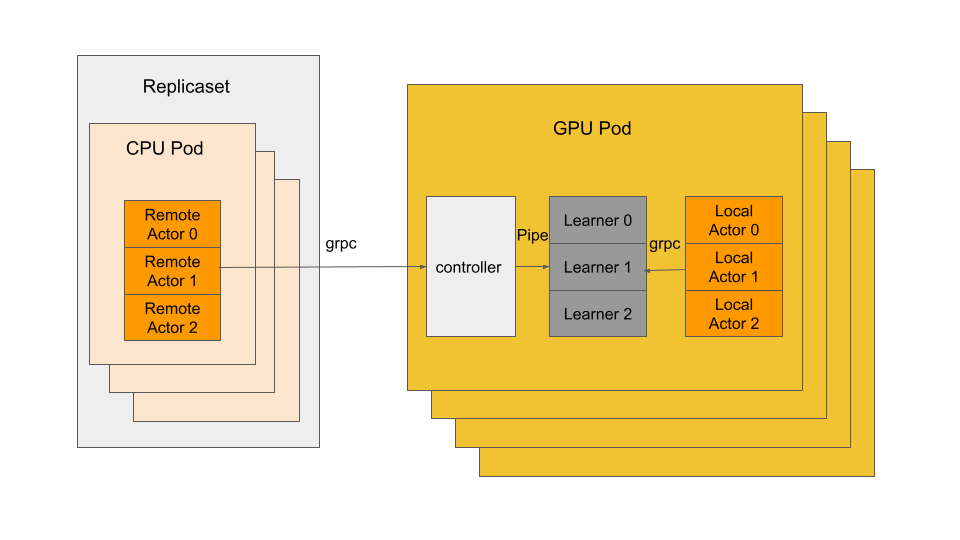
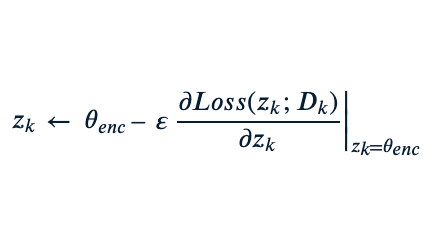Reinforcement Learning
Sequential decision-making for the real world.
強化学習(RL)は、ゲーム、移動、およびロボット工学におけるいくつかの困難な連続した意思決定問題の解決策を提供してきました。
PFNでは、強化学習の課題に取り組み、実際のアプリケーションを実現することを目指しています。 私たちの研究には、ディープRL、安全性、ロボット工学、モデルベースRL、および模倣学習が含まれます。
Publications
Reconnaissance for Reinforcement Learning with Safety Constraints
ECML2021
By : Shin-ichi Maeda, Hayato Watahiki, Yi Ouyang, Shintarou Okada, Masanori Koyama, Prabhat Nagarajan
Periodic Intra-Ensemble Knowledge Distillation for Reinforcement Learning
ECML 2021
By : Zhang-Wei Hong, Prabhat Nagarajan, Guilherme Maeda
ChainerRL: A Deep Reinforcement Learning Library
JMLR 2021
By : Yasuhiro Fujita, Prabhat Nagarajan, Toshiki Kataoka, Takahiro Ishikawa
MANGA: Method Agnostic Neural-policy Generalization and Adaptation
ICRA 2020
By : Homanga Bharadhwaj, Shoichiro Yamaguchi, Shin-ichi Maeda