Blog
大規模言語モデル (LLM) は日進月歩で進化しており、日本語の理解能力についても多くの言語モデルがしのぎを削っています。先日PFNからも、日英2言語を併せた能力で世界トップレベルの性能を示す言語モデルPLaMo-13Bを公開*しました。
一方で、LLMを実際のタスクに適用する場合には、事前学習モデルやファインチューニングによる改善もさることながら、プロンプトの違いが性能を大きく左右します。本稿ではプロンプトを自動的にチューニングすることによって、LLMの能力を最大限に引き出し、与えられた課題の精度をどこまで高められるのかを検証します。
* 本稿で解説するプロンプトチューニング技術は、PLaMo-13B公開時の性能評価には用いていません。
プロンプトエンジニアリングについて
LLMを使ったチャットシステムでは、ユーザーからの問い合わせ内容を改変してLLMに入力することがあります。例えば、図1のように、問い合わせの前後に特定の文章を加えたり、言い換えるなどの改変を施します。このテクニックは、チャットシステムにキャラクターを持たせたり、システムの性能を底上げするためのものです。例えば、本来のクエリに「あなたはカスタマーサポートセンターのオペレーターです。以下のユーザーの問い合わせに回答してください:」というヘッダーを加えるだけで、オペレーターのようなキャラクターを演出することができます。
このような改変を加えることを”プロンプトエンジニアリング”と呼び、その雛形を”プロンプトテンプレート”と呼びます。

図1: LLMとプロンプトテンプレートの関係。例えばカスタマーサポートの自動応答システムの場合、望ましいキャラクターや質問・応答の例をテンプレートに記述する。
通常、プロンプトテンプレートは、システム設計者の試行錯誤によって作成されますが、これを自動化する技術も提案されています。例えばZhou et al.[1]は、遺伝的アルゴリズムによって逐次的にプロンプトを改善することで、人間のエキスパートが作成したものと同等の精度を示すプロンプトを自動的に発見しています。
日本語LLMベンチマークにおけるプロンプトテンプレート
日本語LLMベンチマークにおいても、プロンプトテンプレートは重要な要素となります。というのも、多くのベンチマークでは、問題をそのままLLMに入力するのではなく、プロンプトテンプレートを介して変換されたものを入力します。そして、プロンプトテンプレートはベンチマークの種類によって少しずつ異なっていたり、評価者が複数のプロンプトテンプレートの中から特定のものを選べるようになっています。
例えば、Stability AIから公開されている日本語LLMベンチマーク (以下、Stableベンチマークと表記) には、4種類のプロンプトテンプレートが用意されています。表1は、StableベンチマークにおけるJCommonSenseQAタスクのためのプロンプトテンプレートを示しています。文言は微妙に違いますが、意味するところはほとんど変わりません。また、中には「システム:」「ユーザー:」といった、特定のモデルの性能をより引き出すためと思われる接頭辞が追加されているものもあります。
表1: StableベンチマークのJCommonSenseQAタスクにおけるプロンプトテンプレートの一覧。どのテンプレートを使うかは評価者の裁量によるため、リーダーボード上のモデルは必ずしも同じテンプレートにより評価されているとは限らない。
| プロンプトバージョン | プロンプトテンプレート |
| 0.1 | [問題]:{{question}}\n[選択肢]:\n[{{option_0}},{{option_1}},{{option_2}},{{option_3}},{{option_4}}]\n[答え]: |
| 0.2 | 質問:{{question}}\n選択肢:0.{{option_0}},1.{{option_1}},2.{{option_2}},3.{{option_3}},4.{{option_4}}\n回答: |
| 0.3 | ### 指示:\n与えられた選択肢の中から、最適な答えを選んでください。出力は以下から選択してください:\n- {{option_0}}\n- {{option_1}}\n- {{option_2}}\n- {{option_3}}\n- {{option_4}}\n### 入力:\n{{question}}\n### 応答: |
| 0.4 | ユーザー: 質問:{{question}}<NL>選択肢:<NL>- {{option_0}}<NL>- {{option_1}}<NL>- {{option_2}}<NL>- {{option_3}}<NL>- {{option_4}}<NL>システム: |
プロンプトテンプレートを変えることで、どこまでベンチマークのスコアが変わるのでしょうか。
実は劇的に変化します。図2はプロンプトテンプレートを変化させた時の精度を比較したものです。人間からするとそれぞれの意味合いは大して変わらないにも関わらず、違うプロンプトによって20ポイント以上の精度の違いが出ています。同じプロンプトで別のモデルを比較した際の精度差がたかだか15ポイント程度ですから、20ポイント以上の変動を見せるプロンプトテンプレートの差異は、決して無視できるものではないことがわかります。
言語モデルの真の性能を引き出すためには、モデルそのものだけでなく、プロンプトテンプレートにも工夫が必要となります。
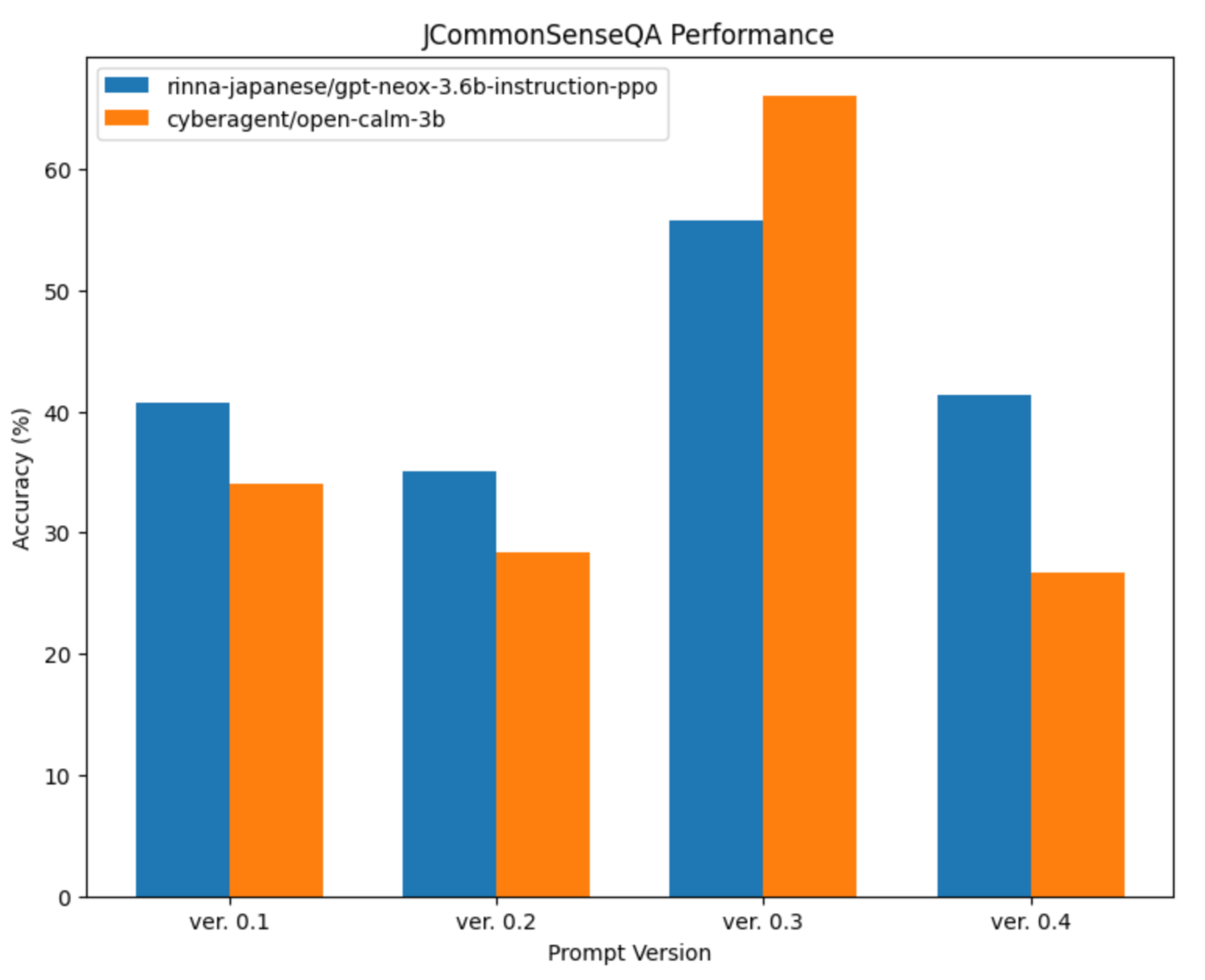
図2: StableベンチマークのJCommonSenseQAタスクにおいて、異なるプロンプトテンプレートを使って評価したときのrinna/japanese-gpt-neox-3.6b-instruction-ppoとcyberagent/open-calm-3bのスコアの変化。テンプレートを変更することで、大きく精度が変化したり、モデルの順位関係が入れ替わることもある。
プロンプトの自動チューニング
以下では、自動的にプロンプトをチューニングするためのアルゴリズムを解説します。その後、StableベンチマークのJCommonSenseQAタスクを対象とし、自動チューニングによる精度の伸び代を検証します。
何をチューニングするか
まずは、チューニングの対象となるプロンプトの構造を詳しく見てみましょう。JCommonSenseQAの評価用データには数千個の設問が用意されており、それぞれの設問について、図3に示されるようなプロンプトが評価対象のLLMに入力されます。その結果LLMが選択した答えと、実際の正解を照合し、設問全体を通した精度がベンチマークのスコアとなります。
LLMに入力されるプロンプトは、以下の3つの部分で構成されています。
- Instruction: LLMへの指示を簡潔に述べています。
- Few-shot Examples: 質問応答のやり方を例示することで、LLMが期待するフォーマットで回答するように誘導しています。このテクニックはFew-shotプロンプティングと呼ばれています。
- Question: 設問の本体です。

図3: 対象のベンチマークタスクにおけるプロンプトの構造。冒頭に簡潔な指示があり、質問応答の例がいくつか提示されたのち、最後に質問の本文が提示される。
Few-shot ExamplesとQuestionは以下のようなテンプレートに従っていることがわかります。このテンプレートにいくつかのバージョンがあることで、前節で述べたような大きなパフォーマンスの差が生まれています。
| {{question_body}}に対して、以下の選択肢から一つ答えを選んでください: – {{option_0}} – {{option_1}} – {{option_2}} – {{option_3}} – {{option_4}} 答えを入力してください: |
以下で述べる探索アルゴリズムによって、プロンプトテンプレートを逐次的に変更し、ベンチマークのスコアが高くなるようにチューニングしていきます。
探索アルゴリズム
図4は探索パイプラインの概要を、図5はアルゴリズムを示します。種となる数種類のテンプレートから始めて、遺伝的アルゴリズムによってテンプレートを交叉・突然変異させていきます。交叉・突然変異によって得られたテンプレートを使ってベンチマークの評価を行い、テンプレートとそのスコアの関係を記録しておきます。親となるテンプレートは、ベンチマークの評価が高いものが高確率で選ばれるよう、トーナメント戦略によって決定します。
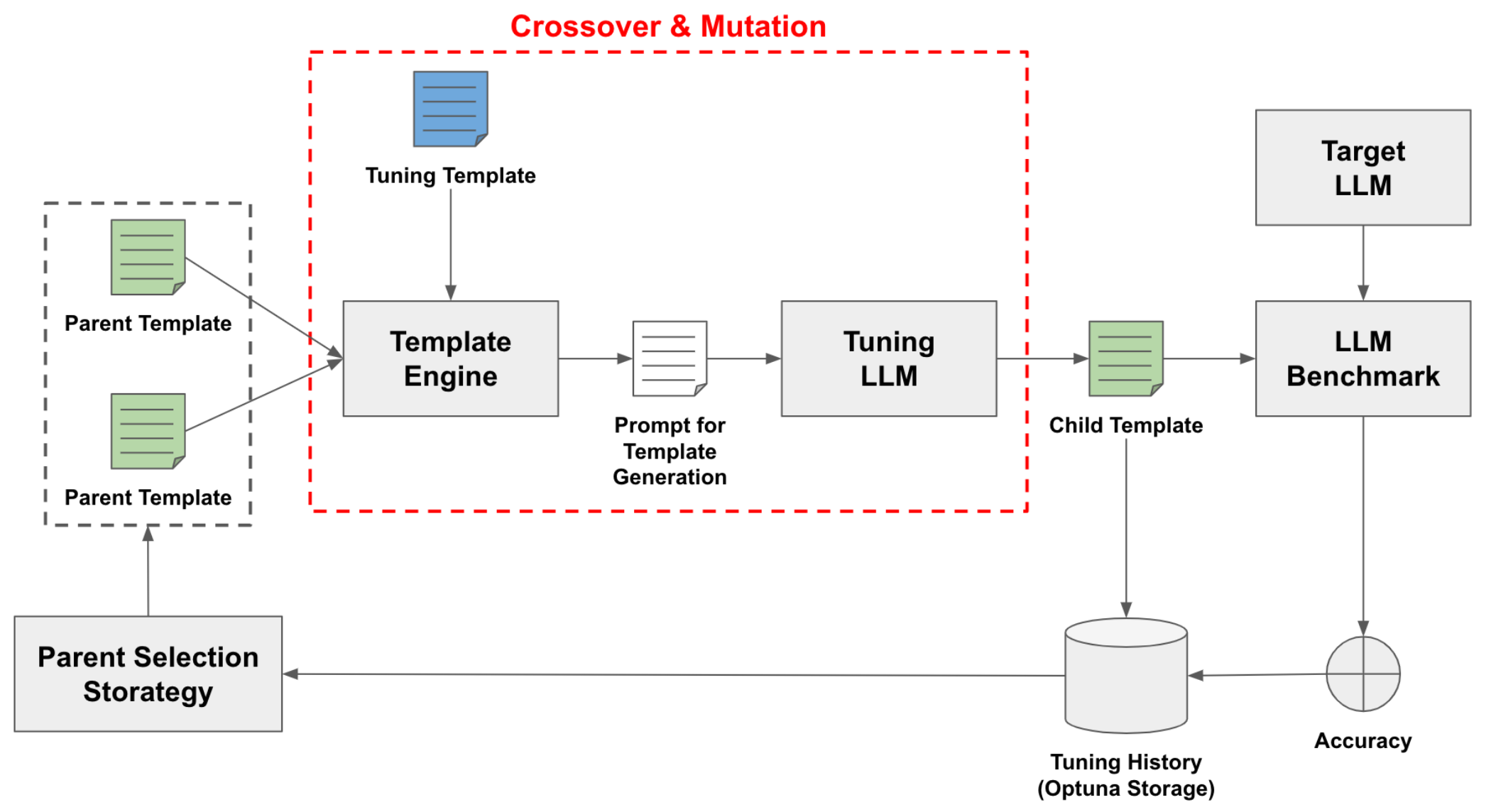
図4: プロンプトテンプレートの探索パイプライン。2個の親テンプレート (Parent Template) を交差・突然変異させることで子テンプレート (Child Template) を生成し、子テンプレートを使ったLLMベンチマークの評価を行う。親テンプレートは過去の探索履歴から、特定の選択戦略によって決定される。このサイクルを何度も繰り返すことで子テンプレートが改善されていく。なお、交差・突然変異については図6にて詳述する。

図5: プロンプトテンプレートの最適化アルゴリズム。イテレーション毎に2個の親テンプレートを選択し、交叉・突然変異させることで新しいテンプレートを生成する。
ここで、交叉・突然変異とは、具体的には図6に示すようなプロンプトをLLMにクエリする操作のことを指します。親となるテンプレートをfew-shot学習の形で提示し (交叉)、「これらのテンプレートを言い換えた新しいテンプレートを出力してください」という命令でリフレーズしています (突然変異)。交叉・突然変異の操作を行うLLM (図4のTuning LLM) は、評価対象のLLM (図4のTarget LLM) と必ずしも同じものである必要はありません。
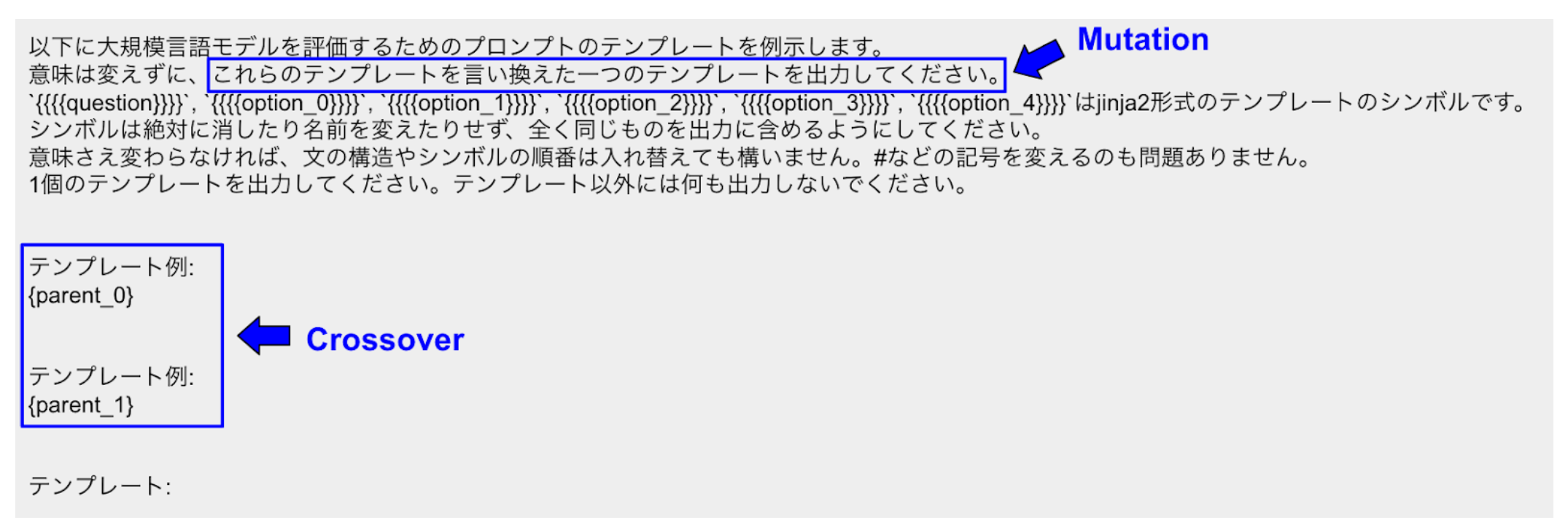
図6: 交叉・突然変異のためのプロンプト。{parent_0}及び{parent_1}の部分に親テンプレートを貼り付け、リフレーズ用のLLMに入力する。
評価実験
実験設定
前節で述べた探索アルゴリズムを検証するための実験を行いました。公開されている4つの言語モデルについて、JCommonSenseQAにおけるスコアに基づいてプロンプトテンプレートをチューニングし、アルゴリズムによる改善度合いを評価しました。以下に、実験の詳細を示します。
- 評価対象のベンチマーク
- JCommonSenseQA (Stableベンチマーク版)
- 評価対象の言語モデル
- rinna/japanese-gpt-neox-3.6b-instruction-ppo
- cyberagent/open-calm-3b
- stabilityai/japanese-stablelm-base-alpha-7b
- pfnet/plamo-13b
- テンプレートの言い換えに利用した言語モデル
- text-davinci-003
- 遺伝的アルゴリズムの設定
- トライアル総数: 400
- 世代毎のトライアル数: 20
- 最大並列数: 6
通常のStableベンチマークでは、JCommonSenseQAの訓練データセットを全てFew-shot学習のために利用していますが、今回は訓練データセットを分割し、2割をチューニング中の評価データセット(以下、Devデータセットと表記)とし、残りの8割をFew-shot学習に利用しました。テストデータセットは、チューニングの結果得られたプロンプトテンプレートを改めて評価するために利用しました。また、Few-shot学習では設問毎に2個の例をランダムに選択しました。
結果
図7は、チューニングの前後でのベンチマークスコアの変化を示しています。左のグループ (Baseline) はStableベンチマークのリーダーボードにおける3つの言語モデルのスコアとPFNで評価したPLaMo-13Bのスコアです。中央のグループ (GA-optimized Dev) は、チューニングされたプロンプトテンプレートを使った際のDevデータセットのスコアです。右のグループ (GA-optimized Test) は同様のプロンプトテンプレートを使ったテストデータセットでのスコアを示します。
いずれの言語モデルにおいても、チューニングされたプロンプトテンプレートを使うことで、スコアが大きく向上しています。モデル間のスコアの差よりも、プロンプトテンプレートによる差が目立っており、最大で50ポイント程度の改善が見られます。
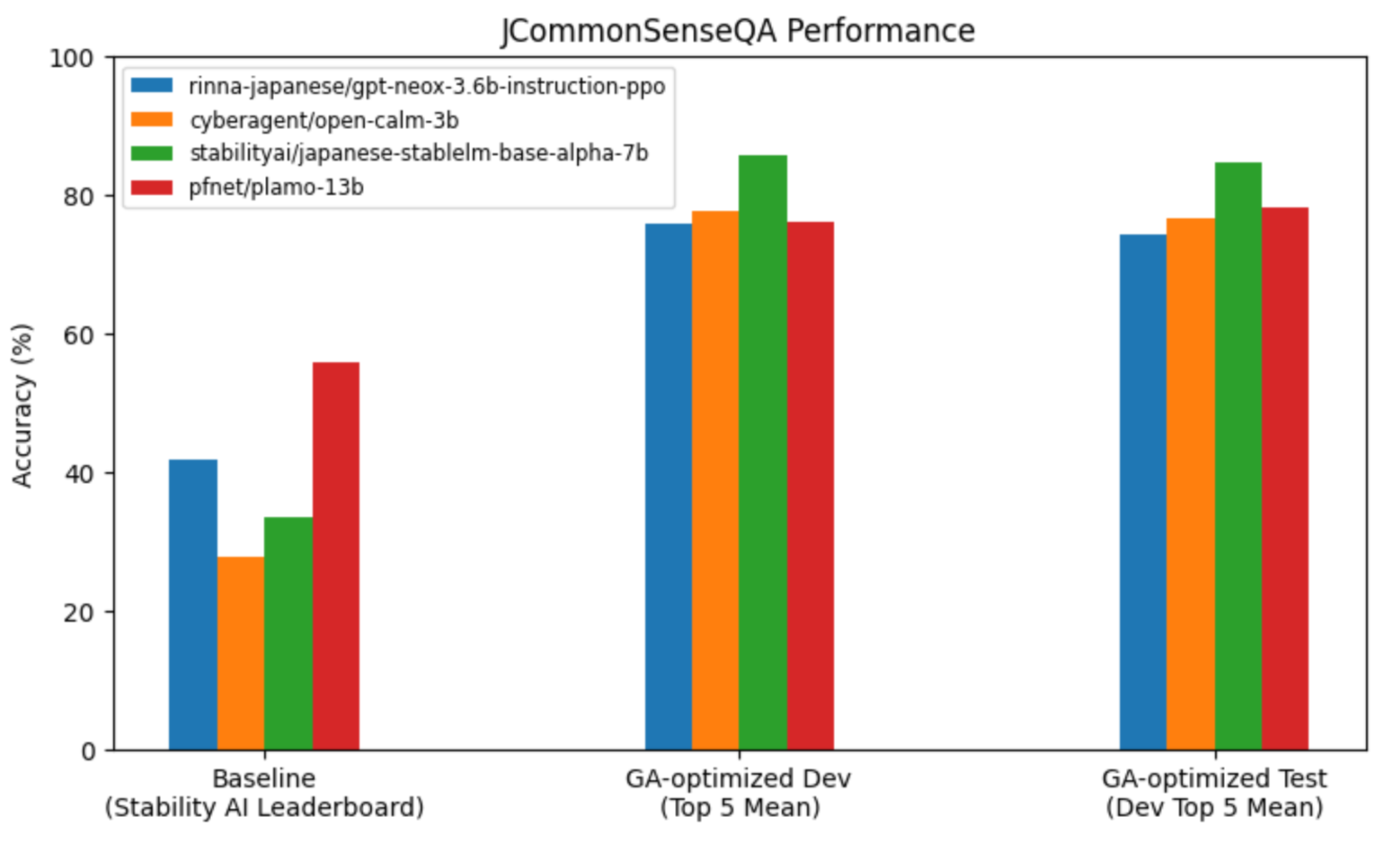
図7: ベースラインのテンプレート (左のグループ) と最適化されたテンプレート (中央・右のグループ) の精度の比較。いずれの言語モデルにおいても、プロンプトの最適化により、大きな精度の改善が見られる。これらの改善幅は、ベースラインにおける言語モデル間の精度差を大きく上回っている。なお、ベースラインの評価はpfnet/plamo-13bについてはPFNが公開したブログの設定に基づき、プロンプトバージョンは0.3である。それ以外の3モデル (rinna-japanese/gpt-neox-3.6b-instruction-ppo・cyberagent/open-calm-3b・stabilityai/japanese-stablelm-base-alpha-7b) についてはStableベンチマークの設定に基づき、プロンプトバージョンはそれぞれ0.4・0.2・0.2である。
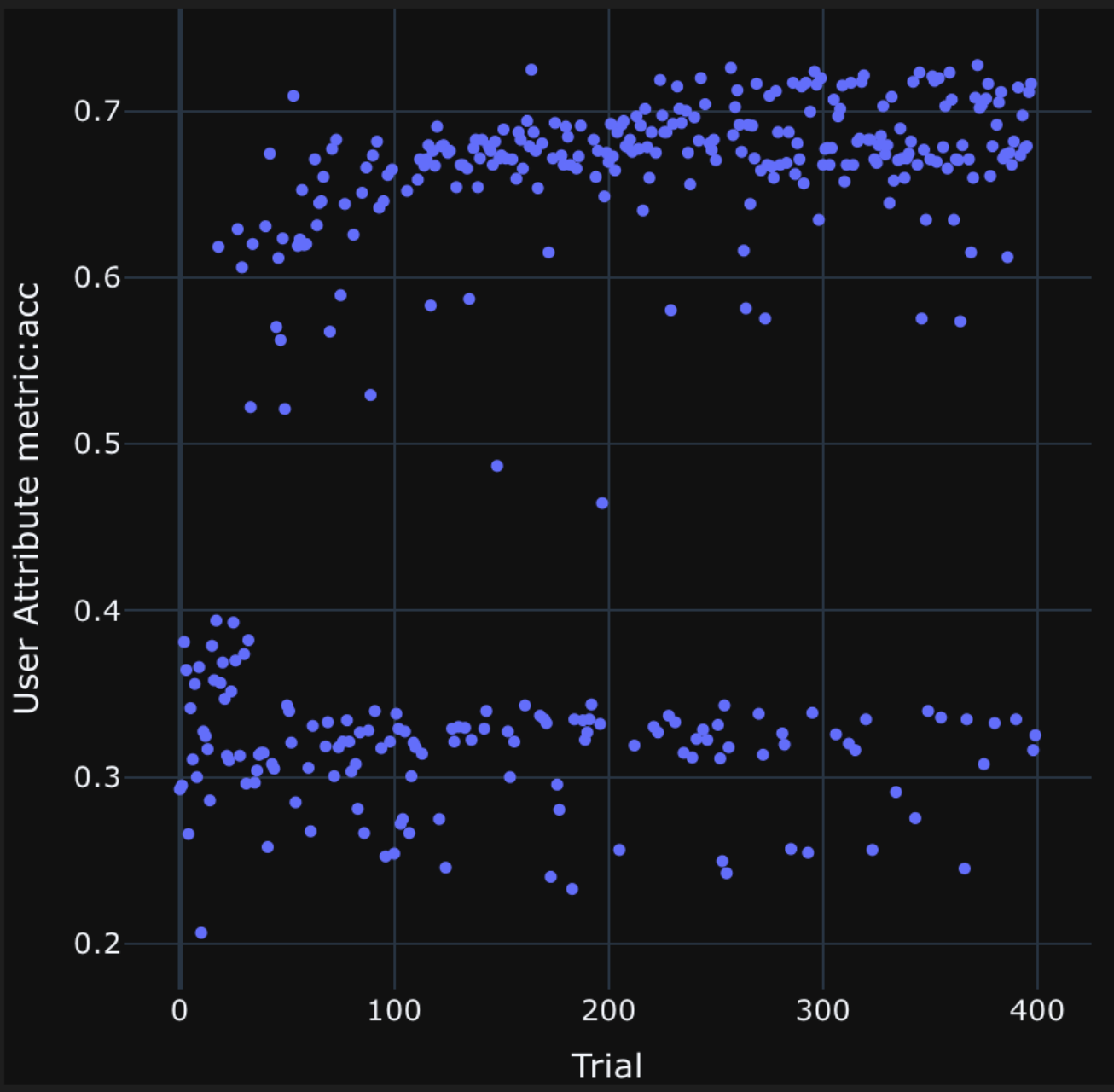
図8: rinna/japanese-gpt-neox-3.6b-instruction-ppoを対象として、JCommonSenseQAタスクのプロンプトを最適化した際の、精度の推移。遺伝的アルゴリズムのイテレーションが進むにつれて、より精度が高くなるプロンプトテンプレートが提案されている。
表2は、4つの言語モデルそれぞれについて、ベースラインのプロンプトテンプレートと、上位のスコアを記録したプロンプトテンプレートを示しています。最適化されたプロンプトテンプレートにおいても、文章の意味は変わっていません。一方で、多くの言語モデルについて、プロンプトを以下のように与えた方が高い精度を示すことがわかりました。
- 質問の本文{{question}}をテンプレートの後半に置くこと
- 『選択肢』という単語ではなく『以下から正しい答えを選んでください』のように文章で意図を伝えていること
言われてみると当たり前に感じてしまいますが、探索しないと気づきにくいテクニックですね。また、プロンプトの締めくくり方や、選択肢を列挙する際のフォーマットなどは、言語モデル毎に違っており、こういった細部では得意とするプロンプトの機微があるようです。
表2: 最適化されたプロンプトテンプレートの例。ベースラインのプロンプトテンプレートはpfnet/plamo-13bについてはPFNが公開したブログの設定に基づく。それ以外の3モデルについてはStableベンチマークの設定に基づく。
| 言語モデル | ベースラインのテンプレート | 最適化されたテンプレート |
| rinna-japanese/gpt-neox-3.6b-instruction-ppo | ユーザー: 質問:{{question}}<NL>選択肢:<NL>- {{option_0}}<NL>- {{option_1}}<NL>- {{option_2}}<NL>- {{option_3}}<NL>- {{option_4}}<NL>システム: | \n\n以下より選択してください:{{option_0}}, {{option_1}}, {{option_2}}, {{option_3}}, {{option_4}}:\n\n[質問]:{{question}}? |
| cyberagent/open-calm-3b | 質問:{{question}}\n選択肢:0.{{option_0}},1.{{option_1}},2.{{option_2}},3.{{option_3}},4.{{option_4}}\n回答: | \n\n以下から解答を選択してください:{{option_0}}, {{option_1}}, {{option_2}}, {{option_3}}, {{option_4}}\n質問:{{question}}\n回答: |
| stabilityai/japanese-stablelm-base-alpha-7b | 質問:{{question}}\n選択肢:0.{{option_0}},1.{{option_1}},2.{{option_2}},3.{{option_3}},4.{{option_4}}\n回答: | \n\n正しい答えは?\n– {{option_0}}\n– {{option_3}}\n– \n{{option_4}}\n– {{option_2}}\n– {{option_1}}\n\n質問: {{question}}\n回答: |
| pfnet/plamo-13b | ### 指示:\n与えられた選択肢の中から、最適な答えを選んでください。出力は以下から選択してください:\n– {{option_0}}\n– {{option_1}}\n– {{option_2}}\n– {{option_3}}\n– {{option_4}}\n\n### 入力:\n{{question}}\n\n### 応答: | \n\n正しい答えは何でしょう?\n0.{{option_0}}\n1.{{option_1}}\n2.{{option_2}}\n3.{{option_3}}\n4.{{option_4}}\n問題:{{question}}\n回答: |
考察
ちょっとしたプロンプトの違いがLLMの精度に大きな影響を及ぼすことがわかりました。また、簡素なプロンプト探索アルゴリズムを適用することで、特にStableベンチマークのJCommonSenseQAにおいては50ポイント以上の改善も見られることがあると示されました。これらの検証結果より、2つの異なる知見が伺えます。
プロンプトチューニングの重要性と自動化可能性
LLMの性能を引き出すためには、探索的なプロンプトエンジニアリングが重要であり、このプロセスを自動化することができます。実験により、遺伝的アルゴリズムを用いてプロンプトテンプレートを逐次的に言い換えていくことで、JCommonSenseQAの精度を大きく底上げできることがわかりました。
本稿の検証ではシンプルな探索空間に遺伝的アルゴリズムを適用しましたが、研究コミュニティにおいては、より発展的な探索手法も提案されています。例えば、Zhou et al.[1]は遺伝的アルゴリズムの初期集団となるプロンプトを手動設計せず、Instruction Inductionと呼ばれる方法で自動生成しています。また、Chen et al.[2]は探索アルゴリズムにベイズ最適化を組み込むことで、より効率的な探索を実現しています。
LLMベンチマークのセンシティビティ
LLMベンチマークはプロンプトの差異に大きな影響を受け、精度の差は必ずしも言語モデル本体の性能差を正しく反映しているとは限りません。比較評価の際には、プロンプトの前提をよく確かめ、文言との微妙な噛み合わせによって精度や順位関係がどこまで変化するかを考慮に入れる必要があります。ただし、具体的にどのように比較すれば、よりフェアで安定したベンチマークになるかについては、未だ確実なことは言えないため、この点は今後のコミュニティの課題になると考えます。
おわりに
PFNグループではLLM・基盤モデルの開発と活用に取り組む仲間を募集しています。本稿で紹介したような応用上のテクニックに留まらず、自社製言語モデル (PLaMo) の大規模学習からマルチモーダルへの拡張、お客様へのソリューション提供まで、PFNグループでの基盤モデルへの取り組みは多岐に渡ります。ご興味のある方は、是非ご応募ください。
参考文献
- [1] Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, Jimmy Ba. Large Language Models Are Human-Level Prompt Engineers. (arXiv)
- [2] Lichang Chen, Jiuhai Chen, Tom Goldstein, Heng Huang, Tianyi Zhou. InstructZero: Efficient Instruction Optimization for Black-Box Large Language Models. (arXiv)
