Blog
本記事は、2023年夏季インターンシッププログラムで勤務された竹田悠哉さんによる寄稿です。
はじめに
2023年度のPFN夏季インターンに参加した、東京大学大学院工学系研究科の竹田悠哉と申します。学部では画像生成の研究をしていましたが、技術の社会実装をより俯瞰的に学びたいと思い、現在は技術経営戦略学専攻で教育工学の研究をしています。
インターンでは「機械学習技術の社会実装」をテーマに、LLM(Large Language Model)にドメイン知識を習得させることに取り組みました。様々な設定において、主に英語で学習されたモデルであるLLaMA2に対して日本語のデータでのFine-tuningを行い、LoRAやInstruction Tuning、ドメイン知識の習得に関する知見を得ることができたと思います。本記事では、そこで利用した技術の紹介と、日本語におけるドメイン知識の習得に関する実験、及び、得られた結果に対する最新研究を踏まえた考察を述べていきます。
背景
LLMの社会実装と言うと、ChatGPTを中心として日進月歩の勢いに見えますが、APIで提供されているテキスト生成や、LangChain、LlamaIndexといったライブラリを利用したものに留まり、LLMの重み自体に手を加えることは多くありません。インターン期間中の8月には、gpt-3.5-turboのFine-tuningがサポートされましたが、学習方法についてはブラックボックスであり、出力形式ではなく知識を学習させるのは難しいという声もあります。LLMの現況として、事前学習データに含まれない知識を扱う際に多くの困難があり、特定の知識を新たに習得させるためのベストプラクティスは十分に得られていません。さらに、知識は常に変化し続けるため、LLMの応用形態によっては、それに追随してモデルを改良し続ける必要もあります。
加えて、LLMに関する研究は指数関数的に増加しており[1] 、毎日のように新たな論文が発表されている一方で、研究としてのインパクトを重視すると英語をメインとした内容にならざるを得ず、日本語を扱う際の知見があまり得られていないというのが現状です。
今回のインターンでは、産業応用における日本語の知見を溜めることを目的として業務を進めました。その中で得られた結果の一部として、Fine-tuningでLLMに知識を学習させることに関するサーベイと検証を技術ブログとして公開したいと思います。
前提知識
事前学習データにはない特定の知識を活用する手法としては、再学習、Retrieval-based LM、外部ツールの利用が挙げられます。現状のRetrieval-based LMを実際に使用してみて、検索だけで十分な特定の知識の活用を行うのは難しいシチュエーションもあるとの思いから、再学習によるものに焦点を当ててプロジェクトを進めました。なお、再学習の利点としては、プログラミング言語のようなRetrieverだけでは扱いにくい知識の活用についても向上が見込まれることが考えられます。
LLMの学習には、主に、以下の図中のTrainingに列挙したような分類があります。先ほど再学習と表現したのはfull scratch以外の学習についてです。またここに挙げていないものとしては、Retreival-based LMとの重複もありますが、ルールベースや探索などでプロンプトを工夫してIn-context Learningを利用するといったことも考えられます(In-context LearningではプロンプトによってAttention行列が変化することから重みに対するアプローチではありますが、パラメータを更新するという意味での学習ではありません)。本プロジェクトでは、Fine-tuningの手法の一つであるLoRA[2](Low-Rank Adaptation)に着目して実験を進めました。

① LoRA
LoRAは、メモリや計算量を抑えてFine-tuningを行えることから、モダリティを問わず、生成モデルの学習でよく用いられています。動作機序は極めて単純で、Fine-tuningにおける一連の学習で更新される重み行列の増分を\(\Delta W\)とおいたときに、低ランク行列\(A\)、\(B\)による\(\Delta W=BA\)という分解を考え、これらの行列を更新することで、モデルの全パラメータに対するfull Fine-tuneに比べて低コストでの計算が可能になるという手法です。
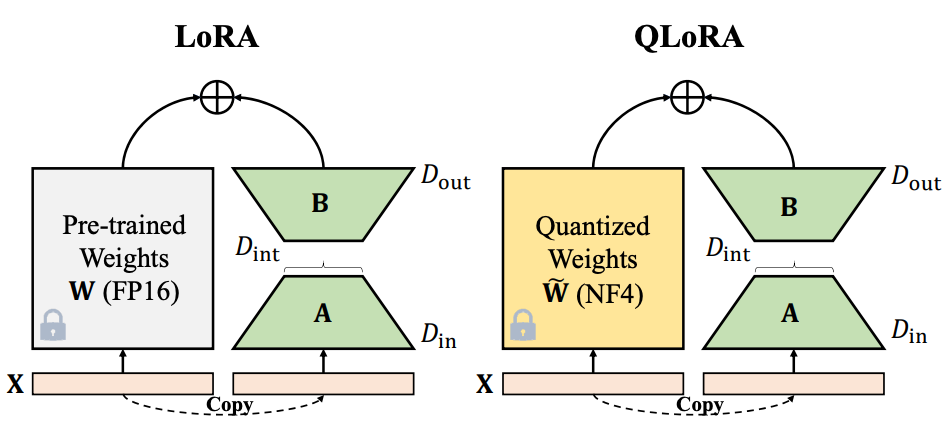 (QA-LoRA論文 [6, Figure2] より、抜粋)
(QA-LoRA論文 [6, Figure2] より、抜粋)
このような手法で学習が可能な理由として、固有次元(Intrinsic Dimension)を用いた分析があります[3]。
目的関数の固有次元は、それぞれの目的に対して満足のいく解に到達するために必要な最小のパラメータ数を測定することができ、ヒューリスティックに上限値を計算することで求められます。Fine-tuningの固有次元は、D個のパラメータ集合\(\theta^D\)を、部分空間法による低次元dの再パラメータ化によるモデルの学習として、
\[\theta^D = \theta^D_0 + P(\theta^d)\]
と定式化されます。直観的には、小さな空間にランダムの線形射影を行い、小さな部分空間で最適化問題を解き、満足のいく解が得られたときにその部分空間の次元を固有次元と呼んでいると言えます。
論文[3]では、Attentionベースのモデルにおける階層性を考慮することでメモリを削減したSAID(Structure Aware Intrinsic Dimension)法と呼ばれる以下の定式化により、固有次元が計算されています。
\[\theta^D_i = \theta^D_{0,i} + \lambda_i P(\theta^{d-m})_i\]
また、再パラメータ化Pの計算には、ランダムな線形密射影(\(\theta^d W\))、ランダムな線形疎射影(\(\theta^d W_{sparse}\))、Fastfood変換によるランダムな線形射影(\(\theta^d M \text{ where } M=HG\Pi HB\))などがあり、実験ではFastfood変換による計算が採用されています。\(M\)の因数分解は、Hadamard行列\(H\)、独立した正規分布に従うランダムな対角行列\(G\)、等しい確率で±1の値を持つランダムな対角行列\(B\)、ランダムな置換行列\(\Pi\)からなり、高速Walsh-Hadamard変換によって\(O(D\log{d})\)で計算できます。
Masked LMではありますがRoBERTa-largeを用いた検証では、例えば、空間全体にランダムに射影された200個の学習可能なパラメータのみを最適化することで、full Fine-tuneの90%の性能を達成できることが示されています。さらに、事前学習が暗黙のうちに固有次元を最小化すること、そして、より大きなモデルは事前学習の更新回数が一定になった後に固有次元が低くなる傾向があることも実証されており、完全なパラメータ空間と同様にFine-tuningに有効な低次元の再パラメータ化の存在が示されています。
まとめると、LoRAは、[3]で言われている、事前学習モデルは大量のパラメータ数にもかかわらず低い固有次元を持ち、Fine-tuningに有効な低次元のパラメータ化も存在する、という主張にインスパイアされ、\(\Delta W\)における重みの更新の固有次元も低いという仮説のもとで、低ランク行列で学習する手法になります。
② QLoRA
また、LoRAにおいて量子化により更なる軽量化を実現した手法としてQLoRA[4]があります。QLoRAでは、事前学習モデルの重みに対する4bit NormalFloatという、正規分布に基づく量子化が提案されており、下式のような計算で変換されています。
\[q_i = \frac1 2 (Q_X(\frac{i} {2^k+1}) + Q_X(\frac{i+1} {2^k+1}))\]
(\(Q_X(\cdot)\):標準正規分布\(\mathcal{N}(0,1)\)への分位点関数)
4bit NormalFloatによる量子化では、重みは正規分布に従って-8から7の16段階で表現されます。加えて、QLoRAでは、量子化定数に関する量子化である二重量子化やメモリスパイクを管理するページ最適化なども導入されています。
こうしたニューラルネットワークを圧縮する他の技術には枝刈りや知識蒸留がありますが、量子化は、ほとんどの場合に枝刈りより優れているとされ[5]、蒸留よりも手軽に高精度なモデルが得られる可能性が高く、LLMにおいても有力な技術と考えられます。実際、QLoRAにおいてAの大きさ(入力の次元)を適応的に定めるQA-LoRA[6] などの派生が提案されているように、今後さらに研究が進むことが期待されます。
QLoRA以外のLoRAの派生手法としては、ランクを適応的に定めるAdaLoRA[7] やDyLoRA[8]、コンテキスト長を拡大できるLongLoRA[9]、行列Aの重みをfreezeすることでさらに軽量化を行うLoRA-FA、行列積をアダマール積やクロネッカー積で計算するLoHAやLoKRなどがあります(一部はLLMではなくStable Diffusionの学習で用いられる手法の通称です)。
他にも、PEFT[10](Parameter Efficient Fine-Tuning)と呼ばれる軽量のFine-tuning手法は存在しますが、精度の面で見劣りするため手法はLoRAに絞りました。
学習手法について
① Instruction Tuning[11, 12]
言語モデルの学習は通常、Causal LMの場合は、Next Token PredictionにおけるPerplexityの最小化による教師なし学習によって最適化されます。Fine-tuningにおいても同様に学習が可能ですが、ユーザの意図に従った動作をするよう学習させる方法として、Instruction Tuningという教師ありのFine-tuning(SFT;Supervised Fine-tuning)があります。Instruction Tuningでは、Instructionとそれに対するOutputを学習(任意でInputも与えることができます)することで、対話応答やコード生成などの能力を向上させることが可能です。学習は、それらをセットにしたInstructionデータによって行います。本実験で用いたInstructionデータは、JAQKETという後述のデータセットにおけるクイズのQAを整形して作成しました。
但し、JAQKETのtrainデータに含まれる選択肢は、正解となる選択肢が最初の要素となるリストとして提供されています。そのため、形式的に最初の選択肢を覚えるという学習をしてしまう懸念があり、さらに選択肢の順番やプロンプトでの位置で出力が大きく変わることも報告されている[13] [14] ことから、整形時にメルセンヌ・ツイスターによってランダムに入れ替えて学習に使用しました。
② Additional Training
Instruction tuningに対して、本稿では、通常のFine-tuningによる学習をAdditional Trainingと呼ぶことにします。Additional Trainingではクイズの答え(=記事のタイトル)に対応するコーパス(=Wikipediaの記事)を学習させました。以下に「逆鱗」が答えとなるInstructionデータとコーパスの例を示します。

実験と考察
データセット
データセットは、Instructionデータが作成でき、Wikipediaの記事を対応コーパスとして用意できる日本語のデータとして、JAQKET[15]を利用しました。JAQKETは日本語のWikipediaから作られ、記事のタイトルが答えとなるような20択のクイズになっています。今回の実験で使用した、trainデータには13061組、dev1には995組のQAが含まれます。
ここで、本来ドメイン知識は医療や法律といった特定のドメインに関する知識のことですが、実験設定を考慮し、事前学習データに含まれていないであろう日本語における知識を指すこととします。具体的には、日本語Wikipediaにおける知識であり、日本の有名人や文化といったものをドメイン知識として扱いました。そのため、一部の知識は英語として含まれている可能性があり、厳密には翻訳能力を差し引いて考える必要がありますが、応用上は新たに与えたデータを知識として適切に獲得できるかに興味があるため、今回は、他言語で持っている可能性のある知識は新たな知識と想定しています。
日本語における知識の習得という観点から、学習用データ(=クイズ)に対する正解率をスコアとして用いました。そのため、検証用データは、学習による日本語能力や対話応答能力の向上を見るために使用しています(興味深いことに、英語のInstruction Tuningによって翻訳能力が向上したという報告もあります[16])。
また、学習率をcosineスケジューラによって減衰させていることから、学習させるデータの順番によって学習率が異なることで、知識の習得具合に影響する可能性がありますが、最初に学習させた500件、ランダムに抽出した500件、最後に学習させた500件それぞれで検証した場合に有意な差は見られなかったことから、今回の学習設定では問題そのものによる違いを小さくするために、学習させるデータ数によらず同一の問題を利用できる最初に学習させた500件で検証を行いました。
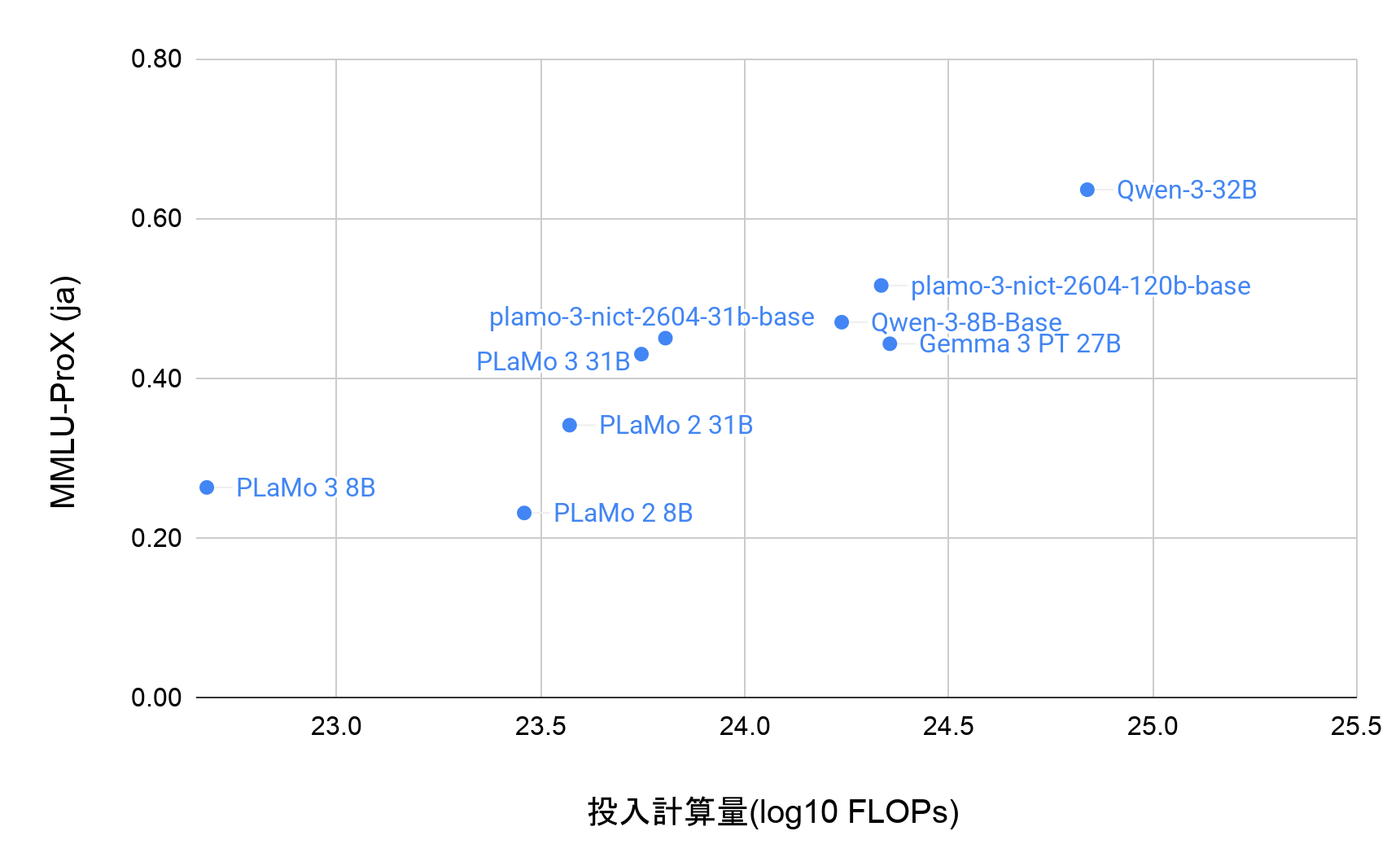
実験1:Instruction Tuningにおけるモデルサイズ、データ数、LoRAランクの調整
はじめに、予備実験として、LLaMA2-7B-chat、LLaMA2-13B-chatにおいてLoRAのランクの大きさやデータ数を変えながらQLoRAによるInstruction Tuningを行いました。
7Bのモデルでは、以下のグラフのように、データの件数を増やすと学習がうまくいかないという結果が得られました。また、LoRAのランクは低い方が学習が安定することがわかりました。
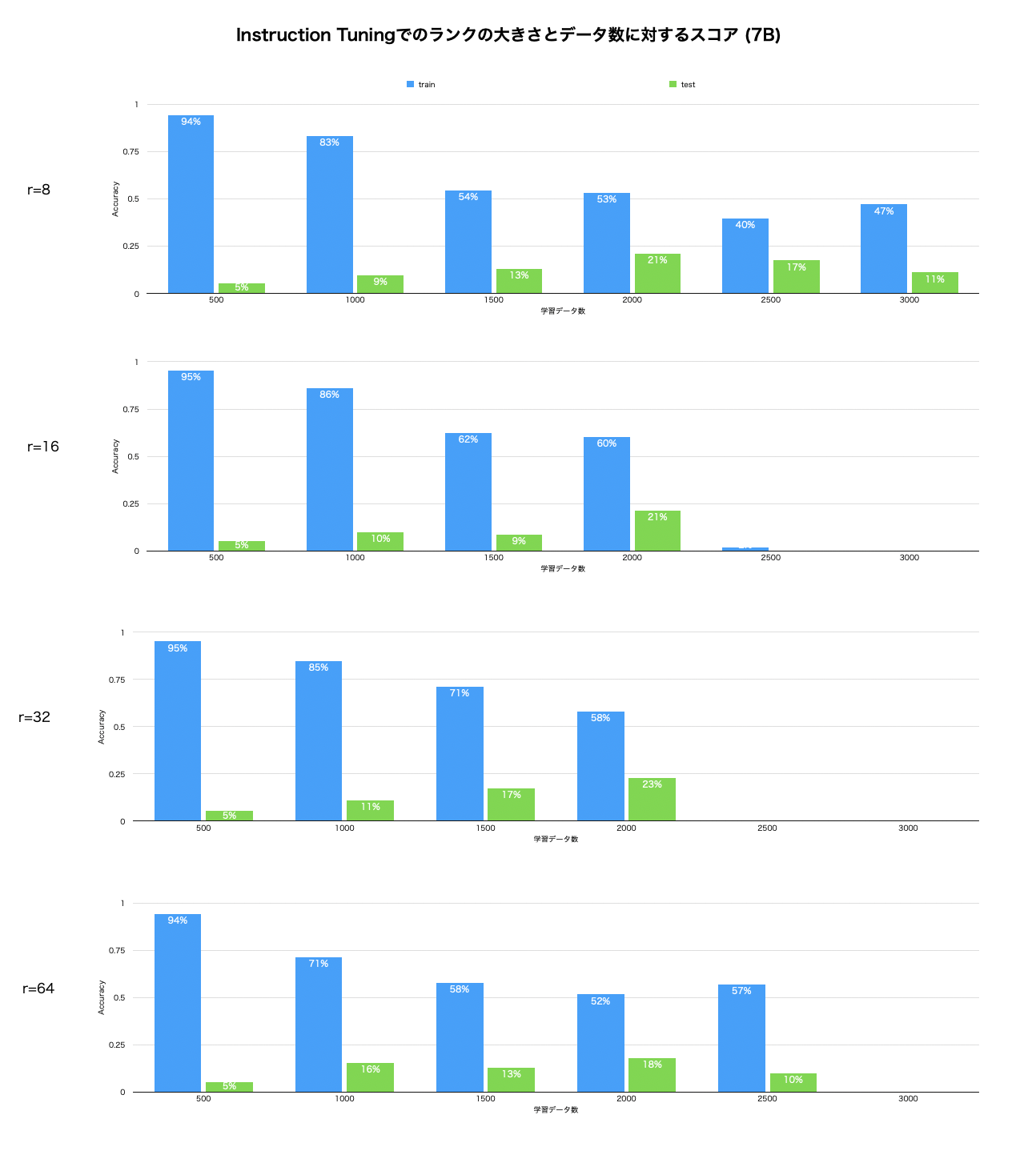 正答率が著しく低いものは、学習時のロス(交差エントロピー)が非常に大きくなっており、選択肢を間違えるというよりは言語モデルとしての機能が失われていました。
正答率が著しく低いものは、学習時のロス(交差エントロピー)が非常に大きくなっており、選択肢を間違えるというよりは言語モデルとしての機能が失われていました。
他には、Instructionデータ(1つのクイズのQ&A)が2500件を超えるとロスが悪化することや、2000件でも2epoch繰り返すとcatastrophic forgettingが見られ、言語モデルそのものの性能が失われ意味のない出力をしていました。
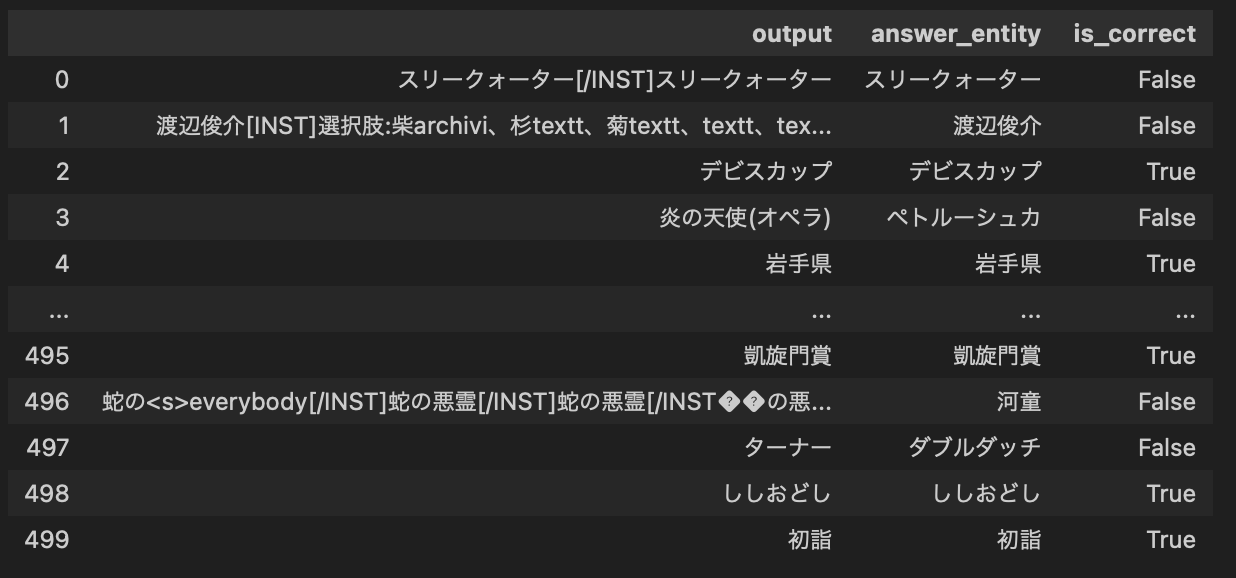 (2500件のInstruction Tuningでの出力例)
(2500件のInstruction Tuningでの出力例)
[17] でも言及されていますが、日本語の学習では、数BのモデルにおけるLoRAによるInstruction Tuningはあまり効果が得られない可能性が高いと考えられます。
一方、13Bのモデルでは、8、16、32、64いずれのランクでも大きな差は見られませんでした。
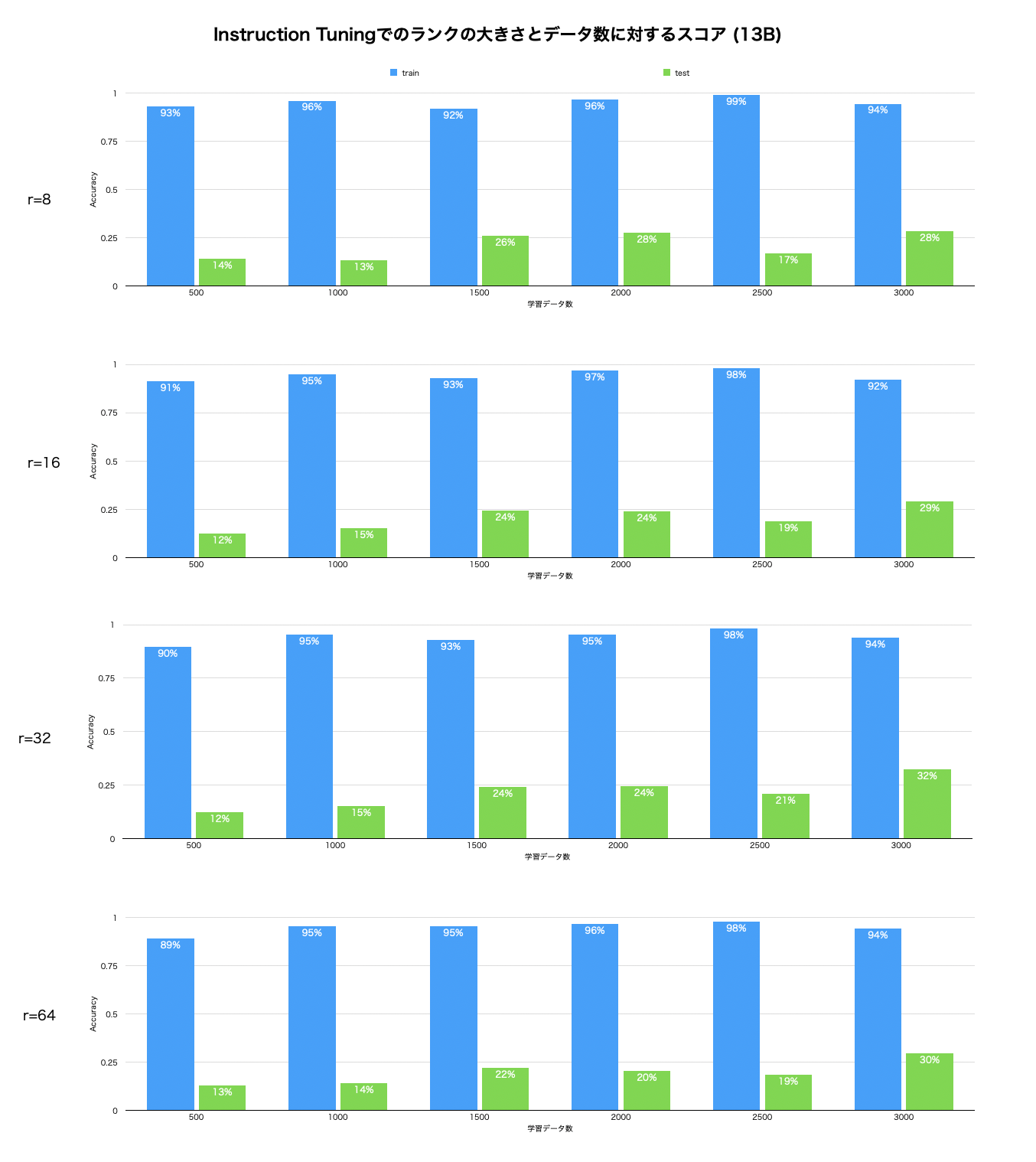
この理由として、7Bに対して層やノードの数が多く、ΔWに対して相対的にパラメータ数が多いため、元の分布からの差分が小さかったからと考えることができそうですが、それだけでは7Bのモデルでのランク8に対して13Bのモデルではランク64でも安定しているため、説明としてはやや弱そうです。ランクを大きくした場合、すなわち、full Fine-tuneに近い学習の場合に、より不安定になっていることと合わせても、10B前後のLLMにおいて、部分空間での最適化における不連続な変化が起きている可能性が考えられます。
しかし、full Fine-tuneよりもパラメータ数が少ないLoRAの方が最適化は難しいはずですが、低ランクでの学習の方が安定することは、計算コスト、特にメモリ量の制限が厳しいLLMの学習においては嬉しい知見と言えそうです。
以上を踏まえて、これ以降の実験では、LoRAのランクは8とし、Instruction Tuningの際は7Bのモデルは2000件、13Bのモデルは13061件のデータを用いました。Additional Trainingでは全てを学習させても大きなロスの増加などは見られなかったことから、学習データ数は7Bと13Bのいずれのモデルでも同数としました。
実験2:各学習手法における知識の蓄積に関連するモジュール
次に、先行研究で述べられている、知識は全結合層に蓄積されるという点について調査しました。LLaMA2のTransformerは以下のようなブロック図で表現できます。ここで、全てのモジュールの重みを学習対象にしたときに対して、Attention層(Q、K、V)を除いた場合と全結合層(Linear Layer、up projection、down projection、gate projection)を除いた場合の比較を行いました。
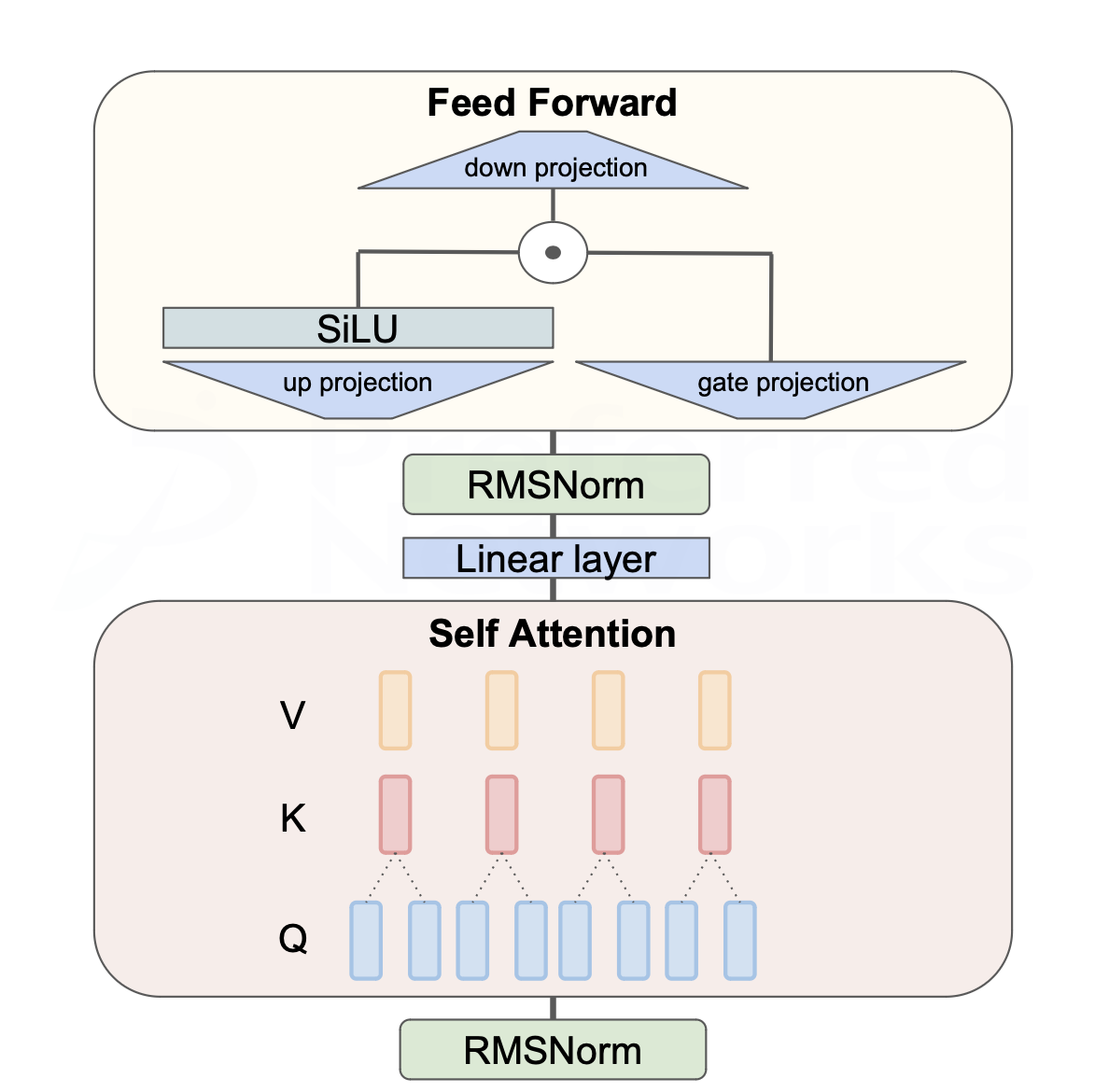
13BのモデルでAdditional Trainingをした場合とInstruction Tuningをした場合について下図に示します。
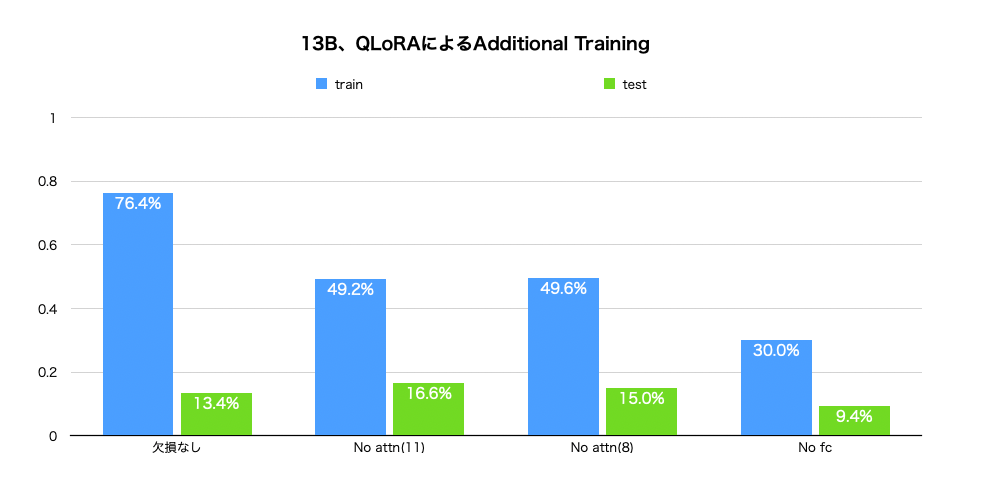
Additional Trainingでは、全結合層を更新しなかった場合のスコアが悪くなっており、先行研究での主張が概ね再現されたと考えられます。また、Attn(11)とあるのは、全結合層に対してAttention層のパラメータ数が少ないため、LoRAのランクを11にすることで擬似的にパラメータ数を揃えて比較するために行った実験です。しかし、あまり変化がなかったことから、パラメータ数の違いによる影響は相対的に小さい可能性や、LoRAによるパラメータ数の調整が原理的にうまく機能していないとしてもLoRAが低い固有次元の学習ということは支持されそうです。
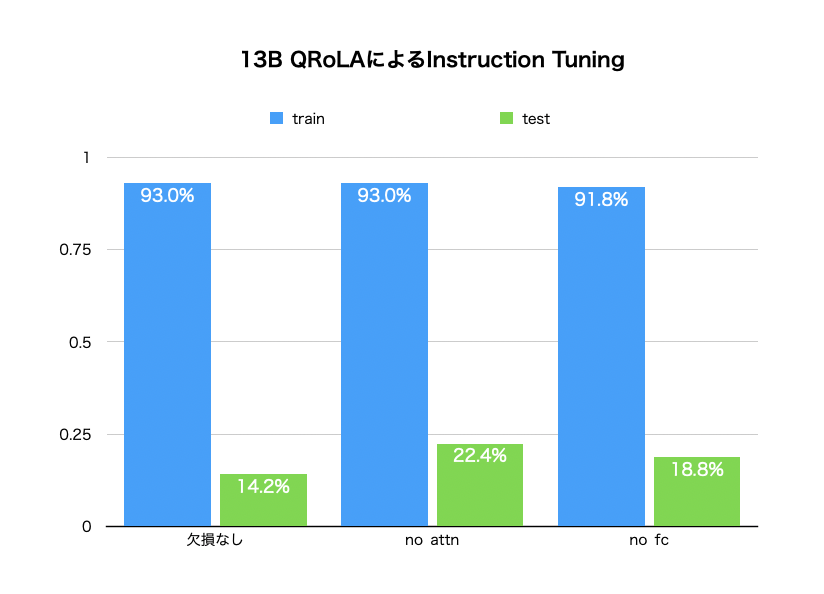
一方、Instruction Tuningでは、欠損によらずほとんど結果に変化が見られませんでした。
実験3:Instruction TuningとAdditional Trainingの順序等について
言語モデルを学習する際、人間の学習のアナロジーから、簡単な文章から始めて難しい文章を学習させる方が効率よく学習できるように思えます。LLMの学習に関する定説はないですが、こうした、モデルを学習するときにデータをどの順番で与えるべきかについては、カリキュラム学習[18]として長く研究されています。LLMにおけるカリキュラム学習の話題では事前学習に関するものが多いと思いますが、Instruction TuningとAddtional Trainingの順番や割合についても重要と考えられます。卑近な例で言えば、一問一答で覚えた知識をもとに記述式にも答えられるか、教科書を読んだだけで問題集を解けるかについての観点と捉えることができそうです。
そこで最後に、知識の習得をFine-tuningで実現したい場合に、LLaMA2-7b-chatを用いてInstruction TuningとAddtional Trainingの順番や割合をどのようにすべきかについての検証を行いました。
はじめに、Instruction TuningとAdditional Trainingの順番と、Instruction Tuningで学習した知識はその後Additional Trainingをしていったときにどうなるかを調べるために、以下の6パターンでスコアの比較をしました。
1-1:Instruction Tuning 500件→Additional Training 500件
1-2:Additional Training 500件→Instruction Tuning 500件
2-1:Instruction Tuning 500件、Additional Training 5000件
2-2:Additional Training 5000件→Instruction Tuning 500件
3-1:Instruction Tuning 500件、Additional Training 10000件
3-2:Additional Training 10000件→Instruction Tuning 500件
結果は以下のグラフのようになり、1-1、1-2で同数のデータを学習させる場合はInstruction Tuningが先の方がスコアが高いですが、2-1、2-2と3-1、3-2はともに、先にAdditional Trainingをした場合の方が、そうでない場合のスコアを上回っていました。
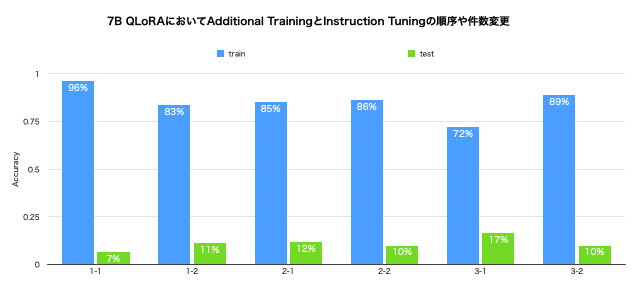
また、1-1、2-1、3-1から、Instruction TuningのAdditional Trainingは件数が増えるに従ってスコアが悪化していました。
これらから、Addtional Trainingで学習させるデータがInstruction Tuningに対して膨大である場合には先に学習した方がよく、少数の場合は後に学習させてもInstruction Tuningの効果には悪影響がないということが示唆されました。
次に、Additional Trainingの後にInstruction Tuningをする場合に、Instruction Tuningで学習させる事柄に関してAdditional Trainingで先に学習させる方が良いかの検証をしました。4-2のみ、Additional TrainingとInstruction Tuningで、評価に用いるデータ500件を重複させて学習させました。
2-2:Additional Training 5000件→Instruction Tuning 500件
4-1:Additional Training 5000件→Instruction Tuning 1000件
4-2:Additional Training 5000件→Instruction Tuning 1000件(重複あり)
結果は以下のグラフのようであり、2-2と4-1を比べると、Instruction Tuningの件数が多い方がスコアが高いという予想通りの結果が得られましたが、一方で、Instruction Tuningをするデータを事前にコーパスで学習していた方が良いかについては、学習していない4-1の方が僅かながらスコアが高くなりました。
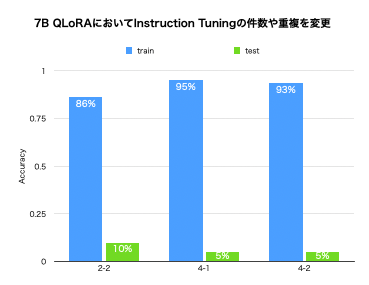
これらから、Instruction Tuningは一定の件数までは繰り返すことで性能の向上が見込まれることと、Instruction前のAdditional Trainingはデータよりもトークン数が重要であることが考えられます。
議論
実験1で見られた、日本語のInstruction Tuningで件数が増えるとロスが急激に上がりやすい点や、LoRAのランクが小さい方が学習が安定する点は、言語モデルのエルゴード性を仮定したときに、英語の検索エンジンのクエリやソーシャルサイトのように、英語のWebデータが元から質問応答をある程度含んでおり、日本語でInstruction Tuningをする場合よりも分布が離れていない可能性が考えられます。
また学習は、初期学習率を小さくした方が安定する可能性が高いと思われます。LoRAの論文[2] ではGPTのFine-tuneは2e-4で行われており、hugging faceの実装でもデフォルトでは2e-4となっていますが、他の論文やブログでは3e-5での例などもあります。しかし、単に下げれば安定するということでもなく、1回の試行における計算コストとチューニングがトレードオフになる可能性はあります。
実験2では、13BモデルのInstructon Tuningにおいては更新する層がスコアに影響を与えないという結果が得られましたが、7BモデルのInstruction TuningではAttention層、特にValueの重みを更新しない場合にスコアが悪くなる可能性が見られました。これについては更なる調査が必要ですが、Instruction Tuningでは知識だけでなく、形式や構造といったプロンプトに対する応答の仕方も学習する必要があり、Attentionの相対的な重要性が増している可能性が考えられます。LoRAやQLoRA特有の現象である可能性や、日本語や多言語を学習させる場合に起こりうる点など、様々な要因を考慮した詳細な実験が必要ですが、包括的な検証により学習データやタスクに対するモジュールレベルでの重要性が明らかになれば、それに応じた重みのみ更新することや、各モジュールで適切な学習率をそれぞれ設定することなどにより、効率的なFine-tuningの実現が期待されます。
また、知識は変容するものであり、較正[19]や忘却[20]による更新が良いのか、適当なCheckpointから新たに学習させる方が好ましいかなど知識に関連して研究すべき点は多くあります。
加えて、本稿では触れませんでしたが、日本語対応の事前学習モデルとしてPLaMo-13BやJapanese StableLM Base Alpha 7Bで同様の実験をした際には、Instruction Tuningにおいて同じ設定ではLLaMA2ほどのスコアは出ませんでしたし、その他の挙動も大きく異なりました。そのため、日本語対応のベースモデルをFine-tuningする場合は、epoch数や学習率、LoRAのランクやデータ数などについての新たな検証が必要であると考えられます。学習データの件数が少ない場合に、日本語をほとんど学習していないLLaMA2のようなモデルの方がスコアが良い可能性がある点についても詳細な調査が望まれます。定性的には、日本語LLMをベースとした場合は、『高瀬舟』と『舞姫』を間違うような惜しい不正解の仕方をしており、知識を混同してしまっている可能性があります。一方で、未知のデータに対する正解率の高さから、プロンプトに対する尤度で出力が決定するため消去法のような絞り込みで特に外れていそうなものをうまく除いている可能性も示唆されました。日本語を新たに習得させようとするときは、純粋に知識だけを学習するだけでなく形式や新言語への対応といった複雑な事情があるため、検証スキームを構築する難易度は高いでしょうが、こうした事柄も知識の習得を扱う上で重要な視点と思われます。
さらに、質問応答ではRetreiverを組み合わせて使用することが多く、現在Kaggleで開催されているコンペティション[21] でも、そうした手法が用いられています。実運用という点では、RAG[22] などRetreival-based LMの技術と組み合わせる際に適切なFine-tuningといった評価も必要であり、Retreiverを使用する場合に差異があるかも気になるところです。
感想
LLMに対する実験では予想と全く異なる結果が出ることが少なくないため、バグを疑いつつ探求を進めることになり、至難ではありましたが一種のフロンティアを感じられて非常に楽しい期間でした。実験をする中で、言語や指示を変えた複数のプロンプトで比較をするといった検証もしており、その中で学習によっては性能が逆転すると言う現象も見られました。
最後にインターンで得られた学びについて述べます。今回の私の取り組みは、世界でも英語以外の言語で同様のことが試されている可能性は十分にあると思います。例えば、ポルトガル語や韓国語で同様の問題意識をもって取り組まれた方はいるかもしれません。しかし、そういった英語以外の言語での知見を探すのには労力がかかるので、GPUが使える環境なら、実装して試してみる方が、手っ取り早くわかるし、良い知見が得られると感じました。プロジェクトの遂行においては、このような、どこにどれだけの労力をかけて取り組むかのバランス感覚が重要だと実感しました。
恵まれた計算機環境や手厚いメンタリングを受けながらLLMの気になる点を探求させていただき、優秀な社員さんやインターン生に囲まれて広範な科学の研究・開発に触れながら、この上なく貴重で充実した夏季休暇を過ごすことができました。PFN Dayやインターンの中間・最終発表は国際学会に参加してるようでしたし、ランチや飲み会での会話も非常に刺激的でした。ブログでは紹介しきれなかった実験や知見も多くあり、非常に密度の濃いインターンを経験させていただきました。この場をお借りして、インターンに関わった皆様に深く御礼を申し上げたいと思います。ありがとうございました。
Appendix
<Appendix1>Transformerでは全結合層に知識が蓄積される
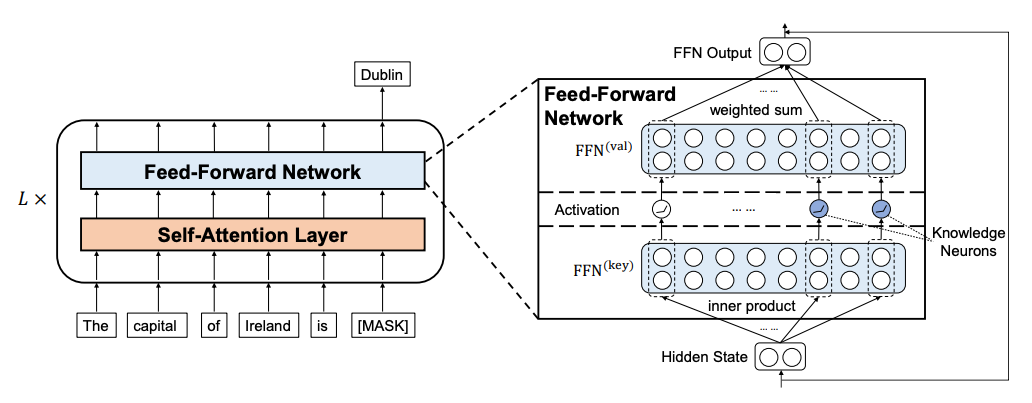
先行研究では、Transformerベースの言語モデルでは、知識は全結合層に蓄積されることが示唆されています[23, 24]。[23]では下図のように全結合層に知識ニューロンの存在を主張しています。[25]では全結合層に知識が蓄積されるという前提に立って知識注入の手法を提案をしています。また、[19]においても誤った事実知識を修正するために、全結合層に対する追加のパラメータを学習しています。
<Appendix2>LLaMA2
実験で使用するモデルはLLaMA2[26]を採用しました。LLaMA2は商用利用可能なオープンソースのモデルとして公開されており、そうしたモデルの中でトップクラスの性能を示しています。LLaMA2の事前学習データには日本語が0.1%程度しか含まれていないとされますが、LLMとして優れた動作が期待され、尚且つオープンソースの大本命として今後は標準規格となり得ることから、日本語の学習済みモデルではなくこちらを利用しました。
モデルは、パラメータ数が7B、13B、30B、70Bの4種類存在していますが、30Bは公開されておらず、現在(2023年9月26日時点)は7B、13B、70Bと、それらを対話向けにFine-tuningした7B-Chat、13B-Chat、70B-Chatの6モデルが利用可能です。Fine-tuningは、InstructGPT同様、Instruction TuningとRLHFによって行われており、そこで得られた知見として、複数ターンにわたる対話の流れを制御するためのGAtt(Ghost Attention)も提案されています。論文では安全性の詳細な検証やデータの品質の重要性についても述べられてます(Alignmentは主にRLHF寄りの議論になります)。LLaMA2はオープンソースであることから有志による開発も盛んであり、C言語での実装や量子化による軽量モデル、様々なFine-tuning済みモデルも公開されています。
参考文献
[1] Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., … & Wen, J. R. (2023). A survey of large language models. arXiv preprint arXiv:2303.18223.
[2] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. (2022). Lora: Low-rank adaptation of large language models. in The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net.
[3] Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. (2021). Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7319–7328, Online. Association for Computational Linguistics.
[4] Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). Qlora: Efficient finetuning of quantized llms. arXiv preprint arXiv:2305.14314.
[5] Kuzmin, A., Nagel, M., van Baalen, M., Behboodi, A., & Blankevoort, T. (2023). Pruning vs Quantization: Which is Better?. arXiv preprint arXiv:2307.02973.
[6] Yuhui Xu Lingxi Xie Xiaotao Gu Xin Chen Heng Chang Hengheng Zhang Zhensu Chen Xiaopeng Zhang Qi Tian (2023). QA-LoRA: QUANTIZATION-AWARE LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS.
[7] Qingru Zhang and Minshuo Chen and Alexander Bukharin and Pengcheng He and Yu Cheng and Weizhu Chen and Tuo Zhao (2023) Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning. The Eleventh International Conference on Learning Representations.
[8] M. Valipour, M. Rezagholizadeh, I. Kobyzev, and A. Ghodsi. (2022). Dylora: Parameter efficient tuning of pre-trained models using dynamic search-free lowrank adaptation. CoRR, vol. abs/2210.07558.
[9] Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, Jiaya Jia. (2023). LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models. arXiv:2309.12307.
[10] S. Mangrulkar, S. Gugger, L. Debut, Y. Belkada, and S. Pau. (2022)., Peft: State-of-the-art parameter-efficient finetuning methods.
[11] Scheurer, J., Campos, J. A., Chan, J. S., Chen, A., Cho, K., & Perez, E. (2022). Training language models with natural language feedback. arXiv preprint arXiv:2204.14146, 8.
[12] Zhang, S., Dong, L., Li, X., Zhang, S., Sun, X., Wang, S., … & Wang, G. (2023). Instruction tuning for large language models: A survey. arXiv preprint arXiv:2308.10792.
[13] Pezeshkpour, P., & Hruschka, E. (2023). Large language models sensitivity to the order of options in multiple-choice questions. arXiv preprint arXiv:2308.11483.
[14] Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2023). Lost in the middle: How language models use long contexts. arXiv preprint arXiv:2307.03172.
[15] 鈴木正敏, 鈴木潤, 松田耕史, 西田京介, & 井之上直也. (2020). JAQKET: クイズを題材にした日本語 QAデータセットの構築. 言語処理学会第 26 回年次大会, 237-240.
[16] N. Muennighoff, T. Wang, L. Sutawika, A. Roberts,S. Biderman, T. L. Scao, M. S. Bari, S. Shen, Z. X. Yong H. Schoelkopf, X. Tang, D. Radev, A. F. Aji, K. Almubarak, S. Albanie, Z. Alyafeai, A. Webson, E. Raff, and C. Raffel. (2022). Crosslingual generalization through multitask finetuning. CoRR, vol. abs/2211.01786, 2022.
[17] 王昊, 中町礼文, 佐藤敏紀. (2023). 日本語の大規模な基盤モデルに対する LoRA チューニング. 言語処理学会第 29 回年次大会, 2222-2226.
[18] Soviany, P., Ionescu, R. T., Rota, P., & Sebe, N. (2022). Curriculum learning: A survey. International Journal of Computer Vision, 130(6), 1526-1565.
[19] Qingxiu Dong, Damai Dai, Yifan Song, Jingjing Xu, Zhifang Sui, and Lei Li. (2022). Calibrating Factual Knowledge in Pretrained Language Models. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 5937–5947, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
[20] Wang, Zhenyi & Yang, Enneng & Shen, Li & Huang, Heng. (2023). A Comprehensive Survey of Forgetting in Deep Learning Beyond Continual Learning.
[21] Kaggle | Competitions | kaggle-llm-science-exam https://www.kaggle.com/competitions/kaggle-llm-science-exam (最終閲覧: 2023年9月29日)
[22] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems. Curran Associates Inc., Red Hook, NY, USA, Article 793, 9459–9474.
[23] Dai, D., Dong, L., Hao, Y., Sui, Z., Chang, B., & Wei, F. (2021). Knowledge neurons in pretrained transformers. arXiv preprint arXiv:2104.08696.
[24] Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. (2021). Transformer Feed-Forward Layers Are Key-Value Memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
[25] Yao, Y., Huang, S., Dong, L., Wei, F., Chen, H., Zhang, N. (2022). Kformer: Knowledge Injection in Transformer Feed-Forward Layers. In: Lu, W., Huang, S., Hong, Y., Zhou, X. (eds) Natural Language Processing and Chinese Computing. NLPCC 2022. Lecture Notes in Computer Science(), vol 13551. Springer, Cham.
[26] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models.