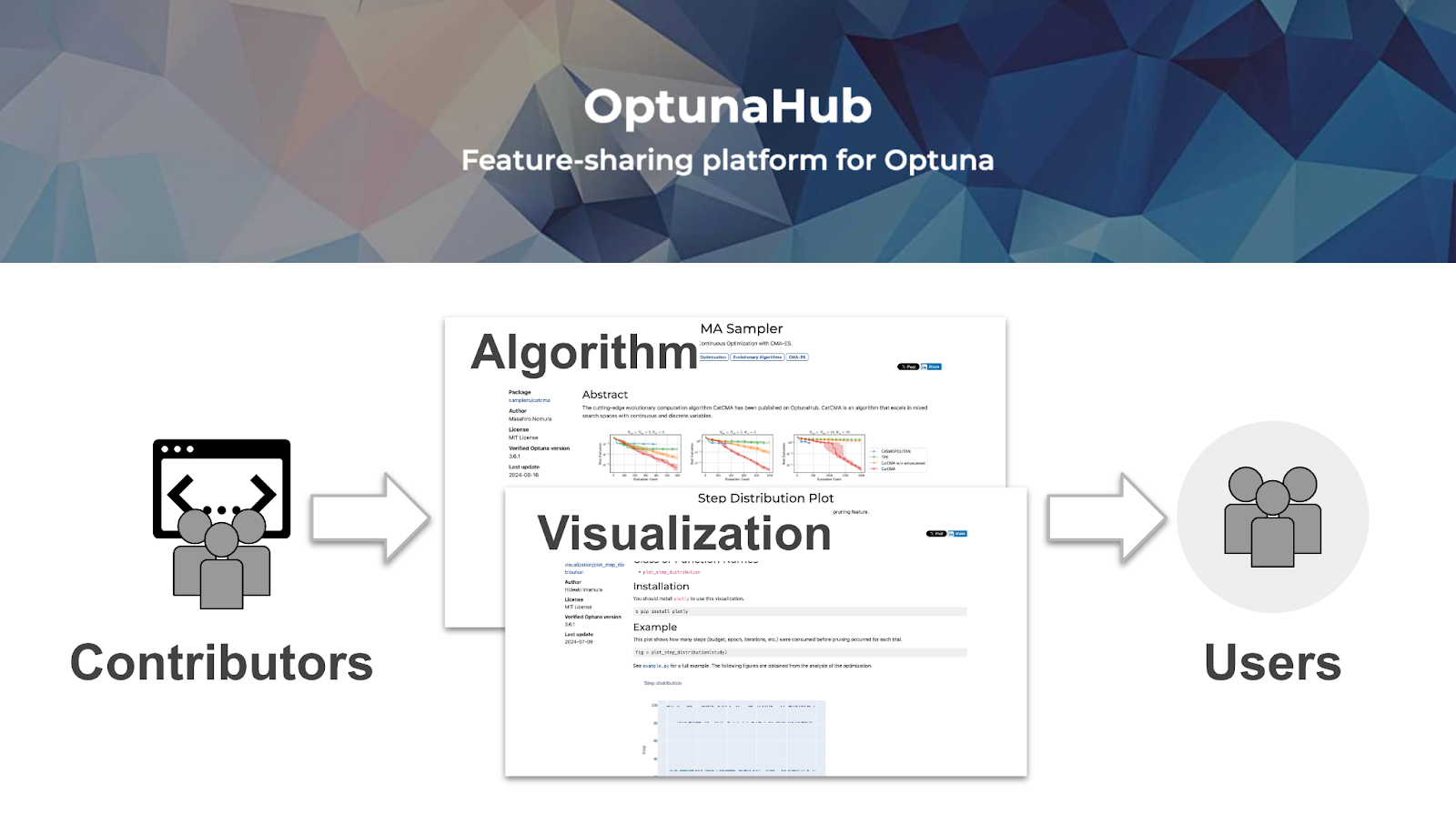
機能共有プラットフォームOptunaHubを正式公開
Optuna向け機能共有プラットフォームOptunaHubの正式版をリリースしました。OptunaHubには数多くの最適化アルゴリズムや可視化手法が登録されており、すぐに利用可能です。また、コントリビュータは自身が開発した機能を手軽に登録し、世界中のOptunaユーザに届けることができます。
OptunaHubにより最先端の手法や特定の問題ドメインに特化した最適化手法をユーザ間で共有するのが便利になりました。我々は機能共有プラットフォームを開発することで、機能開発がより活発になると考えています。Optunaユーザはサードパーティの機能が充実することでOptunaがより便利に使えるようになります。
詳細はOptunaHubのリリースブログもご覧ください。
生成AIの最適化や多様なコンピューティング環境に役立つ機能を強化
実験管理機能の強化:Artifact Storeの正式サポート
Artifact Storeは最適化中に生成されたファイル(Artifact)を管理するための機能です。例えば、生成AIが出力する文章、画像、音声などのファイルや、深層学習モデルのスナップショット等のRDB等では効率的に扱うことのできないサイズのファイルがハイパーパラメータ最適化中に生成されることがあります。Artifact Storeを用いると外部の実験管理ツールを別途インストールすることなく、Optuna上でこれらのサイズの大きなファイルを管理できます。またOptuna Dashboardと連携することでArtifactを簡単に確認できます。
Optuna v4.0ではArtifact StoreへのファイルアップロードAPIの安定化に加えて、Artifactのダウンロード機能等の拡充を行いました。また、Optuna Dashboard側では以前から存在した画像、音声、動画再生に加えて、表形式データの表示機能を追加しました。今回の正式サポートに伴い、API安定化及び後方互換性の担保がされます。安心して多くのユーザに利用して頂けると幸いです。より詳しい説明は個別記事をご覧ください。
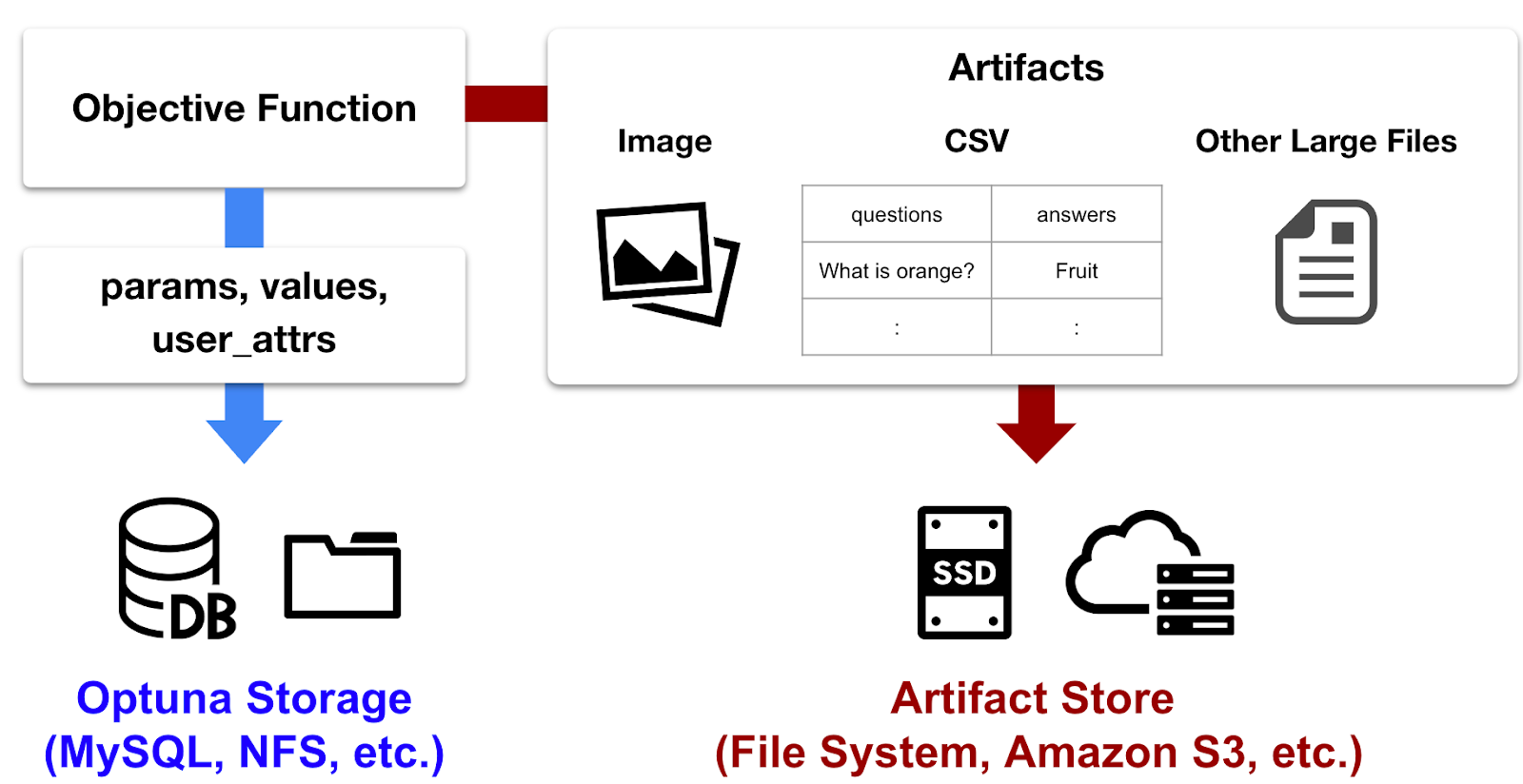
OptunaにおけるArtifactの概念図。Artifact Storeでは目的関数評価時に生成されるファイル (Artifact) を保管するために利用されます。Artifact Storeはファイルシステムやクラウドストレージを利用するため、RDB等では効率的に扱うことができないサイズの大きなデータの管理が可能になります。
JournalStorage: NFSを用いた分散最適化の正式サポート
JournalStorageは、Optuna v3.1で実験的に導入された新しい方式のストレージ実装です(解説ブログ)。従来のように「値」を記録し上書きするのではなく、値の変更の要因となった「操作ログ」を記録します。この方式の利点は、様々な種類のストレージへの対応が容易になることです。
JournalStorageを利用して、NFSを用いた分散最適化が可能なストレージがOptunaに実装されています。例えば、スーパーコンピュータやコンピュータクラスタにおいて、MySQL等のRDB環境が用意できず既存のストレージが使えない場合でも、NFSを用いた分散最適化が可能です。
Optuna v4.0ではJournalStorageのユーザーAPIを整理し、正式サポートを開始しました。今回の正式サポートによりv4.0以降での後方互換性が保証されます。APIの変更に関する詳細はOptuna v4.0 マイグレーションガイドをご確認ください。
import optuna
from optuna.storages import JournalStorage
from optuna.storages.journal import JournalFileBackend
def objective(trial: optuna.Trial) -> float:
...
storage = JournalStorage(JournalFileBackend("./journal.log"))
study = optuna.create_study(storage=storage)
study.optimize(objective)
重要な機能やアルゴリズムを全てのユーザに届ける
多目的TPESamplerの大規模高速化
多目的最適化では複数の目的関数を同時に最適化する性質上、単一目的最適化よりも多くのTrial数を要することが一般的です。必要なTrial数を少しでも減らすためにサンプル効率の良いSamplerを利用することが必要です。Optunaの多目的最適化ではNSGAIISamplerが標準で利用されますが、最近の論文によると1,000 – 10,000 Trials程度の最適化ではTPESamplerがより良いサンプル効率を達成すると報告されています [1]。また、TPESamplerはNSGAIISamplerにはない動的探索空間の取扱いやユーザ定義のカテゴリ変数間距離等に代表されるような機能がサポートされているため、多くの問題設定でTPESamplerがNSGAIISamplerよりも性能的に上回ることが想定されます。
これまでのTPESamplerは多目的最適化においてパラメータの提案に長い時間がかかる実装になっており、TPESamplerが最適化上の律速になるケースがありました。v4.0ではTPESamplerを大幅に高速化し、例えば三目的最適化で200Trialsを提案するためにかかる時間が300倍短縮されました。詳細は個別ブログをご覧ください。
Terminatorアルゴリズム追加
機械学習によるハイパーパラメータ最適化は性能改善をする上で重要ですが、Trial数を増やしすぎるとハイパーパラメータが検証データセットへ過剰適合する問題があります。そのような問題に対処するためにOptunaにはTerminatorという機能が実装されています。Terminatorは検証データセットへの過剰適合が始まる前に最適化プロセス自体を早期終了させる機能です。別の使い方としては最適化を規定量実行した後に、Terminatorの出力値に基づいて最適化のどの段階でハイパーパラメータの過剰適合が開始していそうか可視化することができます。この可視化機能によって、過剰適合前のTrialを判断する一定の理論的根拠に基づく客観的な手がかりを得ることができます。
Terminatorは元々交差検証を伴う機械学習等のハイパーパラメータ最適化が主要な用途でした。Optuna v4.0ではより幅広いユースケースに対応するため、新たにExpected Minimum Model Regret (EMMR)アルゴリズムを導入しました [2]。具体的な使い方はEMMREvaluatorのドキュメントを参照してください。
制約付き最適化の機能強化
制約付き最適化はTPESampler (v3.0.0以降) やNSGAIISampler (v2.5.0以降) のようなOptunaの主要アルゴリズムでサポートされている機能で、v3.3.0以降でも可視化機能強化が行われてきました。v4.0でも制約付き最適化でもさらなる機能強化を行いました。
v4.0ではstudy.best_trialとstudy.best_trialsが制約付き最適化に対応しました。以前は制約非充足な解が含まれる可能性がありましたが、v4.0では制約充足であることが保証されます。
非推奨機能の削除
Optunaでは非推奨となった機能をメジャーリリースのタイミングで削除しています。ユーザのコードが急に壊れることのないように非推奨になってから実際に削除するまでの期間をとっており、原則として非推奨となった時点からメジャーバージョンが2つ上がった時に削除します。v4.0の場合、v2.0.0からv2.10.1の間に非推奨になった機能が主な対象です。一覧はマイグレーションガイドをご覧ください。
ここでは、影響が大きい多目的最適化APIの移行について紹介します。v1.4.0で実験的な機能として導入した多目的最適化は、v2.4.0において単目的の最適化とAPIを共通化することで正式化されました。v4.0では最初の導入時に採用したAPIの削除を行いました。
sampler = optuna.samplers.MOTPESampler() study = optuna.multi_objective.create_study(directions=["minimize", "minimize"], sampler=sampler)
削除したAPIを用いたコード
# MOTPESamplerを廃止し、多目的最適化をサポートしたTPESamplerを用いる sampler = optuna.samplers.TPESampler() # optuna.multi_objectiveサブモジュールを廃止し、単目的最適化と同じAPIを用いる study = optuna.create_study(directions=["minimize", "minimize"], sampler=sampler)
現行のAPIを用いたコード
今後の開発について
我々は新機能の追加とソフトウェアの安定性向上の双方を進めることで、優れたハイパーパラメータ最適化アルゴリズムを実用的に利用できるように開発を行っています。v4.0では新規アルゴリズム追加や扱える問題設定の拡張及び多様な計算環境への対応を行いました。Optunaはこれからもまだまだ進化を続けます。ユースケースの広がりに応じて様々な問題に適用可能にしたり、OptunaHubを通じて新規アルゴリズムへの対応を進める予定です。次のv4.1リリースでもこれらの取り組みを継続していきます。
コントリビュータおよびスポンサー
v4.0のリリースは多くのコントリビュータの力無しには実現しませんでした。以下は、v4.0の開発に関わった開発者の方々の一覧です。
@47aamir, @Alnusjaponica, @HideakiImamura, @Obliquedbishop, @RektPunk, @TTRh, @aaravm, @aisha-partha, @alxhslm, @c-bata, @caleb-kaiser, @contramundum53, @eukaryo, @gen740, @kAIto47802, @karthikkurella, @keisuke-umezawa, @keita-sa, @kz4killua, @nabenabe0928, @neel04, @not522, @nzw0301, @porink0424, @sgerloff, @toshihikoyanase, @virendrapatil24, @y0z
OptunaはGitHub上でスポンサーしていただいています。以下は、今までにOptunaのスポンサーになっていただいた方々の一覧です。
@AlphaImpact, @dec1costello, @dubovikmaster, @shu65, @raquelhortab
参考文献
[1] Yoshihiko Ozaki, Yuki Tanigaki, Shuhei Watanabe, Masahiro Nomura, and Masaki Onishi (2022). Multiobjective Tree-Structured Parzen Estimator. Journal of Artificial Intelligence Research (JAIR) 2022. Available from https://doi.org/10.1613/jair.1.13188.
[2] Ishibashi, H., Karasuyama, M., Takeuchi, I. & Hino, H.. (2023). A Stopping Criterion for Bayesian Optimization by the Gap of Expected Minimum Simple Regrets. Proceedings of The 26th International Conference on Artificial Intelligence and Statistics, in Proceedings of Machine Learning Research 206:6463-6497. Available from https://proceedings.mlr.press/v206/ishibashi23a.html.