Blog
Since early 2021, we at Preferred Networks (PFN) are in the process of moving from HDFS to Ozone. Our Ozone cluster has been gaining adoption for our ML/DL projects, the cluster usage is rapidly growing, and we have expanded the cluster several times over the past two years. However, as the cluster gradually expanded, disk usage imbalance became a problem. For example, adding completely empty data nodes to an Ozone cluster where all existing disks are already 80% full will cause a significant imbalance in cluster usage. Moving data to a newly added empty server is called rebalancing, but how it works exactly is not obvious. In HDFS, there are Balancers that move blocks evenly within the specified threshold on per-node basis, and a Disk Balancer which aligns blocks among disks within a single Datanode. Ozone, on the other hand, has a Container Balancer and at first rebalancing didn’t seem to work in Ozone 1.2.0 because it is still a young feature. Therefore, when we recently added new data nodes we made a decision to perform a manual rebalancing as an emergency maintenance. In this article we show our full story starting from the background.
(For more information on the efforts to build our Ozone clusters, please also read the 2021 blog post “A Year with Apache Ozone”.)
The role of the storage system in PFN’s computing infrastructure is to provide a place to persist the data required for our ML/DL research activities and read it at high speed when needed. The “data required” includes various things such as datasets, program execution results, and job checkpoint files. Recently there has been an increase in the number of use cases [1][2][3][4] that generate data by computation using CG and simulations in the company, and data continues to increase from nothing. We have been purchasing and building servers by predicting demands based on disk usage statistics, but recently it has been difficult to estimate, and disks are filling up faster than expected.
Expanding a cluster by purchasing servers and disk equipment actually takes a lot of time. We faced a situation where we cannot keep up with the pace of data growth if we purchase servers at the stage when the free space is low. We bought and added new servers, and in parallel shrinked HDFS clusters and re-deployed retired HDFS Datanodes as fresh Ozone Datanodes many times. Both HDFS and Ozone thankfully have good support for expanding and removing Datanodes. However, as mentioned above, because of the conditions of procurement and difficulty of the usage forecasting, our cluster expansion progressed only in small steps. Fig. 1 shows the development of system capacity (Orange) and actual usage (Blue) for our cluster over the past year and this shows that usage increases faster than capacity, while we have been repeatedly adding servers. We were planning a system expansion to keep data usage less than 80% however in recent months the usage was reaching this limit.
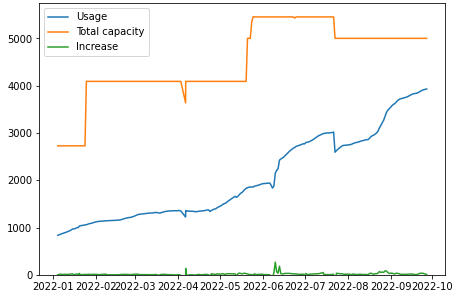
Fig. 1: Physical system capacity and actual usage of the Ozone cluster (Unit: TB)
Incremental Cluster Expansion Led to Disk Imbalance
While free space for the entire cluster was close to running out, the disk usage imbalance among datanodes was also a problem. Fig. 2 shows physical disk usage per datanode. In this figure, datanodes with high disk usage are old nodes, while low disk usage can be observed for newly added nodes. This distribution is undesirable, as disk usage should be as uniform as possible for I/O load balancing. In addition, high disk usage nodes raise concerns about disks running full.
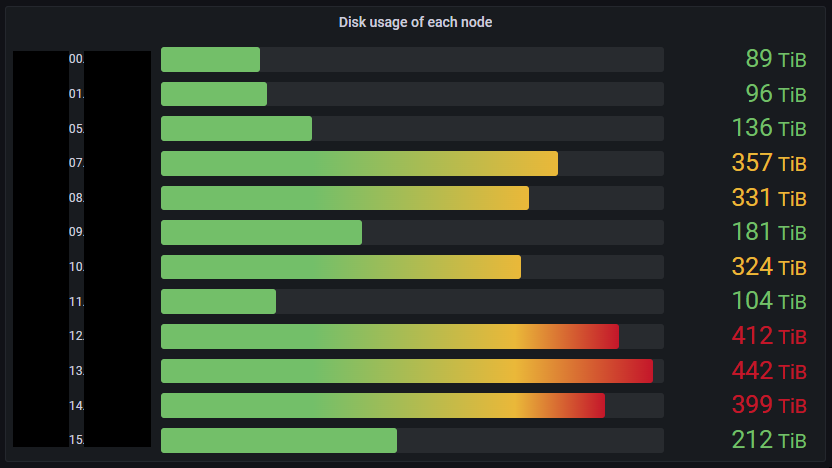
Fig. 2: Ozone Datanodes with an imbalanced state.
Table 1 shows Datanode configuration shows Datanode configuration of each server in Fig. 2:
| Software | Apache Ozone 1.2.0 based custom version |
| CPU | Intel(R) Xeon(R) Silver 4114 x1 20c |
| RAM | 32GB DDR4 x16 |
| HDD | 14TB SATA 6GB/s 7200rpm x36 |
| Network | Mellanox ConnectX-6 (100GbE) x2 |
In Apache Ozone and Hadoop, there are no abilities for automatic disk usage balancing. For HDFS, there is Node Rebalancer that, when started, moves data between Datanodes for disk usage equalization. Ozone has a component called Container Balancer, which rebalances data between Datanodes, similar to HDFS, but unfortunately it is not supported in Ozone 1.2 so it was not yet available to us.
During that time, the Datanodes were keeping the imbalanced state and filling up at the same pace on all nodes, both with high and low usage. Some Datanodes had disk utilization above 90% and close to 100%. At that time, we had no knowledge about the behavior when disks of Datanodes would run full. In order to avoid an unpredictable state, we decided to try decommissioning a Datanode that was approaching full disk state. Decommissioning is an operation that removes Datanodes safely from a cluster, copies all data on the Datanode to other Datanodes, and deletes it from the cluster. If we have extra space, decommissioning a Datanode with high utilization will not only prevent a full disk, but also we can expect data to be written to other Datanodes uniformly.
Since disk capacity for each Datanode is 14TB per HDD and wire speed is fast enough, we started decommissioning with the assumption that the copy could be completed in a few days, even considering that it was an HDD. However, it did not end within the period as originally expected, and two months passed with the node state still being DECOMMISSIONING. As a CLI for checking decommission progress was not implemented yet, we had to read Replication Manager logs directly in SCM, and we found out the decommissioning was stuck at some point. That was when we gave up on the idea of data relocation and rebalancing via node removal.
Emerging of Full Disk Nodes
While we tried the container balancer and decommissioning, unfortunately it did not work for us and time passed, and some nodes in the cluster eventually turned into a disk full state. On disks that reached 100% of usage, containers cannot be opened as shown in Fig. 3. A container [5] is a management unit for Ozone that groups blocks up to 5 GB [6]. Ozone does not manage blocks directly unlike HDFS, but it determines data placement and replication count in container units instead.
Ozone always opens RocksDB in write mode for reading metadata when opening containers, and it seemed to have failed to write logs [7] necessary for opening RocksDB. For these situations, containers on nodes with a full disk would be unavailable for reading.
2022-09-07 15:36:24,555 [grpc-default-executor-8298] ERROR org.apache.hadoop.ozone.container.common.utils.ContainerCache: Error opening DB. Container:150916 ContainerPath:/data/21/ozone/hdds/CID-xxx/current/containerDir38/150916/metadata/150916-dn-container.db
java.io.IOException: Failed init RocksDB, db path : /data/21/ozone/hdds/CID-xxx/current/containerDir38/150916/metadata/150916-dn-container.db, exception :org.rocksdb.RocksDBException While appending to file: /data/21/ozone/hdds/CID-xxx/current/containerDir38/150916/metadata/150916-dn-container.db/MANIFEST-001861: No space left on device; status : IOError(NoSpace); message : While appending to file: /data/21/ozone/hdds/CID-xxx/current/containerDir38/150916/metadata/150916-dn-container.db/MANIFEST-001861: No space left on device
Fig. 3: Failure when opening RocksDB
Even if some Datanodes get a full disk, the only impact is that replicas on these nodes become unreadable, so reading other replicas and writes are not affected. At PFN, a huge amount of data was generated and written to the Ozone clusters day by day even though some Datanodes already had a full disk. A few days later, more Datanodes turned into the full disk state. If the replica count for a replication set is not satisfied with the required replication factor, the data in this set cannot be read. When this happened, cluster users reported that some data in the cluster was not readable. On September 12, we had 5 out of 12 Datanodes in the cluster with a full disk. This means more than half of Datanodes in the clusters had a full disk. If we had been able to wait for the release of Ozone 1.3.0, the Container Balancer may have helped us but we needed to fix Datanodes with full disk as soon as possible to minimize negative impact on our research activities.
An Option for “Manual” Rebalancing
In general, manual operation should be avoided for stateful applications such as filesystems and database systems. This is because the consistency should be maintained by the system and manual intervention can easily destroy system-guaranteed integrity due to simple human errors. Basically all required functions for administration should be shipped in the form of management tools. This is a framework to ensure uniform quality of maintenance and to avoid some unexpected operational errors in advance.
However, since this full disk problem could not be solved by the current standard functions of Ozone, and it was expected that manual rebalancing would solve the problem rather than seeking a solution with existing functions, we decided to try to recover the cluster using manual rebalancing.
We were familiar with the internal data structure of Ozone and had the prospect of being able to operate it manually. There was a time when we regularly gathered to read Ozone’s source code, and we have a habit of checking the source code of the current working version if there was anything suspicious or unclear, which helped us this time. For the next following section, we briefly explain how we actually transferred data by manual rebalancing.
Internal data structure at Ozone 1.2.0 follows Container Layout V2, shown in Figure 4. Container Layout V2 is a format that consists of one directory per container, called a container directory. Container directories consist of metadata (RocksDB and YAML) and blocks (Blob).
Ozone Datanodes have hddsVolumes and each volume stores containers (managed by Ozone SCM) as container directories that are identified by container id. The container id is numbered by the SCM in sequential order.
In PFN, Ozone Datanode are set up in JBOD style, each HDD corresponds to a single hddsVolume. Theoretically, a container is just a directory in a filesystem, we were thinking that probably we can do the same thing as replication or container rebalancing if we can move them to other Datanodes while keeping the directory structure.

Fig. 4: HddsVolume structure in Container Layout V2
There was still one more question for manual rebalancing. If we can move container placement manually, is there any problem in terms of consistency for container location metadata? When the Datanode starts, it scans all data in local disks and then sends gathered information about existing and readable containers as a ContainerReport to SCM. This is equivalent to a BlockReport in HDFS. If we completely stopped Ozone, we thought it would be safe to move containers between Datanodes, and we actually confirmed with a small test case that moving containers while stopping some Datanodes is successful.
Since we confirmed the planned operation with small test cases, we decided to do a manual rebalancing on disk usage using the above internal data structure. At the same time, since we could add seven new Datanodes by shrinking the HDFS cluster, we also decided to expand the Ozone cluster by adding Datanodes. Our policy for manual rebalancing was:
- Prepare Datanodes that have the same configuration (same number of disks, same capacity)
- Pick high disk usage (old) Datanodes and copy half of the containers to new Datanodes
- We pair Datanodes (old) and Datanodes (new) and those pairs are exclusive and uniquely identified (for simplification and to avoid conflicts among container copies)
- Maintain the directory structure to follow Container Layout V2 between old and new including SCM ID and Container ID migration
- Delete containers from old Datanodes after copy completion
- Stop Ozone cluster completely just for the maintenance
- Service stop is a reasonable option because more than half of Datanodes in the cluster could not serve files due to a full disk
- Explain clearly to users that the storage service will completely unavailable during the maintenance period and this is a highly important maintenance
Since this maintenance requires service stops, we decided to prepare a more specific schedule and detailed task list.
Offline Maintenance: Plans and Actions
Schedule Planning
Considerations for the offline maintenance are:
- Ensure sufficient operation time
- Minimize maintenance period since offline maintenance will pause our research activities
- Provide a sufficiently long preparation period
- A longer period allows users to prepare for data migration and allows administrators to verify maintenance instructions
- This is a trade-off because the shorter period possibly can avoid upcoming other unexpected disk-related issues
- Add more grace period since there are consecutive holidays in mid-September (Japanese “Silver Week”)
- Do the maintenance in our business hours to leave room for users and administrators to deal quickly with some unexpected problems
- Ensure a buffer day
As for the time required for operation, assuming sufficient parallelism of the copy process allows us to estimate that the maintenance time is equivalent to the time to copy half of the physical HDD volume size in each Datanodes (14 TB / 2 = 7 TB). Each Datanode is connected to each other with 100GbE network, so we initially estimated the copy to finish within a day. Furthermore we allocated one more day as a buffer and finally decided to stop the cluster for up to two days. In order to ensure enough preparation time, we decided to take at least two weeks for the grace period between the maintenance announcement and the day of the copy operation.
Salvage Important Data
As we set two weeks as a preparation time to fix the problem, we needed to provide another option for cluster users who want to immediately use files that were currently unavailable due to the full disk problem. We salvaged some files from the cluster until the maintenance was completed by getting metadata from OM and location of blocks from SCM to identify Datanodes, and then collecting blocks from containers on Datanodes to restore the original file. For data salvaging, we prepared operations such as reading Ozone metadata, downloading blocks and reconstructing blocks, and made these functions generally available from outside of the cluster. Actually these operations are complex to do manually, so we implemented them as a script for automation.
Preparation for Manual Rebalancing
Initial sketch for the manual rebalancing instruction is:
- Stop all processes related to Ozone
- Prepare and add new Datanodes into the cluster
- Copy half of data from Datanode (old) to Datanode (new)
- Delete completely transferred data from Datanode (old)
- Start Ozone
For copying containers, as actually these copies are just simple directory transfers between the servers, so we decided to use rsync. This time, since we wanted only half of the containers in a Datanode, we transferred containers with an even container ID. Accepting transfer targets in a list format as its arguments is also one of the points why we used rsync. Fig. 5 shows an example of transferring containers using rsync. In practice we have 36 HDDs in a single Datanode so we repeat this command for the number of disks and servers, but since it can be sufficiently parallelized, the transfer time is equivalent to one disk.

Fig. 5: An example of filtering target containers and transferring them with rsync
Since this maintenance requires stopping the Ozone cluster, we wanted to make sure in advance that data transfer time fits reasonably within the maintenance window. As a result, we discovered that the full copy of a single Datanode takes up to five days for just copying 7 TB. A Datanode contains many directories and entries, and this results in low throughput. To minimize the downtime, we used a differential copy as preliminary work for the maintenance. Finally, the maintenance instructions were fixed as following:
- Preliminary: List target containers for copy
- Preliminary: Take a full copy of the target data from Datanode (old) to Datanode (new)
- In the window: Stop all processes related to Ozone
- In the window: Take a differential copy of the target data between Datanodes
- In the window: Remove finished containers from Datanode (old)
- In the window: Remove containers that were deleted after the full copy in step 2 from Datanode (new)
- In the window: Start Ozone
As we waited two weeks for the graceful period, two more nodes with full disks emerged and now there were eight nodes in this state. Fig. 6 shows disk usage of Datanode at that time. Since we had seven nodes to be added, we needed to change the maintenance procedure to merging containers in two Datanodes into one in practice.
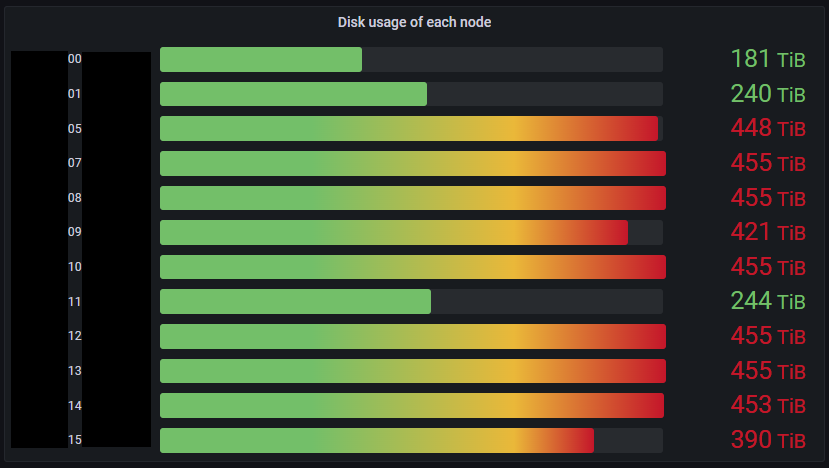
Fig. 6: Disk usage of Datanodes at the before the maintenance day
The Maintenance Day
Although we had to deal with some more new full disk nodes than expected, because the full copies performed as preliminary work had finished successfully until the maintenance day, we stopped the cluster and took the differential copy as planned. For differential copy, rsync has two modes: comparing timestamps and taking checksums between files. We did not use checksum mode to make it faster. Using checksum mode requires calculating the checksum for all target files and throughput is poor for this case.
Eventually, we finished the maintenance on time. On this maintenance day, we went from eight Datanodes with full disks to zero using manual rebalancing, and the disk usage of the entire cluster was also reduced from 85% to 69% by adding new Datanodes. Fig. 7 shows the disk usage report for the cluster after the maintenance. Disk usage related to Ozone indicates green bars and these bars are almost rebalanced among clusters, and finally there is no disk full Datanodes.
Fig. 7: The disk usage report after the maintenance
Manual Rebalancing, a Month Later
Manual rebalance was done on September 22nd. As of now, we do not have any issues caused by the manual rebalance work. In addition, we fixed some other configuration issues of the cluster.
Fixed: Some replication has halted
We noticed expired certificates used by Datanodes after the maintenance. These certificates are used by specific replication procedures among Datanodes and are initialized automatically at the first Datanode launch. Ozone RPC uses Kerberos for the authentication but some replication operations rely on this certificate that was issued by the SCM with a self-signed CA. Actually the expiration date is one year, but functions for renewing certificates are not implemented in Ozone 1.2.0. As our cluster has long-running Datanodes, some certificates in the nodes have already expired.
We have renewed certificates by hand this time and this made replication work properly. While decommissioning is still ongoing after the renewal, the cause of the stuck decommissioning that we met initially is possibly due to expired certificates.
Fixed: Modified ContainerPlacementPolicy
We still see an imbalance for increasing data. We will try to change policies such as ContainerPlacementPolicy, PipelineChoosingPolicy and LeaderChoosePolicy to improve this situation. In particular, we changed the ContainerPlacementPolicy for selecting Datanodes as the container placement to a capacity-aware policy to choose the most vacant Datanodes. As this policy does have an issue (fixed by HDDS-5804) in Ozone 1.2.0, we backported a patch for our internal distribution.
Future works
Ozone is still a young software but the community is highly active. While issues we faced this time were contained in release 1.2.0, most of these issues are fixed for upcoming or future releases so we introduce the following. In PFN, we are running Ozone 1.2.x cluster and master HEAD cluster for anticipating upcoming 1.3.0 release. From now on we will operate clusters while backporting the latest patches if necessary.
Automatic Certificates Renewal (HDDS-7453)
Automate certificate renewal is proposed in the community. This enables us to save effort from toils by manual renewal.
Observability Improvements for Decommissioning (HDDS-2642)
The progress of decommissioning is now exported as metrics. Currently we need to read SCM logs and Datanode state and that was the only way to check the progress of decommissioning. This proposal enables us to improve observability for decommissioning.
Reserved Volume Space (HDDS-6577 & HDDS-6901)
HddsVolume now can claim some reserved space in the Datanode. This change enables to limit disk spaces as some margins for disks, and prevent full disks, and this results in less metadata failures.
Container Balancers (HDDS-4656)
Now we have container balancers in Ozone. This eliminates the need for the manual rebalancing work such as the one we did. This is a significant feature for us to operate clusters, we will carefully evaluate this for our clusters.
Conclusion
As a result of incremental cluster expansion, we experienced disk usage imbalance and moreover some Datanodes reached the state of a full disk. This situation prevented us from reading data from these nodes. In this article, we shared our background and why we made a decision of manual rebalancing and we shared our maintenance operations by introducing the internal data structure of Ozone Datanode. We decided to do offline maintenance by stopping the cluster because more than half of the Datanodes were getting to a degraded state and plans were carefully designed to minimize downtime.
For the maintenance, at first we added seven new Datanodes to the Ozone cluster and then manually moved half of the containers from old to new Datanodes. While the maintenance this time required deep knowledge of the Ozone implementation and its internal data structure, fortunately we finished the maintenance without any troubles and the cluster is still healthy a month after.
We are hiring!
PFN is operating several in-house storage systems (Apache Ozone, HDFS, NFS) focused mainly on object storage systems. We are not just operating existing systems, we are doing everything about our storage systems including server procurement, capacity planning, integrations with our on-premises Kubernetes clusters and user support. If you are interested, please apply via Job Openings in the career page or contact some PFN members.
References
- [1] Development of Universal Neural Network for Materials Discovery, PFN Tech Blog, 2022
- [2] A Research for Geophysical Exploration Methods using a Deep Learning Technology (深層学習を用いた物理探査技術の研究開発; written in Japanese), PFN Tech Blog, 2021
- [3] An Analysis of Earthquake Wave with Machine Learning (機械学習を用いた地震波解析; written in Japanese), PFN Tech Blog, 2022
- [4] Learning Time Evolution Dynamics in Low-Dimensional Latent Spaces of Numerical Simulation Data (数値シミュレーションデータの低次元潜在空間における時間発展ダイナミクスの学習; written in Japanese), 2022
- [5] Containers, Documentations for Apache Ozone, 2021
- [6] Storage Container Manager, Documentations for Apache Ozone, 2021
- [7] MANIFEST, RocksDB Wiki, 2022
Acknowledgement: I appreciate Kota Uenishi, Kiyoshi Mizumaru, Tobias Pfeiffer and Yusuke Doi for helping me a lot to improve this article.
Area
