Blog
リサーチャーの高橋城志(Takahashi Kuniyuki)です。
ICRA2021に採択された少量データセットでの食品の目標量把持の論文を紹介します。
論文、動画は下記から閲覧できます。
論文タイトル:Uncertainty-aware Self-supervised Target-mass Grasping of Granular Foods
著者:Kuniyuki Takahashi, Wilson Ko, Avinash Ummadisingu, Shin-ichi Maeda
論文のリンク:論文arXivリンク
論文の動画:動画リンク
導入や共同開発に興味がある方はご連絡ください。
連絡先:
高橋、千々岩
コンタクトフォームリンク
食品把持の課題
スーパーマーケットやコンビニエンスストアに並べられているお弁当の製造現場を見たことはありますか?お弁当の食品工場では、指定された目標量の食品を食品トレーから把持して、お弁当箱に詰めるという作業が行われています。お弁当は様々な食品から構成され、メニューは多岐に渡ります。さらに、お弁当のメニュー、容器は季節の移り変わりや新商品の発売などによって数週間おきに新しいものが登場します。食品の種類も多いのですが、同じ種類の食品でも一つの食品の形や大きさなどが異なります。このような背景から、大部分の食品に関しては専用機械を作ることが難しく、人手で詰め込み作業が行われています。
詰め込む食品は把持と食品の大きさの観点から、個数で管理する大片食品(焼き魚や唐揚げなど)と重さで管理する細片食品(or 粒状食品)(煮豆や千切りキャベツなど)に分類できます。食品把持に関するロボティクスのこれまでの研究開発では、大片食品では、研究におけるデモンストレーションとして成功した例がいくつか報告されています。しかし、食品の中には数多くの細片食品がありながら、粒状であるために不定形であることから扱いが難しく、あまり研究開発が進んでいません。専用の器具や定量を把持するものはありますが、様々な食品や異なる把持量に対応するためには、設計変更などの多大な労力が必要になります。
本研究では、細片食品に対してユーザーが指定する任意の把持量を把持可能なシステムの構築を目指しました。食品トレー全体のRGB-D画像から、ユーザが指定する任意の目標量を把握するための最適な把持点を特定し、学習する方法を提案しています。このシステムを設計するにあたり、食品業界からは下記の3つの能力が求められています。
R1) 様々な不定形で変形する食品を扱う能力。
R2) 追加のトレーニングを必要とせずに、ユーザーが指定した目標把持量を把握する能力。
R3) 短時間で新しい食品に適応する能力。
粒状食品は変形しやすく、個々の粒子の相互作用が大きいため、正確なシミュレーションやモデル化は困難です。そのため、実世界から学習データを集めて学習するアプローチが、最も実現可能な方法です。我々の提案するシステムは、深層学習の表現力を利用して、実世界のRGB-D画像から直接学習します(R1)。ニューラルネットワークは食品トレー内の把持候補点から把持される食品の把持量を回帰し推定します。それら全ての把持候補点から、ユーザーが指定した把持量に近いものが把持点として選ばれます(R2)。深層学習はとても強力ではありますが、正しく学習されるためには、大規模なデータセットが必要とされます。しかし、実際のロボットでのデータ収集には膨大な時間がかかり、また、食品の劣化、把持による損傷、湿気などの要因から同じ食品を繰り返し利用して訓練データを集めることにも制限があります。このデータ量の制限は、訓練された深層学習の推定結果の信頼性を低いものにしてしまいます。この不完全性に対処するために、自己教師あり学習で推定値の不確実性をモデル化、ユーザーが指定した把持量に近い、把持点候補の中から最も信頼性の高い把持点を利用します(R3)。
目標把持量を把持するシステムと不確実性の予想
ユーザーが指定した粒状食品の目標把持量を把持するための提案方法は次の手順で構成されます(図1参照)。
1)食品トレー全体のRGB-Dパッチでの推定把持量の獲得。
2)推定把持量の不確かさの推定。
3)推定把持量が目標把持量から±0.5 g以内にある点の中から、推定把持量の不確かさが最も低い点を把持点として選択。
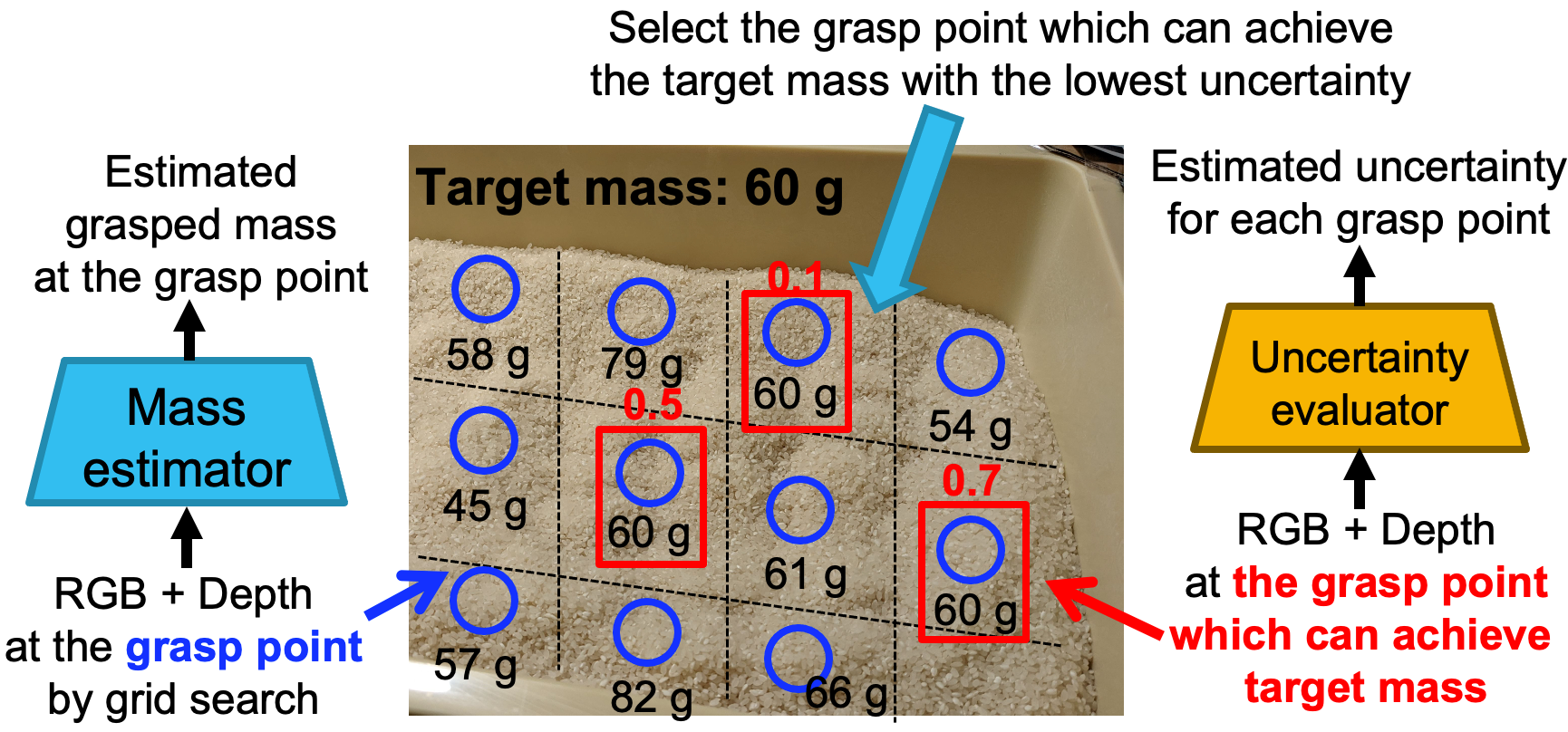
図1 概要:不確実性を考慮した粒状食品の自己教師あり目標量把持学習
RGB-D画像からの推定把持量の推定
推定把持量ネットワークは、切り取られた(パッチの)RGB-D画像から推定される把持量を推定します。したがって、あるパッチの位置をグリッパの把持位置に指定すると、そのパッチに対して推定された把持量をグリッパが把持することが期待されます。
パッチ\(i\)の期待される推定把持量は、ニューラルネットワーク\(F(x_{img,i},x_{depth,i};\xi)=y^{\prime}_{mass,i}\)によって推定されます。\(\xi\)は、最適化するパラメータです。損失関数 \(L\)は、\(\xi\)について最小化します。
\[\min_{\xi}\frac{1}{n}\sum_{i=1}^{n} L(y_{mass,i}, F(x_{img,i},x_{depth,i};\xi))\]
ここで、\(n\)は訓練に使用した切り取られた画像の数であり、\(y_{mass,i}{\in}{R}^{d}\)は、\(i\)番目の画像に対する教師信号、すなわち、実際の把持量です。
損失関数\(L\)として、回帰とクラス分類の選択肢があります。タスクの性質上、連続値で表現された推定把握量を推定する必要があるため回帰を選択しましたが、場合によってはクラス分類でもうまく機能することもあります。
不確実性の予測
モデルの不確実性を明示的に捉えるための2つの方法を提案します(図2参照)。ここでいう不確実性とは、実際の把持量とニューラルネットワークによって予測される推定把持量が異なる可能性のことです。不確実性の低い予測は、実際の把持結果が予測と一致するというモデルの信頼性の高さを示しています。
ここで推定する不確実性には、偶然性(aleatoric)と認識論(epistemic)の両方の不確実性が含まれます。偶然性の不確実性はセンサーやモータのノイズなど環境自身の不確かさによるものです。一方、認識論的不確実性は、モデルの不完全性による不確かさです。私たちの設定では、学習データの不足が認識論の不確実性の主な原因です。
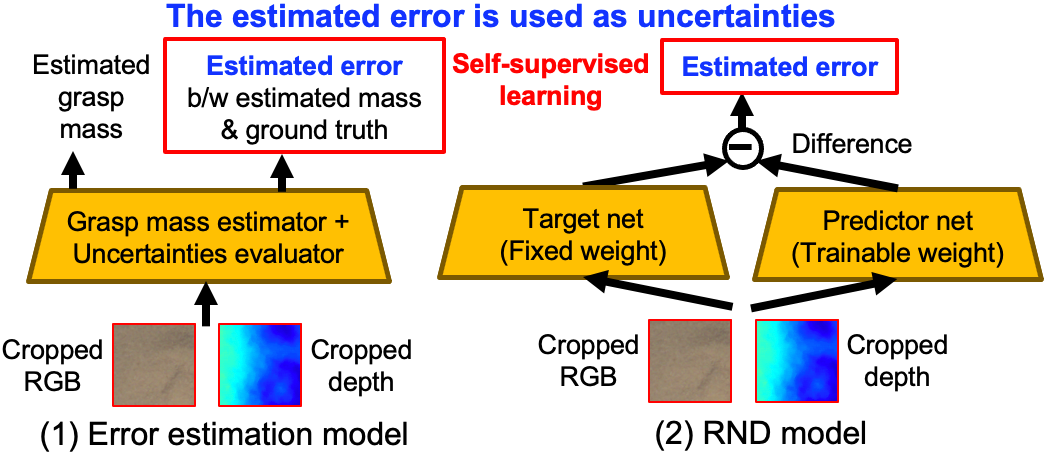
誤差推定による不確実性
強化学習における探索の改善で行われる手法を、モデルの不確実性を推定する方法に適応しました。\(i\)thの入力画像が与えると、誤差推定(Error Estimation (EE))モデルは、実際の把持量\(y_{mass,i}\)と推定把持量モデルで推定された把持量\(y^{\prime}_{mass,i}\)との差の絶対値\(y^{\prime}_{error, i}\)を予測することを学習します(図2(1)参照)。EEモデルは次の損失関数を最小化して求めます。
\[\min_{\xi}\frac{1}{n}\sum_{i=1}^{n} L(|y_{mass,i} – y^{\prime}_{mass,i}|, y^{\prime}_{error,i})\]
ここで注意したいのは、推定把持量モデルの学習で使用した \(y_{mass,i}\)以外の外部から与えられる教師信号は必要ないということです。つまり、EEモデルの学習は、一種の自己教師あり学習です。推定把持量モデルは学習データに対して誤差が小さくなるように学習されるので、推定把持量モデルが適切に学習されて誤差が小さくなるほど、EEモデルが推定する誤差はゼロに近くなります。
RNDによる不確実性
Random Network Distillation (RND)[1]の考え方を用いて、推定把持量の不確かさを推定する方法を提案します。RNDは、強化学習において、より良い探索を行うための新規な状態作用空間を探索するための手法として提案されました。探索の際には、すでに経験したことがあるのか、まだ経験していないのかを判断する必要がありますが、RNDはその判断を行うのに役立ちます。RNDでは、2つのネットワーク \((f, f^{\prime})\)を使います。一つは、Target network \(f\)で観測値を\(f\)にマップします(\(f: O \mapsto {R}^{k}\))。もう一つは、Predictor network \(f^{\prime}\) (\(f^{\prime}: O \mapsto {R}^{k}\))です。Target networkは、Predictor networkの学習のための教師信号を生成します。実際には、重みがランダムに初期化されて固定されたランダムニューラルネットワークで表現されます。そして、MSE\(\frac{1}{n}\sum_{i=1}^n||f^{\prime}(x_{img,i}, x_{depth,i};\theta) – f(x_{img,i}, x_{depth,i})||^{2}\)が最小になるように勾配降下法で学習します。\(\{ x_{img,i}, x_{depth,i} \}\)は推定把持量モデルの学習に用いた画像と全く同じものです。教示信号はTarget networkから与えられたものになります。したがって、\(f\)と\(f^{\prime}\)が学習データ以外の入力を与えられた場合、この差が大きくなることが予想されます。不確実性のモデル化にはRNDのこの特性を利用します、つまり、入力は学習データに近いほど、推定把持量モデルの出力の不確実性は低くなります。この方法では、推定把持量モデルに加えて、\(f\)と\(f^{\prime}\)の2つのネットワークが必要ですが、それぞれの学習には影響を与えません。
[1] Y. Burda, H. Edwards, A. Storkey, and O. Klimov, “Exploration by random network distillation,”arXiv preprint arXiv:1810.12894, 2018.
把持点の選択
ここでは、食品トレーから把持点を選択する方法について説明します。まず、候補となる把持点を食品トレー上をグリッドサーチをして、候補となる把持点を中心とするRGB-Dのパッチを推定把持量モデルに入力として与えます。目標把持量に近い推定把持量を持つパッチが把持点の候補になります。本研究では計量計の解像度から、目標把持量から±0.5g以内にある把持点を選択しています。そして、その中から不確実性が最も低いものを選択し、推定された把持量を把持する確率が最大となるようにしています。
推定把持量モデルのみを用いることは、目標把持量に近いものの中から不確実性をランダムに選択することとほぼ同等です。そして、不確実性が最も少ない候補を選択することは、不確実性をランダムに選択することと同等かそれ以上の効果が期待できます。
データセットの作成
本実験で使用した環境について説明します。ロボットには7自由度アームのSawyerに独自のグリッパをとりつけたものを使用しました(図3(a))。天井にはDepthセンサとRGBカメラを設置しており、食品トレー内の食品の情報を取得できます(図3(c))。さらに、食品トレーの下には計量計を設置しており、どれだけの量を把持したかを計測できます。食品トレーを2つ用意しておき、食品トレーの食品重量がしきい値以下になるまでは同じ食品トレーから把持して、もう一方の食品トレーに把持した食品を置きます。しきい値以下になると、把持と置くトレーを入れ替えることで、人間が介在(食品トレーの切り替えとデータラベルの付与)することなく、無限にデータを収集することが可能です。
今回の実験での把持位置の高さは、把持点中心における食品の表面から、2cmの深さのところを把持するようにしています。このシステムでは、1回のpick&placeの時間は12.5秒で、食品工場で求められる最低限の速さになります。今回の実験では粒の大きさ、質量、形状が異なる4つの食品(コーヒー豆、米粒、オートミール、ピーナッツ)を扱っています。

図3 データセット収集環境:(a)ロボットの環境、(b)対象とした食品:コーヒー豆(1gと22g)、米粒(1gと60g)、(c)RGB画像とDepth画像の例、(d)他の食品:オートミール、ピーナッツ
評価実験:データ収集のためのランダム把持
図4に上記で説明したデータ収集システムを用いて、コーヒー豆と米粒で、50、100、200、500、1000回の把持を行ったときの把持量のヒストグラムを示しています。コーヒー豆も米粒も200回以上の把持を行うと、正規分布になっていることが分かります。それよりも把持回数が少ないと、分布に偏りがあったり、スパースになっていることが分かります。例えば、米粒の60gに関しては50回の把持では1回も把持していません。さらに、次の実験の章で60gを目標把持量としています。そのため、これをクラス分類で扱うのは難しいです。
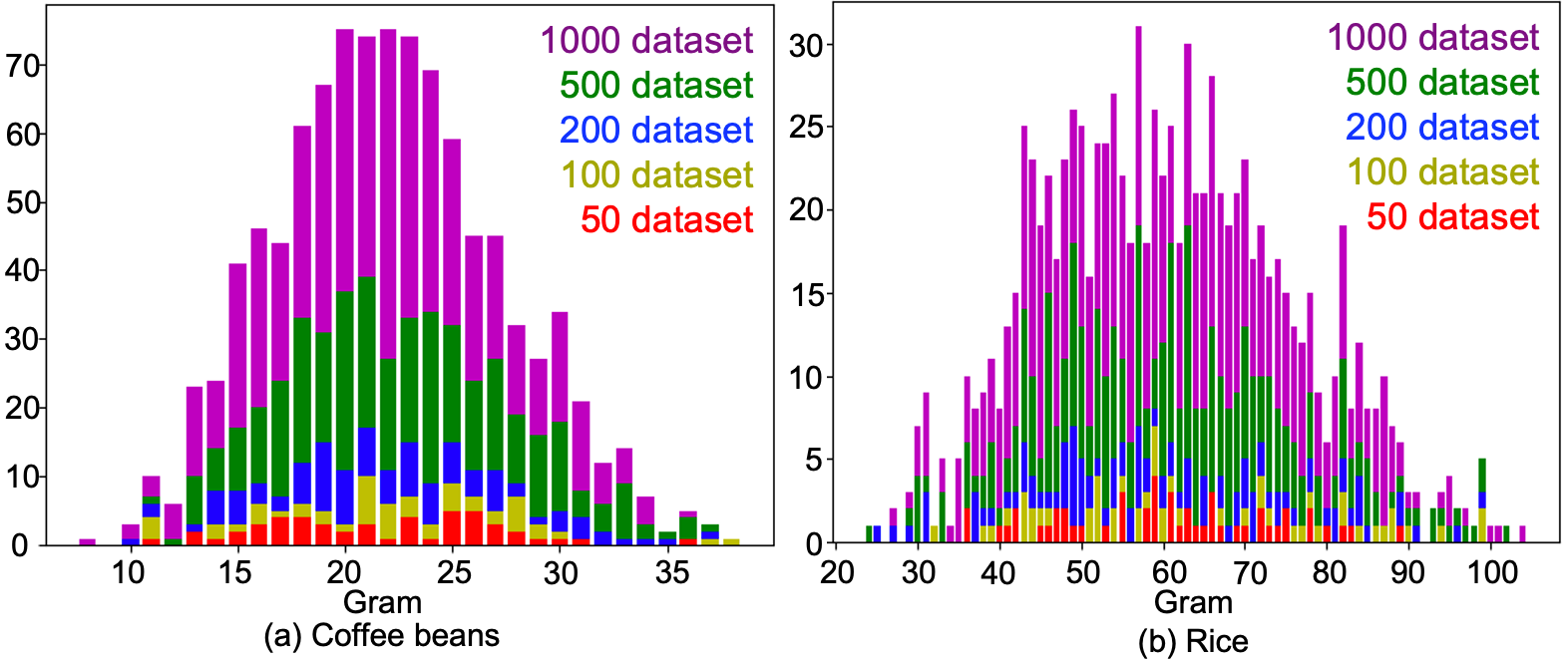
図4 50、100、200、500、1000回把持したときの把持量に関するヒストグラム((a)コーヒー豆、(b)米粒)
評価実験:不確実性を考慮した目標把持量の把持
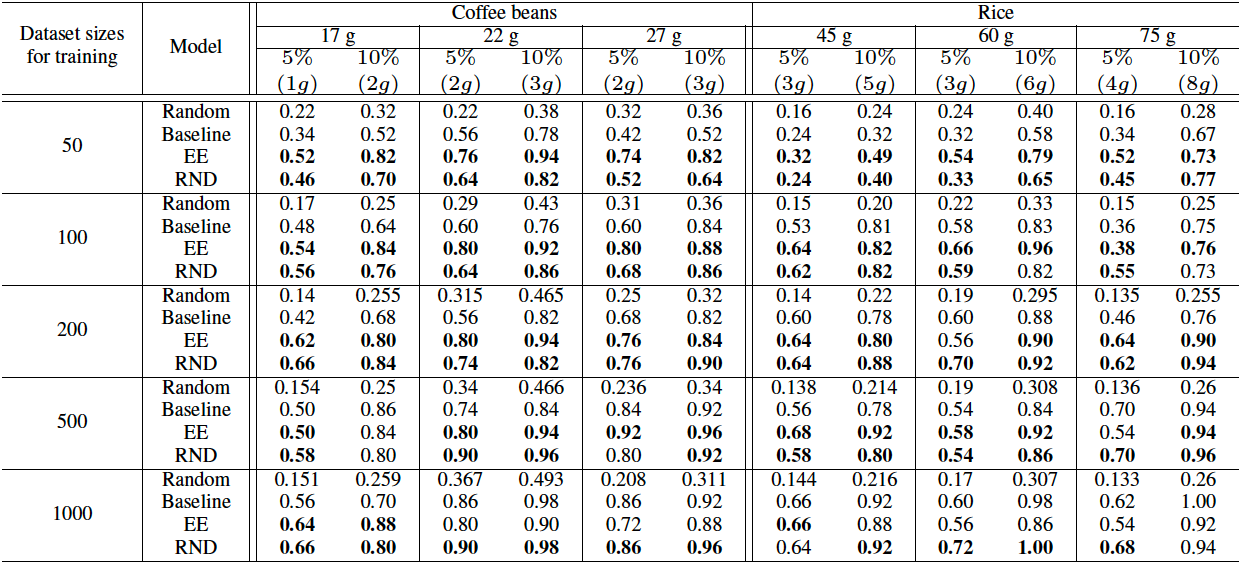
前章で説明した50, 100, 200, 500, 1000回の把持データを学習させて、3つの目標把持量をそれぞれ把持させて評価させました。1000個の学習セットの把持量の平均(mean)と標準偏差(std)を計算し、それらを用いて把持目標(mean-std, mean, mean+std)を設定しています。コーヒー豆は17g, 22g, 27g, 米粒は45g, 60g, 75gが目標把持量です。この論文では、目標値の許容範囲内であったものを「成功」と定義しています。具体的には、\(\frac{| predicted\_mass – target\_mass|}{target\_mass} \leq tol \)のときに、把持を成功したと数えています。表1に、食品業界の基準である5%と10%の2つの許容値に対する成功率を示しています。成功率は50回の把持(結果の安定のため、50回と100回の米粒の学習データセットでは100回の把持)を行わせています。提案手法(EEモデルとRNDモデル)との比較として、ランダムな把持(データ収集と同じ)、不確実性を考慮していない推定把持量が最も目標把持量に近い把持点での把持(Baseline)を行いました。
表1から、学習させるデータセットが小さい場合、不確実性を考慮したEEモデルとRNDモデルはBaselineよりよい傾向であることが分かります。一方、データセットのサイズが大きくなるにつれて、Baselineが提示手法の性能に追いつく、あるいは時には上回ることがあります。これは、学習データセットのサイズが大きくなると、認識論的不確実性(epistemic uncertainty)が減少するために、推定把持量モデルの精度がよくなるためです。しかし、我々のようなアプリケーションでは大規模なデータ収集は困難なため、可能な限り不確実性を最小化することが重要です。
コーヒー豆と米粒で、データサイズと目標把持量を変化させた場合の効果を研究し、小さいデータセットで学習の可能性を確認しました。さらに、オートミールとピーナッツでの追加実験を行うことで、その信憑性を検証します。オートミールとピーナッツは、コーヒー豆や米粒に比べて異なるダイナミクスを持っていますが、表2から、同じグリッパを使用しても、提案手法が頑健に動作していることを示しています。オートミールは軽くて平面的で、握ると圧縮されてしまい、ピーナッツは強く握ると半分に割れてしまいます。
表1 コーヒー豆と米粒の成功率。太字はBaselineより良い結果のものです。
表2 オートミールとピーナッツの成功率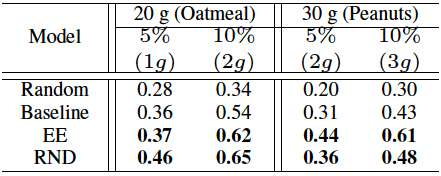
まとめ
本論文では、自己教師あり学習によってモデルの(特に認識論的な)不確実性を考慮することで、非常に小さなデータサイズでも高い性能を得る方法を提案しました。さらに、ラベル付けされたデータを無限に自律的に収集できるデータ収集システムを開発しました。
論文に書かれていない裏話:
<最新版での精度の向上と把持回数の削減>
このプロジェクトを始めた当初は1000回以上の把持回数が必要で、それでも目標把持量に対して10%以下の誤差になる精度は中々上がりませんでした。このBlogに書かれているように、ICRA2021の投稿までに必要な学習データ量も減り、精度を上げることができました。ICRA2021投稿後も研究開発を継続しています。その結果、現在では20~100回分の把持データの学習でも、任意の目標把持量に対して5%以下の誤差になる精度がおよそ100%に達しました。最新版の手法に関しては続報をお待ち下さい。
<最初の実験では生鮮食品を扱っていた>
このプロジェクトを始めた当初は野菜などの生鮮食品で把持の挙動を観察していました。しかし、すぐに野菜の状態が変わったり、腐ったりしてしまうため、乾物での実験に変更していました。現在では少量のデータセットで学習可能になったので、様々な食品へ移行しています。
よく聞かれる質問集:
Q.1 なぜすくい動作ではなく、把持で行っているのですか?
A.すくい動作では軌道を考える必要があり、エンドエフェクタを食品に挿入する位置、角度、深さ、長さなどが必要になり、位置と深さだけを考えればよい把持よりも考慮するべきパラメータが多いです。そのため、把持を選択しました。しかし、本研究で用いた不確実性を考慮した手法はすくい動作でも適用可能です。
Q.2 把持点は食品表面から一定の高さだと、食品トレー内の食品が減ってきたら対応できないですか?
A.食品トレー内の食品が減ってきたら、食品をかき集める動作を行うことで対応できます。本手法では複数の把持の高さでも学習は可能です。しかし、学習に必要なデータセット数の増加と、学習したニューラルネットワークから最適な把持点の計算に時間がかかってしまいます。
Q.3 乾物だけで他の食品は扱えないのでは?
A.現在、お弁当で使われているような様々な食品の研究開発を行っています。
Area
