Blog
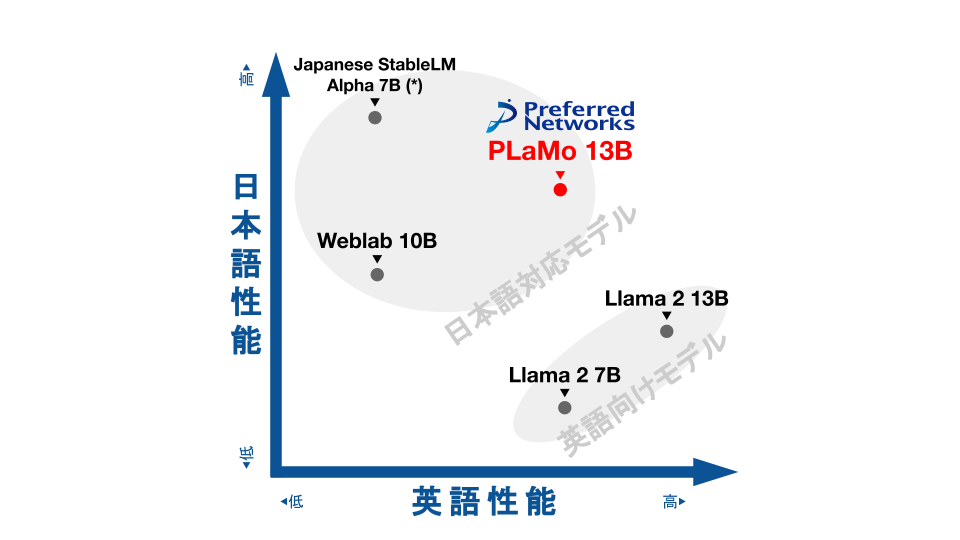
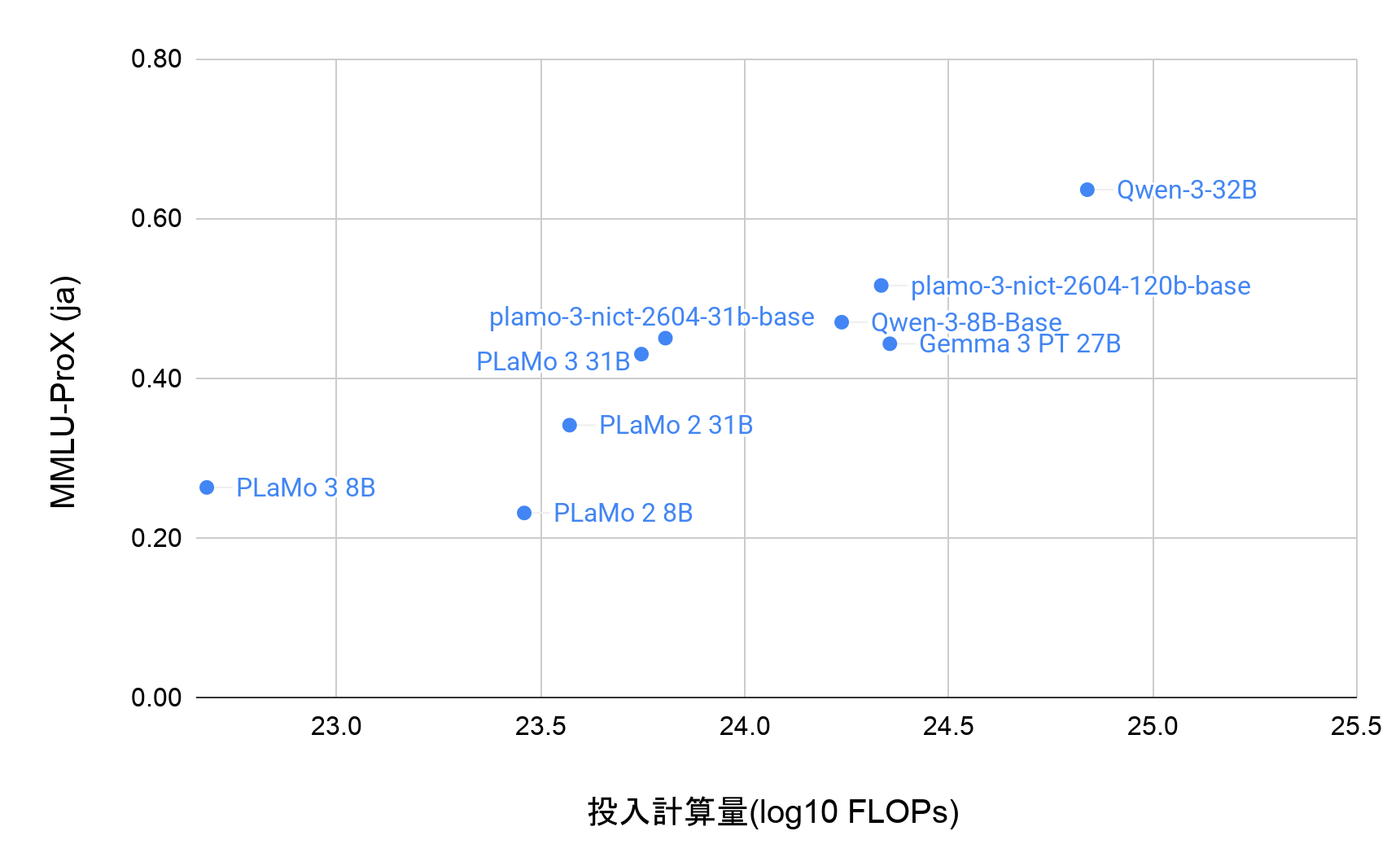
図1: 日英2言語での性能比較(スコアの算出方法についてはAppendix Bを参照)
Preferred Networksでは、9月28日にPLaMo-13Bという大規模な言語モデル (LLM) を公開しました。公開されている他のモデルと比較して、日英2言語を合わせた能力で世界トップレベルの高い性能を示しています。実際に学習を回すまでの技術開発には自社スーパーコンピューターであるMN-2を利用し、学習はAI橋渡しクラウド(AI Bridging Cloud Infrastructure、ABCI) の”第一回 大規模言語モデル構築支援プログラム”を利用して行いました。
今後、PLaMo-13Bを基にした事前学習モデルや、指示学習を行ったモデルについても公開を予定しています。
PLaMo-13Bの概要
PLaMo-13Bは約130億個のパラメータからなる言語モデルです。
PLaMo-13Bは日本語・英語の2つの言語のベンチマークタスクで高い性能を示しています。日本で使われるLLMにおいて、高い日本語能力の必要性は言うまでもないと思います。一方で、LLMを用いて英語の文章を読み書きしない場合においても英語能力が重要となると我々は考えています。世の中のプログラムの多くが英語で書かれていますし、外部ツールを呼び出すような応用をする場合そのためのAPIは英単語を使うことがほとんどです。したがって、日本語のためのLLMであっても、英語が理解できることは不可欠だと考えています。
また、PLaMo-13Bは公開データセットのみで学習され、Apache License 2.0で公開されたOpen Source Software (OSS) であるという点も特徴と言えます。8月中旬にBooks3データセットが公開取り下げとなり停止されましたが、PLaMo-13Bはこれに対応しBooks3データセットを使わずに学習しています。PLaMo-13Bは、LLMとしての使用の他、データセットの生成やフィルタリングなど、目的に制限なく様々な用途に利用していただけます。なお、PLaMo-13BはLLMですので、事実と異なる文章や、社会の価値観にそぐわない文章を生成することがあり得ます。このようなLLMの特性をよく理解した上で、適切にご利用ください。
使用方法
以下のpythonコードでPLaMo-13Bを試すことができます。
import transformers
pipeline = transformers.pipeline(
"text-generation", model="pfnet/plamo-13b", trust_remote_code=True
)
print(
pipeline(
"The future of artificial intelligence technology is ", max_new_tokens=32
)
)
PLaMo-13Bの特徴・詳細
PLaMo-13Bの特徴・詳細について紹介します。
ベンチマーク結果
まず、モデルの特徴を示すためにベンチマークタスクの結果を抜粋して紹介します。詳細な結果や評価の設定はAppendix Aをご覧ください。
多くのLLMは事前学習を行い、その後目的に合わせてファインチューニングを行います。PLaMo-13Bはファインチューニングをしていない事前学習モデルであるので、いくつかの事前学習モデル(ファインチューニングを含まないモデル)と比較します。
日本語を学習したLLMとしては、Stability AIが公開したJapanese StableLM Alpha 7Bと東京大学松尾研究室が公開したweblab-10B を、英語をメインとしたLLMとしてLLaMA-2の7Bおよび13Bをとりあげます。
| 日本語 | 英語 | |||||
| JCommonsenseQA (acc_norm) | MARC-ja (acc_norm) | JSQuAD (exact_match) | arc_challenge (acc_norm) |
arc_easy (acc_norm) |
piqa (acc_norm) |
|
| PLaMo-13B | 53.4 | 95.8 | 70.6 | 40.3 | 64.8 | 76.1 |
| Japanese StableLM Alpha 7B | 27.7 | 96.7 | 70.6 | 33.7 | 63.3 | 73.4 |
| Japanese StableLM Alpha 7B (PFNによるプロンプト変更後) |
75.9 | 96.7 | 70.6 | 33.7 | 63.3 | 73.4 |
| LLaMA 2 7B | 29.2 | 86.0 | 58.4 | 40.6 | 53.6 | 76.9 |
| LLaMA 2 13B | 40.0 | 38.9 | 76.1 | 44.2 | 58.0 | 79.1 |
| weblab-10b | 61.6 | 82.1 | 62.9 | 35.0 | 63.2 | 76.3 |
このベンチマーク結果から、PLaMo-13Bは
- 日本語のベンチマークにおいて、日本語を学習したその他のLLMと同等程度の性能を持つ
- 英語のベンチマークにおいて、LLaMA 7Bと同等程度の性能を持つ
- LLaMA2 13Bと比較すると英語ベンチマークは劣る
というLLMであることが言えます。
すなわち、
- どちらかの言語に重点を置く7Bクラスのモデルと、重点をおいた言語で同等程度 (例えば、LLaMA2 7Bと英語性能で同等程度)
- どちらかの言語に重点をおいた13Bクラスのモデルよりは、重点をおいた言語で劣る (例えば、LLaMA2 13Bより英語性能は劣る)
という性能であると言えます。
Japanese StableLM Alpha 7Bとweblab-10bは日本語を学習したLLMとして最大規模であり、PLaMo-13Bはトップクラスの日本語理解の能力に加えてそれらのモデルより高い英語理解の能力を持っていると言えます。
学習設定
事前学習の設定について紹介します。
データセット
学習に使ったデータセットは以下の3つです。割合としては英語データセットを多く学習していることになります。
日本語を効率良く扱うため、tokenizerはsentencepieceを使って学習したものを用いました。
| データセット名 | 主な言語 | 使用割合 |
| RedPajamaからbooks3を抜いたデータセット | 英語 | 87.7% |
| mc4 (日本語のみ) | 日本語 | 12.0% |
| wikipeda (日本語のみ) | 日本語 | 0.3% |
DNNアーキテクチャ
DNNの基本構造はLLaMA [1]を踏襲しました。将来の高速化の余地を大きくするため以下の2つの変更をLLaMAに加えました。
- Grouped Query Attention (GQA) の利用 [2]
- Parallel Layers の利用 [3]
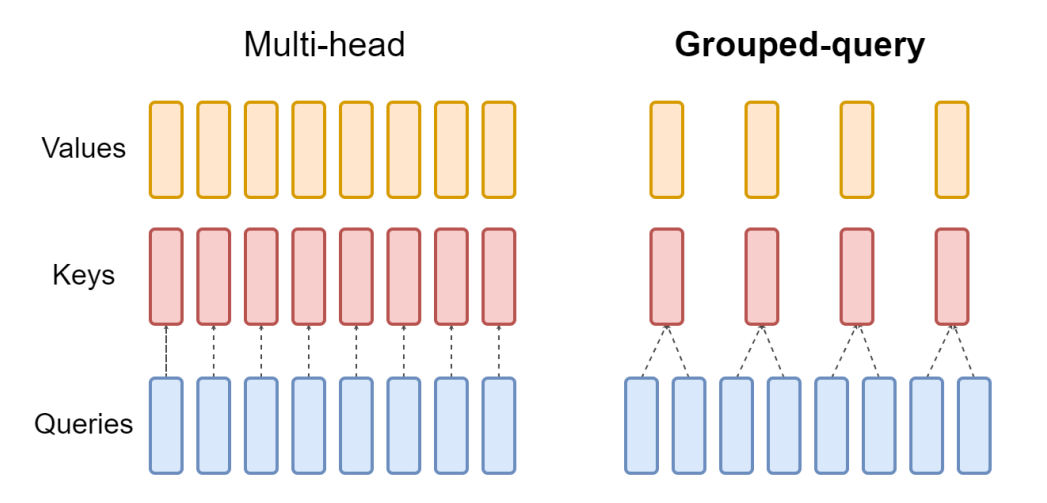
図2: Grouped Query Attention (https://arxiv.org/pdf/2305.13245.pdf より引用)

図3: Parallel Layersと通常のTransformer
学習時間
ABCIのAノード 60ノード (480GPU) を1ヶ月弱使用し、のべ1.4T tokensの学習データをcontext長4096で学習しました。
事前学習の技術的詳細・特徴
ここからは、今回の事前学習で特徴的な点を少し詳細に紹介します。
自社スーパーコンピューター MN-2の活用
PFNでは自社スーパーコンピューターMN-2、MN-3を運用しています。
PLaMo-13Bの学習に必要なGPU量はこれまでにPFNが行ってきたDNN学習のそれより遥かに大きく、MN-2、MN-3でも計算資源を賄うことが困難だったため、本番の学習環境にはABCIを利用しました。
しかし、PLaMo-13Bの学習に自社スーパーコンピューターが役立っていないわけではありません。GPUを利用するスーパーコンピューターであるMN-2は大きく2つの用途に使っています。
1つめは、様々な学習手法のテストベッドとしての用途です。延べ時間でいうと、A100 128GPUを1ヶ月程度、その他A30やV100 GPUもデバッグや小規模なモデルでの実験に多く活用しました。
2つめは、学習全体のCIとしての用途です。LLMの学習は小規模であっても時間がかかるため、GitHub Actionsなどの通常のCIで精度などを確認することは難しいです。我々はMN-2の空き時間をCI用途に使うことで、通常のCIでは確認がし辛い問題の発見に役立てています。
実効効率と効率向上の工夫
次に、PLaMo-13Bの事前学習における実効効率を紹介します。LLMの学習には大量の計算資源に加え通常の学習以上の時間が必要であるため、実効効率を高くすることで必要な計算資源および学習に必要な時間を削減することが重要と言えます。
以下にPLaMo-13Bと他組織がGPUで学習したLLMの実効効率を示します。
| モデル | 実効効率 [%] | 学習context長 | 使用GPU |
| PLaMo-13B | 41.0 | 4096 | A100 40GB x480 |
| GPT-NeoX-20B [3] | 37.5 | 2048 | A100 40GB x96 |
| LLaMA-65B [1] | 46.5 | 2048 | A100 80GB x2048 |
使用するGPUが同じでcontext長がより大きいにも関わらず、PLaMo-13Bの学習はGPT-NeoXよりも高い実効効率でできています。これはPFNでの学習の最適化の効果を示していると考えます。
一方、LLaMA-65Bの学習と比較するとPLaMo-13Bの実効効率は低いです。これには、1) 使っているGPUが違いLLaMAの学習のほうがメモリに余裕があること、2) LLaMAのほうがcontext長が短いこと、3) PLaMo-13Bの学習コードにまだ無駄があること、の3つの理由が考えられます。
PLaMo-13Bの学習コードは後述のように最適化をしてきましたが、学習開始のタイミングなどの理由でできなかった高速化・最適化はいくつもあります。学習に用いたコードは2023年7月末時点のものですが、現在も開発を進めさらなる性能向上を目指しています。
分散学習方法
ここからは実効効率向上のための工夫のうち特徴的なものを紹介します。
まず1つめは分散学習の手法です。LLMの学習ではGPUのメモリが足りなくなるため、3D parallelism [4] などのmodel parallelismがよく行われます。
一方、PLaMo-13Bの学習では今回一切model parallelismを使わず、data parallelismのみで学習するという判断をしました。理由は以下の2点です。
- data parallelismに統一することで、小規模なモデルの学習と使う機能を統一できる。これにより、大規模なモデルのみで起こるといった複雑なバグの発生を減らすことができる
- 学習手法の工夫により、通信にかかる時間をmodel parallelismよりも減らすことができる
2について説明します。data parallelismとはいっても一般的な方法 (例えばPyTorchのDistributedDataParallel) ではGPUメモリが足りなくなるため、Zero Redundancy Optimization stage-3 (ZeRO stage-3, PyTorchではFSDP) [5] を使うことを考えました。
ZeRO stage-3はGPUメモリの消費量を1 / GPU数に減らせる反面、通常のdata parallelismに比べて通信が1回多くなるという問題があります。PLaMo-13Bの学習では、この余分な通信がノード内で完結するようにZeRO stage-3を改良 (以下 ZeRO ノード内 stage-3) しました。ABCIのGPUノードでは、ノード内のGPU同士はNVSwitchにより非常に高速な通信が可能であり、通信時間の大幅な削減が可能です。一方、メモリ消費量はもともとのZeRO stage-3よりも増加しますが、今回の学習では問題となりませんでした。
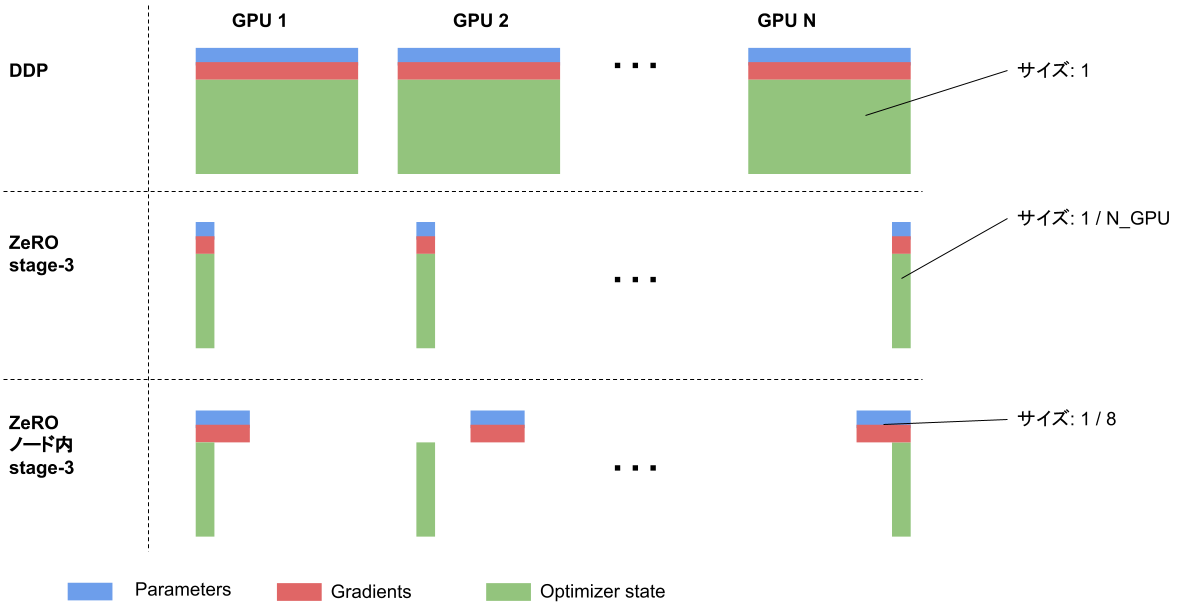
図4: 各方法のメモリ消費量
ZeRO ノード内 stage-3と同様、ノード内の通信によってメモリ消費を削減できる手法として、model parallelismの一種であるTensor Parallel [6]がよく用いられます。一方、今回のPLaMo-13Bの学習の設定では、以下に示すようにTensor Parallelよりノード内でのZeRO stage-3のほうが通信が少なくすみます。
| collective | 通信するTensorのサイズ | 通信が必要なデータ量 (半精度) | |
| TensorParallel (token/GPU=8192) | All-Reduce | 320M要素 | 1280MB※ |
| ZeRO ノード内 stage-3 | All-Gather | 300M要素 | 600MB |
※ All-ReduceではTensorサイズの2倍の通信が必要
データ量子化による通信量の削減
2つめは通信の量子化です。ZeROを用いるdata parallelismにおいてはDNNのパラメータのAllGatherという通信を行います。
PLaMo-13Bの学習ではこの通信をdouble quantization [7] という方法によってデータサイズを1/4にしました。MN-2を用いたプロファイリングにおいて、通信時間がほぼ1/4に削減でき、学習したモデルの性能はほぼ変わらないことを確認しています。また、量子化後のデータを保存し必要に応じてもとの数値フォーマットに戻すことで、GPUメモリの消費量の削減にもつながりました。このメモリ消費量削減はPLaMo-13Bの学習には必須ではありませんでしたが、少ないGPU数で動作確認するのが簡単になったというメリットはありました。
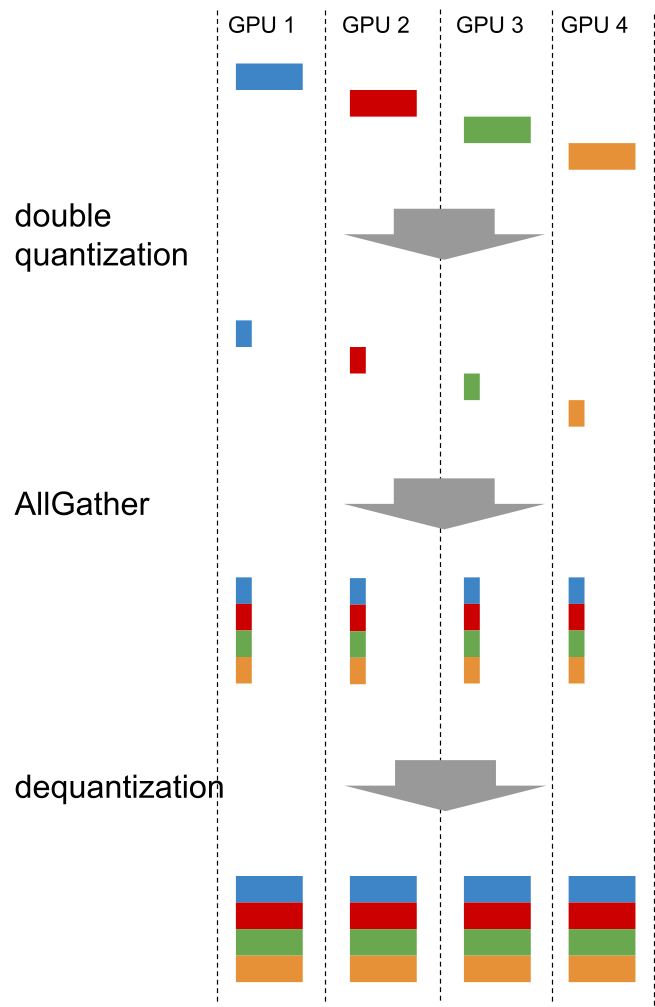
図5: 量子化を使ったAllGatherの実装
我々の知る限り、PLaMo-13Bの学習は、通信に16bit未満の数値表現を使うLLMの学習として最大規模です。PLaMo-13Bに取り入れた技術・手法の中でこの量子化は最も野心的な取り組みだったのではないかと考えています。
CUDAカーネルの実装
LLM (Transformer) の学習は行列積の計算がほぼすべての時間を占めますが、他の処理にかかる時間がないわけではありません。MN-2でプロファイルをとってみると行列積以外の時間が案外多かったため、Rotary Positional Embedding (RoPE) [8]と RMSNormalization [9] の2つの処理について、A100を想定してcudaカーネルを実装しました。
MN-2でのプロファイリングでは、この2操作のカスタムCUDAカーネルの実装により、学習時間の10%程度の削減ができました。CUDAカーネルを書いたと言っても最適化は非常に甘くまだまだ実行時間の削減は可能だと思います。その一方で、簡易的でもCUDAを書くことでかける工数の割に大きな高速化の効果が得られるということはPLaMo-13Bに向けた高速化の中で興味深かった点です。
今回の取り組みの課題
PLaMo-13Bの学習はPFNとしてLLM学習に向けた最初の大規模な取り組みであり、取り組みを通じて課題も多く見つかりました。ここではその中から2つをピックアップして紹介します。
多言語のLLMを効率よく学習する難しさ
PLaMo-13Bでは、日本語での利用を念頭に置きましたが、外部ツールの利用などのためには英語の知識も必要であるという考えのもと学習を行いました。ベンチマーク結果を見るとこの目的はある程度達成できたといえますが、一方で英語だけ、日本語だけとみるとモデルサイズが約半分のモデルと同等程度の性能しか出ない、ということもできます。
多言語のLLMを効率よく学習すること自体が難易度の高い問題であり、そのための手法を今後考えていく必要があると考えています。
適切なベンチマークの作成・整備
我々の想定しているLLMの使い方の1つとして、”日本語を入力として外部ツールを使う” ということを考えていましたが、このような性能を測る適当なベンチマークをまだ作れていません。何らかのベンチマークを用意してその結果を紹介することは可能だったと思いますが、そのベンチマークが外部ツールの利用能力と相関するのかについて我々にまだ知見がないというのが大きな原因です。
今後、PLaMo-13Bの活用を通じて知見をため、今後のモデルの改善を計測するためのベンチマーク整備も行っていく必要があると考えています。
仲間募集中
PFNのLLM開発においてPLaMo-13Bは最初の1ステップであり、今後もLLMの開発を継続して行っていきます。開発は今回のブログで紹介したような計算効率の改善から、DNNアーキテクチャの改善、データセットに対する工夫、LLMを学習するための計算資源の確保まで多岐に渡ります。我々はこれらの課題に情熱をもって挑戦していく仲間を募集しています。
これらの仕事に興味がある方はぜひご応募よろしくお願いします。
- Software Engineer – Foundation Models / ソフトウェアエンジニア 基盤モデル
- 基盤モデルサービス開発エンジニア(大規模言語モデル / 画像基盤モデル)
- 大規模計算基盤エンジニア (Infrastructure)
- 大規模計算基盤リサーチャー (Infrastructure)
- Engineer, Storage / ストレージエンジニア
最後に
私たちはPFNの技術開発ポリシーに基づいてPLaMo-13Bを開発しました。何かお気づきの点があれば、お問い合わせフォームよりご連絡ください。
Reference
- [1] LLaMA: Open and Efficient Foundation Language Models
- [2] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
- [3] GPT-NeoX-20B: An Open-Source Autoregressive Language Model
- [4] Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
- [5] ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- [6] Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- [7] QLoRA: Efficient Finetuning of Quantized LLMs
- [8] RoFormer: Enhanced Transformer with Rotary Position Embedding
- [9] Root Mean Square Layer Normalization
Appendix
Appendix A: ベンチマーク詳細
日本語ベンチマーク
| JCommonsenseQA (acc) | JCommonsenseQA (acc_norm) | JNLI (acc) | JNLI (acc_norm) | MARC-ja (acc) | MARC-ja (acc_norm) | JSQuAD (exact_match) | |
| PLaMo-13B ※ | 55.9 | 53.4 | 41.0 | 36.5 | 95.8 | 95.8 | 70.6 |
| Japanese StableLM Alpha 7B | 33.4 | 27.7 | 43.3 | 37.8 | 96.7 | 96.7 | 70.6 |
| Japanese StableLM Alpha 7B (PFNによるプロンプト変更後) ※ |
79.2 | 75.9 | 43.3 | 37.8 | 96.7 | 96.7 | 70.6 |
| LLaMA 2 7B | 52.6 | 29.2 | 28.2 | 30.2 | 86.0 | 86.0 | 58.4 |
| LLaMA 2 13B | 74.9 | 40.0 | 22.0 | 30.2 | 38.9 | 38.9 | 76.1 |
| weblab-10b | 66.6 | 61.6 | 53.7 | 49.7 | 82.1 | 82.1 | 62.9 |
- ※ jcommonsenseqaのみprompt version 0.3を、その他は0.2を使用
- jcommonsenseqaに関して、Japanese StableLM Alpha 7Bはprompt version 0.2のままだとPLaMo-13Bが不当に精度が高く見える問題がありました。このため、Japanese StableLM Alpha 7Bのみprompt version 0.3の測定結果も載せました。他のモデルに関してもprompt versionを変えると精度が向上する可能性はあります。
- その他のベンチマーク設定はhttps://github.com/Stability-AI/lm-evaluation-harness に準じている
- Japanese Stable LM Alpha 7BのJcommonsenseQA以外の結果および他モデルの結果は以下から取得した
- https://github.com/Stability-AI/lm-evaluation-harness/blob/jp-stable/models/stabilityai/stabilityai-japanese-stablelm-base-alpha-7b/result.json
- https://github.com/Stability-AI/lm-evaluation-harness/blob/jp-stable/models/llama2/llama2-7b/result.json
- https://github.com/Stability-AI/lm-evaluation-harness/blob/jp-stable/models/llama2/llama2-13b/result.json
- https://github.com/Stability-AI/lm-evaluation-harness/pull/85/files#diff-a759330cbe9163a0a0f6f4094cf577558e87848c4d8d84da069c14a3707168c9
英語ベンチマーク
| arc_challenge(acc_norm) | arc_easy(acc_norm) | boolq(acc) | hellaswag(acc_norm) | openbookqa(acc_norm) | piqa(acc_norm) | winogrande(acc) | |
| PLaMo-13B | 40.3 | 64.8 | 67.2 | 70.2 | 40.6 | 76.1 | 65.3 |
| Japanese StableLM Alpha 7B | 33.7 | 63.3 | 64.6 | 63.3 | 38.6 | 73.4 | 62.8 |
| LLaMA 2 7B | 40.6 | 53.6 | 71.1 | 73.0 | 40.8 | 76.9 | 67.1 |
| LLaMA 2 13B | 44.2 | 58.0 | 69.0 | 76.6 | 42.0 | 79.1 | 69.6 |
| weblab-10b | 35.0 | 63.2 | 65.2 | 64.4 | 34.2 | 76.3 | 62.4 |
- ベンチマークの設定はlm-evaluation-harness (https://github.com/EleutherAI/lm-evaluation-harness )のデフォルト設定に準じた
Appendix B: 図1のスコア算出方法
Appendix Aのベンチマークスコアの偏差値の平均を各言語のスコアとしてプロットしました。
ただし、日本語ベンチマークのなかでJNLIだけは除いています。これはJNLIのラベルの比率が均等ではないという問題があり、現状ではaccuracyで正しくモデルの性能を評価できていないと考えているためです。JNLIは3クラス分類のタスクで、一番頻度の高いラベルは全体の55%ほど含まれています。このため、一番出現頻度の高いラベルをそのまま出力する単純なモデルを作り、accuracyで評価すると55という数値になります。この値は他のモデルよりも高い精度になってしまい、accuracyで評価するのは現時点では難しいと考え、JNLIは除いています。
Area
Tag