Blog
はじめに
Preferred Networks (以下PFN) 子会社のPreferred Elements (以下PFE) は1000億 (100B) パラメータ規模のLLMであるPLaMo-100Bについて、2024年2月から5月にかけて事前学習を実施しました。現在はPLaMo-100Bを元にPLaMo Prime/PLaMo Liteをリリースし、主要日本語ベンチマークで世界最高レベルの精度をAPIやChatサービスとして提供しています。また、PFNとPFEの共同で2024年10月から現在にかけて、より高性能かつ軽量なLLMであるPLaMo 2の開発を行っています。
本記事では、PLaMo-100Bや現在開発中のPLaMo 2の事前学習を支える技術について紹介します。
PLaMo-100B、PLaMo 2の開発は、経済産業省が主導する国内の生成AIの開発力を強化するためのプロジェクト「GENIAC(Generative AI Accelerator Challenge)」のもと、NEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)の助成事業に採択され、計算資源の提供支援を受けて実施しています。
これらについての詳細は以下をご覧ください。
長期事前学習を安定的に行うために
PLaMo-100Bの開発を実施したGENIAC第1期では、Google CloudのA3インスタンスが計算資源として提供されましたが、これまでPFN/PFEのLLM開発は自社クラスタを中心として実施しており、IaaS型クラウドの利用は初めてでした。また、2023年9月に公開したPLaMo-13Bの事前学習は約1ヶ月で実施したのに対し、PLaMo-100Bは3ヶ月以上の時間を要すると事前に見積っていました。
上記の事情から、開発者達の精神衛生上、安全かつ安定した状態で学習を進められるコードベースの整備は大きな課題で、具体的には以下の懸念がありました。
- 学習ログを監視できるようにしたい
- 学習に使うデータセットのintegrityを保証したい
- 学習のsnapshot (checkpoint) をどこに保存するのか
- snapshotの作成で計算をなるべく止めたくない
- snapshotからの再起動にかかる時間を短縮したい
- メンテナンスイベントによるGPU再起動のコストを減らしたい
学習ログの監視
PLaMo-100B事前学習の以前からDataLoaderの非同期プロセスを含むすべての学習ログをクラスタの共有ファイルシステムに保存していましたが、Google Cloudで実行する場合はログを簡単に閲覧したり監視することが困難だったため、Google Cloud Loggingを利用しました。
Cloud LoggingはPython標準のloggingハンドラが公式に提供されているので、通常はこれを組み込むだけです。ログにはユーザー定義ラベルを登録でき、ラベルを組み合わせて絞り込んだ状態でストリーミングが可能なので、ラベルに学習ジョブの任意IDとMPIランク番号を入れればランクごとにログを確認することが可能です。
普段の学習フローではCloud Loggingで学習の進行状況を見つつ、lossを確認する場合はTensorboardを、ログの更新が止まっているようならクラスタの状況を確認する、のように活用しています。
Dataset integrityの保証
先に述べたように、私達は普段は自社クラスタを中心にLLMの研究開発を行っています。PLaMo-13Bの事前学習では、すべてのデータセットをABCIのストレージへ転送していましたが、学習に利用するクラスタへ都度必要なデータを転送するのは煩雑な操作です。前処理が異なる、更新前のもの、など誤ったデータセットを転送してしまうリスクもあります。
この問題を緩和する手段として、データセットをAmazon S3へ保存することにしました。クラウドストレージに置くことで、インターネットさえ繋がっていればクラスタに依らず同じデータセットにアクセス可能になります。
一方で、Amazon S3からダウンロードする料金が膨らむことや、インターネットとの十分な通信帯域が必要などの課題もあります。利用コストを最小化するために、各クラスタの共有ストレージをクラスタローカルなキャッシュとして利用しました。
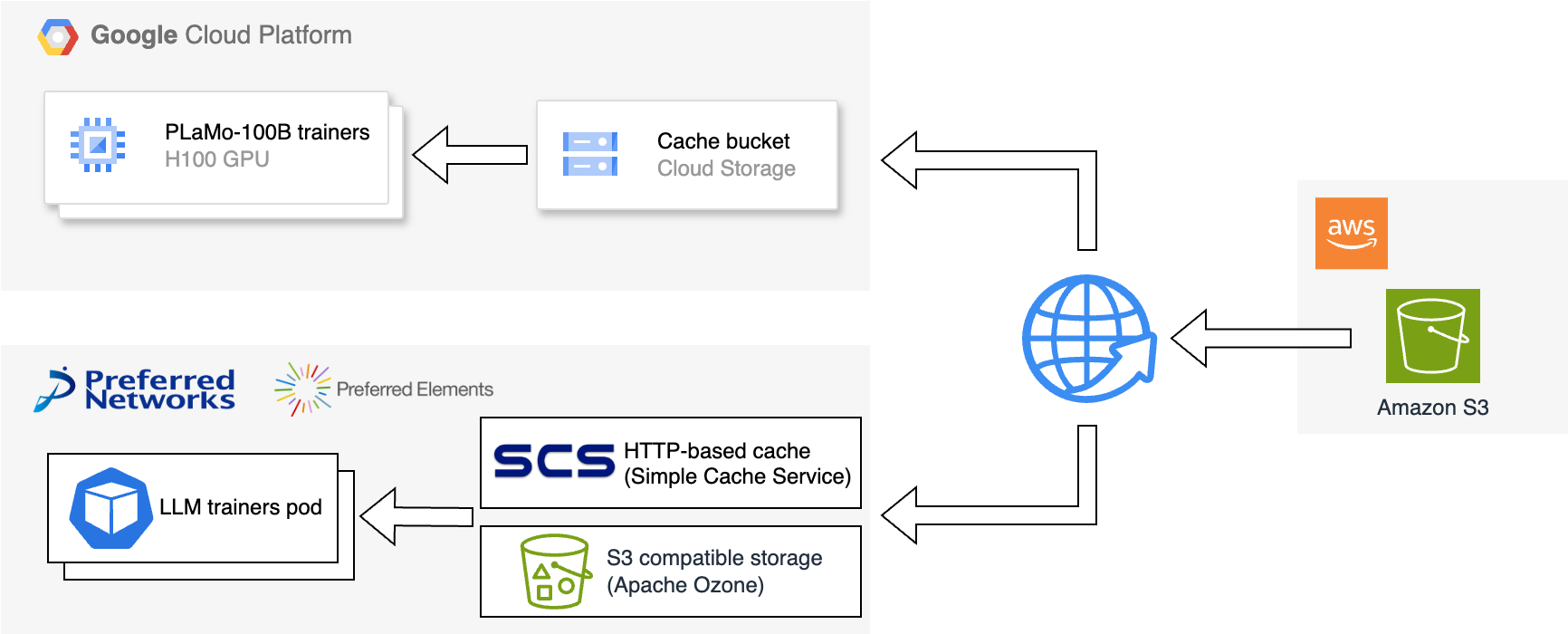
図1:Google Cloudおよび自社クラスタからのデータセットアクセス概要
学習では、データセットをダウンロードするとき、最初にAmazon S3が提供する追加のチェックサムを取得します。キャッシュストレージのオブジェクトとチェックサムを照合し、一致した場合はキャッシュストレージから、不一致の場合はAmazon S3からダウンロードします。
PLaMo-100Bの事前学習では、GCEインスタンスと同じリージョンにAmazon S3と同様のオブジェクトストレージであるGoogle Cloud Storage (以下GCS) のバケットを作成し、キャッシュストレージとしました。また、自社クラスタではHTTP REST APIで動作する内製の分散キャッシュシステムであるSimple Cache Service (SCS) や、S3 compatible storageのApache Ozoneを活用しています。
学習を再実行した場合や、同じデータセットを複数回読む場合はキャッシュストレージへのアクセスとなり、インターネットを経由したAmazon S3からのダウンロードより低コストかつ高速に実現できます。また、誤ったデータを使う心配もありません。
この実装により、Amazon S3にあるデータセットがオリジナルである、と開発チーム内で合意が取れ、データセットの更新や入れ替えのコストを減らすことができました。
学習snapshotの保存
事前学習中のmodel weightやoptimizer state等を保存したものをこの記事ではsnapshotと呼ぶことにします。
100Bモデルのsnapshotを保存するとき、通常はweightだけで約400 GBをストレージに書き込みます。プロセス間の余分な通信や同期の削減を目的に、snapshotは各プロセスが独立に書き込むため、書き込み先のストレージには十分なaggregated bandwidthが必要です。また十分な容量も必要になるため、ストレージの選択は十分な検討が必要です。
HPCクラスタ向けの分散並列ファイルシステムにはLustre FSがあり、Google Cloudでもデプロイ可能です。しかしLustre FSを自分たちで保守するのはエンジニアリングコストが高いと判断し、私達はGCSを利用しました。
GCSはデータ分析基盤としても活用されているため、利用用途から考えると、独立に発生する合計400 GBのPUTリクエストの処理は十分可能と判断しました。
snapshot作成で学習を遅延させない
およそ3ヶ月の事前学習は心理的にsnapshotの作成間隔を短くしたくなりますが、snapshotを保存している間は計算を停止する必要があり、snapshotの作成間隔が短いほど事前学習全体の実行時間が長くなります。
snapshotの作成コストを小さくするため、以下の手順でノードローカルストレージを経由した非同期アップロードを行い、計算の停止時間を短くしました。
- 各プロセスがノードローカルストレージにweight等のデータを書き出す
- バックグラウンドプロセスを起動しノードローカルストレージからGCSへデータをアップロードする
- ノードローカルストレージからアップロード済みデータを削除
Google Compute Engine (以下GCE) のA3インスタンスは、インスタンスあたり6 TBのSSD (375 GB * 16台) を提供しており、各プロセスのsnapshotを保存するのに十分な容量と帯域を持っています。
GCSへのアクセスは通常のTCP通信なのでNICを経由しますが、他方で計算もGPU間通信のためNICを使います。利用するNICが競合し、GPU間通信の性能に影響を与えてしまうのでは?と考える方もいると思います。A3インスタンスのネットワーク性能のドキュメントから引用すると:
- Multi-NIC A3 VMs: For A3 VMs with 8 GPUS attached, multiple physical NICs are available. For these A3 machine types the NICs are arranged as follows on a Peripheral Component Interconnect Express (PCIe) bus:
- For the A3 High machine type: a NIC arrangement of 4+1 is available. With this arrangement, 4 NICs share the same PCIe bus, and 1 NIC resides on a separate PCIe bus. NICs that share the same PCIe bus, have a non-uniform memory access (NUMA) alignment of one NIC per two NVIDIA H100 80GB GPUs.
つまり、以下のような構成イメージと考えられます。
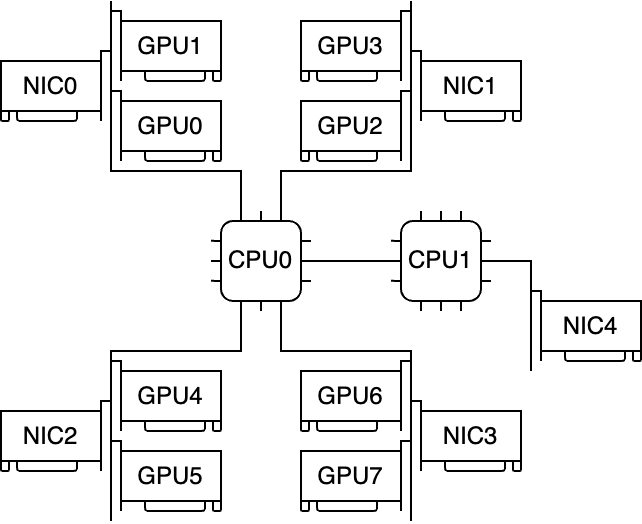
図2:GCE A3 highインスタンスの構成概要
NICをどのように使うかはユーザーが設定できるので、計算に必要な通信に影響を与えることなくGCSへsnapshotを計算の裏でアップロードできます。
実測値では100Bモデルのsnapshot 1つを保存し、snapshotがavailableな状態に遷移するまでに必要な時間はほとんどの場合で約5分以内でした。このうち、snapshotをノードローカルストレージに保存する時間、つまり計算を止める必要があるのは1分未満です。
非同期アップロードをしないと4分以上の計算停止時間が発生することになりますが、snapshotを約2時間に1回の間隔で保存したいとなると、1日で約50分の計算停止時間が発生します。切り上げて1日約1時間とすると、snapshotの保存によって約4日、学習期間が延びる計算です。
これはH100 GPUを始めとした計算コストが4日分、追加で必要なことを意味します。完全無停止で90日なので、再起動が発生した数だけ学習完了日は後退します。たった4日とも思えますが、大規模事前学習には相当数のGPUが必要となり利用料金にも大きな無駄が生じてしまいます。非同期アップロードによって、この無駄を軽減することができました。
学習の再起動にかかる時間を短縮する
私達の経験上、数日から1週間に一度はなんらかの理由で学習の異常終了が発生すると見込まれていたため、snapshotから再起動するのにかかる時間を短くする必要がありました。例として、PyTorch DataLoaderを取り上げます。
バッチの作成コストを隠蔽するため、PyTorch DataLoaderのMultiprocess Loaderを使用していますが、Multiprocess Loaderは状態を保存できるように実装されていません。したがってsnapshotからDataLoaderを復元するには、学習済みのバッチを読み飛ばす必要があります (参考: HuggingFace accelerateの実装) 。
バッチのスキップは、ナイーブな実装では非同期処理によって隠蔽していたバッチ作成コストがすべて顕在化します。私達の測定では、合計で1 T tokenに相当するバッチをスキップすると、PLaMo-100Bの事前学習で使用したリソースよりも少ない状態で1時間以上必要と許容できないコストでした。そこで、状態をpickle化できるStateful DataLoaderを実装しました。
loader = DataLoader(ds, batch_size=16, prefetch_size=4, concurrent=True) it = iter(loader) for _ in range(5): next(it) state = pickle.dumps(loader) restarted_it = pickle.loads(state) assert isinstance(restarted_it, StatefulIterator) assert pickle.dumps(next(it)) == pickle.dumps(next(restarted_it))
非同期プロセスが行うデータセット読み込みからバッチ作成までの処理は、計算時間で完全に隠蔽できるため、1プロセスで処理しています。したがって、snapshotから学習を再実行してもバッチの再現性が保証されます。
DataLoaderの自前実装によってsnapshotからの状態復元はほぼ無視できるコストになり、学習が正常状態 (学習をしている状態) に復帰するまでの時間は約30分となりました。これにはA3インスタンスの起動、GPUの通信設定など学習の実行に必要なすべての初期化コストが入っています。
GPUメンテナンスイベントからの早期復帰
この項目はGoogle CloudでのGPUインスタンス固有の話になります。
Google Cloudではホストメンテナンスイベントがあり、不定期でインスタンスの再起動がスケジュールされます。おおよその頻度としては、GPUは通常2週間に1回とされています。
メンテナンスはインスタンスごとに異なるタイミングで行われるため、ほぼランダムイベントと捉えられます。当初は高頻度ではないと考えていましたが、学習開始直後の1週間でイベントによって失う計算時間を計測し、緊急対応を行いました。
幸いにも、このイベントは各インスタンスが事前に検知可能です。各インスタンスからGCEのメタデータサーバーに対しリクエストを投げると、現在のスケジュールが返却されます。メタデータサーバーはイベントが発生する1時間前から、リクエストへの応答で `TERMINATE_ON_HOST_MAINTENANCE` を返すようになります。
# イベントがスケジュールされていない場合 a3-instance$ curl http://metadata.google.internal/computeMetadata/v1/instance/maintenance-event -H "Metadata-Flavor: Google" NONE # イベントが1時間以内にスケジュールされている場合 a3-instance$ curl http://metadata.google.internal/computeMetadata/v1/instance/maintenance-event -H "Metadata-Flavor: Google" TERMINATE_ON_HOST_MAINTENANCE
学習中は定期的に上記のリクエストを監視し、検知直後および検知してから45分後にsnapshotを作成する方針としました。
このときは約2時間に1回の頻度でsnapshotを作成していましたが、最悪のケースでは次のsnapshotを作成する直前に再起動し、snapshotからの復帰時間も含めておよそ2.5から3時間を失っていました。上述の対応によって、メンテナンスで失う学習時間はsnapshotからの復帰時間も含めて最良値で約45分、最悪値で約1時間30分になり、エラーによる再起動コストに対して最小約1.5倍に圧縮できました。
おわりに
LLMの事前学習を支える技術と題して、計算や高速化手法以外で、しかし重要な実装について紹介しました。特にsnapshotにかかわる部分は、1日のうち3-4時間を無駄にしないために非常に重要な実装となりました。
冒頭でもふれていますが、PFN/PFEはPLaMo-100Bの成果を踏まえ、現在はより高性能かつ軽量なPLaMo-2の開発を進めています。基盤モデル開発は長期にわたる学習を前提としており、機械学習・深層学習の研究開発は当然ながら、それを支える技術も今以上に求められていると感じています。
そのすべてではありませんが、PFN/PFEではコンパイラやストレージ、セキュリティ、計算基盤のエンジニアはもちろん、ビジネス開発やマネジメントなど多くの仲間を募集しています。本記事や募集内容で、興味を持っていただければ幸いです。



