Blog
2017.07.25
FCN-Based 6D Robotic Grasping for Arbitrary Placed Objects
Area
Tag
Hitoshi Kusano
Engineer
Hello! My name is Hitoshi Kusano. I participated in 2016 PFN summer internship program and have been a part-time engineer at PFN ever since, while also studying machine learning at Kyoto University. At PFN, my research topic was to teach an industrial robot how to pick up an object.
Based on the result of my work at PFN, I presented a paper titled ”FCN-Based 6D Robotic Grasping for Arbitrary Placed Objects” at the Learning and Control for Autonomous Manipulation Systems: The Role of Dimensionality Reduction workshop at ICRA 2017, the world’s biggest annual conference in robotics.
Here’s a movie showing how the robot grasps objects:
Below is an outline of my research on teaching an industrial robot how to grasp an object based on an image.
We’re looking for more people to work on advanced robotics at Preferred Networks. If you’re interested, please contact us!
Background
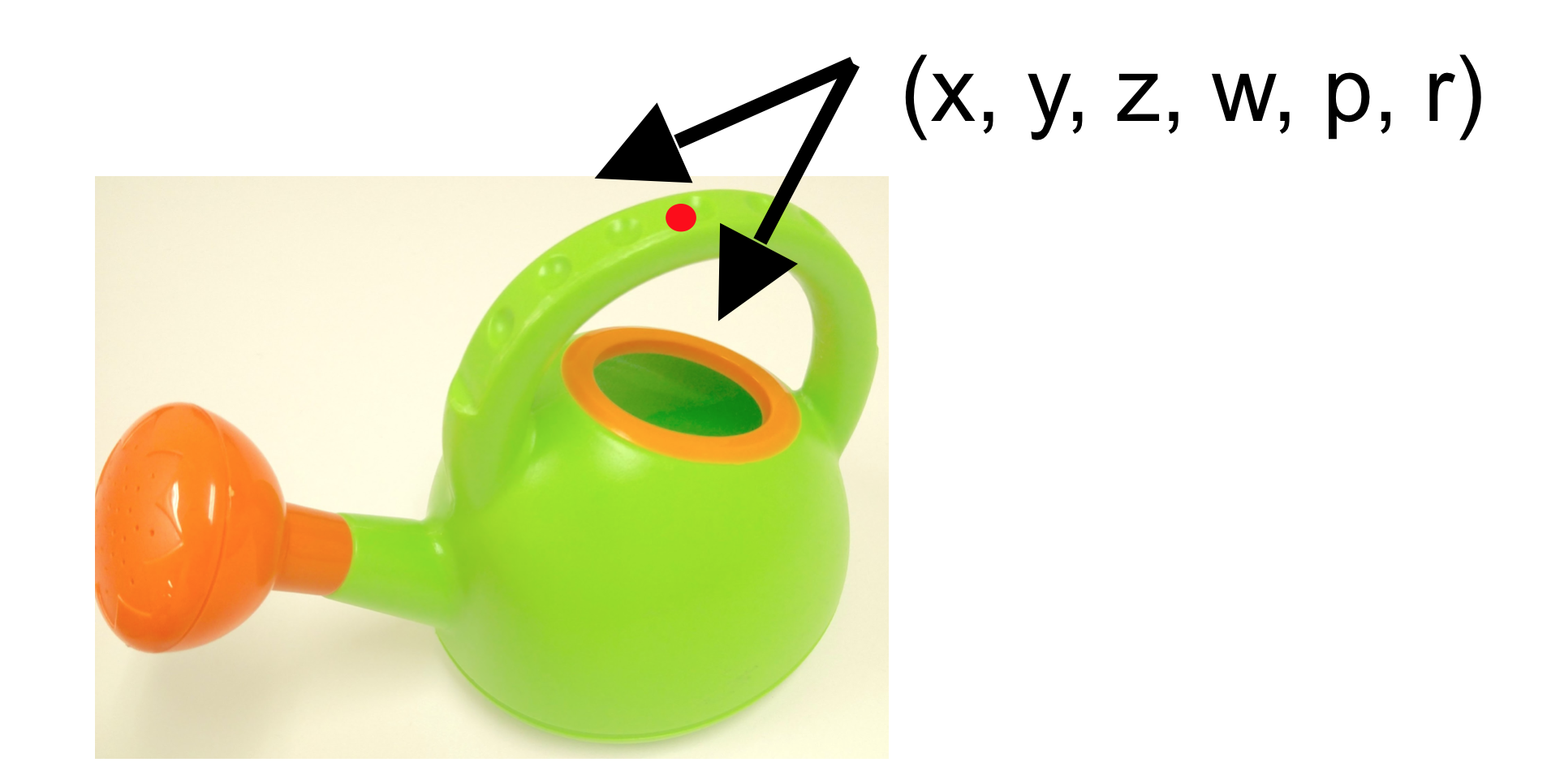
Traditional approaches to grasp an object from image information often rely on object pose estimation or pattern recognition techniques to detect object-specific features in point cloud data. However, such approaches are ill-suited for use in objects placed in unstructured environments, or for use with complex end-effectors with high degrees-of-freedom (DOF) ※1, because they provide information about the state of the object, but not the state in which the robot or its end-effector should be in order to grasp the object. Therefore, these approaches make use of heuristics to select a configuration (i.e. joint angles, position, orientation, etc.) for the robot and its end-effector. Furthermore, detection of object-specific features may fail or provide false positives on either deformable objects or objects unknown to the system. The recent advances and popularity of deep learning have given birth to new methods for grasping that are able to directly generate the configurations of the robot as well as its end-effector, and these are called end-to-end learning of grasping ※2. As end-to-end learning of grasping based on machine learning, Pinto2016, Levine2016, Araki2016, Guo2017 are known. When we think about the usage of complex end-effectors or in unstructured environments for the real application, it is required to predict a grasp either from arbitrary pose or with higher degree of freedoms. However, prior works can predict a grasp from only above orientation, and couldn’t predict 6D grasp pose (arbitrary pose in 3-dimensional space, namely x, y, z, w, p, r) ※3.
※1. The end effector is the part of the robot that interacts with the environment, such as a hand.
※2. End-to-end learning is a learning approach in which a model represents the correspondence between input and output of the system.
The recent popularity of deep learning have proven the efficacy of the approach. In this research, our model employs an end-to-end learning with correspondence between an RGB-D image as an input and grasp pose as an output. Compared to usual learning approach with separated tasks, the approach generally has 2 benefits.
1). With a smaller number of models and hyperparameters, it is easier to select hyperparameters.
2). It is said that to avoid the loss of information accompanied by model separation enables the higher performance if it learns successfully.
※3. Each of w, p, r means each rotation around the z-axis, the y-axis and x-axis. 6 parameters composed of x, y, z, w, p, r represents an arbitrary pose in 3-dimensional space.
Purpose and Contribution
These prior methods, however, have a disadvantage when applied on higher DOF end-effectors or when there is a need for increasingly complex grasp strategies as it becomes more and more difficult or even impossible to annotate the data. Therefore, such methods rely on low dimensional annotations making them unable to output 6D grasp configurations.
In this research, we achieve an End-to-end learning to grasp arbitrary placed objects.
We have 2 contributions.
- We propose a novel data collection strategy for 6D grasp configuration using a teach tool by human
- We also propose an end-to-end CNN model, capable of predicting 6D grasp configurations.
Grasp Configuration Network
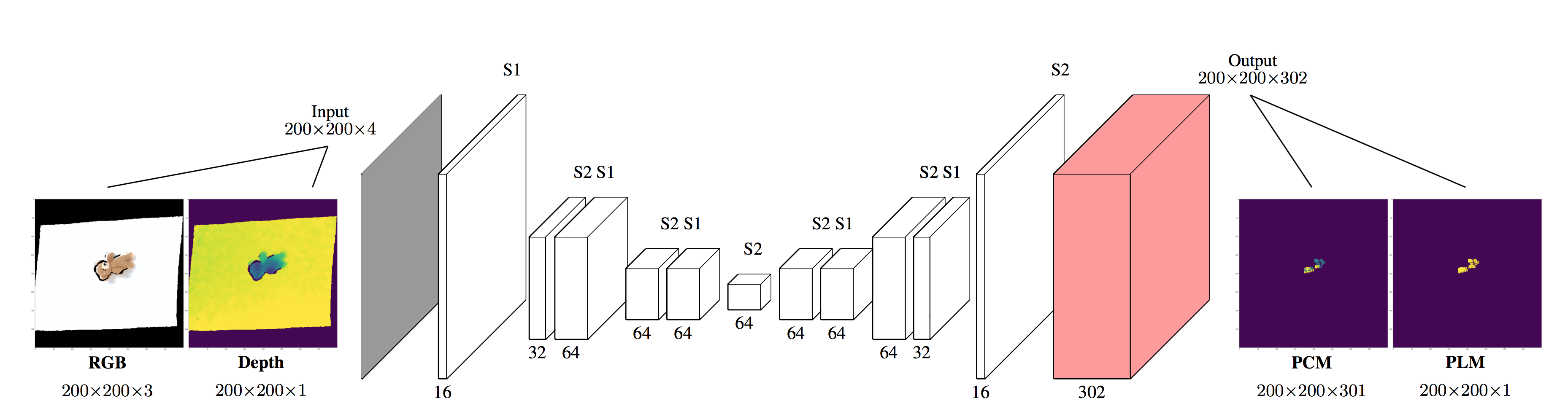
This is our proposed CNN model, an extension for Fully Convolutional Networks, Grasp Configuration Network. This network takes an RGB-D image as an input as shown in below figure. Unlike FCN, this network outputs two maps with scores: a location map for graspability per pixel, and a configuration map providing end-effector configurations per pixel. These are shown in below figure. For Configuration Map, this network classifies valid grasp configurations to 300 classes.
I describe why we don’t use regression in Configuration map but classification here.
Despite the multimodal nature of grasping, prior works have tried to use regression to model grasp configurations, which is bad at modeling multimodal nature. If we let g1 and g2 be valid grasp configurations for a target object o in location (x, y), we argue that the mean of g1 and g2 might neither be an optimal nor valid grasp. We therefore discretize grasp configurations and use a classification model instead, as proposed in Pixel Recurrent Neural Network. A naive solution to achieve discretization is to take all possible combination of quantized configurations along each degree of freedom. However, the amount of combinations would increase exponentially as the dimension of a configuration increases. To alleviate this problem, we categorize valid grasp configurations to 300 classes using k-means clustering.
Data Collection
For data collection, we employ novel data collection strategy to obtain 6D grasp configurations using a simple teach tool as shown below.

The white X mark on the center of the gripper corresponds to the black X mark on the center of the gripper of robot for which grasps are outputted by our network.

(From https://www.thk.com )
And how we collect data is shown below. Under such situation, we collected 11320 grasps. Generally, there are multiple graspable poses for an object with a placement, and we collected multiple grasp poses for an object with a placement exhaustively. Therefore, we can train our model with assuming the place without annotation as the negative example(not graspable point).

Experiment Setup
The environment for system test is shown here.

We use
A. RGB-D Camera: Intel Realsense SR300
B. An arbitrary placed object
C. 3-finger gripper: THK TRX-S
D. 6 DOF industrial robot arm: FANUC M-10iA
Example of predicted grasp configurations
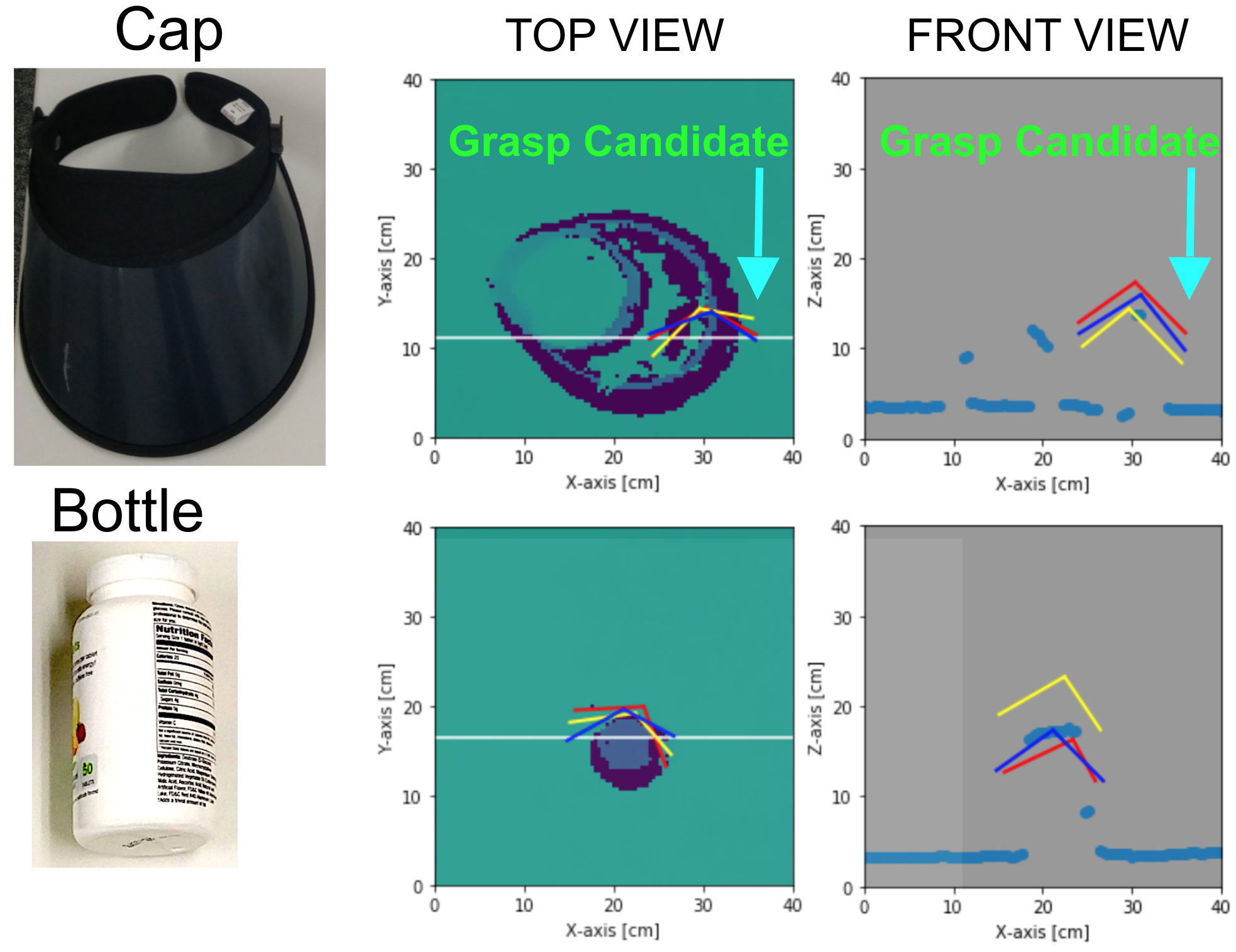
Example outputs of our network are shown here, displaying the ability of our network to propose different grasp configurations for the same (X, Y) location for multiple items. In the middle and right figure, we show grasp candidates. The bottle is standing upright. This network successfully predicts grasp candidates utilizing a rotational degree of freedom.
Results of robotic experiment
We have conducted experiments to command a robot to pick on twelve objects with different rigidness and shapes. Data Collection was performed for only objects shown in left. We define success as whether an object is grasped or not when a robot moves back to an original position in full system test. The low success rate of pipe can be explained by the camera not being able to capture the differences in depth due to its complex shape.

Finally, video of full system test is shown below.
This video plays at double speed.
For further detail, our proceeding and presentation slides are available online.
kusano_2017
Reference
L. Pinto and A. Gupta, “Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours,” in Proc. IEEE ICRA, 2016.
S. Levine, et al., Learning Hand-Eye Coordination for Robotic Grasping with Large-Scale Data Collection. Springer International Publishing, 2017.
R. Araki, et al., “Graspabilityを導入したDCNNによる物体把持位置検出 (Introducing Graspability for Object Grasp Position Detection by DCNN),” in The Robotic Society of Japan, 2016.
D. Guo, et al., “Deep vision networks for real-time robotic grasp detection,” International Journal of Advanced Robotic Systems (IJARS),vol. 14, no. 1, 2017.
J. Long, et al., “Fully convolutional networks for semantic segmentation,” in Proc. IEEE CVPR, 2015.
A. van den Oord, et al., “Pixel recurrent neural networks,” in Proc. ICML, 2016.
Area
Tag