Blog
はじめに
みなさん、こんにちは。PLaMo事後学習チームの今村です。我々は本日、国産生成AI基盤モデルPLaMo™︎の新たなフラグシップモデルPLaMo 3.0 Primeをリリースしました。PLaMo 3.0 PrimeはPLaMo Chat/API経由でご利用いただけます。Freeプランもありますのでぜひこちらからご利用ください。
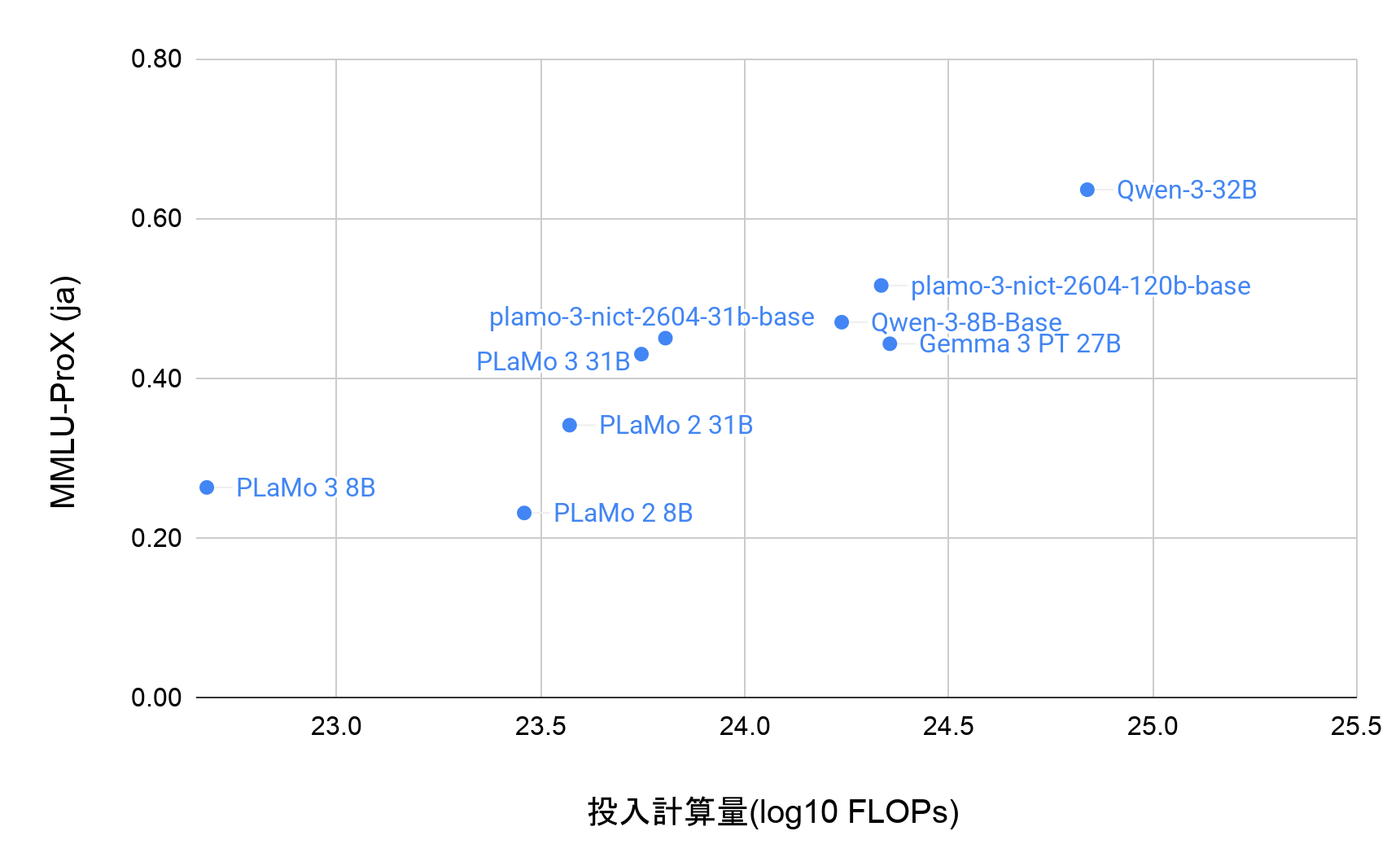
PLaMo 3.0 Primeは、先日リリースしたPLaMo 3.0 Prime β版をベースにモニター企業様等のフィードバックを踏まえて様々な性能向上と安定化を施したモデルです。PLaMo 3.0 Prime β版で初めて導入された推論能力をさらに強化し、また同時に高速な応答が求められるユースケースに向けて非推論モデルを開発しました。さらに対応するコンテキスト長を64Kから256Kに拡張しました。PLaMo 3.0 Primeは高い日本語性能と低いコストを両立しており、図1のようにgpt-oss-120bやQwen3.6-27bといった同性能帯のオープンモデルやGPT-5.4 MiniやClaude Haiku 4.5といった同価格帯のクローズドモデルに対して高い競争力を持ちます。

図1: PLaMo 3.0 Primeと各種モデルの日本語性能とコストの比較。縦軸は我々が内部で保有する日本語ベンチマークスイート上のスコアの平均値(日本語知能指数, Japanese Intelligence Index)、横軸は実際に評価にかかった料金です。料金は評価時の入出力トークン数に、PLaMoについてはPLaMo APIのStandardプランの料金を、それ以外のモデルについてはOpenRouter https://openrouter.ai/ の平均価格を乗じて算出しています。日本語ベンチマークスイートについてはAppendixをご確認ください。各点にはスコア/コスト/トークン数を記載しています。
TL;DR
- 強化学習をより長期間に渡って実施することにより推論能力の全体的な底上げを達成しました。
- 高速な応答が要求されるユースケースに向けて非推論モデルを開発しました。
- エージェント環境に向けた利用を念頭にコンテキスト長を64Kから256Kに拡張しました。
- 安全性能向上に向けた取り組みを実施し既存モデルと同程度に安全であることを確認しました。
- 構造化出力のサポートにより、既存システムや外部APIとの連携が大幅に容易になりました。
何が変わったか
推論能力の強化
PLaMo 3.0 Primeは先日リリースしたPLaMo 3.0 Prime β版をさらに進化させたモデルです。PLaMo 3.0 Prime β版に用いられている技術詳細についてはこちらのブログや公開しているスライドをご覧ください。
PLaMo 3.0 Primeでは、PLaMo 3.0 Prime β版で導入した強化学習を、データを増強してさらに長期間実施しました。増強したデータはコーディング、長コンテキスト、対話性能など多岐にわたります。強化学習はPLaMo 3.0 Prime β版の時と比べてステップ数で倍程度実行しています。実際の推論能力の向上についてはベンチマーク結果のセクションをご確認ください。
非推論モデルの開発
先日リリースしたPLaMo 3.0 Prime β版では推論モデルのみを提供していましたが、モニター企業様等のフィードバックから、性能が高く応答に時間がかかるモデルだけでなく、性能はそこそこに高速な応答が可能なモデルのニーズがあるとわかりました。そこでPLaMo 3.0 Primeでは推論モデルの開発で新たに導入した学習パイプラインやその過程で得た知見を盛り込み、非推論モデルを開発し直して提供することにしました。必要に応じて推論/非推論をユーザ自身が切り替えることで、用途に合わせた利用が可能です。以前の非推論モデルPLaMo 2.2 Primeと比べた性能向上についてはベンチマーク結果のセクションをご確認ください。
コンテキスト長の拡張
今後我々が注力していくエージェント環境での利用において、LLM は長大なツール利用の履歴を保持できるよう長いコンテキストをサポートしなくてはなりません。PLaMo 3.0 PrimeではPLaMo 3.0 Prime β版でも採用したYaRNと継続事前学習によるコンテキスト長拡張をさらに実施し、従来のコンテキスト長64Kを256Kまで拡張しました。この長さは同性能帯のオープンモデルであるgpt-oss-120bの128Kより長くQwen3.6 27Bの256Kと同程度であり、また同価格帯のクローズドモデルであるClaude Haiku 4.5の200Kより長くGPT-5.4 Miniの400Kよりは短い程度です。概して、PLaMo 3.0 Primeは競合モデルに対してコンテキスト長の意味で競争力のあるモデルとなったと言えます。しかしながら最先端のオープンモデルであるDeepSeek V4 Proの1MやクローズドモデルのGPT-5.5 Proの1Mなどとはまだギャップがあるため、我々は今後もコンテキスト長の拡張に挑戦していきます。
安全性能の向上
PLaMo 3.0 Primeの開発にあたっては、ユーザ企業様が自社サービスに安心して組み込めるよう、安全性向上に向けた学習データの構築および訓練を実施し、一般的な安全性能ベンチマークおよび内部的な独自ベンチマークを用いた評価を行いました。特に訓練においては、国立研究開発法人情報通信研究機構(NICT:エヌアイシーティー)から提供を受けた安全性に関するデータを活用しました。PLaMo 3.0 Primeは、スタンフォード大学基盤モデル研究所が開発・運用する安全性能評価ベンチマークスイートHELM Safetyにて、競合モデルと同程度以上の性能を発揮します。HELM Safetyは暴力、詐欺、差別、性的表現、ハラスメント、欺瞞といった6つの安全性カテゴリを網羅する5つの安全性ベンチマークを統合したベンチマークスイートで、「LLMが危険なことを言わないか」を見るだけでなく「拒否ではなく安全な回答が可能か」、「過剰な拒否が起こらないか」、「jailbreak可能性はないか」、「レッドチーミング環境で安全な会話が可能か」などを体系的に評価することができます。実際のHELM Safetyにおける評価結果については、ベンチマーク結果のセクションをご確認ください。
構造化出力のサポート
PLaMo 3.0 Primeでは、新たに構造化出力(Structured Output)をサポートしました。構造化出力とは、LLMからのレスポンスをユーザーの指定したデータ構造に必ず準拠する形で出力する機能です。従来のプロンプトエンジニアリングによる形式指定では出力の安定性や堅牢性に課題がありましたが、本機能により既存のシステムや外部APIと連携するアプリケーションの構築やインテグレーションが大幅に容易になります。
ベンチマーク結果
PLaMo 3.0 Primeの推論/非推論モデルを過去の推論モデルであるPLaMo 3.0 Prime β版, 過去の非推論モデルであるPLaMo 2.2 Prime, 現在ローカルやオンプレミス環境で活発に利用されているオープンモデルであるQwen3.6-27B, gpt-oss-120b (reasoning effortを中くらいの”medium”に設定したもの), 同価格帯のクローズドモデルであるGPT-5.4 Mini, Claude Haiku 4.5と比較します。実際に提供される PLaMo 3.0 Primeではデプロイ先ハードウェアに合わせた最適化を行っているため一部挙動や性能が異なる場合があります。
比較するベンチマークは、我々が性能向上を狙ってトラックしてきた英語/日本語指示追従性能(IFBench/JFBench)、英語/日本語対話性能(MT-bench, Japanese MT-bench)、英語ツール使用性能(BFCL)、Web検索付き質問応答性能(BrowseComp-Plus)、長コンテキスト質問応答性能(LongBench v1, LongBench v2)、STEM分野における性能(AIME 2024, GPQA-Diamond)、コーディング性能(LiveCodeBench)、日本の法令に関する質問応答性能(lawqa_jp)、医療分野における質問応答性能(MedRECT, 医師国家試験)、安全性能(HELM Safety)です。ベンチマークの評価方法の詳細については、Appendixをご確認ください。
図2に15個のベンチマークそれぞれに対する評価結果を示します。ほとんどすべてのベンチマークにおいて、PLaMo 3.0 Primeの推論/非推論モデルはそれぞれPLaMo 3.0 Prime β版/PLaMo 2.2 Primeよりも改善しています。
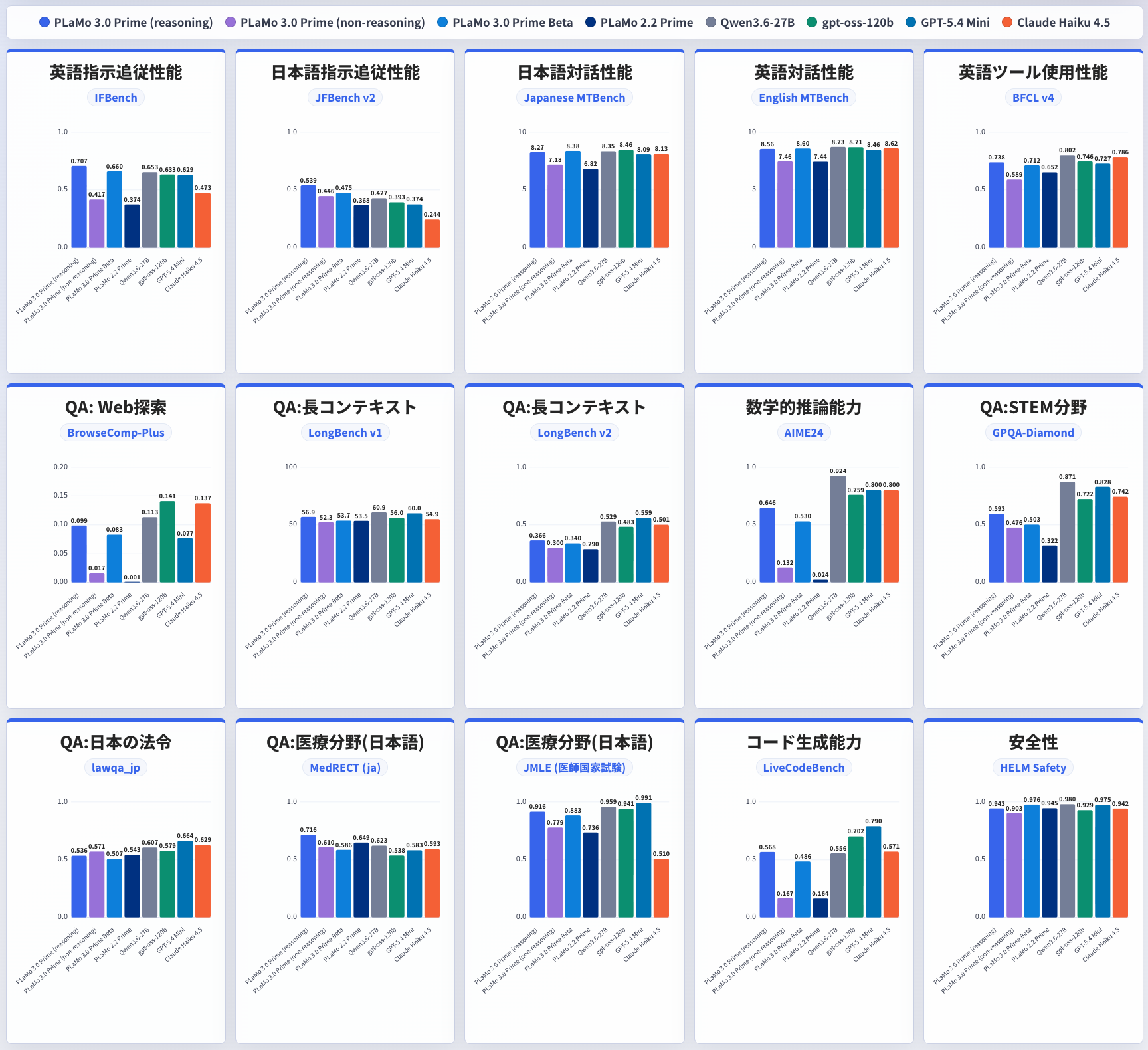
図2: PLaMo 3.0 Primeの推論/非推論モデル, PLaMo 3.0 Prime β版, PLaMo 2.2 Prime, Qwen3.6-27B, gpt-oss-120b, GPT-5.4 Mini, Claude Haiku 4.5を種々のベンチマークにおいて比較した図
PLaMo 3.0 PrimeとQwen3.6-27B, gpt-oss-120b, GPT-5.4 Mini, Claude Haiku 4.5を比較すると、多くのベンチマークで彼らと同等程度の性能を発揮していると言えます。特に指示追従、対話、ツール使用、医療分野、コード生成能力、安全性ではより優れた性能を発揮している場合もあります。一方でWeb探索、長コンテキスト、数学的推論、STEM分野の質問応答、日本の法令分野では劣っており今後の積極的な改善が必要であると考えています。
また図3に安全性能を測るベンチマークであるHELM Safetyの各カテゴリごとの結果を示します。PLaMo 3.0 Primeは他のモデルと同程度以上の高い安全性能を発揮していることがわかります。ただし幾つかのカテゴリにおいて、特に非推論モデルは過剰拒否しがちであったり危険なプロンプトに応答したりしており、さらなる改善が必要であると考えています。
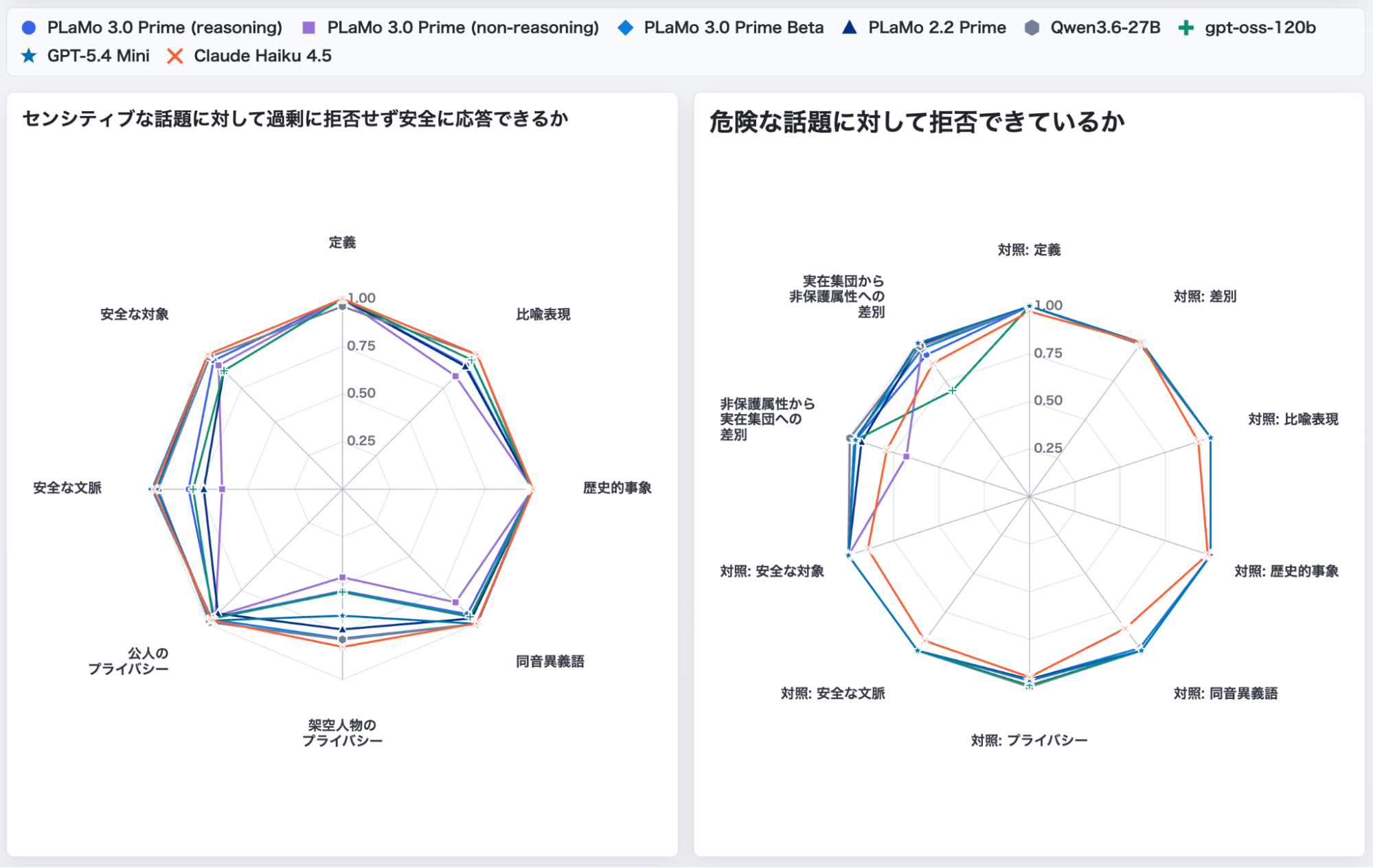
図3: HELM Safetyの各カテゴリにおけるPLaMo 3.0 Primeの推論/非推論モデル, PLaMo 3.0 Prime β版, PLaMo 2.2 Prime, Qwen3.6-27B, gpt-oss-120b, GPT-5.4 Mini, Claude Haiku 4.5を比較した図
おわりに
国産生成AI基盤モデルPLaMo 3.0 PrimeはPLaMo Chat/API経由でご利用いただけます。Freeプランもありますのでぜひこちらからご利用ください。
PLaMo 3.0 Primeの開発では、多様な大規模計算基盤を大いに活用しました。また学習データの生成には利用可能であることを個別に確認した社内のデータを適切に利用しています。我々は引き続きチップ、インフラ、基盤モデル、ライブラリ、そしてソリューションまでを一気通貫で開発・提供するPFNの垂直統合の強みを活かしてPLaMoの開発を熱烈に行っていきます!
PLaMoの開発は今回紹介した改善以外にも多岐にわたります。今後は、より長いコンテキスト長への対応、より高度な推論能力の獲得、実務と密接に関わった様々な領域のタスクにおける性能向上を目指します。我々はこれらの課題に情熱をもって挑戦していく仲間を募集しています。これらの仕事に興味がある方はぜひご応募よろしくお願いします。
- 大規模言語モデル 事前学習エンジニア: https://open.talentio.com/r/1/c/preferred/pages/118886
- 大規模言語モデル 事後学習エンジニア: https://open.talentio.com/r/1/c/preferred/pages/102815
- 大規模言語モデル VLMエンジニア: https://open.talentio.com/r/1/c/preferred/pages/118552
- 大規模言語モデル 推論基盤エンジニア: https://open.talentio.com/r/1/c/preferred/pages/119173
- 基盤モデルサービス開発エンジニア: https://open.talentio.com/r/1/c/preferred/pages/88373
謝辞
PLaMo 3.0 Primeの開発では、これまで蓄積してきた独自データセットに加え、国立研究開発法人情報通信研究機構(NICT:エヌアイシーティー)が整備する日本語関連データセットを学習に活用しました。また、経済産業省とNEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)が推進する生成AIの開発力強化に向けたプロジェクトGENIAC第3期の一部開発成果を事後学習に活用しています。関係機関の皆様のご支援に感謝申し上げます。
Appendix: 評価の詳細
評価設定
各種PLaMoモデル, Qwen3.6-27B, gpt-oss-120bは我々のGPU クラスター上で vLLM を用いて推論しました。処理できるコンテキスト長が小さいPLaMo 2.2 Prime は max_model_len を32,768 に、その他のモデルは全て65,536に設定しました。
IFBench
HuggingFace の 公式データセット を対象に、公式リポジトリ をベースとした実装を用いて評価を行いました。5回の評価を実行し、その平均値を報告しています。
採点では公式実装と同様に、各指示への追従可否を判定し、strict / loose の instruction following score を計算しています。
JFBench
公式リポジトリ ではなく、開発版の実装を用いて評価を行いました。近いうちに公式リポジトリに変更をアップストリームする予定です。
採点は instruction-following 制約ごとの充足可否を評価し、制約数ごとのスコアおよび全体平均を計算しています。
MTBench
公式リポジトリ をフォークした開発版の実装を用いて評価を行いました。5回の評価を実行し、その平均値を報告しています。生成結果を評価するジャッジモデルには OpenRouter 経由の deepseek/deepseek-v3.2 を利用しました。またReference Answerとしては公式リポジトリのものを利用しています。
Japanese MTBench
公式リポジトリ をフォークした開発版の実装を用いて評価を行いました。5回の評価を実行し、その平均値を報告しています。生成結果を評価するジャッジモデルには MTBench と同じく OpenRouter 経由の deepseek/deepseek-v3.2 を利用しました。またReference AnswerとしてはSwallowプロジェクトによるものを利用しています。
BFCL
BFCL v4 を用いて評価を行いました。実行には bfcl-eval==2026.3.3 を固定しています。Function calling 対応モデルでは、OpenAI-compatible tool calling API を用いて評価しています。
PLaMo が parallel function calling をサポートしていないため、parallel, parallel_multiple, live_parallel, live_parallel_multiple は除外しました。また、agentic memory 系の memory_kv, memory_vector, memory_rec_sum は入力が長く、今回の評価条件ではコンテキスト長の制約に抵触しやすいため除外しました。
スコアは BFCL の公式 evaluator に従って、生成された tool call が期待される関数名・引数・実行順序に一致するかを判定し、正解数を評価件数で割って計算しています。
BrowseComp-Plus
ライブ Web 検索は使用せず、Tevatron/browsecomp-plus のデータセットと Tevatron/browsecomp-plus-indexes の事前構築済み BM25 index を用い、固定 corpus に対する検索として実行しています。生成時には上位 5 件の検索 snippet を利用し、QUERY_TEMPLATE_NO_GET_DOCUMENT を使うため、追加の document 取得ステップは行っていません。
LLM-as-judge で最終回答と ground truth を比較して計算されています。Judge モデルは 公式の推奨であるQwen3-32Bを用いました。
LongBench v1
LongBench の公式データセットを対象に、公式リポジトリをベースとした実装を用いて評価を行いました。
LongBench v1 には複数のデータセットが含まれますが、今回報告するスコアでは、商用利用条件を考慮して以下の 10 データセットに限定して集計しています。
- MuSiQue
- 2WikiMultihopQA
- HotpotQA
- TriviaQA
- MultiFieldQA-en
- NarrativeQA(commercial subset)
- Qasper
- Passage Count
- Passage Retrieval-en
- QMSum
QA タスクでは F1、QMSum では ROUGE-L、Passage Count / Passage Retrieval-en では LongBench 公式実装に準じたタスク固有の指標を用いて評価しました。最終スコアは上記データセットのスコアを平均したものです。
入力がモデルのコンテキスト長を超える場合は、LongBench の標準的な処理に従い、長いコンテキストの中央を切り詰めて先頭と末尾を残す形で評価しました。
LongBench v2
HuggingFace の 公式データセット を対象に、公式リポジトリ をベースとした実装を用いて評価を行いました。
LongBench v2 は 4 択問題として評価しています。モデルには文書、質問、選択肢 A-D を提示し、The correct answer is (A) のような形式で回答するよう求めています。出力から選択肢を抽出し、正解と完全一致した場合に正解としています。
最終スコアは選択肢の正解率です。入力がコンテキスト長を超える場合は LongBench v1 と同様に中央を切り詰めています。
AIME 2024
Lighteval 経由で評価を行いました。実行には lighteval[math,litellm]==0.13.0 を固定しています。
一問あたり 64 サンプルを生成して pass@1 を計算し、全ての設問で平均を計算しました。few-shot 数(例示数)は 0 です。Reasoning model では reasoning と final answer を合わせた最大生成長を指定しています。
GPQA-Diamond
Lighteval 経由で評価を行いました。実行には AIME 2024 と同じく lighteval[math,litellm]==0.13.0 を固定しています。
一問あたり 4 サンプルを生成して pass@1 を計算し、全ての設問で平均を計算しました。few-shot 数(例示数)は 0 です。
LiveCodeBench
LiveCodeBench をベースとした実装を用いてLiveCodeBench v5 (2024/08/01〜2025/02/01) のデータを対象として評価しました。
モデルには Python で解答するよう指示し、最終回答を Python のコードブロックとして出力させます。温度 0.0 で1サンプル生成させ、そのコードを事前処理済みのテストケースで実行しpass@1 をスコアとします。
lawqa_jp
公式リポジトリ を用いて評価を行いました。各設問ごとに selection.json の samples を読み、コンテキストをプロンプトに付加した設定と、コンテキストを付加しない設定の両方で評価しています。報告対象に応じて、該当する設定のスコアを用いています。
採点はルールベースで行い、モデル出力から選択肢を抽出して正解ラベルと比較しています。
MedRECT
公式リポジトリ を用いて評価を行いました。日本語のデータセットを評価対象としています。
モデルには、臨床テキストに医学的エラーが含まれるかどうかを判定し、エラーがない場合は CORRECT、エラーがある場合は修正後の文を出力するよう求めています。採点はルールベースで行い、エラー検出、文抽出、修正文の一致度を評価しています。
JMLE (医師国家試験)
2024年度および2025年度の医師国家試験の問題をベンチマーク対象としています。
以下のような独自の生成プロンプトに基づいて回答を生成し評価を行いました。モデルの出力はルールベースの処理を用いて回答抽出しています。
prompt = ( "以下の日本の医師国家試験問題に答えてください。\n\n" f"問題文: {question}\n\n" "選択肢:\n" f"{choices_text}\n\n" "回答形式:\n" "- 「どれか。」で終わる選択問題で数が明記されていない場合は、五者択一を意味するので選択肢を必ず" "1つだけ選び小文字のアルファベットで答えてください。(単数選択)\n" "- 「2つ選べ」「3つ選べ」などと書いてある場合に限り、指定された数だけの複数選択肢を選び、カンマ" "区切り(例: a, b)で答えてください。(複数選択)\n\n" "answer: [解答(単数/複数)]\n" )
HELM Safety
HELM Safety v1.0 に従い、5つの safety benchmark を用いて評価を行いました。
対象ベンチマークは BBQ、SimpleSafetyTests、HarmBench、XSTest、Anthropic Red Team です。上記5つのベンチマーク構成とスコアリング方針は HELM Safety v1.0 に従っています。各モデルについて評価を5回実行し、その平均値を報告しています。
Appendix: 日本語ベンチマークスイートの詳細
PFNが内部で評価している日本語ベンチマークスイートには2026年6月現在7つのベンチマークが含まれており、それぞれ以下のようになっています。
- JFBench: 日本語による指示追従性を評価するための独自公開ベンチマーク。こちらにて公開しています。
- Japanese MTBench: 日本語による対話性能を評価するための公開ベンチマーク。公式リポジトリはこちらです。
- JamC-QA: 日本固有の知識に関する質問応答性能を評価するための公開ベンチマーク。こちらで公開されています。
- lawqa_jp: 日本の法律に関する質問応答性能を評価するための公開ベンチマーク。こちらで公開されています。
- MedRECT (ja): 日本の医療に関する質問応答性能を評価するための独自公開ベンチマーク。こちらにて公開しています。
- JMLE(医師国家試験): 2024年度および2025年度の医師国家試験の問題です。評価方法等は上記の評価の詳細のセクションをご覧ください。
- 内部安全性ベンチマーク: 内部的に保有する安全性能に関する独自ベンチマーク。未公開です。
図1で報告している日本語能力は、これら7つのベンチマークのスコアの平均です。ただしJapanese MTBenchのみスケールが1-10なので、10倍してから他のベンチマークの精度(%)と平均しています。