Blog
背景
Preferred Networks(以下PFN)とグループ会社のPreferred Elements(以下PFE)では2024年10月からGENIAC 第2期を開始し、その中で高性能かつ軽量なLLMの開発を行っています。この開発で、予備実験・検証として、先日blogで公開した10億 (1B) パラメータ規模のLLM (PLaMo 2 1B)に加えて80億(8B)パラメータ規模のLLM (PLaMo 2 8B) の学習を行いました。今回の記事では、PLaMo 2 8Bの開発について紹介します。
PLaMo 2 8Bのアーキテクチャや利用したデータセットに関しては、先日公開しましたPLaMo 2 1Bの記事をご覧ください。
https://tech.preferred.jp/ja/blog/plamo-2/
上記にあるように、この開発は経済産業省及び国立研究開発法人新エネルギー‧産業技術総合開発機構(NEDO)が実施する、国内の生成AIの開発力を強化するためのプロジェクト「GENIAC(Generative AI Accelerator Challenge)」の支援を受けて実施しました。
GENIAC 第2期におけるPFNとPFEの目標
今回PFNとPFEではモデルサイズを抑えたまま高い性能を実現するために高品質なデータを作成し、そのうえで小規模なモデルで高い精度を達成することを目標に活動しています。
特に、幅広い知識を測定するJMMLUやコーディングタスクであるJHumanEvalにおいて高い精度を達成することを目的の一つとしています。ここでは、現時点で得られた8Bモデルの性能検証を行った予備実験の結果について紹介します。
評価結果
最初に、開発したPLaMo 2 8Bの結果のまとめとその後に各ベンチマークの結果を示し、そのあと結果の考察を述べていきます。
結果のまとめ
まず、結果のまとめを先に紹介します。昨年開発したPLaMo 100Bと比較するとPLaMo 2 8Bは各ベンチマークで、同程度のスコア、または一部のベンチマークについてはPLaMo 100Bのスコアを超えることができました。特に日本で利用することを考えると日本特有の問題で高いスコアを達成できるかが一つ重要なポイントとなると考えられますが、この点に関してもPLaMo 100Bと同レベルのスコアを達成できており、8Bという小さいモデルながら、高い日本の知識を有したモデルになっていると考えられます。
ここから測定したベンチマークについて説明していきます。
PLaMo 2 1Bのときの評価と同様に今回も英語と日本語の両方で幅広い知識を測定するためにMMLUとその日本語訳であるJMMLUを使った評価、コーディング能力を測定するためにHumanEval+とJHumanEvalで評価しました。
また、8Bに関しては翻訳のスコアも十分上がることが確認されているので、翻訳タスクであるWMT20の結果も示します。
これに加えて、日本語の評価としてPFNで開発しているpfgen-benchの結果も示します。
比較対象としては8B以下のモデルで事前学習のデータに日本語が含まれていると考えられているモデルを選びました。
以下に各ベンチマークのスコアが具体的にどのような値であったかを示します。
JMMLU, MMLUの評価結果
まずはJMMLUとMMLUの評価結果に関してです。
JMMLUに関しては公開されているtestデータの各項目の5つのサンプルをランダムに選び、few shotの入力として利用しました。評価はLanguage Model Evaluation Harness のMMLUのコードを改良して実施しました。
また、MMLUのような選択問題に関してはpromptで性能が大きく変化することが知られています。今回は選択肢をLLMに入力し、A,B,C,Dの選択肢を答えさせる方法(Language Model Evaluation HarnessのMMLUにおけるdefaultのprompt)を利用しました。
結果は以下の通りです。
表1: JMMLU, MMLUの結果
| モデル | JMMLU (5 shot, acc) | MMLU (5 shot, acc) |
| Qwen/Qwen2.5-7B | 0.681 | 0.742 |
| tokyotech-llm/Llama-3.1-Swallow-8B-v0.2 | 0.600 | 0.622 |
| sbintuitions/sarashina2-7b | 0.400 | 0.425 |
| pfnet/plamo-100b | 0.575 | 0.603 |
| PLaMo 2 8B | 0.572 | 0.573 |
JHumanEval, HumanEval+の評価結果
次にコーディングタスクであるJHumanEvalとHumanEval+の結果を示します。
表2: JHumanEval, HumanEval+の結果
| モデル | JHumanEval(0-shot, pass@1) | HumanEval+(0-shot, pass@1) |
| Qwen/Qwen2.5-7B | 0.482 | 0.470 |
| tokyotech-llm/Llama-3.1-Swallow-8B-v0.2 | 0.232 | 0.201 |
| sbintuitions/sarashina2-7b | 0.128 | 0.128 |
| pfnet/plamo-100b | 0.268 | 0.220 |
| PLaMo 2 8B | 0.463 | 0.463 |
WMT20
次に翻訳ベンチマークの一つであるWMT20です。こちらはStability AIのlm-evaluation-harnes を修正し、評価指標としてwmt22-comet-da を利用して測定しました。このwmt22-comet-daは0から1の値を取り、数値が1に高いほど翻訳精度が高いということを示している指標になっています。
結果は以下の通りです。
表3: WMT20の結果
| モデル | wmt20 (4-shot, en → ja, wmt22-comet-da) | wmt20 (4-shot, ja → en, wmt22-comet-da) |
| Qwen/Qwen2.5-7B | 0.868 | 0.806 |
| tokyotech-llm/Llama-3.1-Swallow-8B-v0.2 | 0.900 | 0.820 |
| sbintuitions/sarashina2-7b | 0.891 | 0.805 |
| pfnet/plamo-100b | 0.899 | 0.819 |
| PLaMo 2 8B | 0.901 | 0.814 |
pfgen-bench
最後にpfgen-benchの結果を示します。pfgen-benchはPFNが開発している日本語の文章生成性能評価ベンチマークです。ベンチマークのスコアは0から1の値を取るようになっており、数値が高いほど良い日本語の文章が生成できていることを示します。
このベンチマーク結果は以下の通りです。
表4: pfgen-benchの結果
| モデル | pfgen-bench |
| Qwen/Qwen2.5-7B | 0.467* |
| tokyotech-llm/Llama-3.1-Swallow-8B-v0.2 | 0.702 * |
| sbintuitions/sarashina2-7b | 0.646 * |
| pfnet/plamo-100b | 0.747 * |
| PLaMo 2 8B | 0.752 |
* https://github.com/pfnet-research/pfgen-bench から引用
評価結果の考察
JMMLU/MMLUとJHumanEval/HumanEval+に関して
PLaMo 2 8BのJMMLUとMMLUの結果をみると、日本で開発された同レベルのサイズのsarashina2-7bと比べるとPLaMo 2 8Bのほうがより高いスコアを達成できています。これに加えて、昨年開発した10倍以上巨大なPLaMo 100Bと比べてほぼ同レベルのスコアを達成することができました。
これは昨年PLaMo 100Bの開発以降に作成したデータが、より高品質なものであったため達成できたことであると考えています。また、コーディングタスクに関してはPLaMo 100Bでは課題となっていたのですが、これについても改善し、8Bというサイズで100Bのモデルのスコアを超えることができました。
一方、Qwen2.5-7BとPLaMo 2 8Bの結果を比較すると、MMLUやHumanEval+だけでなく、JMMLUやJHumanEvalでもQwen2.5-7Bのほうが高いスコアになっています。これはJMMLUやJHumanEvalで必要な知識やコードを生成する能力は、言語に依存するところが小さいため、英語や中国語で高いスコアを達成することができるQwen2.5-7Bであれば高い精度が達成できるためであると考えられます。
また、Llama-3.1-Swallow-8B-v0.2とPLaMo 2 8BのJMMLUに関しても同じ理由で、Llama-3.1-Swallow-8B-v0.2のベースとなっているLlama-3.1の8B自体がMMLUで高いスコアが達成できているため、JMMLUでも高いスコアが達成できていると考えられます。
一方、コーディングタスクにおいてはLlama-3.1は事前学習モデル時点ではそれほど高い精度を達成しているわけではないため、品質の高いコーディングデータを学習に含めたPLaMo 2 8Bが高い精度を達成できたと考えています。
日本語に依存している部分に関しては次以降でより詳細に説明していきます。
日本語に関する能力の深堀り
上述の通り、PLaMo 2 8BはMMLUやHumanEval+といった言語への依存があまりないベンチマークにおいて、PLaMo-100Bに近い、あるいは上回る能力を獲得しています。
しかし、日本においてLLMを活用することを考えると、日本語固有の能力も重要となります。例えば地理や法律などは言語ごとに重点を置くべき知識に差がありそうです。また、用途によっては日本語を生成できる必要もあります。
こういった日本語に関する能力について、ベンチマーク結果からPLaMo 2 8Bの能力を見ていきます。
日本語固有の知識 (JMMLU 日本問題)
JMMLUには日本問題という、MMLUからの翻訳ではない問題があります。熟語、公民、日本地理、日本史の4タスクからなるこれらの問題は、英語ではあまり問われることのない日本語固有の知識・問題が集まっています。
これらJMMLU 日本語問題の性能を通して、各モデルの日本語固有知識について見ていきます。
表5: JMMLUから日本問題を抜粋
| モデル | 平均 | 熟語 | 公民 | 日本地理 | 日本史 |
| Qwen/Qwen2.5-7B | 0.77 | 0.92 | 0.85 | 0.77 | 0.52 |
| tokyotech-llm/Llama-3.1-Swallow-8B-v0.2 | 0.87 | 0.97 | 0.89 | 0.91 | 0.71 |
| sbintuitions/sarashina2-7b | 0.67 | 0.73 | 0.73 | 0.54 | 0.66 |
| pfnet/plamo-100b | 0.85 | 0.94 | 0.87 | 0.86 | 0.74 |
| PLaMo 2 8B | 0.85 | 0.97 | 0.87 | 0.85 | 0.71 |
PLaMo 2 8Bは、JMMLUの日本問題においてもPLaMo-100Bとほぼ同等の性能を発揮しています。PLaMo 2ではデータセットとして英語データの翻訳データを使っていますが、これらによって日本語固有の知識が忘れられる・失われるということがなかったことがわかります。
同サイズのモデルで比較すると、Qwen2.5-7Bとsarashina2-7bよりPLaMo 2 8Bのほうが性能が高く、Llama-3.1-Swallow-8Bは更に性能が高くなっています。
Qwen2.5-7BとPLaMo 2 8Bの差は日本語での学習量の違いに起因すると考えられます。sarashina2-7bとの差が何に起因するかは不明ですが、JMMLU全体での性能差が日本問題でも現れているのかもしれません。
一方、Llama3.1-Swallow-8BはPLaMo 2 8Bより高い性能を発揮しています。これは、swallowは学術分野の内容を重点的に用いるデータセットを用いていたのに対し、PLaMo 2はそれ以外の内容も明示的に入れているというデータセットの構成の差に起因すると思われます。
日本語生成能力 (pfgen-bench, WMT20)
日本語の生成能力について、pfgen-benchと翻訳ベンチマークであるWMT20を用いてみていきます。
PLaMo 2 8Bは、pfgen-bench、英日翻訳のどちらにおいてもPLaMo-100Bと同等以上の性能を示しており、優れた日本語の生成能力を持つことがわかります。また、同サイズのモデルと比較しても高い性能を発揮しています。
Llama3.1-Swallow-8Bに注目してみます。pfgen-benchも日本語特有の知識を問うという点ではJMMLU 日本問題と同じですが、pfgen-benchではPLaMo 2 8Bのほうが性能が高いという結果になりました。
この原因には選択肢問題か記述問題かの違いなど様々な要因が考えられますが、1つの要因としてはデータセットの構成があると考えています。
JMMLU 日本問題が学校教科を念頭においた質問なのに対し、pfgen-benchでは学校教科としては登場しない・しにくい問も含まれます (例: Q43. 天空の城ラピュタはどのような作品ですか?)。このような質問に適切に答えるには、学術分野以外のテキストを明示的に残したPLaMo 2でのデータセットのほうが向いているのだろうと考えられます。
学習の詳細
ここからは、今回の学習について紹介します。
今回の学習は基本的にPLaMo 2 1Bを踏襲しました。ただ、データセットはPLaMo 2 1Bの学習後に生成したデータを追加で使用しています。
今回新たに取り入れた手法としては、weight reusingがあります。
weight reusingは、より小さなDNNモデルの重みを使って大きなDNNモデルの初期値を決める手法です。LLMにおいては、NeurIPSのPhi-2の発表において、phiシリーズでの利用が紹介されています。
事前に小規模な学習で検証したところ、weight reusingにより大きな性能向上が確認できました。weight reusingをすることで学習初期のtrain lossの下がりが大幅に改善されており、学習後半でもtrain lossはランダムな初期値よりも良くなっています。各種downstream taskの性能でも改善が見られました。
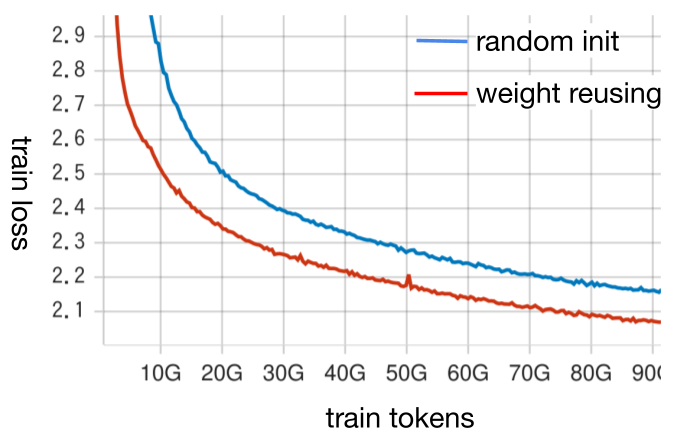
図: weight reusingの実験時のtrain loss。青が8Bモデルをランダムな初期値から学習した場合、赤がweight reusingを使った初期値から学習した場合。
一般にこのような手法は、学習を長くしていくと効果が小さくなっていく、あるいは逆効果となることが予想されます。
しかし、LLMにおいては学習を長くするための計算資源が膨大であるため、weight reusingの効果があるケースの方が多いだろうと考えています。
最後に
今回は、GENIAC 第2期における事前学習の取り組みについて紹介しました。現在はこの結果をもとによりモデルサイズなどの規模を大きくした事前学習の実験に移ると同時に、PLaMo 2 8Bの事後学習を進めています。
今回学習したPLaMo 2 8Bに関してもPLaMo 2 1Bと同様に、何等かの形でモデルの重みを公開することを検討しています。
仲間募集中
PFN/PFEでは今後もLLMの開発を継続して行っていきます。開発は今回紹介した以外にも多岐にわたります。我々はこれらの課題に情熱をもって挑戦していく仲間を募集しています。
これらの仕事に興味がある方はぜひご応募よろしくお願いします。
https://www.preferred.jp/ja/careers/
Appendix
JMMLUのprompt
JMMLUのdefaultで利用したpromptは以下の通りです。
選択問題 問題: 48以上88以下=?以上11以下が成り立つ数を求めよ。 A. 6 B. 11 C. 8 D. 5 回答: A … 問題: ペレスさんは5日間で合計40マイルを運転した。毎日同じ距離を走った。ペレスさんは毎日何マイルを運転したか。 A. 5 B. 7 C. 8 D. 9 回答:
MMLUのprompt
MMLUのdefaultで利用したpromptは以下の通りです。
The following are multiple choice questions (with answers) about elementary mathematics. The population of the city where Michelle was born is 145,826. What is the value of the 5 in the number 145,826? A. 5 thousands B. 5 hundreds C. 5 tens D. 5 ones Answer: A … What is the value of p in 24 = 2p? A. p = 4 B. p = 8 C. p = 12 D. p = 24 Answer:
JHumanevalのprompt
promptは https://huggingface.co/datasets/kogi-jwu/jhumaneval のpromptをそのまま利用しました。
例を以下に示します。
from typing import List
def has_close_elements(numbers: List[float], threshold: float)->; bool:
"""リストnumbersの中に、与えられたthresholdより近い2つの数値が存在するか判定する
>>> has_close_elements([1.0, 2.0, 3.0], 0.5)
False
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""
また、LLMのコードの生成は以下のものでも止まるようにしました
[ "\nclass", "\ndef", "\n#", "\n@", "\nprint", "\nif", "\n```", "<|file_sep|>", "\nimport", "\nfrom"]
HumanEval+ のprompt
promptは https://huggingface.co/datasets/evalplus/humanevalplus のpromptをそのまま利用しました。
例を以下に示します。
from typing import List
def has_close_elements(numbers: List[float], threshold: float) ->; bool:
""" Check if in given list of numbers, are any two numbers closer to each other than
given threshold.
>>> has_close_elements([1.0, 2.0, 3.0], 0.5)
False
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""
また、LLMのコードの生成は以下のものでも止まるようにしました
[ "\nclass", "\ndef", "\n#", "\n@", "\nprint", "\nif", "\n```", "<|file_sep|>", "\nimport", "\nfrom"]
WMT20のprompt
wmt20の評価はhttps://github.com/Stability-AI/lm-evaluation-harness/tree/jp-stable のものと同じものを利用しました。具体的にはen → jaは以下のようなpromptになります。
English phrase: Ford Motor and Volkswagen have said they will spend billions of dollars to jointly develop electric and self-driving vehicles. Japanese phrase: フォード・モーターとフォルクスワーゲンは、電気自動車と自動運転車の共同開発に数十億ドルを投資する予定だと発表している。 … English phrase: Dozens of fundraising coffee mornings are taking place across Scotland on Friday. Japanese phrase:
pfgen-bench の評価設定
評価設定はhttps://github.com/pfnet-research/pfgen-bench のものをそのまま利用しています。ただし、その他のモデルと合わせるため、新たに評価したモデル (Qwen2.5-7BおよびPLaMo 2 8B) も試行回数は100回としています。



