Blog
はじめに
近年、ニューラルネットワークを用いた機械学習の実用化が様々な分野で進んでいます。機械学習モデルの推論精度を向上させるためには、通常多くの試行錯誤が必要となりますが、モデルのデプロイ先の多様化に伴い、単純な精度向上だけでなく利用環境の制約(推論速度、メモリ使用量、バッテリー消費量、等々)も考慮したチューニングが必要となっています。
そのようなニューラルネットワークを実デバイス上での速度や精度の要求に合わせてチューニングする作業は、多くの人的資源と計算資源を要します。PFNでは、この作業を自動化しつつ人手よりもさらに良いモデルを作成する手法の一つとして、ニューラルアーキテクチャ探索(Neural Architecture Search、以降は”NAS”と表記)を効率的に行うためのエコシステムの整備を進めています。
本記事では、開発を行っているNASエコシステムの概要と、その適用事例の一つとして、自律移動ロボット上で動作するセマンティックセグメンテーションモデルのアーキテクチャ探索を行った結果を紹介します。今回取り上げる事例は、実デバイス(ロボット上のプロセッサ)へのデプロイを伴うプロジェクトでのNASですが、精度と速度の幅広いトレードオフを含んだ、優れたアーキテクチャ群を発見することができました(図1)。
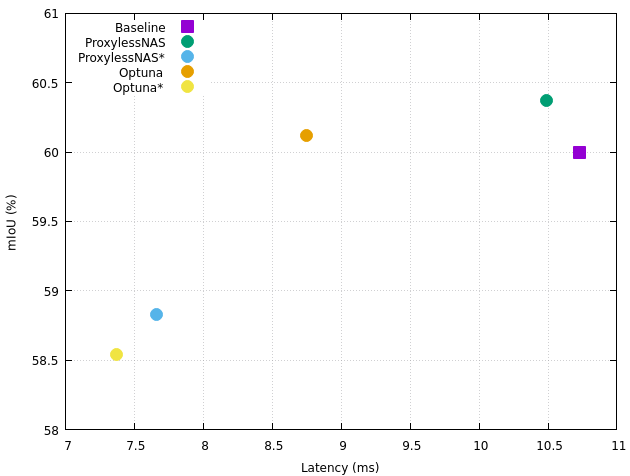
図1: モデルの性能(mIoU)とデバイス上での推論時間(latency)を軸としたセマンティックセグメンテーションモデルのアーキテクチャ探索の結果。各点は見つかったアーキテクチャ、ラベルは探索に用いた手法名、を表しています(末尾の”*”の有無は、探索手法ではなく探索空間の違いを示しています)。エンコーダ部にMobileNetV2を使用したベースラインモデルよりも、推論時間が短い、様々なトレードオフのアーキテクチャ群が発見できていることが見て取れます。
NASエコシステム
図2は開発を進めているNASエコシステムの概要になります。
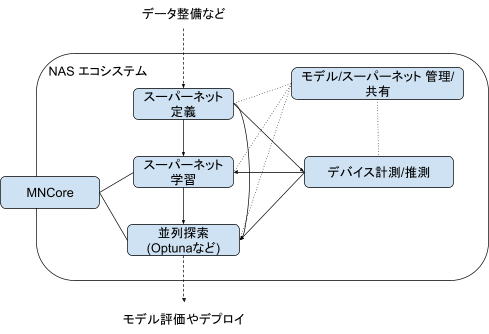
図2: NASエコシステムの概要
NASでは、スーパーネットと呼ばれる探索空間内の全ての候補モデルを包含した巨大なモデルがよく使用されます。こうしたモデルの構築や学習、管理には通常のニューラルネットワークとは異なるサポートが必要となります(Appendixの「スーパーネットの定義・学習方法」には実例がいくつか記載されています)。 また、デプロイ先デバイス(CPU、GPU、SoC、etc)によって最適なアーキテクチャは変わってくるため、モデルの性能を最大限に発揮させるためにはデプロイ先での性能計測・推測も重要となってきます。さらに、これらの特殊な計算をPFNの計算資源(GPUクラスタ, MN-Core)を生かして行い、発見された大量のモデルや、それらのモデルの作成過程を管理する必要もあります。このようにPFNでは、NASの実用途への適用を容易にすることを目指して、様々なレイヤーのフレームワークやサービスの開発を行なっています。
中でも、スーパーネットの定義と学習を行うフレームワークは既存のOSSには見られない様々な特徴を備えています。このフレームワークではモデル定義と探索アルゴリズムが分離されており、例えばNAS-FPNのような複雑な探索空間(図3)をスーパーネットとして定義しつつ、ProxylessNAS などのウェイトシェアリングを用いた多目的最適化アルゴリズムを適用するといった野心的な組み合わせも実行できます。
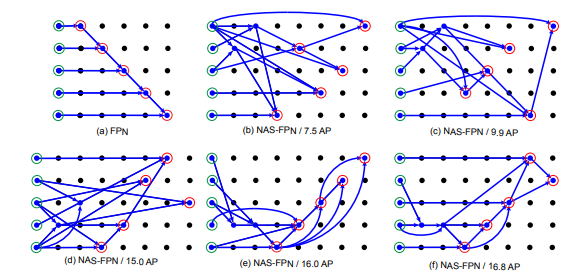
図3: NAS-FPNの探索空間で表現可能なアーキテクチャの例(https://arxiv.org/abs/1904.07392より引用)
事例: セマンティックセグメンテーションでのNAS
ここからはPFN社内でのNASの事例紹介となります。
探索対象は、自律移動ロボット上で動作するセマンティックセグメンテーション(画像内の各画素のラベルへのマッピング)用のモデルで、ロボットの特性上リアルタイム性が重要となるため、「推論性能をなるべく落とさずに推論時間を削減したい」というのが探索の目的です。
問題設定
ベースラインモデル
ベースラインモデルとしては、エンコーダ(Encoder)とデコーダ(Decoder)の組み合わせからなるシンプルなセマンティックセグメンテーションモデルを使用しています(図4)。エンコーダ部分にはatrous-convolutionを用いたMobileNetV2を、デコーダ部分にはconvolution layer一層を採用しています。
図4: セマンティックセグメンテーションのイメージ (https://arxiv.org/abs/2001.05566 より引用)
この中のエンコーダ部分が、今回のアーキテクチャ探索の対象範囲となります。
探索空間
ProxylessNAS論文が定義しているMobileNetV2ベースの探索空間を採用しています。この探索空間では、MobileNetV2内の各InvertedResidualブロックの構造が探索対象となっており、選択肢は以下の通りです(図5):
- kernel size: 3 or 5 or 7 (MobileNetV2の場合は常に3)
- expansion ratio: 3 or 6 (MobileNetV2の場合は常に6)
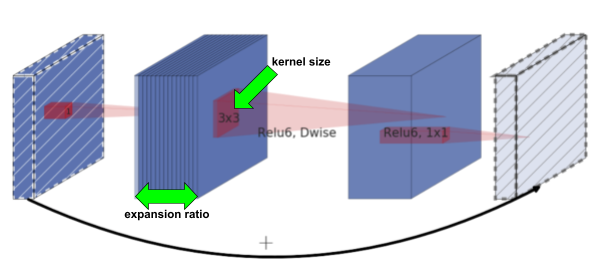
図5: InvertedResidualブロックと探索範囲(https://arxiv.org/abs/1812.00332より引用)
ブロックは最大で21個存在し、特定のブロックをスキップするかどうかも探索対象に含まれます(ただし各レイヤーの先頭ブロックがスキップされることはありません)。探索空間のサイズ(候補アーキテクチャの総数)はおよそ10の17乗となります。
また、上記の探索空間を低レイテンシ寄りに調整した亜種も併用しており、こちらを使用して発見されたアーキテクチャに関しては、結果(図1およびテーブル1)のラベル名の末尾に”*”が付与されています。探索空間の違いが探索効率に与える影響に関しては、Appendixにも記載があるので、興味のある方はそちらも参照してみてください。
データセット
モデルの学習および評価には、自社で収集したデータセットを使用しています。モデルの学習用に約10,000枚、評価用に約1,000枚の画像およびアノテーションデータが存在します。また、探索時を除き、エンコーダでは別データセットで事前学習した重みを使用しています。
アーキテクチャの評価指標
アーキテクチャの評価指標としてはmIoU(mean Intersection over Union)とNVIDIA GPU上での推論時間(レイテンシ)が使われています。今回は「mIoUの最大化」と「レイテンシの最小化」を同時に目指す多目的探索となります。
なお、デプロイ対象デバイス上で毎回レイテンシを実測するのは手間なので、探索時には代わりに推定値を使用しています(詳細はAppendixを参照)。
探索アルゴリズム
今回はOptunaとProxylessNASを使って探索を行いました。
Optuna
OptunaはOSSのハイパーパラメータ最適化ライブラリですが、NASの用途にも適用可能となっています。今回は、mIoUとレイテンシの最適化が行いたいので、多目的最適化に対応したNSGA-IIサンプラーを利用しています。また、低レイテンシ付近を重点的に試行する必要があったのでenqueue_trialという機能を用いて「一番レイテンシの短いアーキテクチャ」をシードとして探索対象に含めています(なお、v2.5.0からNSGA-IIで制約が表現可能になったので、今なら「レイテンシが〇〇ms以下を重点的に探索する」といった指定も可能です)。
Optunaによる探索では「候補アーキテクチャ(モデル)のサンプリングと学習・評価」が試行回数分繰り返されることになります。各試行でのモデルの学習設定は、基本的に通常の学習時のものと同様ですが、以下の点が異なっています:
- エポック数は通常の学習時の1/10倍
- ImageNetでの事前学習は無し
- 評価用データセットには、学習データセットの1/10をスプリット
参考までに、Optunaの可視化機能を使ってプロットした、探索結果の図を載せておきます。
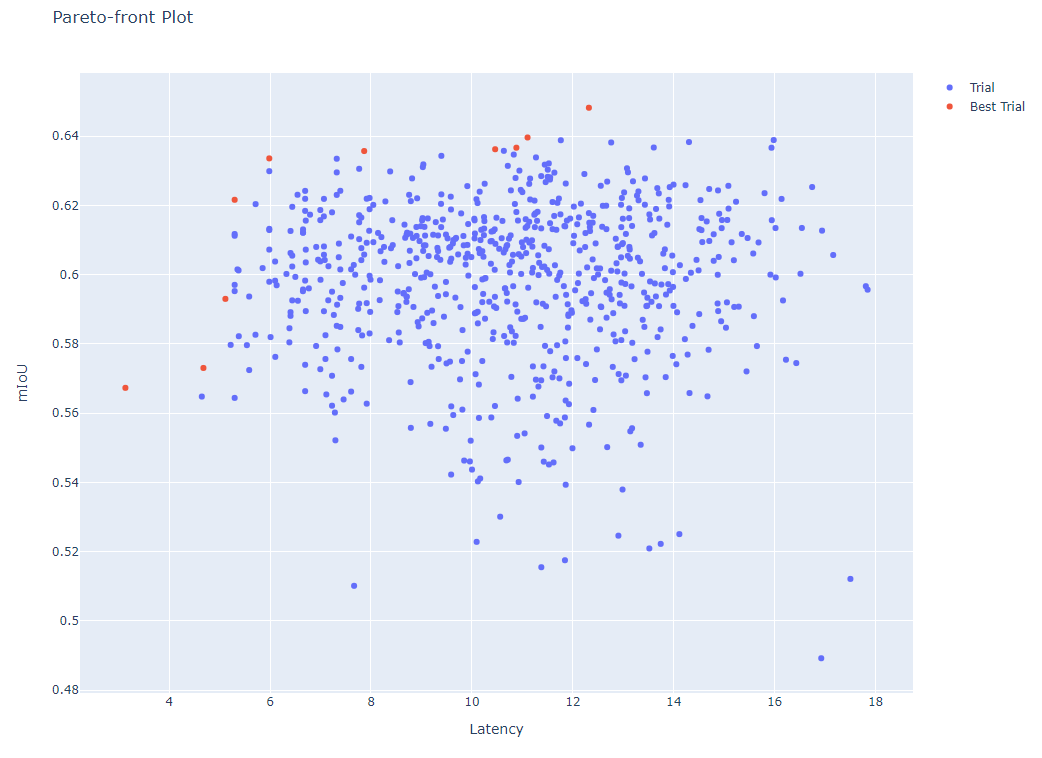
図6: Optunaでの探索結果。各点はサンプリングされたアーキテクチャに対応。左上のものほど、レイテンシは短く、mIoUが高い、優れたアーキテクチャとなる。
ProxylessNAS
もう一つの探索アルゴリズムとしては、勾配ベースのProxylessNASを使用しました。ProxylessNASの詳細は論文を参照して貰うのが良いですが、一言で書くなら、スーパーネットモデルの学習とアーキテクチャ探索を同時に行うような手法になります。そのため、Optunaのように何度もモデルの学習(試行)を繰り返す必要がなく、効率的に探索が行えるという利点があります。
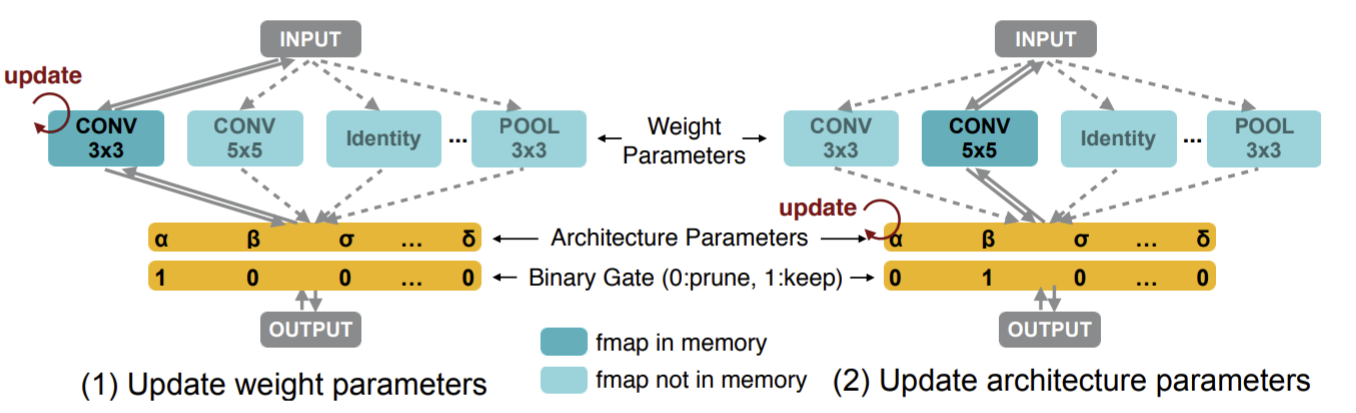
図7: ProxylessNASでのモデル学習ループ。各イテレーションで、通常の重みパラメータの更新と、探索用のアーキテクチャパラメータの更新を交互に行う(https://arxiv.org/abs/1812.00332より引用)
今回は探索時にレイテンシを考慮する必要があるため、図7の右の「Update architecture parameters」の際には、レイテンシを正則化項として加味したロス関数を使用しています。
モデルの学習設定は、基本的に通常の学習時のものと同様ですが、以下の点が異なっています:
- ImageNetでの事前学習は無し
- 探索(アーキテクチャパラメータ更新)用データセットには、学習データセットの1/2をスプリット
探索の流れ
探索全体の流れは以下の様になります:
- 【探索準備】レイテンシ推定のためのデータ収集
- 【探索実行】OptunaないしProxylessNASで探索を実施
- 【評価準備】見つかったアーキテクチャ(エンコーダモデル)を事前学習
- 【評価実行】上のアーキテクチャを用いたセグメンテーションモデルを学習し、mIoUとデバイス上でのレイテンシを取得
探索結果
探索結果は冒頭の図1にも示されていますが、それを表にまとめたものを以下に再掲しておきます。この表には追加で探索に要したGPU時間(Search GPU hours)およびOptunaでの試行回数(n_trials)も記載されています(なおAppendixには、発見されたアーキテクチャ群の可視化結果も載っています)。
| 探索手法名 | Latency (ms) | mIoU (%) | Search GPU hours | n_trials |
| Optuna* | 7.37 | 59.26 | 240 | 90 |
| ProxylessNAS* | 7.66 | 59.96 | 64 | |
| Optuna | 8.75 | 61.70 | 2544 | 708 |
| ProxylessNAS | 10.49 | 62.43 | 56 | |
| Baseline | 10.73 | 61.08 |
テーブル1: NASによって発見されたアーキテクチャ群およびベースラインモデルの評価結果
テーブル1を見ると、様々なトレードオフを含んだアーキテクチャ群が発見できていることが見て取れます。例えば”Optuna”では、mIoUを維持したまま、レイテンシを二割減らすようなアーキテクチャが見つかっています(なお実際には、各探索手法で複数個のアーキテクチャが見つかっていますが、簡単のためにそれぞれで代表的なものを一つだけピックアップしています)。
探索時間の観点では、Optunaは候補アーキテクチャの評価の度にモデルの学習が必要となるため、”ProxylessNAS”や”ProxylessNAS*”に比べて、優れたアーキテクチャを発見するまでに、かなり長い時間を要しています。低レイテンシ寄りに調整された探索空間を用いた”Optuna*”では、比較的少ない試行回数で済んでいますが、それでもProxylessNASに比べると数倍の時間が掛かっています。
ただしOptunaには「制約が少なく幅広い範囲に適用可能(例えば、目的関数に微分可能性が不要だったり、モデルアーキテクチャ以外の通常のハイパーパラメータも同時に最適化可能です)」あるいは「パレートフロント(図6)が描けるため全体の傾向が掴みやすい」といった利点もあるため、今後もケースバイケースで使い分けて行くことになると考えています。
おわりに
本記事では、PFNにおけるNASの取り組みを紹介しました。
NASは、今回の事例以外にも複数の社内プロジェクトで活用されており、実績やノウハウが蓄積されています。今後は、こういった知見や開発したツール、MN-Core等の計算資源を生かして、さらに多くのプロジェクトで積極的にNAS活用を推進していきたいと考えています。
また、本記事では概要紹介のみとなりましたが、NASエコシステム自体の開発は現在も進んでおり、どんどん便利になっています。この辺りは面白い話題も無数にあるため、機会があればまた別途紹介したいと思っています。
Appendix
低レイテンシ寄りに調整された探索空間
今回の事例では、ProxylessNAS論文が定義するMobileNetV2ベースの探索空間を採用しましたが、それをより低レイテンシ寄りに調整した探索空間も同時に使用しました。テーブル1のラベル名の末尾に”*”が、この調整版の探索空間を使用して探索を行ったことを表しています。
この探索空間は、大まかには以下の二つの調整がなされています:
- 同一レイヤ内のブロック群で選択されるkernel-sizeおよびexpansion-ratioは等しくなるようにする => サンプリングされたアーキテクチャ群のレイテンシの分散が大きくなりやすくなる
- あるブロックがスキップされた場合は、同じレイヤ内の後続のブロックも全てスキップする => スキップがより積極的に選択され、全体のレイテンシが短くなる
これによって、レイテンシの分布は図8のように変化し、アーキテクチャのサンプリング時にレイテンシが短いものが選択されやすくなりました。
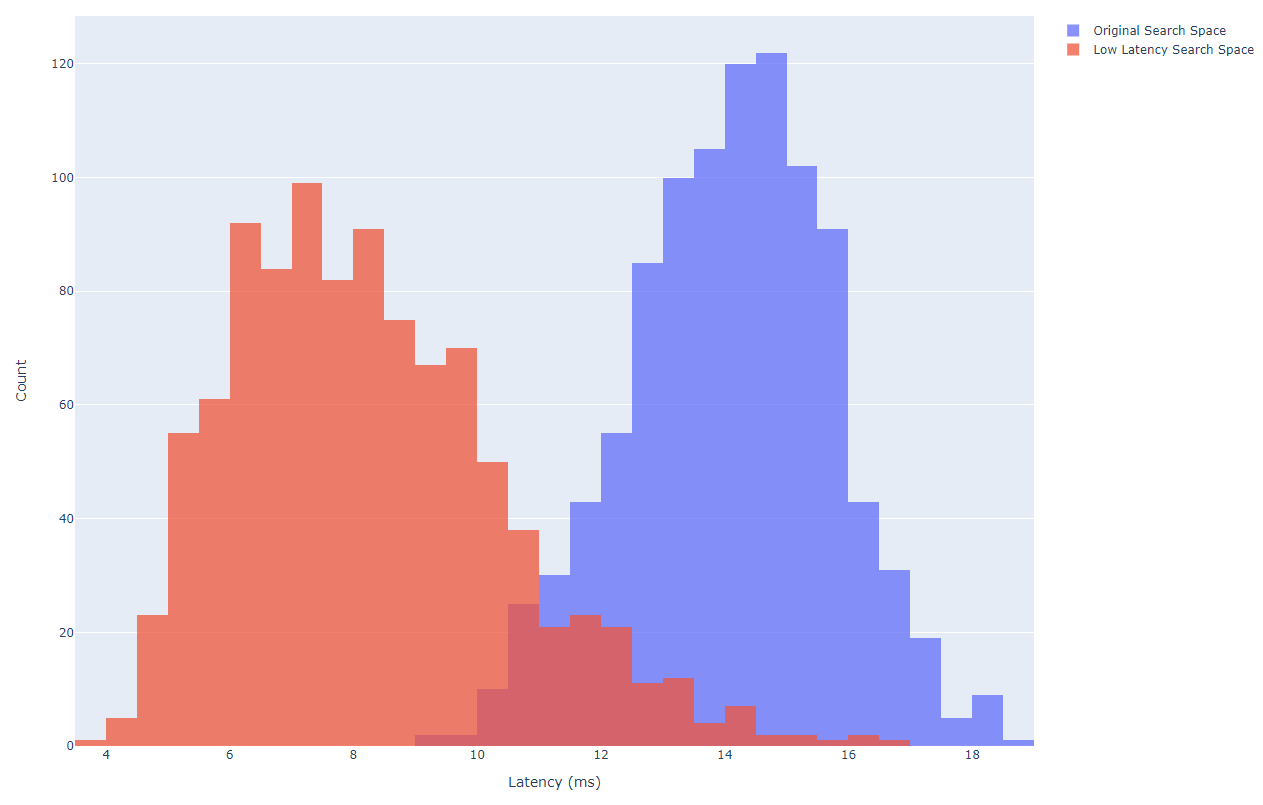
図8: 探索空間によるレイテンシの分布の違い。オリジナルの探索空間および低レイテンシ寄りに調整された探索空間から、それぞれ1000個のアーキテクチャをランダムにサンプリングし、結果をヒストグラムで表示している。
この調整の影響はOptunaでの探索効率に顕著に現れており、テーブル1にも示されているように、調整版探索空間を用いた”Optuna*”は、通常の探索空間を用いた”Optuna”よりも、大幅に短い時間で、レイテンシが短い良いアーキテクチャを発見できていました。
もちろん理想としては、探索空間を人手で弄ることはせず、探索アルゴリズム側の工夫のみで所望のアーキテクチャを発見できることがベストですが、プラクティカルには、こういったテクニックもとても重要となってきます。
見つかったアーキテクチャ群
参考までにNASによって発見されたアーキテクチャの可視化結果を載せておきます。
角丸の長方形は、一つのInvertedResidualブロックを表します。また、長方形の色および〇x〇はkernel-sizeを、大きさおよびMB△はexpansion-ratioを、反映しています。
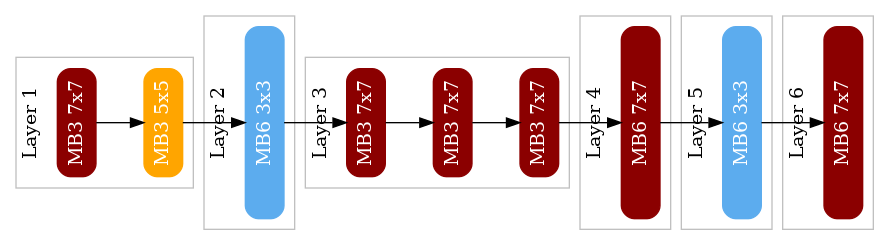
図9: “Optuna*”の発見アーキテクチャ (latency=7.37, mIoU=59.26)
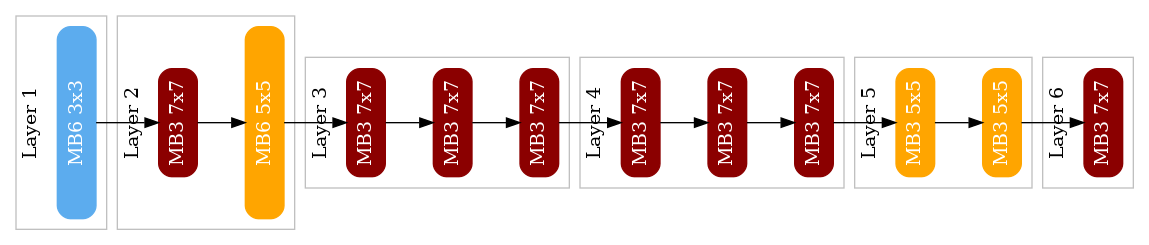
図10: “ProxylessNAS*”の発見アーキテクチャ (latency=7.66, mIoU=59.96)

図11: “Optuna”の発見アーキテクチャ (latency=8.75, mIoU=61.70)

図12: “ProxylessNAS”の発見アーキテクチャ (latency=10.49, mIoU=62.43)
スーパーネット(探索空間)の定義・学習方法
本記事で取り上げたようなNASを簡単に行えるようにするためには、通常のニューラルネットワークの定義や学習に加えて、スーパーネットのサポートが必要となります。
スーパーネット(探索空間)の定義や学習、およびそれを用いた探索を容易にするために、PFNではOptuNASという名前の、PyTorch向けのNASライブラリの開発を行っています。これは名前の通り、探索アルゴリズムとしてOptunaが利用可能な他、DARTSやProxylessNAS、SPOS等といったNAS固有のアルゴリズム群もサポートしています。
スーパーネット(探索空間)定義
OptuNASでの探索空間は、torch.nn.Moduleを継承したスーパーネットモデルによって定義されます。一番ベーシックな方法では、Choiceというクラスを使用して、以下の様に記述することになります。
from optunas.nn import Choice
from torch import nn
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self._module = nn.Sequential(
Choice(
name="input_conv",
module_dict=dict(
conv_1x1=nn.Conv2d(3, 4, kernel_size=1, padding=0),
conv_3x3=nn.Conv2d(3, 4, kernel_size=3, padding=1),
conv_5x5=nn.Conv2d(3, 4, kernel_size=5, padding=2),
conv_7x7=nn.Conv2d(3, 4, kernel_size=7, padding=3),
),
),
nn.ReLU(),
nn.Conv2d(4, 5, kernel_size=3, padding=1),
)
def forward(self, x):
return self._module(x)
図13: Choiceを使った探索空間(スーパーネットモジュール)の定義例
今回は割愛しますが、Choiceよりもプリミティブな、計算グラフをダイレクトに記述するためのAPIも存在します。これによってChoiceが並んだだけのシンプルな探索空間だけでなく、DARTSやNAS-FPNの論文が使用しているグラフ構造が変化するような探索空間まで、同じ枠組みの中で扱えるようになっています。
Optunaによる探索
Optunaを使ったアーキテクチャ探索のコードは、以下のような形になりますoptunas.optuna_sample()の中ではOptunaのSuggestAPIを用いてアーキテクチャのサンプリングが行われています。
import optuna
import optunas
def objective(trial):
module = MyModule()
optunas.optuna_sample(module, trial) # Sample a sub-network.
train(module) # Train the sub-network with fewer epochs.
miou = evaluate_miou(module)
latency = evaluate_latency(module)
return [miou, latency]
study = optuna.create_study(directions=["maximize", "minimize"])
study.optimize(objective, n_trials=100)
図14: Optunaを使ったアーキテクチャ探索例(mIoUとレイテンシの多目的探索)
ProxylessNASによる探索
次のコードは、ProxylessNASを用いたアーキテクチャ探索の例となります。
train_data_loader = ...
test_data_loader = ...
search_data_loader = ...
# Loss function to optimize model parameters (weights).
def train_loss(output, target):
...
# Loss function to optimize architecture parameters.
def search_loss(batch):
data, target = batch
...
architect = optunas.architects.ProxylessNASArchitect(
module=module,
data_loader=search_data_loader,
loss_fn=search_loss,
)
# Training loop.
for epoch in range(0, epochs):
for data, target in train_data_loader:
# Update model parameters.
optimizer.zero_grad()
output = module(batch)
loss = train_loss(output, target)
loss.backward()
optimizer.step()
# Update architecture parameters.
architect.step()
# Select the best architeccture and evaluate it with the test dataset.
...
図15: ProxylessNASを用いたアーキテクチャ探索例
Optunaとは異なり、ProxylessNASの場合には、モデルの学習と探索が同時に行われるため、学習ループに少し手を入れる必要があります(コード例の中のarchitect.step()呼び出し)。
今回はProxylessNAS用にoptunas.architects.ProxylessNASArchitectというクラスを使用していますが、この部分を(例えば)optunas.architects.DARTSArchitectのように別のクラスに変更することで、他のNASアルゴリズムを簡単に試せるようになっています。
デバイスでのレイテンシ推定
本文中にも記載がある通り、今回は事例では、探索時にはアーキテクチャのレイテンシを毎回デバイス上で計測することはせずに、推定値を利用しています。
仕組みを簡単に紹介すると、以下のようになります:
- 探索空間(スーパネットモデル)内の各サブモジュールを、Choiceモジュールを跨がないように分割(例えば、今回は各InvertedResidulaブロックがChoiceモジュールで囲まれているので、それが一つの計測単位となる)
- 事前に上の各サブモジュールのレイテンシをデバイス上で計測して記録しておく
- 推定時には、対象アーキテクチャ内の各サブモジュールの測定値を合算する
図16は、この推定値とデバイスでの実測値の相関度合を示した図となりますが、推定値と実測値がかなり一致していることが見て取れるかと思います。
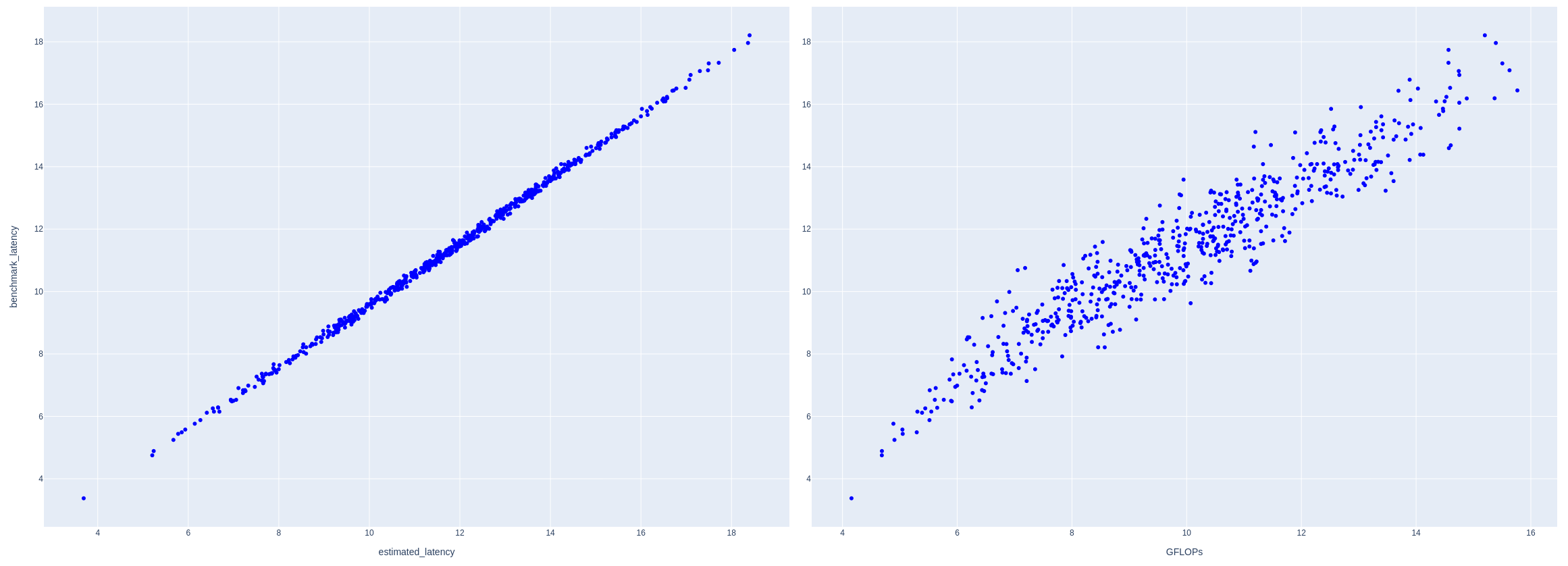
図16: 左はレイテンシの推定値と実測値の相関度合い、右はFLOPSとレイテンシ実測値の相関度合い
比較対象として、右図にFLOPSとレイテンシ実測値のプロットも載せてありますが、こちらの方が点がバラけており、相関度合いが低くなっています。
探索時に使用する評価値(推定レイテンシやFLOPS)と最終評価値(デバイス上での実測値)の順位相関が低いと、本当は良くないアーキテクチャを優れたものと誤認してしまう可能性が高まるため、今回は推定レイテンシの方が、FLOPSに比べて、NASの評価指標として相応しいと言えます。
また面白い点として、左図では点群がy=xと比べて若干右に移動しています。これはサブモジュールを個別に計測して合算した値は、サブモジュール全てを含むモジュール全体を計測した値と比べて少し大きい傾向にあることを表しています。モジュール全体を実行する場合は非同期実行による最適化が行われるため、若干レイテンシが小さくなることが原因と考えられます。
