Blog
背景
Preferred Networks(以下PFN)とグループ会社のPreferred Elements(以下PFE)では2024年10月からGENIAC 第2期を開始し、その中で高性能かつ軽量なLLMの開発を行っています。その中で、予備実験・検証として、枝刈り(pruning)による20億 (2B) パラメータ規模のLLM (PLaMo 2 2B) の学習を行いました。今回の記事では、このモデルの開発について紹介します。
上記にあるように、この開発は経済産業省及び国立研究開発法人新エネルギー‧産業技術総合開発機構(NEDO)が実施する、国内の生成AIの開発力を強化するためのプロジェクト「GENIAC(Generative AI Accelerator Challenge)」の支援を受けて実施しました。
GENIAC 第2期におけるPFNとPFEの目標
今回PFNとPFEではモデルサイズを抑えたまま高い性能を実現するために高品質なデータを作成し、そのうえで小規模なモデルで高い精度を達成することを目標に活動しています。
この活動の中で、高い日本語能力を維持したまま、幅広い知識を測定するJMMLUやコーディングタスクであるJHumanEvalにおいてモデルサイズを抑えたまま高い精度を達成することを目的の一つとしています。この目標を達成するための方向性の技術の一つとして、大きいモデルの一部のパラメータを削り、小さいモデルの重みとするpruningという技術の活用があると考えています。
この記事では、このpruningの技術の検証として、すでに開発したPLaMo 2 8Bを利用し、pruningを活用しながら開発したPLaMo 2 2Bについて紹介します。
評価結果
最初に、開発したPLaMo 2 2Bの結果のまとめと各ベンチマークの結果を示します。そのあと各モデルとの結果の比較を述べていきます。
まず結果を一言でまとめると、今回開発したPLaMo 2 2Bは以前開発したPLaMo 2 1Bよりも投入した学習計算量が少ないにもかかわらず、日本語の様々なベンチマークで高いスコアを達成することができました。
具体的な各ベンチマークの結果は以下に順番に説明していきます。
まず、評価に使ったベンチマークについてです。日本で利用される際、日本語による受け答えや日本の独自の知識が重要であると考えています。これらを測るベンチマークとして、日本語のベンチマークとしてよく使われる、JCommonSenseQAとJSQuAD、PFNで開発しているpfgen-benchを利用しました。
さらに、LLMの応用例として重要な翻訳についても能力を測定するために、翻訳のベンチマークであるWMT20の結果も示します。
これに加えて、英語と日本語の両方で幅広い知識を測定するために、MMLUとその日本語訳であるJMMLUを使った評価、コーディング能力を測定するためにHumanEval+とJHumanEvalで評価しました。
比較対象には2B以下のモデルで、事前学習のデータに日本語が含まれていると考えられる事前学習済みモデルを選びました。ただし、gemma-2-2bに関しては日本語で継続学習されたモデルはinstruction済みモデルのみ公開されているため、gemma-2-2bの事前学習モデル(ただしこれは日本語はほとんど含まれていないと思われます)と日本語の継続学習がされたgemma-2-2b-jpn-itを比較対象として加えました。このため、gemma-2-2b-jpn-itだけは他のモデルと傾向が違うと考えられます。
以下に各ベンチマークのスコアが具体的にどのような値であったかを示します。
日本語のベンチマークについて
まず、日本語のLLMの評価でよく使われるJGLUEの一部であるJCommonSenseQAとJSQuAD、PFNで開発しているpfgen-benchの精度を以下に示します。
表1: JCommonSenseQAとJSQuAD、pfgen-benchの結果
| モデル | JCommonSenseQA(3 shots, acc_norm)* | JSQuAD(2 shots, F1)** | pfgen-bench |
| sbintuitions/sarashina2.1-1b | 0.326 | 89.343 | 0.572 *** |
| llm-jp/llm-jp-3-1.8b | 0.274 | 75.257 | 0.466 *** |
| google/gemma-2-2b | 0.230 | 2.129 | 0.383 *** |
| google/gemma-2-2b-jpn-it | 0.603 | 77.972 | 0.461 *** |
| SakanaAI/TinySwallow-1.5B | 0.592 | 82.150 | 0.334 *** |
| PLaMo 2 2B | 0.768 | 92.952 | 0.597 |
| PLaMo 2 8B (参考) | 0.759 | 94.216 | 0.753 *** |
*: Stability AIのlm-evaluation-harnessのjcommonsenseqa-1.1-0.2.1 と同じデータ、promptで測定
**: Stability AIのlm-evaluation-harnessのjsquad-1.1-0.2 と同じデータ、promptで測定。ただし、DYNAMIC_MAX_LENGTH=Falseで実行。
***: https://github.com/pfnet-research/pfgen-bench から引用
WMT20
次に翻訳ベンチマークであるWMT20の結果を示します。こちらはStability AIのlm-evaluation-harnes を修正し、評価指標としてwmt22-comet-da を利用して測定しました。このwmt22-comet-daは0から1の値を取り、数値が1に高いほど翻訳精度が高いということを示している指標になっています。
結果は以下の通りです。
表2: WMT20の結果
| モデル | WMT20 (4-shot, en → ja, wmt22-comet-da) | WMT20 (4-shot, ja → en, wmt22-comet-da) |
| sbintuitions/sarashina2.1-1b | 0.874 | 0.766 |
| llm-jp/llm-jp-3-1.8b | 0.855 | 0.768 |
| google/gemma-2-2b | 0.536 | 0.442 |
| google/gemma-2-2b-jpn-it | 0.809 | 0.716 |
| SakanaAI/TinySwallow-1.5B | 0.876 | 0.787 |
| PLaMo 2 2B | 0.891 | 0.803 |
| PLaMo 2 8B (参考) | 0.901 | 0.814 |
JMMLUの評価結果
ここからJMMLUについての結果を示します。
JMMLUに関しては公開されているtestデータの各項目の5つのサンプルをランダムに選び、選んだサンプルをfew shotの入力として利用して測定しました。評価にはLanguage Model Evaluation Harness のMMLUのコードを改良して実施しました。
また、JMMLUの評価のpromptとしてLanguage Model Evaluation HarnessのMMLUで実装されているdefault(選択肢をLLMに入力し、A,B,C,Dの選択肢を答えさせる方法)と、continuation(選択肢を見せずに選択肢の文章の尤度が一番高いものを選ぶ方法)の2種類を測定しました。
結果は以下の通りです。
表3: JMMLUの評価結果
| default(5-shot, acc)* | continuation(5-shot, acc_norm)** | |
| sbintuitions/sarashina2.1-1b | 0.258 | 0.362 |
| llm-jp/llm-jp-3-1.8b | 0.264 | 0.334 |
| google/gemma-2-2b | 0.259 | 0.264 |
| google/gemma-2-2b-jpn-it | 0.382 | 0.298 |
| SakanaAI/TinySwallow-1.5B | 0.519 | 0.347 |
| PLaMo 2 2B | 0.505 | 0.401 |
| PLaMo 2 8B (参考) | 0.572 | 0.447 |
*: LLMに質問とA,B,C,Dの4つの選択肢が入力されて、LLMは正解となる選択肢をアルファベットで回答させるやり方。promptの詳細はAppendix参照
**: LLMに質問と選択肢のテキストを与えて、最も選択肢のテキストの尤度が高くなるものを正解として選ぶやり方。promptの詳細はAppendix参照。
MMLUの評価結果
MMLUについては評価にはLanguage Model Evaluation Harness を利用しました。こちらもJMMLUと同様にdefaultとcontinuationの2種類を測定しました。結果は以下の通りです。
結果は以下の通りです。
表4: MMLUの評価結果
| モデル | default(5 shots, acc)* | continuation(5 shots, acc_norm)** |
| sbintuitions/sarashina2.1-1b | 0.253 | 0.368 |
| llm-jp/llm-jp-3-1.8b | 0.249 | 0.343 |
| google/gemma-2-2b | 0.328 | 0.300 |
| google/gemma-2-2b-jpn-it | 0.498 | 0.410 |
| SakanaAI/TinySwallow-1.5B | 0.547 | 0.395 |
| PLaMo 2 2B | 0.480 | 0.385 |
| PLaMo 2 8B (参考) | 0.573 | 0.465 |
*: JMMLUと同じようにLLMに質問とA,B,C,Dの4つの選択肢が入力されて、LLMは正解となる選択肢をアルファベットで回答させるやり方。promptの詳細はAppendix参照
**: JMMLUと同じようにLLMに質問と選択肢のテキストを与えて、最も選択肢のテキストの尤度が高くなるものを正解として選ぶやり方。promptの詳細はAppendix参照
JHumanEvalとHumanEval+
次にコーディングタスクであるJHumanEvalとHumanEval+についてです。
結果は以下の通りです。
表5: コーディングタスクの結果
| モデル | JHumanEval(0-shots, pass@1)* | HumanEval+(0-shots, pass@1)** |
| sbintuitions/sarashina2.1-1b | 0.073 | 0.073 |
| llm-jp/llm-jp-3-1.8b | 0.000 | 0.006 |
| google/gemma-2-2b | 0.171 | 0.159 |
| google/gemma-2-2b-jpn-it | 0.317 | 0.335 |
| SakanaAI/TinySwallow-1.5B | 0.256 | 0.232 |
| PLaMo 2 2B | 0.311 | 0.341 |
| PLaMo 2 8B (参考) | 0.463 | 0.463 |
*: 評価の詳細はAppendix参照
**: 評価の詳細はAppendix参照
他モデルとの結果比較
日本語固有の問題について
日本においてLLMを活用することを考えると、日本語固有の知識が重要となります。数学やコーディングといった能力は言語によらずほぼ同じものが要求されると考えられますが、例えば地理や法律などは国ごとに重点を置くべき知識に差がありそうです。また、用途によっては日本語を生成できる必要もあります。
まず、こういった日本語に関する能力について、ベンチマーク結果からPLaMo 2 2Bの能力を見ていきます。
日本語能力 (JCommonSenseQAとJSQuAD, pfgen-bench, WMT20)
まず日本語に関する能力を測るベンチマークとしてJCommonSenseQA、JSQuADの結果をみていきます。これらの結果ではPLaMo 2 8Bの時点で高い精度を達成できていたこともあり、それがうまくPLaMo 2 2Bにも引き継がれていて、結果として他の2Bクラスのモデルと比較してPLaMo 2 2Bが高い精度を達成することができました。
次に、日本語の文章を生成能力について、pfgen-benchと翻訳ベンチマークであるWMT20を用いてみていきます。
pfgen-benchと英日翻訳のどちらの結果からも、PLaMo 2 2Bは同程度のサイズのモデルにおいて最高クラスの日本語生成能力を持つことがわかります。
ただ、英日翻訳のベンチマークスコアはPLaMo 2 8Bの結果をほぼ維持できているのに対し、pfgen-benchのスコアは大きく低下しています。自由記述で質問に回答するというタスクの難易度が英日翻訳と比べて高く、モデルサイズが小さくなった影響をより受けているのではないかと思います。
JMMLU日本問題
JMMLUには日本問題という、MMLUからの翻訳ではない問題があります。熟語、公民、日本地理、日本史の4タスクからなるこれらの問題は、英語ではあまり問われることのない日本語固有の知識・問題が集まっています。
これらJMMLU 日本語問題の性能を通して、各モデルの日本語固有知識について見ていきます。default (4択による評価) だと選択肢問題に答えられずチャンスレベルと変わらない結果になってしまうモデルもあるので、continuationの評価方法をここでは採用します。その他の設定はJMMLU全体の結果と同じです。
表6: JMMLU (continuation) から日本問題を抜粋
| モデル | 平均 | 熟語 | 公民 | 日本地理 | 日本史 |
| sbintuitions/sarashina2.1-1b | 0.75 | 0.84 | 0.78 | 0.75 | 0.61 |
| llm-jp/llm-jp-3-1.8b | 0.66 | 0.77 | 0.68 | 0.63 | 0.55 |
| google/gemma-2-2b | 0.28 | 0.30 | 0.33 | 0.25 | 0.25 |
| google/gemma-2-2b-jpn-it | 0.37 | 0.48 | 0.41 | 0.29 | 0.30 |
| SakanaAI/TinySwallow-1.5B | 0.63 | 0.70 | 0.70 | 0.63 | 0.49 |
| PLaMo 2 2B | 0.77 | 0.88 | 0.81 | 0.76 | 0.61 |
| PLaMo 2 8B (参考) | 0.82 | 0.92 | 0.86 | 0.81 | 0.78 |
PLaMo 2 1Bでも取り上げたとおり、JMMLU 日本問題は日本語での学習量が非常に重要なベンチマークです。JMMLU全体では高い性能を発揮しているgemma-2-2b-jpn-itやTinySwallow-1.5Bが日本問題に限ると突出していないことからもこのベンチマークにおける日本語学習量の重要性がわかります。
一方で、PLaMo 2 2Bは後述の通り学習token数は少なめですが、日本問題においても高い性能を発揮できています。pruningを通して、PLaMo 2 8Bの日本語能力を転移させることができたためと考えられます。
JMMLU/MMLUとJHumanEval/HumanEval+に関して
次にJMMLUとMMLUに関してです。PLaMo 2 1Bのときにも紹介しましたが、MMLUは小さいモデルや少ない学習token数のモデルではdefaultの評価方法、つまり、選択肢をLLMに入力し、A,B,C,Dの選択肢を答えさせる方法ではほぼランダムに選んだ場合(チャンスレベル)の0.25前後の値になっていることが多いことが知られています。一方、continuationの評価方法、つまり、選択肢を見せずに選択肢の文章の尤度が一番高いものを選ぶ方法ではdefaultの評価方法ではチャンスレベル付近の精度だったモデルでも精度がチャンスレベルよりも高い精度になります。JMMLUに関してもMMLUと似たような傾向があることが先ほどの結果からも見て取ることができます。これと似たような考察はdatacomp-lm に書かれていますので詳しく知りたい方はこちらをご覧ください。
実際、JMMLUとMMLUのどちらもdefaultの評価ではいくつかのモデルでチャンスレベル付近の精度になっていることがわかります。ただ、PLaMo 2 2BやSakanaAI/TinySwallow-1.5B に関してはcontinuationだけでなく、defaultでもチャンスレベルよりも高い精度を達成することができています。
これに加えて、コーディングタスクのJHumanEvalやHumanEval+に関してもPLaMo 2 2Bでは高いスコアが達成できており、事後学習済みのgoogle/gemma-2-2b-jpn-itと同レベルの精度を事前学習モデルの段階で達成することができています。
Pruningの詳細
ここからは、今回用いたpruningの手法及びその結果について詳細を説明します。
Pruning手法
Pruningは学習済みのDNNモデルの重みのうち重要なものをのみを残すことで、効率よく高性能かつ小サイズなDNNモデルを得る手法です。LLMにおいてはLlama3.2がpruningによって、1Bモデルを作っています。
我々はMinitronの手法をベースにしたpruningを行いました。この手法は、structural pruningと再学習 (retraining) を組み合わせたものです。pruningの処理が比較的軽量、pruningによりアーキテクチャが変化しないので作ったモデルが使いやすい、といった理由から採用しました。
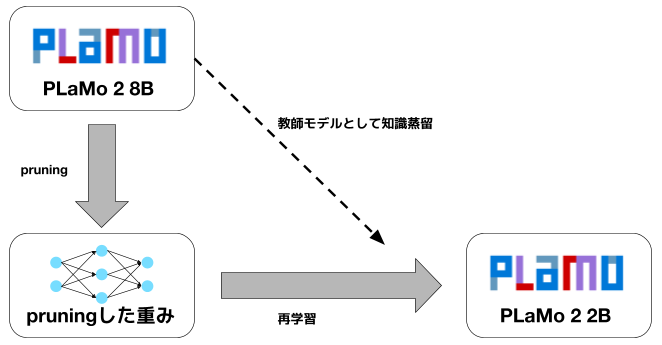
図1: Pruingの概要
PLaMo 2 8Bをpruningして初期重みを作った後、知識蒸留を組み合わせた再学習を行いました。
この手法では、まず元のモデルから重要な重みのみを残すpruningを行い、後に元のモデルを教師とした知識蒸留 (knowledge distillation)によって再学習を行います。
知識蒸留では一般的なKL距離を利用した損失関数を利用していますが、メモリ消費量の削減のため、教師のlogitsは上位128 tokenのみを使うようにしました。PLaMo 2のtokenizerは語彙数が100K個あり、対応するlogitをすべて保持するとメモリ消費量が非常に大きくなりますが、上位128個のみにすることで大幅にメモリ消費量を抑えることができました。
教師のlogitが不正確になることによる知識蒸留の効果の低下のリスクもありますが、事前検証において上位128個のみをもちいても効果が大きく変わることはないことが確かめられたため、メモリ消費量を重視しました。
学習token数は、Minitronが4Bモデルを94B token学習していたのを参考に、同じくらいのtoken数ということで100B tokenを学習にもちいています。
Pruningの効果
Pruningの効果やメリットを、PLaMo 2 2BとPLaMo 2 1Bなどを比較しつつ見ていきます。
以下に学習に使った計算量 (FLOPs) とJMMLU、JHumanEvalのベンチマークにおける性能をまとめました。また、参考として検証用に100B token学習した8Bモデルも載せています。なお、PLaMo 2 2Bの学習計算量には元となったPLaMo 2 8Bの学習計算量は含めていません。
これらの学習はデータセットがそれぞれ異なるので厳密な比較ではありませんが、大きなデータセットについては共通しており参考にできる結果と考えています。
表7: 学習計算量とモデル性能
| 学習token数 | 学習計算量
[10^18 FLOPs] |
JMMLU
(default(5 shots, acc) |
JHumanEval(0-shots, pass@1) | |
| PLaMo 2 2B | 100B token | 2800 * | 0.505 | 0.311 |
| PLaMo 2 1B | 4T token | 24000 | 0.334 | 0.189 |
| 8Bモデル (検証用) | 100B token | 4800 | 0.365 | 0.232 |
* Pruning元であるPLaMo 2 8Bの学習計算量を除き、2B自体の学習に必要な計算量と蒸留する際に利用する8Bの推論の計算量を含めた値
PLaMo 2 2Bは、3つのなかで最も少ない学習計算量でありながら、2つのベンチマークで最も高い性能を発揮しています。
今回のpruningと再学習は必要な学習計算量の観点では優れた手法であると言えそうです。なお、pruningするためには元となるモデルが必要であり、この学習にはPLaMo 2 1Bよりも大きな計算資源を利用しています。しかし、性能の高い大きなモデルはpruningをするしないに関わらず必要であり、pruningのための計算資源から抜いて考えることは不自然ではないと考えています。
このpruningの効率の良さは、モデルを小さくする上で特に重要です。モデルサイズが一定の時、学習token数を増やしていってもいずれ性能向上がほとんどみられなくなることが知られています (参考:http://arxiv.org/abs/2403.08540) 。Pruningと再学習を利用することで短いtoken数で高い性能を発揮できるということは、この問題を緩和して、モデルサイズを変えずに高い性能のモデルを学習できる可能性があると言えそうです。
また、事前学習全体で見てもpruningにはメリットがあると考えています。
使用するGPUなどの要件によって使いたいLLMのサイズは変わってきます。例えば、ともかく良い性能のモデルが必要であれば巨大なモデルを使うことになりますし、エッジデバイスでの利用を考えると1B〜2B程度のサイズのモデルが適していることが多いはずです。
このため、LLMの事前学習では、いくつかのモデルのバリエーションを作ることが求められます。従来はこの要求を満たすために大規模な学習を複数種類独立して流す必要がありました。似通った大規模な実験を複数流すことは事前学習に必要な計算資源を大きく増加させてしまいます。
今回紹介したpruningによって、無駄なく効率的に高い性能の事前学習モデルのバリエーションを用意できるようになりました。
最後に
今回は、GENIAC 第2期における事前学習の取り組みの一つとしてpruningを利用して開発したPLaMo 2 2Bのモデルの評価結果と利用したpruningについて紹介しました。現在はより大きなモデルとして30Bの学習を行っています。こちらに関しても学習が完了次第、どのような結果になったのかをblog等で共有できればと考えています。
仲間募集中
PFN/PFEでは今後もLLMの開発を継続して行っていきます。開発は今回紹介した以外にも多岐に渡ります。我々はこれらの課題に情熱をもって挑戦していく仲間を募集しています。
これらの仕事に興味がある方はぜひご応募よろしくお願いします。
https://www.preferred.jp/ja/careers/
Appendix
JMMLUのdefaultにおけるprompt
JMMLUのdefaultで利用したpromptは以下の通りです。
選択問題 問題: 48以上88以下=?以上11以下が成り立つ数を求めよ。 A. 6 B. 11 C. 8 D. 5 回答: A … 問題: ペレスさんは5日間で合計40マイルを運転した。毎日同じ距離を走った。ペレスさんは毎日何マイルを運転したか。 A. 5 B. 7 C. 8 D. 9 回答:
JMMLUのcontinuationにおけるprompt
JMMLUのcontinuationで利用したpromptは以下の通りです。
選択問題 問題: 48以上88以下=?以上11以下が成り立つ数を求めよ。 回答: 6 … 問題: ペレスさんは5日間で合計40マイルを運転した。毎日同じ距離を走った。ペレスさんは毎日何マイルを運転したか。 回答:
MMLUのdefaultにおけるprompt
MMLUのdefaultで利用したpromptは以下の通りです。
The following are multiple choice questions (with answers) about elementary mathematics. The population of the city where Michelle was born is 145,826. What is the value of the 5 in the number 145,826? A. 5 thousands B. 5 hundreds C. 5 tens D. 5 ones Answer: A … What is the value of p in 24 = 2p? A. p = 4 B. p = 8 C. p = 12 D. p = 24 Answer:
MMLUのcontinuationにおけるprompt
MMLUのcontinuationで利用したpromptは以下の通りです。
The following are multiple choice questions (with answers) about elementary mathematics. The population of the city where Michelle was born is 145,826. What is the value of the 5 in the number 145,826? Answer: 5 thousands … What is the value of p in 24 = 2p? Answer:
JHumanEvalの評価方法
promptは https://huggingface.co/datasets/kogi-jwu/jhumaneval のpromptをそのまま利用しました。
例を以下に示します。
from typing import List
def has_close_elements(numbers: List[float], threshold: float) -> bool:
"""リストnumbersの中に、与えられたthresholdより近い2つの数値が存在するか判定する
>>> has_close_elements([1.0, 2.0, 3.0], 0.5)
False
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""
また、LLMのコードの生成は以下のものでも止まるようにしました
[ "\nclass", "\ndef", "\n#", "\n@", "\nprint", "\nif", "\n```", "<file_sep>", "\nimport", "\nfrom"]
HumanEval+
promptはhttps://huggingface.co/datasets/evalplus/humanevalplus のpromptをそのまま利用しました。
例を以下に示します。
from typing import List
def has_close_elements(numbers: List[float], threshold: float) -> bool:
""" Check if in given list of numbers, are any two numbers closer to each other than
given threshold.
>>> has_close_elements([1.0, 2.0, 3.0], 0.5)
False
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""
また、LLMのコードの生成は以下のものでも止まるようにしました。
[ "\nclass", "\ndef", "\n#", "\n@", "\nprint", "\nif", "\n```", "<file_sep>", "\nimport", "\nfrom"]
WMT20のprompt
wmt20の評価はhttps://github.com/Stability-AI/lm-evaluation-harness/tree/jp-stable のものと同じものを利用しました。具体的にはen → jaは以下のようなpromptになります。
English phrase: Ford Motor and Volkswagen have said they will spend billions of dollars to jointly develop electric and self-driving vehicles. Japanese phrase: フォード・モーターとフォルクスワーゲンは、電気自動車と自動運転車の共同開発に数十億ドルを投資する予定だと発表している。 … English phrase: Dozens of fundraising coffee mornings are taking place across Scotland on Friday. Japanese phrase:
pfgen-bench の評価設定
評価設定はhttps://github.com/pfnet-research/pfgen-bench のものをそのまま利用しています。ただし、その他のモデルと合わせるため、新たに評価したモデル (Qwen2.5-7BおよびPLaMo 2 8B) も試行回数は100回としています。



